






CUDA调动硬件

CPU遇到的瓶颈:

时钟频率墙:硬件不能越来越小,可以做,但是不能用,因为会产生散热问题
存储器:单位面积的存储东西越来越多,存储器的速度和大小并不会又很快的提升,不能满足处理器的发展。
GPU应运而生:
只能向多核及并行系统发展,顺势而生的GPU---Graphics Processing Unit
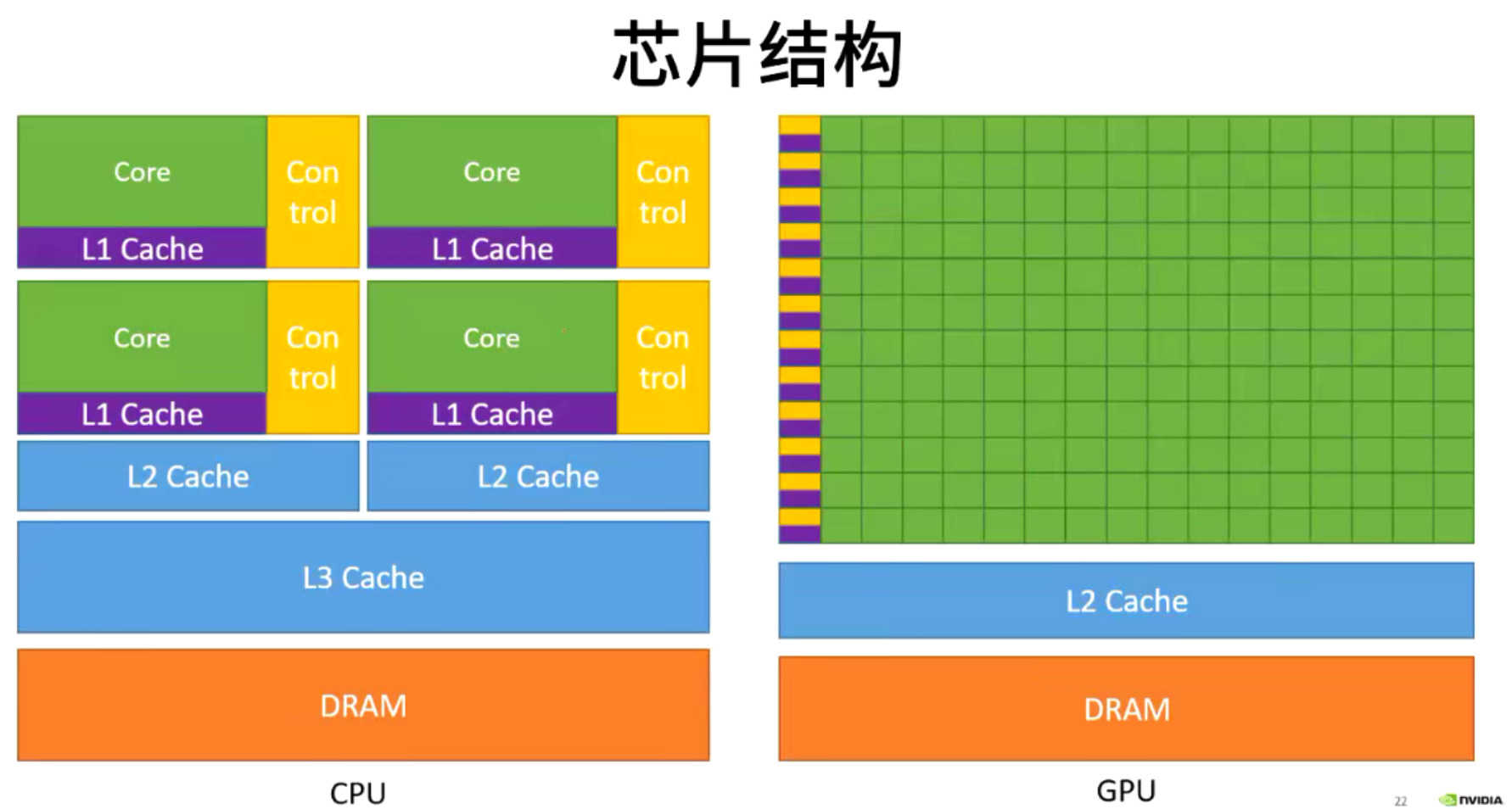
流多处理器(stream multiprocessor,sm)
GPU是一个协处理器,他要和CPU进行合作处理事情。CPU是线性执行的,GPU是并行处理的。
并行计算是同时应用多个计算资源解决一个计算问题,涉及多个计算资源或处理器
问题被分解为多个离散的部分,可以同时处理(并行)
每个部分可以由一系列指令完成
最好是计算密集的任务:通信和计算开销比例合适;不要受制于访存带宽;这些都能在基于ARM平台的Jetson NANO上完成!


3.1 异构计算
Host CPU和内存(host memory) ---做逻辑控制
Device GPU和显存(device memory)---做并行化计算
3.2 CUDA安装
适用设备:所有包含NVIDIA GPU的服务器,工作站,个人电脑,嵌入式设备等电子设备
软件安装:
Windows:https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html只需要安装一个.exe的可执行程序
Linux:https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html按照上面的教程,需要6/7个步骤即可
Jetson:https://developer.nvidia.com/embedded/jetpack直接利用NVIDIA SDK Manager或者SD image进行刷机即可
软件安装:
查看当前设备中GPU状态:服务器、工作站、个人电脑---nvidia-smi;Jetson等设备:Jtop
查看当前设备参数
在CUDA sample中1_Utilities/deviceQuery文件夹下的deviceQuery程序。以Ubuntu为例,deviceQuery程序在:/user/local/cuda/sample/1_Utilities/deviceQuery
3.3 CUDA程序的编写


名词解释:
执行:就是说程序在哪里执行
调用:就是用的时候在哪里调的
__global__可以在GPU上调用,也可以在CPU上调用;__device__可以在GPU上调用;__device__和_host_执行空间说明符一起使用,说明该函数可以被CPU和GPU一起编译。
__global__ 可以在GPU上执行,可以在GPU上编译也可以在CPU上编译
__device__ 只能在GPU上执行
__host__ 只能在CPU上执行
(图片里的意思:设备指的就是GPU,主机指的就是CPU)

//Kernel function
__global__ void VecAdd(float* A,float* B,float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
//Kernel invocation with N threads
VecAdd<<<1,N>>>(A,B,C);//调用核函数
//调用核函数需要一个执行设置:<<<1,N>>> 定义调用了多少个线程
}3.4 CUDA程序编译


NVCC会把CPU代码和GPU代码分别编译,然后可以把这两部分的编译结果合成一个可执行程序。
//nvcc向后编译,现实版本的要比虚拟版本的架构更高一点
//gpu-architecture要比gpu-code低才可以
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=sm_50,sm_52
nvcc x.cu --gpu-architecture=compute_50
nvcc x.cu\
--generate-code arch=compute_50,code=sm_50\
--generate-code arch=compute_50.code-sm_52\
--generate-code arch=computer_53,code=sm_53
nvcc x.cu\
--generate-code
arch=computer_50,code=[sm_50,sm_52]\
--generate-code arch=computer_53,code=sm_53
跟gcc编译差不多,hello_from_gpu.cu编译成hello_from_gpu.o,然后再把hello_from_gpu.o和hello_cuda_main.cu编译成hello_from_gpu,这就是编译结束了。
3.5 利用NVPEOF查看程序执行情况
Kernel Timeline输出的是以gpu kernel为单位的一段时间的运行时间线,我们可以通过它观察GPU在什么时候有闲置或者利用不够充分的行为,更准确地定位优化问题。nvprof是nvidia提供地用于生成gpu timline的工具,其为cuda toolkit的自带工具。
nvprof -o out.nvvp a.exe
模式一:nvprof a.exe
模式二:nvprof --print-gpu-trace a.exe(可以查看更细节的东西)
模式三:nvprof --print-api-trace a.exe (查看从头到尾的运行细节)
3.6 CUDA线程层次
Thread:sequential execution unit
所有线程执行相同的和函数
并行执行
Thread Block:a group of threads(多个线程组合在一起为一个Block)
执行在一个Streaming Multiprocessor(SM)
同一个Block中的线程可以协作
Thread Grid: a collection of thread blocks(多个块组合在一起为一个Grid)
一个Grid当中的Block可以在多个SM中执行
【HelloFromGPU<<<?,?>>>();第一个问号是Grid里有多少个Block,第二个问号是Block里有多少个线程】
如何定位线程的具体位置呢?
答:
-threadIdx.[x y z]是执行当前kernel函数的线程在block中的索引值(threadIdx.x是1,threadIdx.y是0)
-blockIdx.[x y z]是指执行当前kernel函数的线程所在block,在grid中的索引值(blockIdx.x是1,blockIdx.y是1)
-blockDim.[x y z]表示一个block中包含多少个线程(blockDim.x是5,blockDim.y是3)
-gridDim.[x y z]表示一个grid中包含多少个block(gridDim.x是3,gridDim.y是2)


上述图二:add<<<1,4>>>(a,b,c)申请的所有线程数都会执行上面那一个程序。然后a,b,c都是数组,如果是在CPU里,那就是一个循环,第一步:c[0]=a[0]+b[0];第二步:c[1]=a[1]+b[1];但是GPU里面就是同时申请多个线程,然后同时运算。

Blocks好像也不是必须的
增加了一个层次
3.7 执行流程
加载核函数
将Grid分配到一个Device
根据<<<..>>>内的执行设置的第一个参数,Giga threads engine将block分配到SM中。一个Block内的线程一定会在同一个SM内,一个SM可以有很多Block
根据<<<..>>>内的执行设置的第二个参数,Wrap调度器会调用线程。
Wrap调度器为了提高运行效率,会将每32个线程分为一组,称作一个warp
每个Wrap会被分配到32个core上运行

3.8 CUDA线程索引

Parallelizable problem: c=a+b; a,b,c are vectors of length N
void vecAdd(int n,int*a,int*b,int*c)
{
for(int i=0;i<n;i++)
{
c[i]=a[i]+b[i];
}
}//CUDA implementation的main函数:
void main()
{
int size=N*sizeof(int); //空间大小
int *a,*b,*c;
a=(int*)malloc(size); //给向量a申请空间
b=(int*)malloc(size);
c=(int*)malloc(size);
memset(c,0,size); //初始化内存
init_rand_f(a,N); //赋值
init_rand_f(b,N);
vecAdd(N,a,b,c);
}int main(void)
{
size_t size=N*sizeof(int); //N是数据个数,乘sizeof(int)可以得到数据大小
int *h_a,*h_b;int *d_a,*d_b,*d_c;
h_a=(int*)malloc(size);
h_b=(int*)malloc(size);
...
cudaMalloc((void**)&d_a,size);
cudaMalloc((void**)&d_b,size);
cudaMalloc((void**)&d_c,size);
//以下,第一个是目的地,第二个是源,第三个是数据大小,第四个是传输方向,从哪里传到哪里
cudaMemcpy(d_a,h_a,size,cudaMemcpyHostToDevice);//把a里的数据从CPU传到GPU
cudaMemcpy(d_b,h_b,size,cudaMemcpyHostToDevice);//把b里的数据从CPU传到GPU
vectorAdd<<<grid,block>>>(d_a,d_b,d_c,N); //d_a等,是Device Pointers
cudaMemcpy(h_c,d_c,size,cudaMemcpyDeviceToHost);//执行完核函数之后,把数据从GPU传到CPU
//以下是释放数据存储
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
free(h_a);
free(h_b);
return 0;
}【如何设置Gridsize & Blocksize?】
//这些只是推荐申请,没有什么标准答案
block_size=128;
gride_size=(N+block_size-1)/block_size;那么我们每个Block可以申请多少个线程?

第五行:每个block最大有1024个线程;第六行:不是说三个维度可以同时到最大值,而是说这几个的乘积不能超过1024。
可以同时执行的线程数是一个Warps(一个Warps里有32个线程),一个Block里面可以有多个Warps,

【如果数据过多,线程不够用怎么办?】

//在每个线程里都有一个for循环
__global__add(const double*x,const double *y,double *z,int n)
{
int index=blockDim.x*blockIdx.x+threadIdx.x;
int stride=blockDim.x*gridDim.x;
for(;index<n;index+=stride)
{
z[index]=x[index]+y[index];
}
}3.9 实验--CUDA编程模型
3.9.1 编写第一个CUDA程序
关键词:"__global__" , <<<...>>> , .cu
在当前的目录下创建一个名为hello_cuda.cu的文件,编写第一个Cuda程序:
当我们编写一个hello_word程序的时候,我们通常会这样写:
#include <stdio.h>
void hello_from_cpu()
{
printf("Hello World from the CPU!\n");
}
int main(void)
{
hello_from_cpu();
return 0;
}如果我们要把它改成调用GPU的时候,我们需要在void hello_from_cpu()之前加入 __global__标识符,并且在调用这个函数的时候添加<<<...>>>来设定执行设置
在当前的目录下创建一个名为hello_cuda.cu的文件,更改上述程序,将它改为在GPU上执行的程序,
#include <stdio.h>
__global__ void hello_from_gpu()
{
printf("Hello World from the GPU!\n");
}
int main(void)
{
hello_from_gpu<<<1,1>>>();
cudaDeviceSynchronize();
return 0;
}3.9.2、编写完成后,我们开始编译并执行程序,在这里我们可以利用nvcc进行编译
/usr/local/cuda/bin/nvcc -arch=compute_72 -code=sm_72 hello_cuda.cu -o hello_cuda -run3.9.3、这里我们也可以利用编写Makefile的方式来进行编译
# 先写一个Makefile脚本
TEST_SOURCE = hellocuda.cu # 源文件
TARGETBIN := ./hello_cuda # 目标文件
CC = /usr/local/cuda/bin/nvcc # nvcc的位置
$(TARGETBIN):$(TEST_SOURCE)
# 一步到位 把源文件转化成目标文件-o $(CC)是编译命令
$(CC) $(TEST_SOURCE) -o $(TARGETBIN)
.PHONY:clean
clean:
-rm -rf $(TARGETBIN) # 删掉目标文件
-rm -rf *.o # 删掉所有的中间文件然后输入make;然后我们就可以得到一个名为hello_cuda.exe的程序,我们开始执行一下,这是执行命令./hello_cuda
多个文件协同编译,修改Makefile文件:
1、编译hello_from_gpu.cu文件生成hello_from_gpu.o
2、编译hello_cuda02-test.cu和上一步生成的hello_from_gpu.o,生成./hello_cuda_multi_file
TEST_SOURCE = hello_cuda02-test.cuTARGETBIN := ./hello_cuda_multi_fileCC = /usr/local/cuda/bin/nvcc# 目标文件的生成 依赖于hello_cuda02-test.cu和hello_from_gpu.o$(TARGETBIN):hello_cuda02-test.cu hello_from_gpu.o $(CC) $(TEST_SOURCE) hello_from_gpu.o -o $(TARGETBIN)# hello_from_gpu.o依赖于hello_from_gpu.cu生成hello_from_gpu.o:hello_from_gpu.cu $(CC) --device-c hello_from_gpu.cu -o hello_from_gpu.o.PHONY:cleanclean: -rm -rf $(TARGETBIN) -rm -rf *.o
然后输入指令make -f Makefile_Multi_file,./hello_cuda_multi_file以及make -f Makefile_Multi_file clean
$ make -f rules.txt
或者
$ make --file=rules.txt
上面代码指定make命令依据rules.txt文件中的规则,进行构建。这时已经完成了第一个CUDA程序,接下来修改<<<...>>>里面的信息,查看显示效果,可以把<<<1,1>>>改成<<<2,4>>>查看效果
3.9.4.利用nvprof进行查看程序性能
sudo /usr/local/cuda/bin/nvprof ./hello_cuda

3.10 实验--CUDA编程模型(线程组织)
3.10.1 使用多个线程的和函数
1.当我们在讨论GPU和CUDA时,我们一定会考虑如何调用每一个线程,如何定为每一个线程。其实,在CUDA编程模型中,每一个线程都有一个唯一的标识符或者序号,而我们可以通过threadIdx来得到当前的线程在线程块中的序号,通过blockIdx来得到该线程所在的线程块在grid当中的序号,即:
threadIdx.x 是执行当前kernel函数的线程在block中的x方向的序号 blockIdx.x 是执行当前kernel函数的线程所在block,在grid中的x方向的序号
#include <stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
printf("Hello World from block %d and thread %d!\n", bid, tid);
}
int main()
{
hello_from_gpu<<<5, 5>>>();
cudaDeviceSynchronize();
return 0;
}创建好了之后,我们开始编译make,执行./Index_of_thread
3.10.2 使用线程索引
那我们如何能够得到一个线程在所有的线程中的索引值?比如:我们申请了4个线程块,每个线程块有8个线程,那么我们就申请了32个线程,那么我需要找到第3个线程块(编号为2的block)里面的第6个线程(编号为5的thread)在所有线程中的索引值怎么办?
gridDim表示一个grid中包含多少个block,gridDim.x表示横向block数量,gridDim.y表示纵向block数量
blockDim表示一个block中包含多少个线程,blockDim.x表示横向block数量,blockDim.y表示纵向block数量
在上面的那个例子中,gridDim.x=4, blockDim.x=8,那么,我们要找的第22个线程(编号为21)的唯一索引就应该是,index = blockIdx.x * blockDim.x + threadIdx.x

接下来,我们通过完成一个向量加法的实例来实践一下,我们来实现的CPU代码如下:
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
void add(const double *x, const double *y, double *z, const int N)
{
for (int n = 0; n < N; ++n)
{
z[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{
bool has_error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
has_error = true;
}
}
printf("%s\n", has_error ? "Errors" : "Pass");
}
int main(void)
{
const int N = 100000000;
const int M = sizeof(double) * N;
double *x = (double*) malloc(M);
double *y = (double*) malloc(M);
double *z = (double*) malloc(M);
for (int n = 0; n < N; ++n)
{
x[n] = 1;
y[n] = 2;
}
add(x, y, z, N);
check(z, N);
free(x);
free(y);
free(z);
return 0;
}为了完成这个程序,我们先要将数据传输给GPU,并在GPU完成计算的时候,将数据从GPU中传输给CPU内存。这时我们就需要考虑如何申请GPU存储单元,以及内存和显存之间的数据传输。
#include <math.h>
#include <stdio.h>
void __global__ add(const double *x, const double *y, double *z, int count)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x; //n是线程索引
if( n < count)
{
z[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{
bool error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
error = true;
}
}
printf("%s\n", error ? "Errors" : "Pass");
}
int main(void)
{
const int N = 1000;
const int M = sizeof(double) * N;
double *h_x = (double*) malloc(M); //申请一部分空间
double *h_y = (double*) malloc(M);
double *h_z = (double*) malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = 1;
h_y[n] = 2;
}
double *d_x, *d_y, *d_z; //设备端
cudaMalloc((void **)&d_x, M); //申请GPU的存储单元
cudaMalloc((void **)&d_y, M);//返回arraytype类型,不能返回直接分配好的指针,要返回一个指向那个指针的指针,要修改那个参量
cudaMalloc((void **)&d_z, M);
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice); //完成数据从CPU到GPU的传输
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
const int block_size = 128; //这是推荐设置
const int grid_size = (N + block_size - 1) / block_size;
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N); //调用add函数
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost); //从Device(GPU)端传输到Host(CPU)
check(h_z, N); //检查
free(h_x); //释放cpu的数据存储
free(h_y);
free(h_z);
cudaFree(d_x); //释放GPU的数据存储
cudaFree(d_y);
cudaFree(d_z);
return 0;
}然后输入make -f Makefile_vectorAdd,然后再输入./vectorAdd利用nvprof查看程序性能sudo /usr/local/cuda/bin/nvprof --print-api-trace ./vectorAdd















 4650
4650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











