







 本文介绍了基于THUCNews数据集的中文文本分类任务,详细描述了数据预处理流程,包括中文分词、停用词处理及TF-IDF特征提取,并采用贝叶斯模型进行分类,最后展示了模型评估结果。
本文介绍了基于THUCNews数据集的中文文本分类任务,详细描述了数据预处理流程,包括中文分词、停用词处理及TF-IDF特征提取,并采用贝叶斯模型进行分类,最后展示了模型评估结果。
THUCNews数据集
数据集背景
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。清华大学自然语言处理实验室在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。数据集介绍转自:THUCTC: 一个高效的中文文本分类工具包。本文采用了清华NLP组提供的THUCNews新闻文本分类数据集的子集,该数据集使用了其中的10个分类,每个分类6500条,总共65000条新闻数据。
数据集下载
- 官方链接:THUCTC: 一个高效的中文文本分类工具包,提供个人信息后即可下载;
- 共享下载链接:下载链接1(提取码:5e76),下载链接2(提取码:qfud);
数据集介绍
本文采用了清华NLP组提供的THUCNews新闻文本分类数据集的子集,数据集共有4个文件,具体如下:
cnews.train.txt:训练集(10*5000,一共50000条数据)cnews.test.txt:测试集(10*1000,共10000条数据)cnews.test.txt:验证集(10*500,共5000条数据)cnews.vocab.txt:停用词表(共5000条数据)
数据预处理
数据导入
import pandas as pd
# 数据加载
train_df = pd.read_csv("./data/cnews.train.txt", sep='\t', names=['label', 'content'])
test_df = pd.read_csv("./data/cnews.test.txt", sep='\t', names=['label', 'content'])
print(train_df.info())
print(test_df.info())
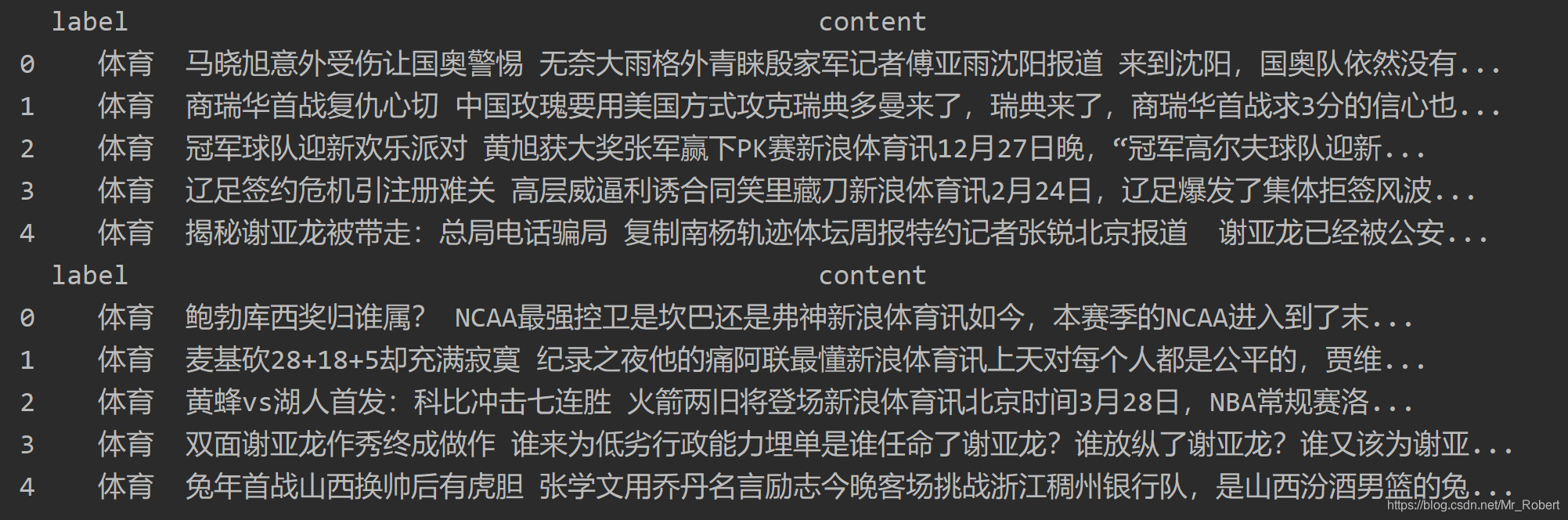
print(train_df.head(5))
print(test_df.head(5))
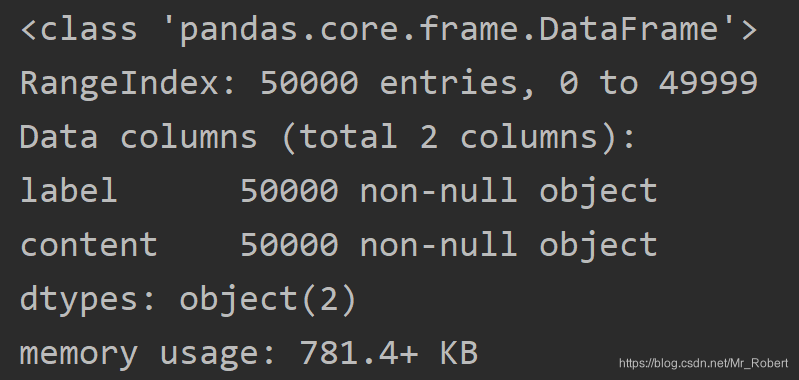
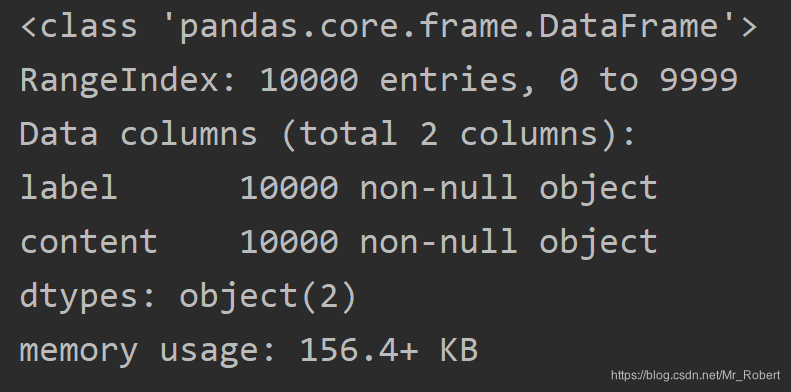
训练集和测试集的前5个数据样本信息具体如下:
中文分词、去停用词
import jieba
X_train = train_df['content']
y_train = train_df['label']
X_test = test_df['content']
y_test = test_df['label']
# 数据预处理
def cut_content(data):
"""
利用jieba工具进行中文分词
:param data: 数据
:return:
"""
words = data.apply(lambda x: ' '.join(jieba.cut(x)))
return words
# 加载停用词表
stopwords_file = open('./data/cnews.vocab.txt', encoding='utf-8')
stopwords_list = stopwords_file.readlines()
stopwords = [x.strip() for x in stopwords_list]
特征工程
TF-IDF提取特征
from sklearn.feature_extraction.text import TfidfVectorizer
# TF-IDF提取特征
tfidf_vector = TfidfVectorizer(stop_words=stopwords, max_features=5000, lowercase=False, sublinear_tf=True, max_df=0.8)
tfidf_vector.fit(cut_content(X_train))
X_train_tfidf = tfidf_vector.transform(cut_content(X_train))
X_test_tfidf = tfidf_vector.transform(cut_content(X_test))
print(X_train_tfidf.shape) # (50000, 5000)
print(X_test_tfidf.shape) # (10000, 5000)
卡方统计量进行特征选择
from sklearn.feature_selection import SelectKBest, chi2
# 利用卡方统计量进行特征选择
selector = SelectKBest(chi2, k=3000)
X_train_tfidf_chi = selector.fit_transform(X_train_tfidf, y_train)
X_test_tfidf_chi = selector.transform(X_test_tfidf)
print(X_train_tfidf_chi.shape) # (50000, 3000)
print(X_test_tfidf_chi.shape) # (10000, 3000)
模型训练:贝叶斯模型
from sklearn.naive_bayes import MultinomialNB
clf_nb = MultinomialNB(alpha=0.2) # 模型参数可以根据分类结果进行调优
# 使用TF-IDF作为特征向量
clf_nb.fit(X_train_tfidf, y_train) # 模型训练
y_pred = clf_nb.predict(X_test_tfidf) # 模型预测
# 使用TF-IDF+chi作为特征向量
clf_nb.fit(X_train_tfidf_chi, y_train) # 模型训练
y_pred_chi = clf_nb.predict(X_test_tfidf_chi) # 模型预测
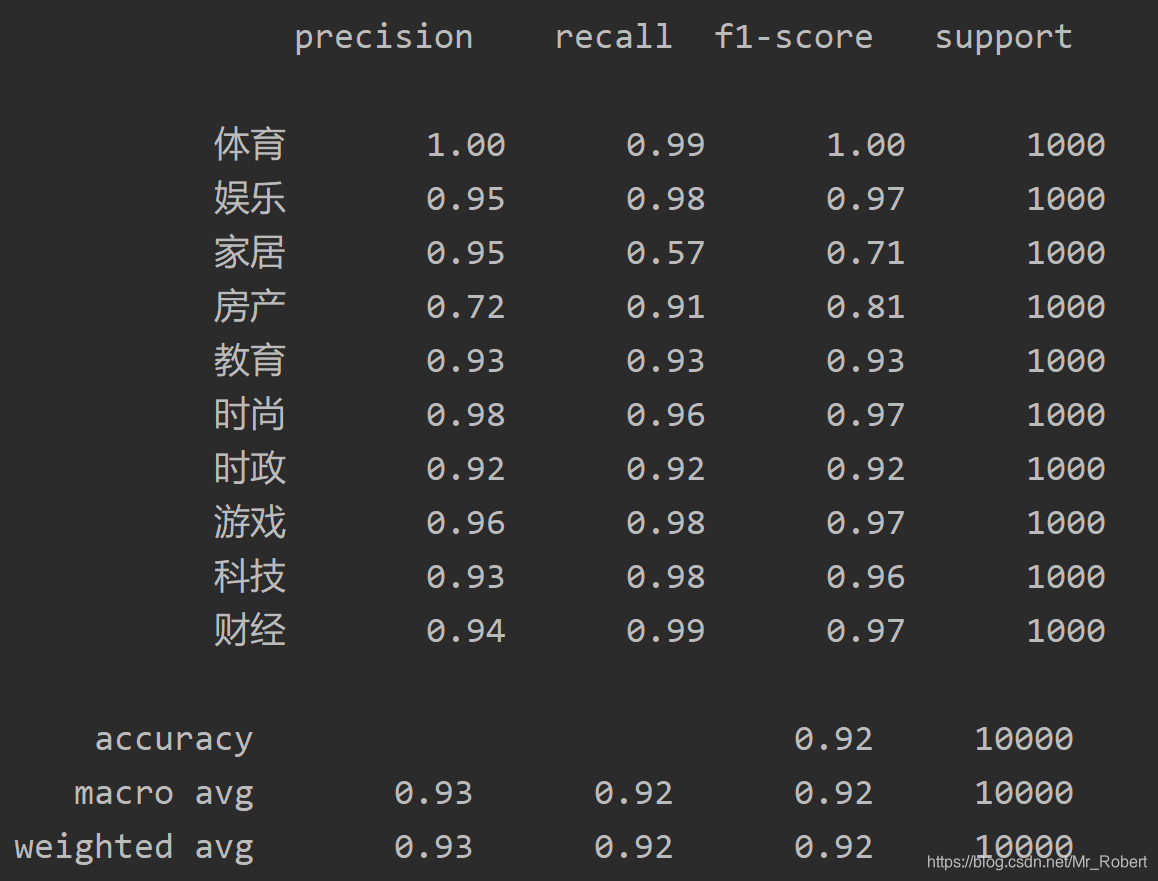
模型评估
from sklearn.metrics import classification_report, confusion_matrix
# 测试集准确率
print(clf_nb.score(X_test_tfidf, y_test)) # 0.9177
print(clf_nb.score(X_test_tfidf_chi, y_test)) # 0.9226
# 查看各类指标
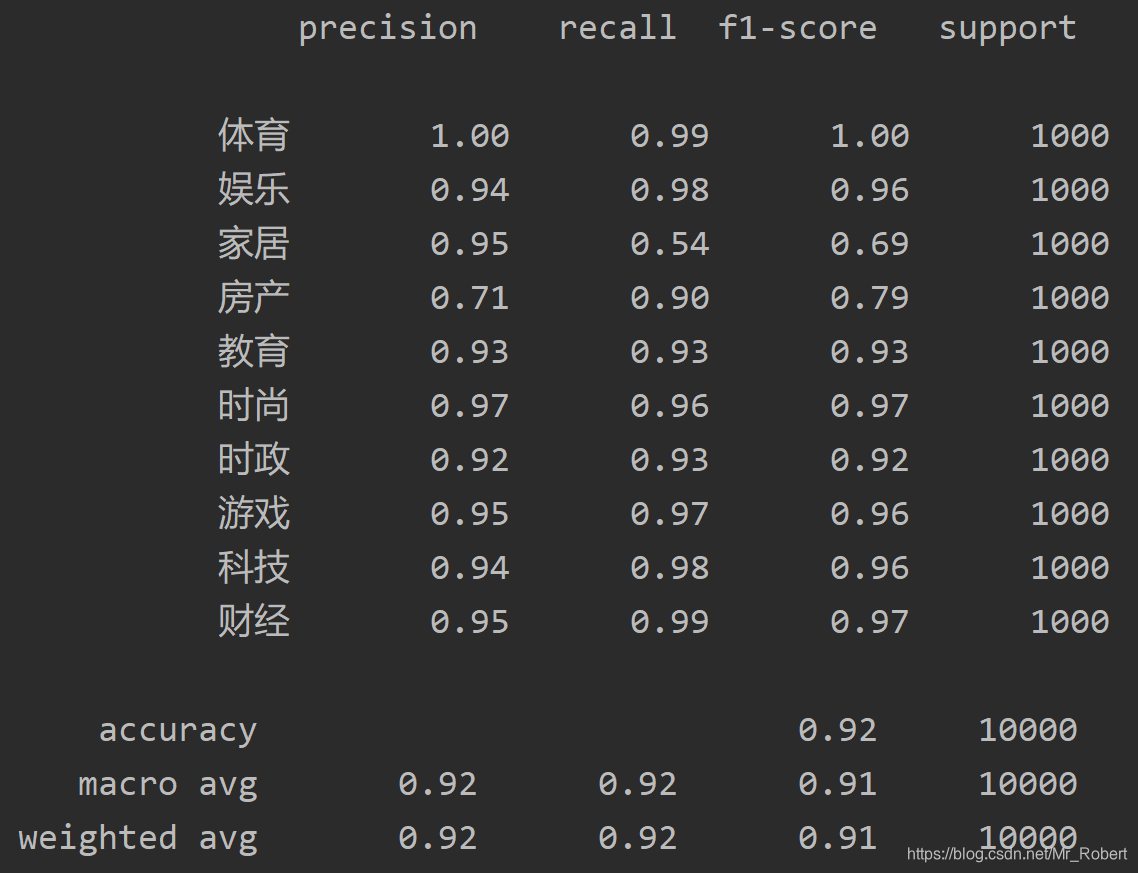
print(classification_report(y_test, y_pred))
print(classification_report(y_test, y_pred_chi))
# 查看混淆矩阵
print(confusion_matrix(y_test, y_pred))
print(confusion_matrix(y_test, y_pred_chi))

















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









