







目录
异构计算
本质上是CPU和GPU配合进行计算。

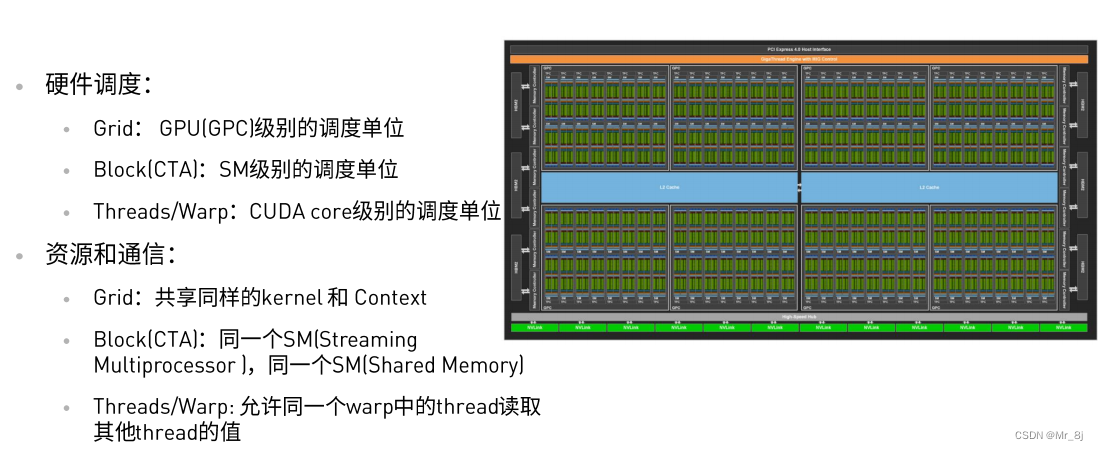
CUDA线程层次
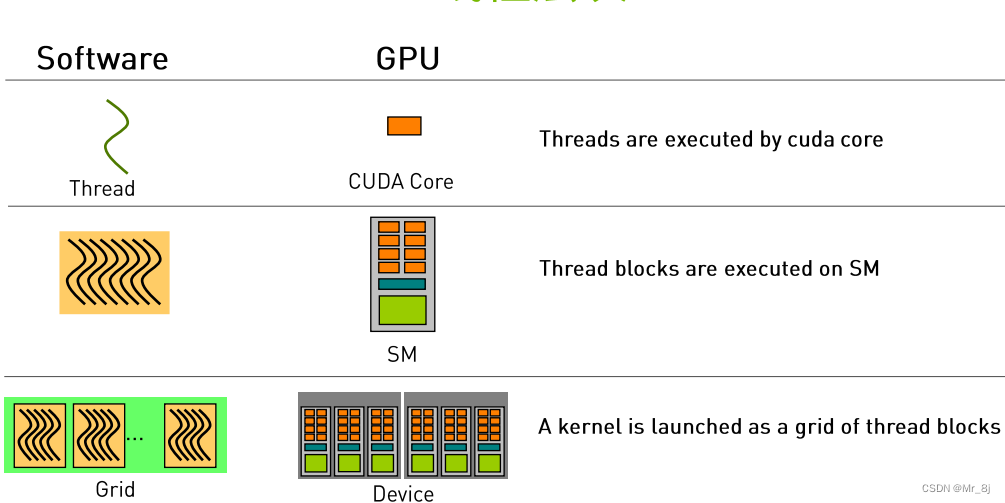
thread 线程:sequential execution unit 顺序执行单元
- 所有线程执行相同的核函数
- 并行执行
笔记:要区别cpu串行的思想,GPU中所有线程在同一时间并行执行一个函数(函数叫核函数)
(thread)block 块:a group of threads 多个thread组成一个block组
- 执行在一个Streaming Multiprocessor(SM)
- 同一个block中的线程可以协作
笔记:推荐block中含有128个thread,但是不绝对,需要根据实际场景进行改变来优化。warp是一个SM执行的基本单元,一个warp含有32个thread,因此申请32倍数的线程可以最大化利用线程。
thread grid 网格:a collection of thread blocks 多个block组成一个grid
- 一个grid当中的block可以在多个SM中执行
CUDA执行流程

CUDA线程索引
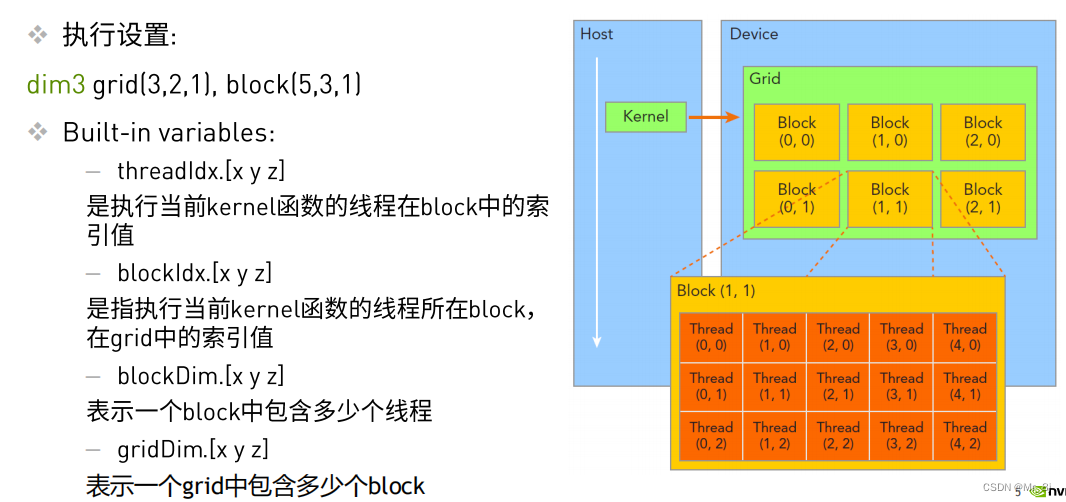
dim3 grid(3,2,1) ,block(5,3,1) 如上图所示
dim3表示三个维度
grid(3,2,1) 表示grid内x方向有3个block,y方向有2个block,z方向有1个block。grid_size为6
block(5,3,1)表示block内x方向有5个thread,y方向有3个thread,z向有1个thread。block_size为15
eg. HelloFromGPU <<<grid_size, block_size>>>();

如上图所示情况下为grid为1维的情况。
下图为grid是2维的情况:


若2维gird情况下:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y
idx = iy*nx + ix;
CUDA线程分配
 一个warp含有32个thread,若仅仅多出1个thread,也需要另外一个warp,因此最好申请32倍数的thread。
一个warp含有32个thread,若仅仅多出1个thread,也需要另外一个warp,因此最好申请32倍数的thread。
查看设备数据
在devicequery中查看设备warp、block等数据。

1个block最大线程个数:1024,block每个维度最大线程可设置为1024,1024,64。
注意是每个维度方向线程的乘积即总线程数要小于1024。
实例:向量加法
通过索引index,让每个执行kernel函数的线程处理不同数据
GPU中,申请所有的线程,都会执行相同的核函数。(思维转变)

#include <math.h>
#include <stdio.h>
//核函数 矩阵相加
__global__ void add(const double *x, const double *y, double *z, int count)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
//n为线程index,index小于所要求的元素数量N,就进行相加运算
if( n < count)
{
z[n] = x[n] + y[n];
}
}
//判断每个数的和是否为3
void check(const double *z, const int N)
{
bool error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
error = true;
}
}
printf("%s\n", error ? "Errors" : "Pass");
}
int main(void)
{
//取1000个数
const int N = 1000;
//计算1000个double类型的字节数
const int M = sizeof(double) * N;
//申请cpu内存
double *h_x = (double*) malloc(M);
double *h_y = (double*) malloc(M);
double *h_z = (double*) malloc(M);
//给矩阵中1000个元素赋值1和2
for (int n = 0; n < N; ++n)
{
h_x[n] = 1;
h_y[n] = 2;
}
//申请GPU内存
double *d_x, *d_y, *d_z;
cudaMalloc((void **)&d_x, M);
cudaMalloc((void **)&d_y, M);
cudaMalloc((void **)&d_z, M);
//将数据从cpu传输到gpu上
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
//设置block大小和grid大小
const int block_size = 128;
//通过此公式计算所需grid大小,grid_size最少需要比N大一些,推荐设置
const int grid_size = (N + block_size - 1) / block_size;
//核函数计算
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
//计算完传回数据
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);
check(h_z, N);
//释放cpu和gpu内存
free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}问题:若数据过大,线程不够用
总共8个线程,需要处理32个数据。

解决办法:通过循环利用线程多次处理。
__global__ add(const double *x, const double *y, double *z, int n)
{
int index = blockDim.x * blockIdx.x + threadIdx.x;
int stride = blockDim.x * gridDim.x; //stride为滑移长度,此处为8,也为分配的总线程数
for(; index <n; index +=stride)
z[index] = x[index] + y[index];
}















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









