







ps:改良之后的多线程版本在最后
背景
大饼加了不少技术交流群,之前在群里看到拉钩教育平台在做活动,花了1块钱买了套课程。比较尴尬的是大饼一般都会在上下班的路中学习下(路上时间比较久)而这个视频无法缓存,只能通过在线的方式进行学习,这(what`s the fuck…)
对于没有多少流量的我来说没法忍…于是乎想着通过爬虫的方式将视频爬取下来…
主要技术知识运用
1、request模块发送请求
2、json模块对返回值进行处理
3、AES解密
主要流程
1、登录后选择已购买的课程(这是我已购买的其中一套课程,以此为例)
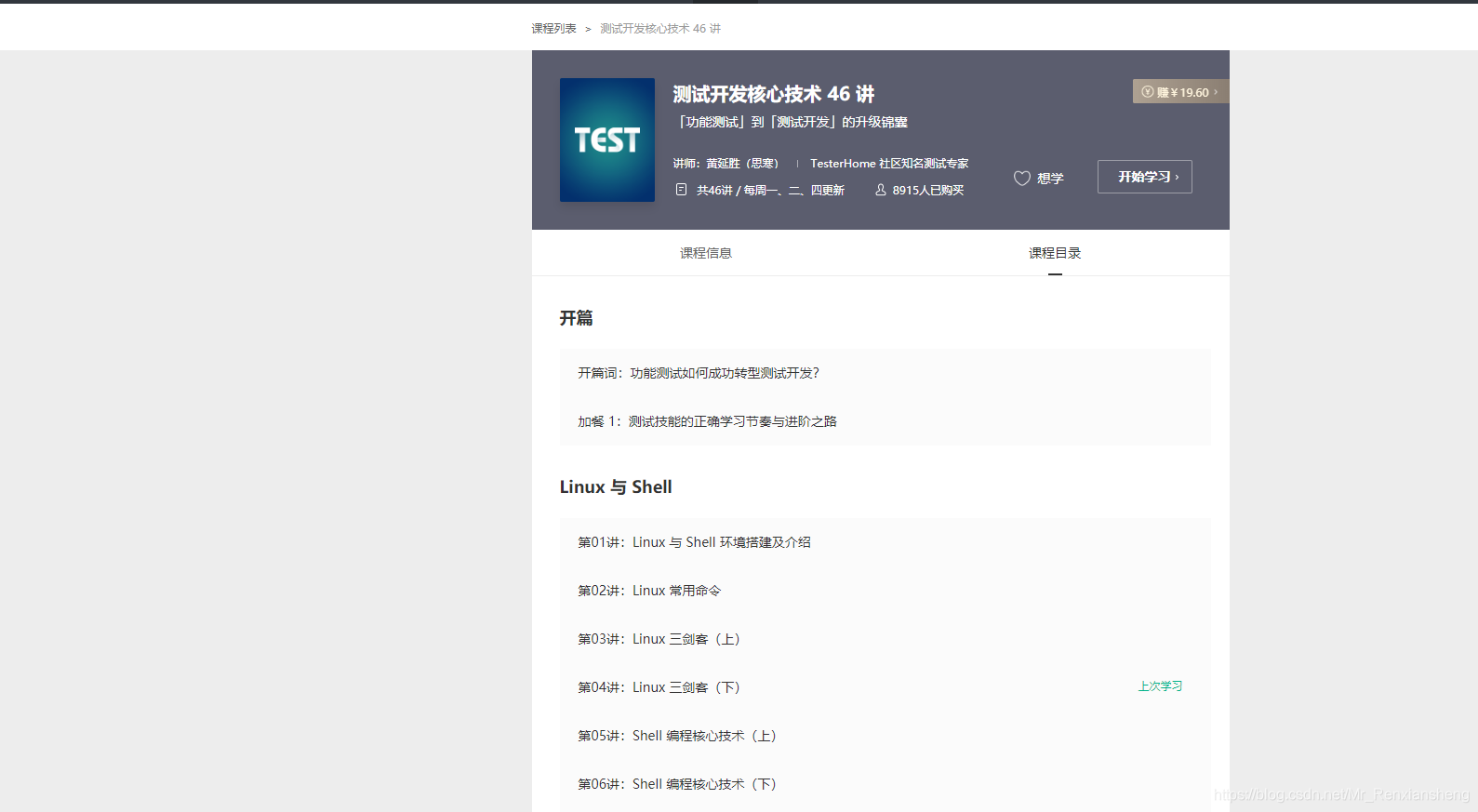
2、为了一次性拿到所有课程名以及课程链接,这里可以通过f12抓包的方式获取
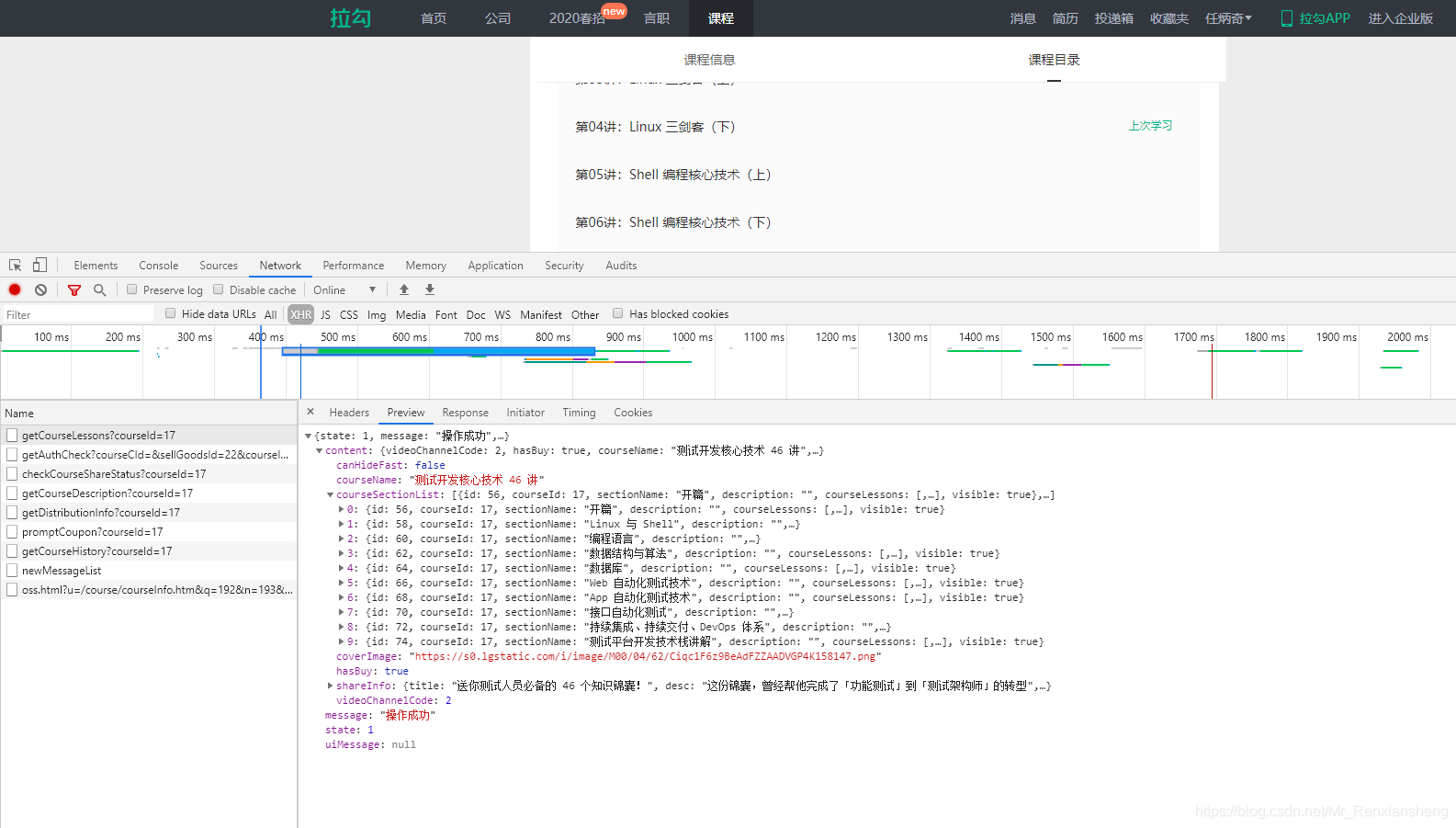
通过对响应的分析,可以确定就是这个请求…此时可以通过headers查看请求的地址以及响应的一些参数。
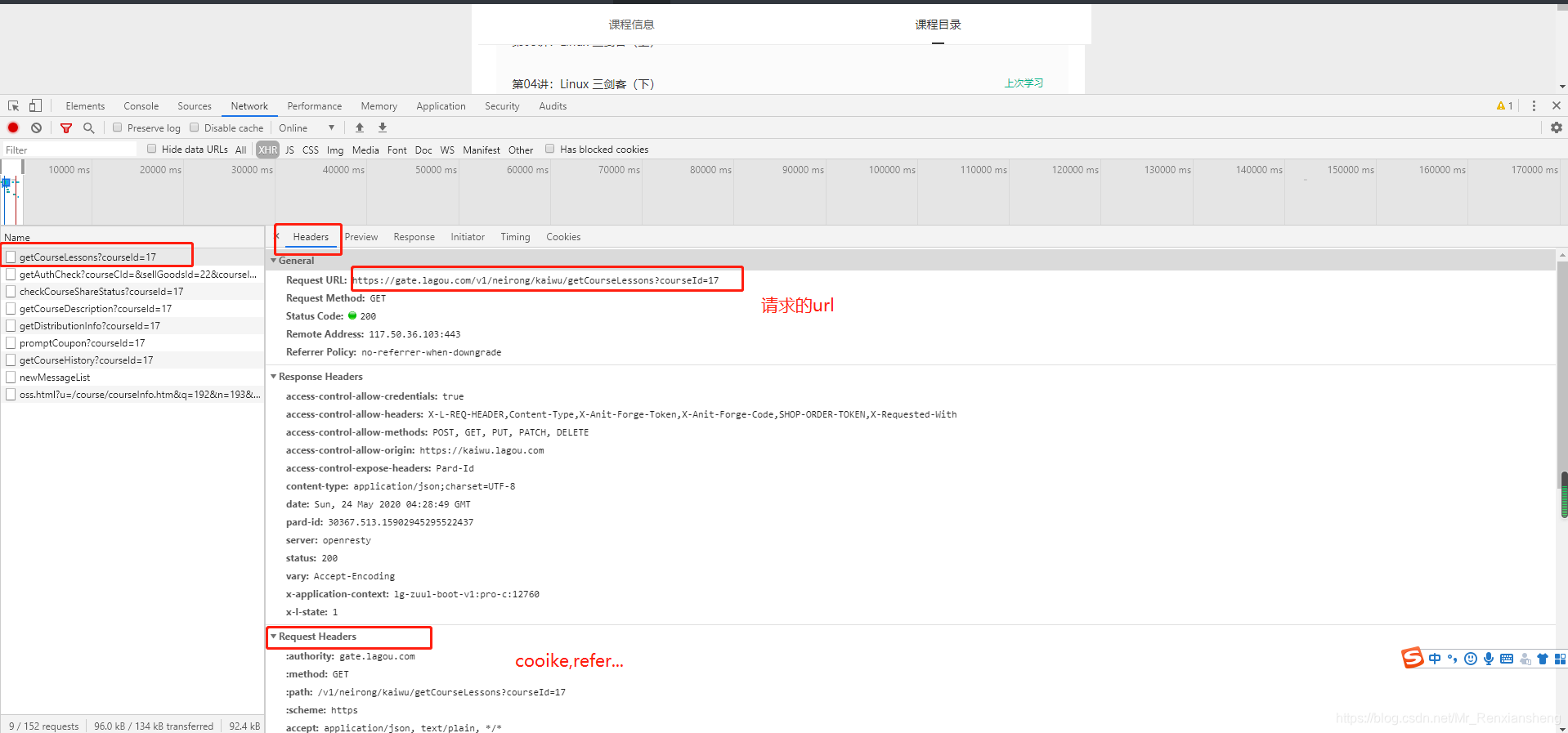
request headers中有很详细的信息,一般cooike肯定是需要带上的(代码中的cooike是错误的,这里只截取了一部分),大饼这里偷了下懒,把一些相对重要的信息都配置到headers中了
def __init__(self):
self.url='https://gate.lagou.com/v1/neirong/kaiwu/getCourseLessons?courseId=17'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Cookie':'16ded4ec8fd4fc%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2280.0.3987.132%22%7D%2C%22first_id%22%3A%22172322a320715c-0a184f9286834f-4313f6a-2073600-172322a320890a%22%7D',
'Referer':'https://kaiwu.lagou.com/course/courseInfo.htm?courseId=17',
'Origin':'https://kaiwu.lagou.com',
'Sec-fetch-dest':'empty',
'Sec-fetch-mode':'cors',
'Sec-fetch-site':'same-site',
'x-l-req-header':'{deviceType:1}'}
3、配置好了一些基本信息后就可以开始发送请求了
此次请求是为了拿到所有课程的m3u8以及课程名
ps:很多视频网站会通过m3u8的方式将视频分割成多个ts文件,我们要做的就是分析m3u8文件得到所有ts文件的url 同时如果加密了需要得到key
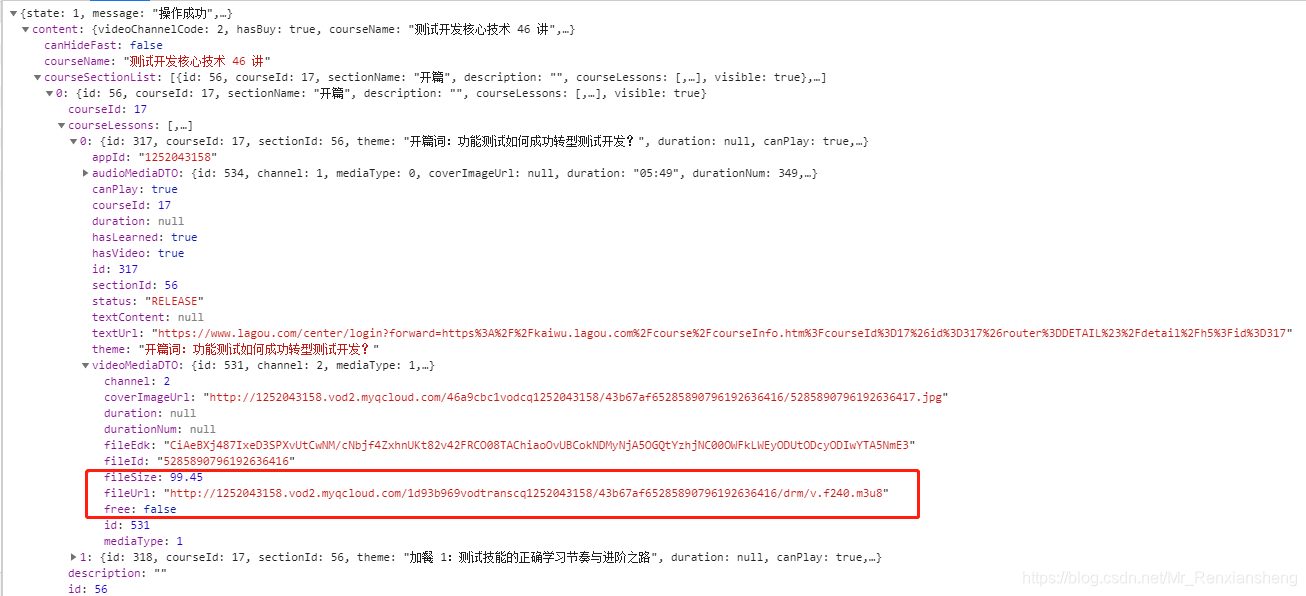
请求发送后返回来的是一个json格式的数据,从上图可以看到,m3u8的url其实就在这个json的数据中,而我们就是需要想办法得到这个m3u8的url
具体代码如下:
通过parse_one方法得到了所有课程的m3u8以及课程名,通过字典的形式进行存储,然后把得到的字典传递给下一个方法
def parse_one(self):
'''
:return: url_list:所有课程的m3u8 url
name_list:所有课程的名字
'''
url_list=[]
name_list=[]
html=requests.get(url=self.url,headers=self.headers).text
dit_message=json.loads(html)
message_list=dit_message['content']['courseSectionList']
for message in message_list:
# print(message)
for i in message['courseLessons']:
if i['videoMediaDTO'] ==None:
pass
else:
url_list.append(i['videoMediaDTO']['fileUrl'])
name_list.append(i['theme'])
#将两个列表合并成一个字典,每个m3u8对应一个name
m3u8_dict=dict(zip(url_list,name_list))
# print(m3u8_dic)
self.get_key(m3u8_dict) #返回所有课程的m3u8以及课程名
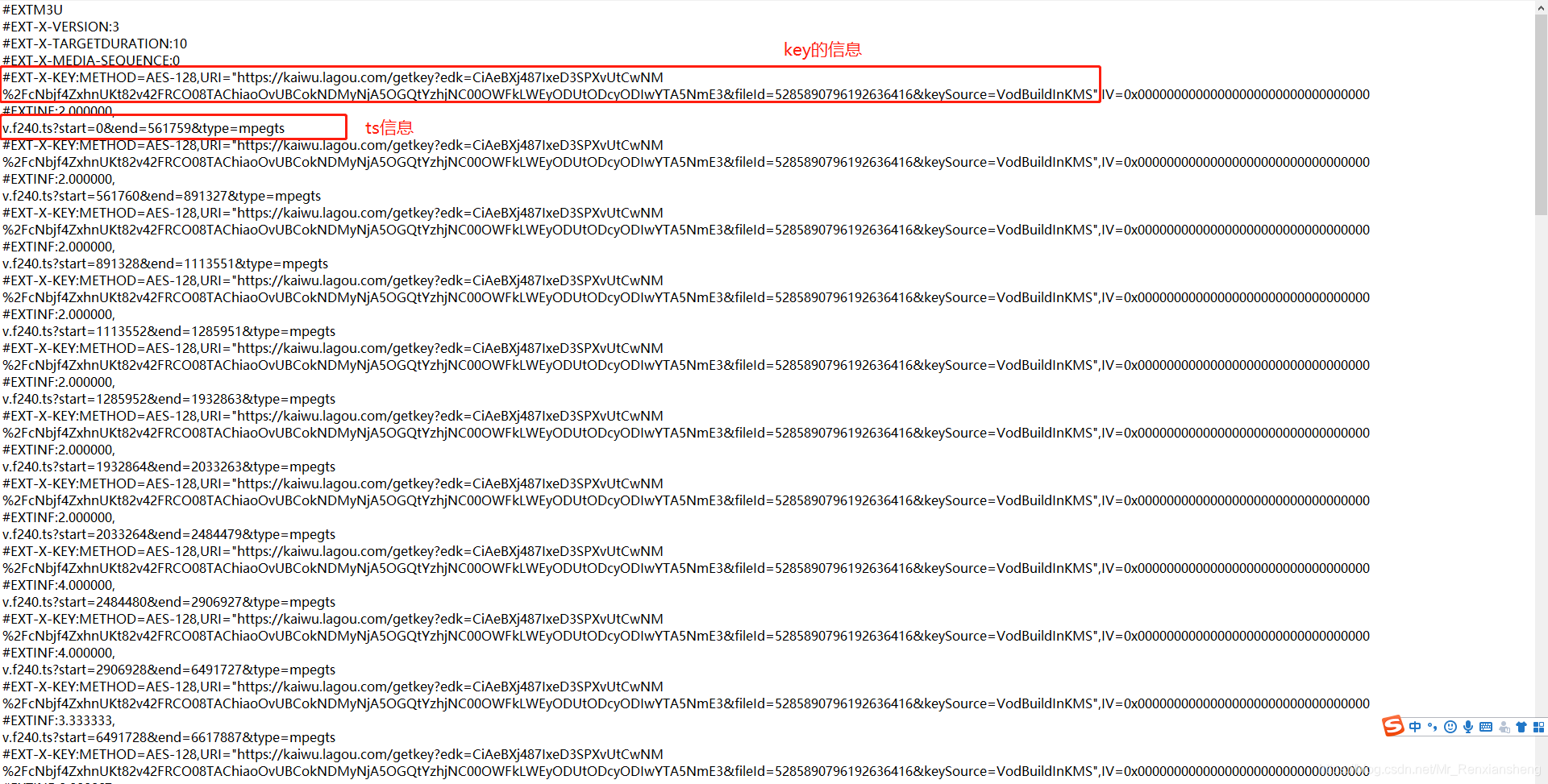
4、拿到了m3u8的url后,就可以通过同样的方式发送请求,可以从此请求中获取ts 以及key相关的信息
请求发送后得到下面这些信息(只截取了一部分)
我们要做的是从下面这些信息中拿到key(key的url已经找到了,通过requests发送请求即可得到真正的key)以及所有ts的url(这里ts的url只给出了部分需要自己拼接,用发送请求的url进行拼接)具体代码如下:
def get_key(self,m3u8_dict):
global key
ts_list=[]
for k in m3u8_dict:
url_list=k.split('.')[0:-2]
str_url='.'.join(url_list)
true_url=str_url.split('/')[0:-1]
t_url='/'.join(true_url) #拼接ts的url前面部分
html = requests.get(url=k, headers=self.headers).text #请求返回包含ts以及key数据
time.sleep(1)
message=html.split('\n') #获取key以及ts的url
name=m3u8_dict[k]
for i in message:
if 'URI' in i:
key_url=i.split(',')[1].split('"')[1]
key = requests.get(url=key_url, headers=self.headers).content
# print(i)
if 'v.f240.ts?'in i:
ts_url=t_url+'/'+i
# print(ts_url)
# print(key)
self.write(key,ts_url,name)
代码解读:(对响应回来的数据进行各种切割拼接的操作以得到真正有用的内容)
1、遍历上一个请求穿过来的字典,k是m3u8的url,通过这个url可以拼接出ts真正的url
2、获取key
3、将key,ts的url以及课程的名字传递给下一个方法
5、发送请求写入数据
这个步骤中在写入的过程需要进行解密
def write(self,key,ts_url,name):
# print(key)
cryptor = AES.new(key, AES.MODE_CBC, iv=key)
if os.path.exists('{}.mp4'.format(name)):
pass
else:
with open('{}.mp4'.format(name),'ab')as f:
html=requests.get(url=ts_url,headers=self.headers).content
time.sleep(1)
f.write(cryptor.decrypt(html))
print('{}爬取完毕'.format(name)+'对应的key是{}'.format(key))
这里我进行了一些判断(之前有一次爬取时到一半远程主机断开了连接,怀疑是被检测到了)如果课程视频文件已经在本地了,那么下次爬取将会从这个课程之后进行爬取
解密的部分就不再赘述了,基本上都是这么个格式…
总结
课程视频虽然能够爬取下来了,但是目前这个代码还是有很多可以优化的地方,比如
1、可以使用多线程的方式提高爬取的效率(大饼不是很着急,放在后台慢慢爬也能接受)
2、key的部分发送了很多重复的请求,每个m3u8中的key是一样的所以每个m3u8只要获取一次key就可以了
有空的时候会再对其进行适当的优化
写在最后
这个视频爬虫基本上就是这样了,属于非常基础的爬虫,适合跟大饼类似的爬虫基础玩家阅读,同时非常欢迎大佬莅临,要是能传授几招就更好了,哈哈哈!!!(想的略多…)
多线程版本
爬取视频
import threading
from queue import Queue
import re
import requests
import json
from Crypto.Cipher import AES
import time
import os
import pdfkit
class LaGou_spider():
def __init__(self,url):
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Cookie': 'cookie信息',
'Referer': 'https://kaiwu.lagou.com/course/courseInfo.htm?courseId=17',
'Origin': 'https://kaiwu.lagou.com',
'Sec-fetch-dest': 'empty',
'Sec-fetch-mode': 'cors',
'Sec-fetch-site': 'same-site',
'x-l-req-header': '{deviceType:1}'}
# self.url='https://gate.lagou.com/v1/neirong/kaiwu/getCourseLessons?courseId=46'
self.queue = Queue() # 初始化一个队列
self.error_queue = Queue()
def get_id(self):
ture_url_list=[]
html = requests.get(url=self.url, headers=self.headers).text
dit_message = json.loads(html)
message_list = dit_message['content']['courseSectionList']
for message in message_list:
id1=message["courseLessons"]
for t_id in id1:
ture_url="https://gate.lagou.com/v1/neirong/kaiwu/getCourseLessonDetail?lessonId={}".format(t_id["id"])
ture_url_list.append(ture_url)
return ture_url_list
def parse_one(self,ture_url_list):
"""
:return:获得所有的课程url和课程名 返回一个队列(请求一次)
"""
for ture_url in ture_url_list:
# print(ture_url)
html = requests.get(url=ture_url, headers=self.headers).text
# print(html)
dit_message = json.loads(html)
message_list = dit_message['content']
# print(message_list["videoMedia"])
if message_list["videoMedia"] == None:
continue
else:
name=message_list["theme"]
m3u8=message_list["videoMedia"]["fileUrl"]
# print(m3u8)
m3u8_dict = {m3u8:name} # key为视频的url,val为视频的name
if os.path.exists("{}.mp4".format(name)):
print("{}已经存在".format(name))
pass
else:
# print(m3u8_dict)
self.queue.put(m3u8_dict) # 将每个本地不存在的视频url(m3u8)和name加入到队列中
# for message in message_list:
# # print(message)
# for i in message['courseLessons']:
# if i['videoMediaDTO'] == None:
# pass
# else:
# key = i['videoMediaDTO']['fileUrl']
# val = i['theme']
# m3u8_dict = {key: val} # key为视频的url,val为视频的name
# # print(m3u8_dict)
#
return self.queue
#
def get_key(self, **kwargs):
# global key
m3u8_dict = kwargs
# print(m3u8_dict)
for k in m3u8_dict: # 获取某个视频的url
name = ''
# print(k)
true_url = k.split('/')[0:-1]
t_url = '/'.join(true_url) # 拼接ts的url前面部分
html = requests.get(url=k, headers=self.headers).text # 请求返回包含ts以及key数据
# print(html)
message = html.split('\n') # 获取key以及ts的url
key_parse = re.compile('URI="(.*?)"')
key_list = key_parse.findall(html)
# print("密匙链接"+key_list)
# print(key_list[0])
key = requests.get(url=key_list[0],
headers=self.headers).content # 一个m3u8文件中的所有ts对应的key是同一个 发一次请求获得m3u8文件的key
# print(key)
name1 = m3u8_dict[k] # 视频的名字
# print("视频名:"+name1)
if "|" or '?' or '/' in name1:
name = name1.replace("|" , "-")
for i in message:
if '.ts' in i:
ts_url = t_url + '/' + i
# print("ts_url"+ts_url)
self.write(key, ts_url, name, m3u8_dict)
else:
name = name1
for i in message:
# print(i)
if '.ts' in i:
ts_url = t_url + '/' + i
# print(ts_url)
self.write(key, ts_url, name, m3u8_dict)
def write(self, key, ts_url, name01, m3u8_dict):
dir='D:\\video'
if not os.path.exists(dir):
os.makedirs(dir)
cryptor = AES.new(key, AES.MODE_CBC, iv=key)
with open('{}\\{}.mp4'.format(dir,name01), 'ab')as f:
try:
html = requests.get(url=ts_url, headers=self.headers).content
f.write(cryptor.decrypt(html))
print('{},{}写入成功'.format(ts_url, name01))
except Exception as e:
print('{}爬取出错'.format(name01))
while True:
if f.close(): # 检查这个出问题的文件是否关闭 闭关则删除然后重新爬取,没关闭则等待10s,直到该文件被删除并重新爬取为止
os.remove('{}.mp4'.format(name01))
print('{}删除成功'.format(name01))
thread = self.thread_method(self.get_key, m3u8_dict)
print("开启线程{},{}重新爬取".format(thread.getName(), name01))
thread.start()
thread.join()
break
else:
time.sleep(10)
def thread_method(self, method, value): # 创建线程方法
thread = threading.Thread(target=method, kwargs=value)
return thread
def main(self):
global m3u8
thread_list = []
ture_url_list=self.get_id()
m3u8_dict = self.parse_one(ture_url_list)
while not m3u8_dict.empty():
for i in range(5): # 创建线程并启动
if not m3u8_dict.empty():
m3u8 = m3u8_dict.get()
# print(type(m3u8))
thread = self.thread_method(self.get_key, m3u8)
thread.start()
print(thread.getName() + '启动成功,{}'.format(m3u8))
time.sleep(1)
thread_list.append(thread)
else:
break
for k in thread_list:
k.join() # 回收线程
if __name__ == "__main__":
run = LaGou_spider()
# run.get_id()
time1 = time.time()
run.main()
time2 = time.time()
print(time2 - time1)
爬取文章
import threading
from queue import Queue
import requests
import json
import time
import pdfkit
class LaGou_Article_Spider():
def __init__(self,url):
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Cookie': 'cookie信息',
'Referer': 'https://kaiwu.lagou.com/course/courseInfo.htm?courseId=17',
'Origin': 'https://kaiwu.lagou.com',
'Sec-fetch-dest': 'empty',
'Sec-fetch-mode': 'cors',
'Sec-fetch-site': 'same-site',
'x-l-req-header': '{deviceType:1}'}
self.textUrl='https://gate.lagou.com/v1/neirong/kaiwu/getCourseLessonDetail?lessonId=' #发现课程文章html的请求url前面都是一样的最后的id不同而已
self.queue = Queue() # 初始化一个队列
self.error_queue = Queue()
def parse_one(self):
"""
:return:获取文章html的url
"""
# id_list=[]
html = requests.get(url=self.url, headers=self.headers).text
dit_message = json.loads(html)
message_list = dit_message['content']['courseSectionList']
# print(message_list)
for message in message_list:
for i in message['courseLessons']:
true_url=self.textUrl+str(i['id'])
self.queue.put(true_url)#文章的请求url
return self.queue
def get_html(self,true_url):
"""
:return:返回一个Str 类型的html
"""
global article_name
html=requests.get(url=true_url,timeout=10,headers=self.headers).text
dit_message = json.loads(html)
str_html=str(dit_message['content']['textContent'])
article_name1=dit_message['content']['theme']
if "|" or '?' or '/' in article_name1:
article_name=article_name1.replace("|"and'?'and'/', "-")
else:
article_name=article_name1
self.htmltopdf(str_html,article_name)
def htmltopdf(self,str_html,article_name):
path_wk = r'D:\wkhtmltox-0.12.6-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf=path_wk)
options = {
'page-size': 'Letter',
'encoding': 'UTF-8',
'custom-header': [('Accept-Encoding', 'gzip')]
}
pdfkit.from_string(str_html,"D:\\video\\{}.pdf".format(article_name),configuration=config,options=options)
def thread_method(self, method, value): # 创建线程方法
thread = threading.Thread(target=method, args=value)
return thread
def main(self):
thread_list = []
true_url= self.parse_one()
while not true_url.empty():
for i in range(10): # 创建线程并启动
if not true_url.empty():
m3u8 = true_url.get()
print(m3u8)
thread = self.thread_method(self.get_html, (m3u8,))
thread.start()
print(thread.getName() + '启动成功,{}'.format(m3u8))
thread_list.append(thread)
else:
break
while len(thread_list)!=0:
for k in thread_list:
k.join() # 回收线程
print('{}线程回收完毕'.format(k))
thread_list.remove(k)
if __name__ =="__main__":
run = LaGou_spider('faklf')
run.main()
整合视频和文章
from LaGou_spider import LaGou_Article_Spider
from LaGou_spider import LaGou_spider
print("请输入课程编号:")
number=int(input())
url='https://gate.lagou.com/v1/neirong/kaiwu/getCourseLessons?courseId={}'.format(number)
video=LaGou_spider.LaGou_spider(url)
video.main()
article=LaGou_Article_Spider.LaGou_Article_Spider(url)
article.main()
使用方法:
1、启动整合视频和文章
2、输入课程ID(课程ID在进入课程页面时可以从url处得到)
3、自动下载视频和文章(文章会保存成PDF)
(不一定所有的课程都能爬取成功…,且爬且珍惜,该教程主要用于学习交流)
代码非最优…凑合能用,比起之前的版本速度提升了很多,可根据自己电脑的性能以及网速多起几个线程…大饼起了10个线程,视屏应该是4.27G,用了10分钟左右,还能接受!
改良点:
爬取的过程中进行了判断,有时爬取速度过快远程主机会断开连接,当远程主机断开连接后,程序会报错,这时捕获这个异常,然后删除这个爬取了一半的文件,再起一个线程重新爬取这个视频,这样以来只要出错,后续依然会爬取这个文件,直到全部爬取成功为止…实现真正的自动爬取所有视频
(大饼可能人品比较好在测试的过程中并未出现上述情况,所以该功能还有待验证)
最后慢就是快,莫贪…
cooike部分需要自己添加

















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









