







视频教程在Pytorch框架Profiling调优命令行实战_哔哩哔哩_bilibili
一、MindStudio介绍
MindStudio为用户提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。通过依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助用户在一个工具上就能高效便捷地完成AI应用开发。另一方面,MindStudio采用插件化扩展机制,以支持开发者通过开发插件来扩展已有功能。在本案例中所使用的MindStudio版本为5.0.RC1,具体安装流程可参考MindStudio安装教程(https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000002.html)。
具体的,MindStudio的功能包括:
- 针对安装与部署,MindStudio提供多种部署方式,支持多种主流操作系统,为开发者提供最大便利。
- 针对网络模型的开发,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型训练,支持多种主流框架的模型转换。集成了训练可视化、脚本转换、模型转换、精度比对等工具,提升了网络模型移植、分析和优化的效率。
- 针对算子开发,MindStudio提供包含UT测试、ST测试、TIK算子调试等的全套算子开发流程。支持TensorFlow、PyTorch、MindSpore等多种主流框架的TBE和AI CPU自定义算子开发。
- 针对应用开发,MindStudio集成了Profiling性能调优、编译器、MindX SDK的应用开发、可视化pipeline业务流编排等工具,为开发者提供了图形化的集成开发环境,通过MindStudio可以进行工程管理、编译、调试、性能分析等全流程开发,可以很大程度提高开发效率。
MindStudio功能框架如图1所示,目前含有的工具链包括:模型转换工具、模型训练工具、自定义算子开发工具、应用开发工具、工程管理工具、编译工具、流程编排工具、精度比对工具、日志管理工具、性能分析工具、设备管理工具等多种工具。
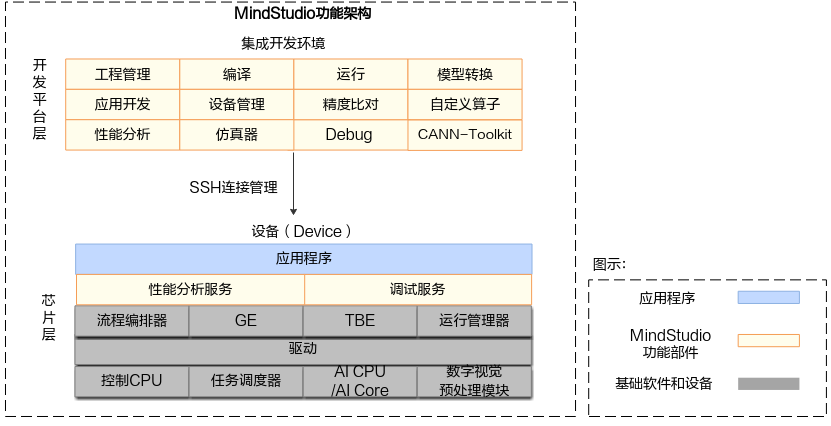
图1
- MindStudio工具中的主要功能特性:
- 工程管理:为开发人员提供创建工程、打开工程、关闭工程、删除工程、新增工程文件目录和属性设置等功能。
- SSH管理:为开发人员提供新增SSH连接、删除SSH连接、修改SSH连接、加密SSH密码和修改SSH密码保存方式等功能。
- 应用开发:针对业务流程开发人员,MindStudio工具提供基于AscendCL(Ascend Computing Language)和集成MindX SDK的应用开发编程方式,编程后的编译、运行、结果显示等一站式服务让流程开发更加智能化,可以让开发者快速上手。
- 自定义算子开发:提供了基于TBE和AI CPU的算子编程开发的集成开发环境,让不同平台下的算子移植更加便捷,适配昇腾AI处理器的速度更快。
- 离线模型转换:训练好的第三方网络模型可以直接通过离线模型工具导入并转换成离线模型,并可一键式自动生成模型接口,方便开发者基于模型接口进行编程,同时也提供了离线模型的可视化功能。
- 日志管理:MindStudio为昇腾AI处理器提供了覆盖全系统的日志收集与日志分析解决方案,提升运行时算法问题的定位效率。提供了统一形式的跨平台日志可视化分析能力及运行时诊断能力,提升日志分析系统的易用性。
- 性能分析:MindStudio以图形界面呈现方式,实现针对主机和设备上多节点、多模块异构体系的高效、易用、可灵活扩展的系统化性能分析,以及针对昇腾AI处理器的性能和功耗的同步分析,满足算法优化对系统性能分析的需求。
- 设备管理:MindStudio提供设备管理工具,实现对连接到主机上的设备的管理功能。
- 精度比对:可以用来比对自有模型算子的运算结果与Caffe、TensorFlow、ONNX标准算子的运算结果,以便用来确认神经网络运算误差发生的原因。
- 开发工具包的安装与管理:为开发者提供基于昇腾AI处理器的相关算法开发套件包Ascend-cann-toolkit,旨在帮助开发者进行快速、高效的人工智能算法开发。开发者可以将开发套件包安装到MindStudio上,使用MindStudio进行快速开发。Ascend-cann-toolkit包含了基于昇腾AI处理器开发依赖的头文件和库文件、编译工具链、调优工具等。
二、Profiling基本介绍
Profiling作为专业的昇腾AI任务性能调优工具,其功能涵盖AI任务运行时关键数据采集和性能指标分析。
具体的,Profiling实现了Host+Device侧丰富的性能数据采集能力和全景Timeline交互分析能力,展示Host+Device侧各项性能指标,帮助用户快速发现和定位AI应用的性能瓶颈,包括资源瓶颈导致的AI算法短板,指导算法性能提升和系统资源利用率的优化。同时,Profiling还支持Host+Device侧的资源利用可视化统计分析,具体包括Host侧CPU、Memory、Disk、Network利用率和Device侧APP工程的硬件和软件性能数据。
Profiling的使用包括三个步骤:首先采集性能数据;接着解析性能数据,并分析性能瓶颈;最后解决性能瓶颈后重新采集、解析并分析性能是否提升。
针对开发者的差异化需求,Profiling提供了全场景下多种性能数据采集方案,包括:
- 离线推理场景:msprof命令行方式、AscendCL API方式、pyACL API方式、acl.json配置文件方式;
- 训练/在线推理场景:msprof命令行方式、Ascend Graph API方式、环境变量方式、TensorFlow框架方式。
msprof命令行工具不仅可以解析采集到的性能数据,也提供了完整性能数据采集能力(更多的数据类型)。因此官方推荐使用msprof命令行工具完成性能调优全过程。
除msprof命令行工具外,Profiling的其他数据采集方案也有各自的特点:
- API方式:AscendCL API方式是最灵活的Profiling数据采集方案,提供定制化的性能数据采集能力。pyACL API方式是AscendCL API方式的Python封装版本,其中AscendCL API和pyACL API都是仅支持离线推理场景且需要在应用程序中调用Profiling相关接口。Ascend Graph API方式是昇腾Graph开发时使用的,其仅支持训练和在线推理场景且需要在Ascend Graph编程中调用Profiling相关接口。
- Acl.json配置文件方式:配置文件方式,支持Profiling与其他组件的统一配置。其仅支持离线推理场景且需要修改配置文件
- 环境变量方式:通过设置特定的环境变量控制Profiling,Profiling配置可以迁移到不同的训练或在线推理的环境变量脚本中执行。但其仅支持训练和在线推理场景。
- TensorFlow框架方式:基于TensorFlow框架编程时使用,其仅支持训练和在线推理场景且需要在TensorFlow框架编程时调用Profiling相关代码。
三、Profiling总体流程
Profiling总体流程如下图所示。应按流程提前准备环境、进行应用程序开发或算子开发并采集Profiling性能数据、解析Profiling性能数据。
其中msprof命令行工具方式在采集后会自动进行Profiling数据的解析,其余方式需要将采集到的数据拷贝到安装有Ascend-cann-toolkit开发套件包的环境中手动进行数据解析。

图2
- 性能数据采集:采集Profiling数据前需参见《应用软件开发指南 (C&C++)》和《TBE自定义算子开发指南》进行应用开发和算子开发,将应用软件或算子可执行文件拷贝到运行环境运行并采集Profiling数据。具体的,根据实际情况选择其中一种采集方式采集性能数据。
- Msprof命令行方式
- AscendCL API方式
- pyACL API方式
- acl.json配置文件方式
- Ascend Graph API方式
- 环境变量方式
- TensorFlow框架方式
- 解析性能数据、并分析性能瓶颈:采集到性能数据后,对性能数据进行解析,快速发现和定位AI应用、芯片及算子的性能瓶颈,包括资源瓶颈导致的AI算法短板,指导算法性能提升和系统资源利用率的优化;接着找到对应性能瓶颈的解决方案,加以完善。
- 解决性能瓶颈后重新采集、解析并分析性能是否提升:通过Profiling性能分析工具再一次采集性能数据,并对比两次解析结果分析性能是否得到提高。
四、Profiling使用约束
- 权限约束:使用Profiling功能前请确保执行用户的umask值大于等于0027,否则会导致获取的Profiling数据所在目录和文件权限过大。
- 若要查看umask的值,则执行命令:umask。
- 若要修改umask的值,则执行命令:umask 新的取值。
- 不支持在同一个Device侧同时拉起多个Profiling任务。
- Profiling功能与Dump功能不建议同时使用,即启动Profiling前,请关闭数据Dump。原因:如果同时开启,由于Dump操作会影响系统性能,会造成Profiling采集的性能数据指标不准确。
- 采集单个Profiling任务数据并落盘时,在打开所有采集项的情况下,需要保证磁盘读写速度,具体规格如下:
- 仅使用单个Device进行推理时,磁盘读写速度不低于50MB/s。
- 仅使用单个Device进行训练时,磁盘读写速度不低于60MB/s。
- 多个Device场景下,磁盘读写速度不低于:单个Device磁盘读写速度规格 * Device数。
- 采集Profiling数据过程中如果配置的落盘路径磁盘空间已满,会出现性能数据无法落盘情况,须保证足够的磁盘空间。落盘的性能原始数据需要用户自行清理,预防磁盘空间被占满(昇腾310 AI处理器);落盘的性能原始数据可以通过配置storage-limit参数来预防磁盘空间被占满(昇腾710 AI处理器)(昇腾910 AI处理器)。
- 解析Profiling数据过程中如果配置的落盘路径磁盘或用户目录空间已满,会出现解析失败的或文件无法落盘的情况,须自行清理磁盘或用户目录空间。
- Profiling工具需要配套Python版本使用,本功能要求Python3.7及以上版本。
- 应用工程开发务必遵循《应用软件开发指南 (C&C++)》手册,调用aclInit()接口完成AscendCL初始化和调用aclFinalize()接口完成AscendCL去初始化,才能获取到完整的Profiling性能数据。
- 算力分组场景下,AI Core性能指标采集项只支持采集AI任务运行性能数据(昇腾910 AI处理器)。
- 使用pyACL API开发的应用工程在通过命令行方式(msprof)采集Profiling数据时,不支持在工程Python脚本中打开相对路径文件。Python脚本中包含打开相对路径文件操作会导致采集Profiling数据报错。
五、msprof命令行工具说明及操作流程
- 基本介绍:msprof命令行工具提供了采集通用命令以及AI任务运行性能数据、昇腾AI处理器系统数据、HOST侧数据和msproftx数据性能数据的采集和解析能力。适用于推理和训练场景。
其中,采集通用命令是Profiling采集的基础,非采集项,用于提供Profiling采集时的基本信息,包括参数含义帮助、指定待采集项目AI任务文件、采集到Profiling数据的存放路径、自定义环境变量、采集到Profiling数据允许存放的文件大小等。
msprof命令行采集功能的采集功能如下:
- msprof采集通用命令:
- 命令示例:./msprof -application=/home/HwHiAiUser/HIAI_PROJECTS/MyAppname/out/main --output=/home/HwHiAiUser
- 非Ascend RC场景下,msprof会自动解析采集到的Profiling数据,并默认导出最小模型号(Model ID)的第一轮迭代数据。
表1 采集命令常用参数说明
| 参数 | 描述 | 可选/必选 |
| --help | 帮助提示参数。 | 可选 |
| --application | 配置为运行环境上AI任务文件,如:推理环境App可执行文件所在目录+文件名,例如:--application=/home/HwHiAiUser/HIAI_PROJECTS/MyAppname/out/main。 训练环境训练脚本目录+文件名,例如:--application=/home/HwHiAiUser/train/mindspore/scripts/run_standalone_train.sh。 如果“application”带参数输入,此时需要使用英文双引号将“application”的参数值括起来,例如--application="main parameters1 parameters2 parameters3 ..."。 不建议配置其他用户目录下的AI任务,避免提权风险。 | 采集全部性能数据、采集AI任务运行时性能数据或采集msproftx数据时,本参数必选;仅采集昇腾AI处理器系统数据时,本参数不选;采集Host侧性能数据时,本参数可选。 |
| --output | 收集到的Profiling数据的存放路径,默认为AI任务所在目录。 | 采集全部性能数据或采集AI任务运行时性能数据时,本参数可选; 仅采集昇腾AI处理器系统数据时,本参数必选。 |
| --environment | 执行Profiling时运行环境上需要的自定义环境变量。 配置格式为--environment="${envKey}=${envValue}"或environment="${envKey1}=${envValue1};${envKey2}=${envValue2}"。例如:--environment="LD_LIBRARY_PATH=/home/HwHiAiUser/Ascend/nnrt/latest/lib64"。 | 可选 |
| --storage-limit | 指定落盘目录允许存放的最大文件容量。当Profiling数据文件在磁盘中即将占满本参数设置的最大存储空间(剩余空间<=20MB)或剩余磁盘总空间即将被占满时(总空间剩余<=20MB),则将磁盘内最早的文件进行老化删除处理。 单位为MB,取值范围为[200, 4294967295],默认未配置本参数。参数值配置格式为数值+单位,例如--storage-limit=200MB。未配置本参数时,不开启数据老化功能。(昇腾710 AI处理器)(昇腾910 AI处理器) | 可选 |
- 采集AI任务运行性能数据
- 命令示例:./msprof --application=/home/HwHiAiUser/HIAI_PROJECTS/MyAppname/out/main --output=/home/HwHiAiUser --model-execution=on --runtime-api=on --aicpu=on # 登录运行环境并进入“msprof”工具所在目录执行以下命令
- 采集AI任务运行性能数据—application是必选项目。
- 通过--ascendcl和--runtime-api参数采集Host与Device之间、Device间的同步异步内存复制时延性能数据前,需要安装Ascend-cann-toolkit开发套件包。
- 配置采集AI任务运行时性能数据参数后生成的Profiling数据如表3和表4。
表2 参数说明
| 参数 | 描述 | 可选/必选 |
| --ascendcl | 控制acl性能数据采集的开关,可选on或off,默认为on。该参数配置前提是application参数已配置。 可采集acl性能数据,Host与Device之间、Device间的同步异步内存复制时延acl性能数据。 | 可选 |
| --model-execution | 控制ge model execution性能数据采集开关,可选on或off,默认为off。该参数配置前提是application参数已配置。 | 可选 |
| --runtime-api | 控制runtime api性能数据采集开关,可选on或off,默认为off。该参数配置前提是application参数已配置。 可采集runtime-api性能数据(不包含Host和Devise之间的数据搬运),Host与Device之间、Device间的同步异步内存复制时延runtime-api性能数据。 | 可选 |
| --hccl | 控制HCCL数据采集开关,可选on或off,默认为off。该参数配置前提是application参数已配置。 | 可选 |
| --task-time | 控制ts timeline数据(昇腾310 AI处理器)。 控制hwts log数据采集开关。(昇腾710 AI处理器)(昇腾910 AI处理器) 可选on或off,默认为on。该参数配置前提是application参数已配置。 | 可选 |
| --aicpu | 采集AICPU算子的详细信息,如:算子执行时间、数据拷贝时间等。可选on或off,默认值为off。该参数配置前提是application参数已配置。 | 可选 |
| --ai-core | 控制AI Core数据采集的开关,可选on或off,默认值为on。 | 可选 |
| --aic-mode | AI Core硬件的采集类型,可选值task-based或sample-based。 task-based是以task为粒度进行性能数据采集,sample-based是以固定的时间周期进行性能数据采集。 配置为采集AI任务运行性能数据时自动识别为task-based;配置为采集昇腾AI处理器系统数据时自动识别为sample-based。 该参数配置前提是ai-core参数设置为on。 | 可选 |
| --aic-freq | sample-based场景下的采样频率,默认值100,范围1~100,单位hz。 该参数配置前提是ai-core参数设置为on。 | 可选 |
| --aic-metrics | AI Core性能指标采集项,默认为PipeUtilization,包括ArithmeticUtilization、PipeUtilization、Memory、MemoryL0、MemoryUB、ResourceConflictRatio。以上各参数值对应的详细采集指标请参见AI Core性能指标采集项说明。 该参数配置前提是ai-core参数设置为on。 | 可选 |
| --l2 | 控制L2采样数据的开关,可选on或off,默认为off。该参数配置前提是application参数已配置。(昇腾710 AI处理器)(昇腾910 AI处理器) | 可选 |
表3 采集内容(timeline)
| timeline文件名 | 相关参数 | 说明 |
| msprof_*.json | all | timeline数据总表。对采集到的timeline性能数据按照迭代粒度进行性能展示。详情请参见timeline数据总表。 |
| ai_stack_time_*.json | --ascendcl --model-execution --runtime-api --task-time 以上参数至少开启一个。 | 各个组件(AscendCL,GE,Runtime,Task Scheduler)的耗时。详情请参见AscendCL、GE、Runtime、Task Schduler组件耗时数据概览。 |
| thread_group_*.json | --ascendcl --model-execution --runtime-api 以上参数可选。 | AscendCL,GE,Runtime组件耗时数据。该文件内的各组件数据按照线程(Thread)粒度进行排列,方便查看各线程下各组件的耗时数据。当模型为动态Shape时自动采集并生成该文件。文件详情请参见AscendCL、GE、Runtime组件耗时完整数据(按线程粒度展示)。 |
| task_time_*.json | --task-time | Task Scheduler任务调度信息。文件详情请参见Task Scheduler任务调度信息数据。 |
| acl_*.json | --ascendcl | AscendCL接口耗时数据,生成该文件需要采集的Profiling数据中包含AclModule.开头的文件。文件详情请参见AscendCL接口耗时数据。 |
| runtime_api_*.json | --runtime-api | Runtime接口耗时数据。文件详情请参见Runtime接口耗时数据。 |
| ge_*.json | --model-execution | GE接口耗时数据。文件详情请参见GE接口耗时数据。 |
| ge_op_execute_*.json | - | 算子下发各阶段耗时数据。当模型为动态Shape时自动采集并生成该文件。文件详情请参见算子下发各阶段耗时数据。 |
| step_trace_*.json | - | 迭代轨迹数据,每轮迭代的耗时。文件详情请参见迭代轨迹数据。 |
| hccl_*.json | --hccl | HCCL数据。文件详情请参见HCCL数据。 |
| 注:“*”表示{device_id}_{model_id}_{iter_id},其中{device_id}表示设备ID,{model_id}表示模型ID,{iter_id}表示某轮迭代的ID号。这些字段可以使用数据解析与导出完成数据解析后,使用数据解析与导出中的“查询Profiling数据文件信息查询功能”对结果文件进行查询得出,若查询某些字段显示为N/A(为空)则在导出的结果文件名中不展示。 | ||
表4 采集内容(summary)
| summary文件名 | 相关参数 | 说明 |
| acl_*.csv | --ascendcl | AscendCL接口的耗时。详情请参见AscendCL接口耗时数据。 |
| acl_statistic_*.csv | --ascendcl | AscendCL接口调用次数及耗时。详情请参见AscendCL接口调用次数及耗时数据。 |
| op_summary_*.csv | --task-time(可选) --ai-core(可选) --aic-metrics(可选) --aicpu(可选) 配置--task-time、--ai-core和--aic-metrics生成AI Core算子信息;配置--aicpu生成AI CPU算子信息。 | AI Core数据,获取每个task的ai core metrics的耗时。详情请参见AI Core数据。 |
| op_statistic_*.csv | --task-time(可选) --ai-core(可选) --aic-metrics(可选) --aicpu(可选) 配置--task-time、--ai-core和--aic-metrics生成AI Core算子信息;配置--aicpu生成AI CPU算子信息。 | AI Core算子调用次数及耗时,从算子类型维度找出耗时最大的算子类型。详情请参见AI Core算子调用次数及耗时数据。 |
| step_trace_*.csv | - | 迭代轨迹数据。文件详情请参见迭代轨迹数据。 |
| ai_stack_time_*.csv | --ascendcl --model-execution --runtime-api --task-time 以上四个参数至少开启一个。 | 每个组件(AscendCL,GE,Runtime,Task Scheduler)的耗时。详情请参见各个组件的耗时数据。 |
| runtime_api_*.csv | --runtime-api | 每个runtime api的调用时长。详情请参见Runtime接口耗时数据。 |
| fusion_op_*.csv | - | 模型中算子融合前后信息。详情请参见模型中算子融合前后信息数据。 |
| ge_op_execute_*.csv | - | 算子下发各阶段耗时数据。当模型为动态Shape时自动采集并生成该文件。文件详情请参见算子下发各阶段耗时数据。 |
| task_time_*.csv | --task-time | Task Scheduler的任务调度信息数据。详情请参见: |
| aicpu_*.csv | --aicpu | AI CPU数据。文件详情请参见AI CPU数据。 |
| l2_cache_*.csv | --l2 | L2Cache数据。详情请参见L2Cache数据(昇腾710 AI处理器)(昇腾910 AI处理器)。 |
| prof_rule_0.json | - | 调优建议。无需指定Profiling参数自动生成,完成后打屏显示结果,详细介绍请参见性能调优建议。 |
| 注:“*”表示{device_id}_{model_id}_{iter_id},其中{device_id}表示设备ID,{model_id}表示模型ID,{iter_id}表示某轮迭代的ID号。这些字段可以使用数据解析与导出完成数据解析后,使用数据解析与导出中的“查询Profiling数据文件信息查询功能”对结果文件进行查询得出,若查询某些字段显示为N/A(为空)则在导出的结果文件名中不展示。 | ||
- 采集昇腾AI处理器系统数据
- 命令示例:./msprof --output=/home/HwHiAiUser --sys-devices=<ID> --sys-period=<period> --sys-hardware-mem=on # 登录运行环境并进入“msprof”工具所在目录执行以下命令。
- 采集昇腾AI处理器系统数据--application参数不选,且—output是必选项目。
- 不指定--application参数时,为仅采集昇腾AI处理器系统数据;也可以同时指定--application参数和其他参数及昇腾AI处理器系统数据参数,同时采集这些数据,此时--sys-period和--sys-devices参数无需配置。
- Ascend EP场景下,使用msprof命令行方式采集整网推理Profiling数据时,通过配置--llc-profiling、--sys-cpu-profiling、--sys-profiling和--sys-pid-profiling采集项采集相应数据,采集完成后,除--sys-cpu-profiling采集项仅生成TS CPU数据外,其余采集项均不会生成数据;但在不配置--application参数时,配置上述几个采集项均会有数据生成。
- 配置采集昇腾AI处理器系统数据参数后生成的Profiling数据如表6和表7。
表5 参数说明
| 参数 | 描述 | 可选/必选 |
| --sys-period | 系统的采样时长,取值范围大于0,上限为30*24*3600,单位s。 | 必选 |
| --sys-devices | 设备ID。可以为all或多个设备ID(以逗号分隔)。 | 必选 |
| --ai-core | 控制AI Core数据采集的开关,可选on或off,默认值为off。 | 可选 |
| --aic-mode | AI Core硬件的采集类型,可选值task-based或sample-based,默认task-based。task-based是以task为粒度进行性能数据采集,sample-based是以固定的时间周期进行性能数据采集。 该参数配置前提是ai-core参数设置为on。 | 可选 |
| --aic-freq | sample-based场景下的采样频率,默认值100,范围1~100,单位hz。 该参数配置前提是ai-core参数设置为on。 | 可选 |
| --aic-metrics | AI Core性能指标采集项,默认为PipeUtilization,包括ArithmeticUtilization、PipeUtilization、Memory、MemoryL0、MemoryUB、ResourceConflictRatio。以上各参数值对应的详细采集指标请参见AI Core性能指标采集项说明。 该参数配置前提是ai-core参数设置为on。 | 可选 |
| --sys-hardware-mem | 控制DDR,HBM(昇腾910 AI处理器),LLC的读写带宽数据采集开关,可选on或off,默认为off。 | 可选 |
| --sys-hardware-mem-freq | DDR,HBM(昇腾910 AI处理器),LLC的读写带宽数据采集频率,范围1~1000,默认值为50,单位hz。 设置该参数需要sys-hardware-mem参数设置为on。 | 可选 |
| --llc-profiling | LLC Profiling采集事件,可以设置为:
如要采集该数据,需要sys-hardware-mem设置为on。 | 可选 |
| --sys-cpu-profiling | CPU(AI CPU、Ctrl CPU、TS CPU)采集开关。可选on或off,默认值为off。 | 可选 |
| --sys-cpu-freq | CPU采集频率,范围1-50,默认值为50,单位hz。设置该参数需要sys-cpu-profiling参数设置为on。 | 可选 |
| --sys-profiling | 系统CPU usage及System memory采集开关。可选on或off,默认值为off。 | 可选 |
| --sys-sampling-freq | 系统CPU usage及System memory采集频率,范围1-10,默认值为10,单位hz。设置该参数需要sys-profiling参数设置为on。 | 可选 |
| --sys-pid-profiling | 进程的CPU usage及进程的memory采集开关。可选on或off,默认值为off。 | 可选 |
| --sys-pid-sampling-freq | 进程的CPU usage及进程的memory采集频率,范围1-10,默认值为10,单位hz。设置该参数需要sys-pid-profiling参数设置为on。 | 可选 |
| --sys-io-profiling | NIC(昇腾310 AI处理器)(昇腾910 AI处理器)、ROCE(昇腾910 AI处理器)采集开关。可选on或off,默认值为off。 | 可选 |
| --sys-io-sampling-freq | NIC(昇腾310 AI处理器)(昇腾910 AI处理器)、ROCE(昇腾910 AI处理器)采集频率,范围1-100,默认值为100,单位hz。设置该参数需要sys-io-profiling参数设置为on。 | 可选 |
| --sys-interconnection-profiling | PCIe采集开关,可选on或off,默认值为off。 (昇腾710 AI处理器)(昇腾910 AI处理器) | 可选 |
| --sys-interconnection-freq | PCIe采集频率,范围1-50,默认值为50,单位hz。 设置该参数需要sys-interconnection-profiling参数设置为on。 (昇腾710 AI处理器)(昇腾910 AI处理器) | 可选 |
| --dvpp-profiling | DVPP采集开关,可选on或off,默认值为off。 (昇腾310 AI处理器)(昇腾910 AI处理器) | 可选 |
| --dvpp-freq | DVPP采集频率,范围1-100,默认值为50,单位hz。 设置该参数需要dvpp-profiling参数设置为on。 (昇腾310 AI处理器)(昇腾910 AI处理器) | 可选 |
表6 采集内容(timeline)
| timeline文件名 | 相关参数 | 说明 |
| ai_core_utilization_*.json | --ai-core | 每个Core上指令占比数据,sample-based模式下才会生成。详情请参见每个Core上指令占比数据。 |
| ddr_*.json | --sys-hardware-mem | DDR内存读写速率。详情请参见DDR内存读写速率数据。 |
| hbm_*.json | --sys-hardware-mem | HBM内存读写速率。文件详情请参见HBM内存读写速率数据(昇腾910 AI处理器)。 (昇腾910 AI处理器) |
| llc_aicpu_*.json | --sys-hardware-mem --llc-profiling=capacity | AI CPU的三级缓存使用量,LLC Profiling采集事件设置为capacity时才会导出该文件。文件详情请参见AI CPU的三级缓存使用量数据(昇腾310 AI处理器)。 (昇腾310 AI处理器) |
| llc_ctrlcpu_*.json | --sys-hardware-mem --llc-profiling=capacity | Control CPU三级缓存使用量,LLC Profiling采集事件设置为capacity时才会导出该文件。文件详情请参见Control CPU三级缓存使用量数据(昇腾310 AI处理器)。 (昇腾310 AI处理器) |
| llc_bandwidth_*.json | --sys-hardware-mem --llc-profiling=bandwidth | 三级缓存带宽,LLC Profiling采集事件设置为bandwidth时才会导出该文件。文件详情请参见三级缓存带宽数据(昇腾310 AI处理器)。 (昇腾310 AI处理器) |
| llc_read_write_*.json | --sys-hardware-mem | 三级缓存读写速率数据。文件详情请参见三级缓存读写速率数据(昇腾710 AI处理器)(昇腾910 AI处理器)。 (昇腾710 AI处理器)(昇腾910 AI处理器) |
| nic_*.json | --sys-io-profiling | 每个时间节点网络信息数据。文件详情请参见每个时间节点网络信息数据(昇腾310 AI处理器)(昇腾910 AI处理器)。 (昇腾310 AI处理器)(昇腾910 AI处理器) |
| roce_*.json | --sys-io-profiling | RoCE通信接口带宽数据。文件详情请参见RoCE通信接口带宽数据(昇腾910 AI处理器)。 (昇腾910 AI处理器) |
| hccs_*.json | --sys-interconnection-profiling | 集合通信带宽数据。文件详情请参见集合通信带宽数据(昇腾910 AI处理器)。 (昇腾910 AI处理器) |
| pcie_*.json | --sys-interconnection-profiling | PCIe带宽。详情请参见PCIe带宽数据(昇腾710 AI处理器)(昇腾910 AI处理器)。 (昇腾710 AI处理器)(昇腾910 AI处理器) |
| 注:“*”表示{device_id}_{model_id}_{iter_id},其中{device_id}表示设备ID,{model_id}表示模型ID,{iter_id}表示某轮迭代的ID号。这些字段可以使用数据解析与导出完成数据解析后,使用数据解析与导出中的“查询Profiling数据文件信息查询功能”对结果文件进行查询得出,若查询某些字段显示为N/A(为空)则在导出的结果文件名中不展示。 | ||
表7 采集内容(summary)
| summary文件名 | 相关参数 | 说明 | |
| ai_core_utilization_*.csv | --ai-core --aic-mode=sample-based | 每个Core上指令占比数据。详情请参见每个Core上指令占比数据。 | |
| ddr_*.csv | --sys-hardware-mem | DDR内存读写速率。详情请参见DDR内存读写速率数据。 | |
| hbm_*.csv | --sys-hardware-mem | HBM内存读写速率,data中包含hbm.开头的文件。详情请参见HBM内存读写速率数据(昇腾910 AI处理器)。 (昇腾910 AI处理器) | |
| llc_aicpu_*.csv | --sys-hardware-mem --llc-profiling=capacity | AI CPU三级缓存使用量,LLC Profiling采集事件设置为capacity时才会导出该文件。详情请参见AI CPU三级缓存使用量数据(昇腾310 AI处理器)。 (昇腾310 AI处理器) | |
| llc_ctrlcpu_*.csv | --sys-hardware-mem --llc-profiling=capacity | Control CPU三级缓存使用量,LLC Profiling采集事件设置为capacity时才会导出该文件。详情请参见Ctrl CPU三级缓存使用量数据(昇腾310 AI处理器)。 (昇腾310 AI处理器) | |
| llc_bandwidth_*.csv | --sys-hardware-mem --llc-profiling=bandwidth | 三级缓存带宽,LLC Profiling采集事件设置为bandwidth时才会导出该文件。三级缓存带宽数据(昇腾310 AI处理器)。 (昇腾310 AI处理器) | |
| llc_read_write_*.csv | --sys-hardware-mem | 三级缓存读写速率数据。文件详情请参见三级缓存读写速率数据(昇腾710 AI处理器)(昇腾910 AI处理器)。 (昇腾710 AI处理器)(昇腾910 AI处理器) | |
| ai_cpu_top_function_*.csv | --sys-cpu-profiling | AI CPU热点函数。文件详情请参见AI CPU热点函数数据。 | |
| ai_cpu_pmu_events_*.csv | --sys-cpu-profiling | AI CPU PMU事件。文件详情请参见AI CPU PMU事件数据。 | |
| ctrl_cpu_top_function_*.csv | --sys-cpu-profiling | Ctrl CPU热点函数。文件详情请参见Ctrl CPU热点函数数据。 | |
| ctrl_cpu_pmu_events_*.csv | --sys-cpu-profiling | Ctrl CPU PMU事件。文件详情请参见Ctrl CPU PMU事件数据。 | |
| ts_cpu_top_function_*.csv | --sys-cpu-profiling | TS CPU热点函数。文件详情请参见TS CPU热点函数数据。 | |
| ts_cpu_pmu_events_*.csv | --sys-cpu-profiling | TS CPU PMU事件。文件详情请参见TS CPU PMU事件数据。 | |
| cpu_usage_*.csv | --sys-profiling | AI CPU、Control CPU利用率。文件详情请参见AI CPU、Ctrl CPU利用率数据。 | |
| sys_mem_*.csv | --sys-profiling | 指定device的内存使用情况。详情请参见系统内存数据。 | |
| process_cpu_usage_*.csv | --sys-pid-profiling | 进程CPU占用率。生成文件详情请参见进程CPU占用率数据。 | |
| process_mem_*.csv | --sys-pid-profiling | 进程内存占用率。文件详情请参见进程内存占用率数据。 | |
| nic_*.csv | --sys-io-profiling | 每个时间节点网络信息数据。文件详情请参见每个时间节点网络信息数据(昇腾310 AI处理器)(昇腾910 AI处理器)。 (昇腾310 AI处理器)(昇腾910 AI处理器) | |
| roce_*.csv | --sys-io-profiling | RoCE通信接口带宽数据。文件详情请参见RoCE通信接口带宽数据(昇腾910 AI处理器)。 (昇腾910 AI处理器) | |
| hccs_*.csv | --sys-interconnection-profiling | 集合通信带宽数据。文件详情请参见集合通信带宽数据(昇腾910 AI处理器)。 (昇腾910 AI处理器) | |
| pcie_*.csv | --sys-interconnection-profiling | PCIe带宽。详情请参见PCIe带宽数据(昇腾710 AI处理器)(昇腾910 AI处理器)。 (昇腾710 AI处理器)(昇腾910 AI处理器) | |
| dvpp_*.csv | --dvpp-profiling | DVPP数据。文件详情请参见DVPP数据(昇腾310 AI处理器)(昇腾910 AI处理器)。 (昇腾310 AI处理器)(昇腾910 AI处理器) | |
| 注:“*”表示{device_id}_{model_id}_{iter_id},其中{device_id}表示设备ID,{model_id}表示模型ID,{iter_id}表示某轮迭代的ID号。这些字段可以使用数据解析与导出完成数据解析后,使用数据解析与导出中的“查询Profiling数据文件信息查询功能”对结果文件进行查询得出,若查询某些字段显示为N/A(为空)则在导出的结果文件名中不展示。 | |||
- 采集Host侧数据
-
- 依赖AI任务运行时采集:采集Host侧数据需要确认采集的进程,因此依赖AI任务运行时的采集即对所在应用程序的进程进行采集。
- 命令示例:./msprof --application=/home/HwHiAiUser/HIAI_PROJECTS/MyAppname/out/main --output=/home/HwHiAiUser --host-sys=cpu # 登录运行环境并进入“msprof”工具所在目录执行以下命令。
- 依赖昇腾AI处理器系统采集:采集Host侧数据需要确认采集的进程,因此昇腾AI处理器系统采集需要指定采集的系统进程号。
- 命令示例:./msprof --output=/home/HwHiAiUser --sys-devices=<ID> --sys-period=<period> --sys-hardware-mem=on --host-sys-pid=<pid> --host-sys=cpu # # 登录运行环境并进入“msprof”工具所在目录执行以下命令。
-
- 采集Host侧disk性能数据需要安装第三方开源工具iotop,采集osrt性能数据需要安装第三方开源工具perf和ltrace,其安装方法参见安装perf、iotop、ltrace工具。完成安装后须参见配置用户权限完成用户权限配置,且每次重新安装CANN软件包需要重新配置。
- 使用开源工具ltrace采集osrt性能数据会导致CPU占用率过高,其与应用工程的pthread加解锁相关,会影响进程运行速度。
- KylinV10SP1操作系统下不支持--host-sys=osrt参数。
- 配置采集AI任务运行时性能数据参数后生成的Profiling数据如表9和表10。
表8 参数说明
| 参数 | 描述 | 可选/必选 |
| --host-sys | Host侧性能数据采集开关,取值包括cpu,mem,disk,network和osrt,可选其中的一项或多项,选多项时用逗号隔开。配置该项必须配置host-sys-pid 参数或application参数。各项取值含义如下:
配置示例:--host-sys=cpu,mem,disk,network。 | 必选 |
| --host-sys-pid | 指定需要采集的Host侧应用程序的pid。 依赖AI任务运行时该参数无需配置,且配置无效。 | 必选 |
表9 采集内容(timeline)
| timeline文件名 | 相关参数 | 说明 |
| host_cpu_usage.json | --host-sys=cpu | Host侧CPU利用率。详情请参见Host侧CPU利用率数据。 |
| host_mem_usage.json | --host-sys=mem | Host侧内存利用率。详情请参见Host侧内存利用率数据。 |
| host_disk_usage.json | --host-sys=disk | Host侧磁盘I/O利用率。详情请参见Host侧磁盘I/O利用率数据。 |
| host_network_usage.json | --host-sys=network | Host侧网络I/O利用率。详情请参见Host侧网络I/O利用率数据。 |
| os_runtime_api.json | --host-sys=osrt | Host侧syscall和pthreadcall数据。详情请参见Host侧syscall和pthreadcall数据。 |
表10 采集内容(summary)
| summary文件名 | 相关参数 | 说明 |
| os_runtime_statistic.csv | --host-sys=osrt | Host侧syscall和pthreadcall数据。详情请参见Host侧syscall和pthreadcall数据。 |
- 采集msproftx数据
- 使用说明:msprof tool extension,MindStudio系统调优工具扩展。当用户需要定位应用程序或上层框架程序的性能瓶颈时,可在Profiling采集进程内(aclprofStart接口、aclprofStop接口之间)调用Profiling AscendCL API扩展接口(统称为msproftx接口),开启记录应用程序执行期间特定事件发生的时间跨度,并将数据写入Profiling数据文件,再使用Profiling工具解析该文件,并导出展示性能分析数据。
- 命令实例:./msprof --application=/home/HwHiAiUser/HIAI_PROJECTS/MyAppname/out/main --msproftx=on # 登录运行环境并进入“msprof”工具所在目录执行以下命令。
表11 参数说明
| 参数 | 描述 | 可选/必选 |
| --msproftx | 控制msproftx用户和上层框架程序输出性能数据的开关,可选on或off,默认值为off。 | 必选 |
- 安装:通过可执行文件“msprof”进行数据采集Profiling性能数据。安装路径如:/home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/bin,而Ascend RC场景下路径为/var。
- msprof命令行工具使用的前提条件:
- 采集Profiling数据前,需确保编译生成的应用工程或算子工程能在运行环境中正常运行。
- 使用msprof命令行方式采集Profiling数据前请确保完成环境搭建。
- 以Ascend-cann-toolkit开发套件包的运行用户(以HwHiAiUser用户为例)登录开发/运行环境。
- 切换至“msprof”文件所在目录,如:/home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/bin,Ascend RC场景下路径为/var。
- 执行Profiling命令,采集性能数据。
六、Pytorch框架Profiling性能数据采集(msprof命令行)
在Pytorch框架下,以ResNet50网络在训练场景中性能优化分析为例,展示Pytorch框架Profiling调优命令行的性能数据采集过程。
- 启动MindStudio,单击菜单栏“Tools > Start SSH session > Select Host to Connect”,单击选择运行环境。
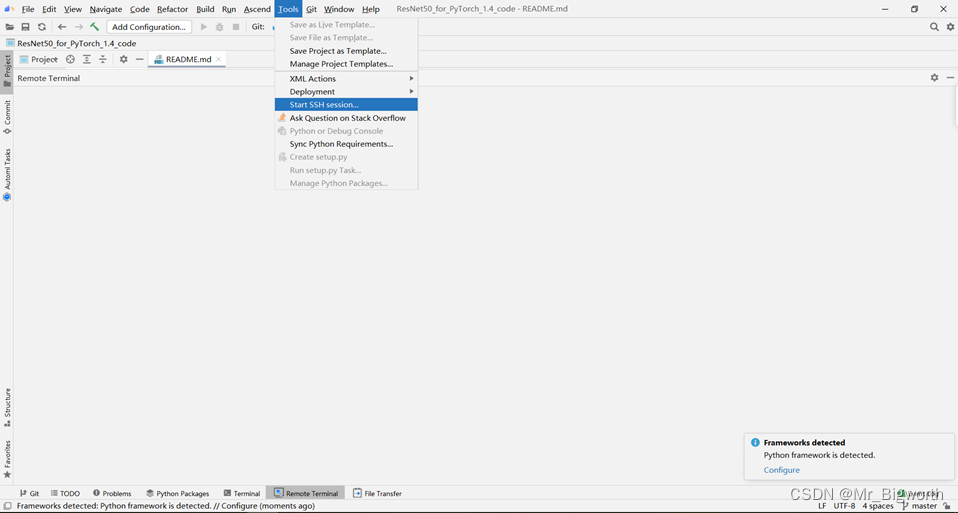
图3
- 登陆运行环境后,进入“msprof”文件所在目录,例如Ascend EP场景下路径:/home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/bin,Ascend RC场景下路径为/var

图4
- 执行Profiling命令,采集性能数据:
- 执行采集通用命令:./msprof --application=/home/HwHiAiUser/HIAI_PROJECTS/MyAppname/out/run.sh ## 其中,application参数指定的文件可以是推理场景的可执行文件,也可以是训练场景的下的训练脚本文件。 非Ascend RC场景下,msprof会自动解析采集到的Profiling数据,默认导出最小模型号(Model ID)的第一轮迭代数据。导出数据详细介绍请参见数据解析与导出。
- 其中可通过./msprof –help来获得各个参数的说明,例如--output用于收集到的Profiling数据的存放路径,默认为AI任务所在目录;--ascendcl用于显示acl性能数据;--environment用于执行Profiling时运行环境上需要的自定义环境变量等等。详细参数说明如表12所示。
表12 采集命令参数说明
| 参数 | 描述 | 可选/必选 |
| --help | 帮助提示参数。 | 可选 |
| --application | 配置为运行环境上AI任务文件,如:推理环境App可执行文件所在目录+文件名,例如:--application=/home/HwHiAiUser/HIAI_PROJECTS/MyAppname/out/main。 训练环境训练脚本目录+文件名,例如:--application=/home/HwHiAiUser/train/mindspore/scripts/run_standalone_train.sh。如果“application”带参数输入,此时需要使用英文双引号将“application”的参数值括起来,例如--application="main parameters1 parameters2 parameters3 ..."。 不建议配置其他用户目录下的AI任务,避免提权风险。 | 采集全部性能数据、采集AI任务运行时性能数据或采集msproftx数据时,本参数必选;仅采集昇腾AI处理器系统数据时,本参数不选;采集Host侧性能数据时,本参数可选。 |
| --output | 收集到的Profiling数据的存放路径,默认为AI任务所在目录。 | 采集全部性能数据或采集AI任务运行时性能数据时,本参数可选; 仅采集昇腾AI处理器系统数据时,本参数必选。 |
| --environment | 执行Profiling时运行环境上需要的自定义环境变量。 配置格式为--environment="${envKey}=${envValue}"或environment="${envKey1}=${envValue1};${envKey2}=${envValue2}"。例如:--environment="LD_LIBRARY_PATH=/home/HwHiAiUser/Ascend/nnrt/latest/lib64"。 | 可选 |
| --storage-limit | 指定落盘目录允许存放的最大文件容量。当Profiling数据文件在磁盘中即将占满本参数设置的最大存储空间(剩余空间<=20MB)或剩余磁盘总空间即将被占满时(总空间剩余<=20MB),则将磁盘内最早的文件进行老化删除处理。 单位为MB,取值范围为[200, 4294967295],默认未配置本参数。参数值配置格式为数值+单位,例如--storage-limit=200MB。未配置本参数时,不开启数据老化功能。(昇腾710 AI处理器)(昇腾910 AI处理器) | 可选 |
| --ascendcl | 显示acl的profiling数据,默认值是on | 可选 |
| --model-execution | 显示ge模型运行profiling数据,默认值是off | 可选 |
| --runtime-api | 显示runtime api的profiling数据,默认值是off | 可选 |
| --task-time | 显示任务的profiling数据,默认值是on | 可选 |
| -ai-core | 开启/关闭ai core profiling,采集app Profiling时默认开启。 | 可选 |
| --aic-mode | 将aic分析模式设置为基于任务或基于样本。 在基于任务的模式下,分析数据将按任务收集。 在基于样本的模式下,将在特定的时间间隔内收集分析数据。默认值是基于任务的。 | 可选 |
| --aic-freq | aic采样频率,以赫兹为单位,默认值为100Hz,范围为1到100Hz。 | 可选 |
| --aic-metrics | aic 指标组,包括 ArithneticUtilization、PipeUtilization、Memory、MemoryLo、ResourceConflictRatio、MenoryUB。默认值为PipeUtilization。 | 可选 |
| --sys-period | 以秒为单位设置系统分析的总采样周期。 | 可选 |
| --sys-devices | 收集sys profiling时通过设备ID指定profiling范围。取值为all或ID列表(用','分割)。 | 可选 |
| --hccl | 显示 hccl 分析数据,默认值为off。 | 可选 |
| -biu | 显示biu的profiling数据,默认值为off | 可选 |
| --biu-freq | 以时钟周期为单位的biu采样周期,默认值为1000个周期,范围为300到30000个周期。 | 可选 |
| --msproftx | 展示msproftx数据,默认值为off。 | 可选 |
| --python-path | 指定用于分析的python解释器路径,请确保python版本为3.7.5或更高版本。 | 可选 |
| --parse | 使用msprof解析采集数据的开关,默认为off。 | 可选 |
| --query | 使用msprof查询采集数据的开关,默认值为off。 | 可选 |
| --export | 使用msprof导出采集数据的开关,默认值为off。 | 可选 |
| --iteration-id | 导出迭代id,仅在打开参数导出时使用,默认值为1 | 可选 |
| --model-id | 导出模型id,仅在打开参数导出时使用,msprof将默认导出最小可访问模型。 | 可选 |
| --summary-format | 导出摘要文件格式,仅在打开参数导出时使用,包括csv、json,默认值为csv。 | 可选 |
| -aicpu | 显示 aicpu profiling数据,默认值为off。 | 可选 |
| --sys-hardware-men | LLC、DDR、HBM 采集开关。 | 可选 |
| --sys-hardware-mem-freq | LLC、DDR、HBM采集频率,范围1~1000,默认50,单位Hz。 | 可选 |
| --llc-profiling | LLc profiling组,包括读、写,默认值是read。 | 可选 |
| --sys-cpu-profiling | CPU 采集开关,可选开/关,默认值为off。 | 可选 |
| --sys-cpu-freq | 以赫兹为单位的CPU采样频率。默认值为50Hz,范围为1到50Hz。 | 可选 |
| --sys-profiling | System CPU使用率和系统内存获取开关,默认值为off。 | 可选 |
| --sys-sampling-freq | sys采样频率,以赫兹为单位。默认值为10Hz,范围为1到10Hz。 | 可选 |
| --sys-pid-profiling | 进程的CPU使用率和进程的内存获取开关,默认值为off。 | 可选 |
| --sys-pid-sampling-freq | 以赫兹为单位的pid采样频率。默认值为10Hz,范围为1到10Hz。 | 可选 |
| --sys-io-profiling | NIC、ROCE获取开关,默认值为off。 | 可选 |
| --sys-io-sampling-freq | NIC,ROCE采集频率,范围1~100,默认值为100,单位Hz。 | 可选 |
| --sys-interconnection-profiling | PCIE、HCCS采集开关,默认值为off。 | 可选 |
| --sys-interconnection-freq | PCIE,HCCS采集频率,范围1~50,默认50,单位Hz。 | 可选 |
| --dvpp-profiling | DVPP采集开关,默认为off。 | 可选 |
| --dvpp-freq | DVPP采集频率,范围1~100,默认50,单位Hz。 | 可选 |
| --l2 | L2 Cache获取开关。默认值为off。 | 可选 |
| --host-sys | host-sys数据类型,包括cpu,mem,disk,network,osrt | 可选 |
| -host-sys-pid | 设置要收集性能数据的应用进程的PID。 | 可选 |
| -help | 帮助信息 | 可选 |
- 在本案例中,执行训练场景中的ResNet训练脚本文件run_1p.sh

图5
- 采集性能数据:
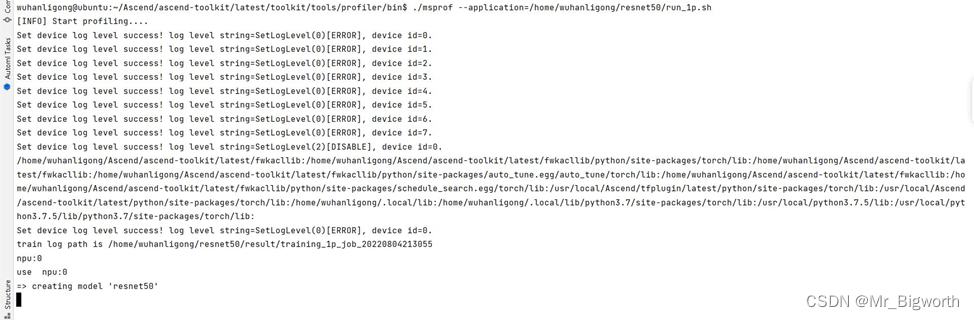
图6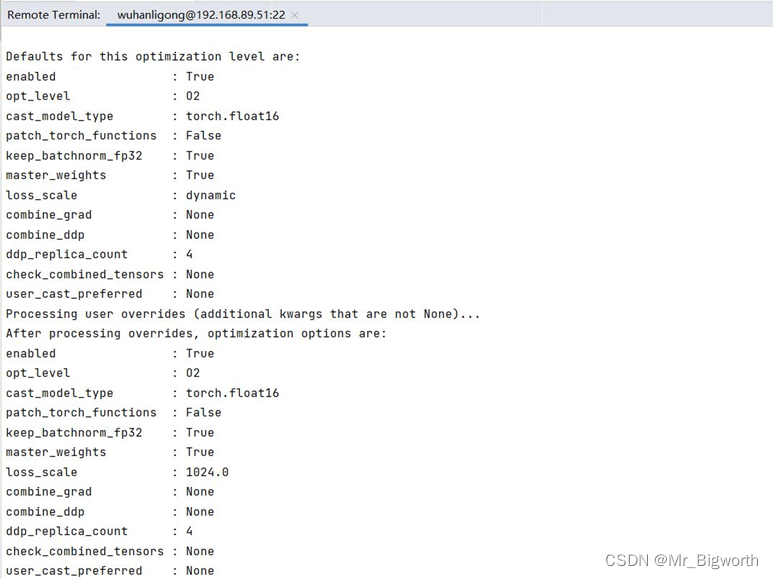
图7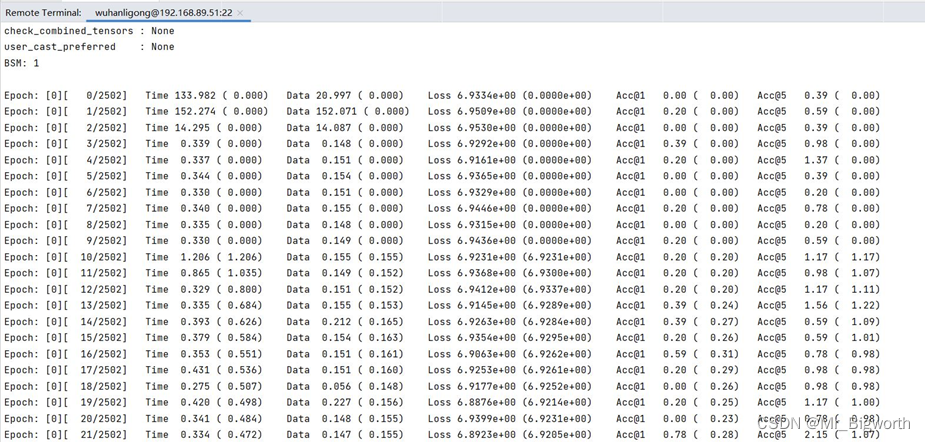
图8
七、数据解析与导出(msprof命令行)
- 非RC场景下,性能数据采集(msprof命令行方式)会自动解析采集到的Profiling数据,并默认导出最小模型号(Model ID)的第一轮迭代数据。若需要自定义导出数据,可以在采集进程结束之后,使用msprof --export的导出功能导出指定模型号和迭代的数据。
- msprof命令行解析功能也可以为其他性能数据采集方式执行解析操作,只需要提供原始数据文件PROF_XXX使用msprof --export解析并导出即可。
- msprof命令行解析功能包括的功能有:
- Profiling数据解析:解析原始数据文件PROF_XXX内的Profiling数据文件。
- Profiling数据导出:将原始数据文件PROF_XXX内的Profiling数据文件导出为可视化的Timeline和Summary数据文件。
- Profiling数据文件信息查询:执行解析后可以使用msprof工具提供的查询功能查询路径下生成的Profiling数据文件的基本信息。
- Profiling数据解析:
- msprof命令行方式会自动解析采集到的Profiling数据,并默认导出最小模型号(Model ID)的第一轮迭代数据,当在RC场景下无法进行解析或解析失败时,可以在msprof命令执行完成后再次执行./msprof --parse=on命令对采集的数据重新进行解析。RC场景需先将数据拷贝到开发环境以解析数据。
- 命令行格式:./msprof --parse=on --output=<dir>

图9
图10
表13 解析命令参数说明
| 参数 | 说明 | 可选/必选 |
| --parse | 单独使用命令行工具进行解析。取值为:on:开启解析功能;off:关闭解析功能。 | 必选 |
| --output | 收集到的Profiling数据目录。须指定为PROF_XXX目录(仅生成汇总Timeline目录数据)或PROF_XXX目录下的host或device目录(生成具体设备数据),例如:/home/HwHiAiUser/profiler_data/PROF_XXX或/home/HwHiAiUser/profiler_data/PROF_XXX/device1。 | 必选 |
- Profiling数据文件信息查询:
- 在性能数据采集(msprof命令行方式)默认导出最小模型号(Model ID)的第一轮迭代数据或使用msprof --export导出其他迭代的数据后,可使用查询功能查询路径下生成的Profiling数据文件的基本信息。
- 命令行格式:./msprof --query=on --output=<dir>

图11
表14 信息查询命令参数说明
| 参数 | 说明 | 可选/必选 |
| --query | 查询Profiling数据文件信息。可选on或off,默认值为off。 当完成Profiling解析后,可以通过本参数查询Profiling数据文件信息,需使用--output参数指定查询的目标路径。 Ascend RC场景不支持本参数。 | 必选 |
| --output | 收集到的Profiling数据目录。须指定为PROF_XXX目录(仅查询汇总Timeline目录数据)或PROF_XXX目录下的host或device目录(查询具体设备数据),例如:/home/HwHiAiUser/profiler_data/PRO_FXXX或/home/HwHiAiUser/profiler_data/PROF_XXX/device1。 | 必选 |
- msprof工具的查询功能获取到的信息如表15所示。
表15 Profiling数据文件信息
| 字段 | 含义 |
| Job Info | 任务名 |
| Device ID | 设备号 |
| Dir Name | 文件夹名称 |
| Collection Time | 数据采集时间 |
| Model ID | 模型号 |
| Iteration Number | 总迭代数 |
| Top Time Iteration | 耗时最长的5个迭代号 |
- Profiling数据导出:
- 非RC场景下,msprof命令行方式会自动解析采集到的Profiling数据,并默认导出最小模型号(Model ID)的第一轮迭代数据。若需要自定义导出数据,可以在采集进程结束之后,使用msprof --export的导出功能导出指定模型号和迭代的数据。
- 命令行格式:./msprof --export=on --output=<dir> [--iteration-id=<number>] [--model-id=<number>] [--summary-format=<csv/json>]
图12
表16 信息查询命令参数说明
| 参数 | 说明 | 可选/必选 |
| --export | 导出Profiling timeline和summary数据。可选on或off,默认值为off。 默认导出迭代1、可导出的最小模型号(Model ID)的timeline和summary数据。 若需导出其他迭代/模型的数据,可在msprof命令执行完成后重新执行命令配置本参数和–model-id、–iteration-id参数。对于未解析的PROF_XXX文件,自动解析后再导出。示例:./msprof --export=on --output=/home/HwHiAiUser –model-id=2 –iteration-id=2 | 必选 |
| --output | 收集到的Profiling数据目录。须指定为PROF_XXX目录(仅生成汇总Timeline目录数据)或PROF_XXX目录下的host或device目录(生成具体设备数据),例如:/home/HwHiAiUser/profiler_data/PROF_XXX或/home/HwHiAiUser/profiler_data/PROF_XXX/device1。 | 必选 |
| --iteration-id | 某轮迭代的ID号,默认值为1。 | 可选 |
| --model-id | 模型ID。默认为可导出的最小模型号。 | 可选 |
| --summary-format | summary数据文件的导出格式,支持csv和json两种格式,默认值为csv。 | 可选 |
八、分析Profiling数据
- 执行完上述命令,Profiling即可以完成性能数据的采集并自动进行Profiling解析和导出,在AI任务文件的父目录下生成名为PROF_XXX的Profiling数据。
- 性能分析成功运行:

图13
- 生成的Profiling数据:

图14
- 生成的Profiling数据目录结构:
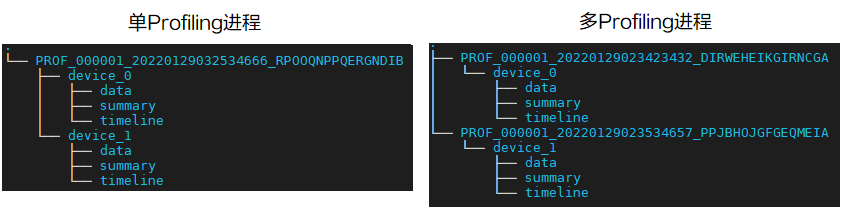
图15
- 多Device场景下,若启动单Profiling采集进程,则仅生成一个PROF_XXX目录,若启动多Profiling采集进程则生成多个PROF_XXX目录,其中Device目录在PROF_XXX目录下生成,每个PROF_XXX目录下生成多少个Device目录与用户实际操作有关,不影响Profiling分析。
- 其中,summary文件夹汇总了AI任务运行时的软硬件数据,timeline文件夹汇总了AI任务运行的时序信息,summary和timeline文件夹内各文件如表17所示。
- timeline数据说明:将timeline中的数据移动到Google的chrome trace中可以可视化呈现;
- timeline数据总表msprof_*.json展示如下,注意timeline数据总表msprof_*.json展示的数据属于迭代内的数据,迭代外的数据不展示。

图16
- 算子下发各阶段耗时数据ge_op_execute_0_1.json展示如下:

图17
- AscendCL、GE、Runtime组件耗时完整数据(按线程粒度展示)group_process_thread_*.json展示如下:

图18
- AscendCL接口耗时数据acl_0_1.json展示如下:

图19
- summary数据说明:summary中的csv可以通过excel表格打开,进行排序,对性能问题进行分析,以进一步提高性能。
- AscendCL接口耗时数据:生成的AscendCL接口耗时数据acl_0_1.csv内容截图如20。
- 字段说明:字段Name表示AscendCL API名称;Type表示AscendCL API类型;Start Time表示AscendCL API执行开始时间,单位us;Duration表示AscendCL API运行耗时,单位us;Process ID表示AscendCL API所在进程ID;Thread ID表示AscendCL API所在线程ID。
- 数据说明:将运行耗时进行由大到小的排序,可以看到aclopCompileAndExecute和OpCompile的运行耗时占比最高。
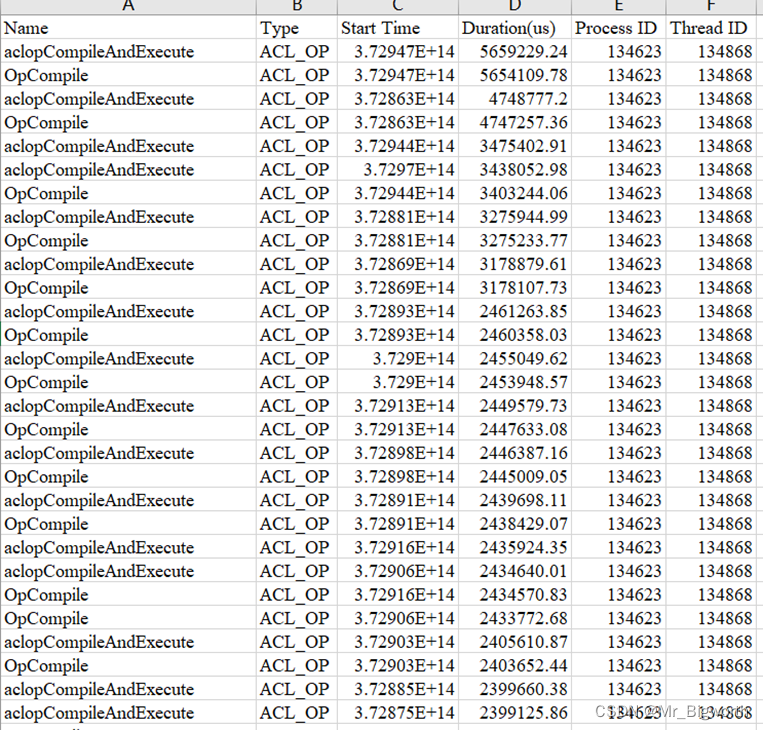
图20
- AscendCL接口调用次数及耗时数据:生成的acl_statistic_0_1.csv的内容截图如图21。
- 字段说明:字段Name表示AscendCL API名称;Type表示AscendCL API类型;Time(%)表示AscendCL接口调用耗时占比;Time(us)表示AscendCL接口调用耗时,单位us;Count表示AscendCL接口调用次数;Avg、Min、Max分别对应AscendCL接口调用平均耗时、最小耗时、最大耗时,单位us;Process ID表示AscendCL API所在进程ID;Thread ID表示AscendCL API所在线程ID。
- 数据说明:由该表可以看出,在resnet50的模型训练中,aclopCompileAndExecute和OpCompile接口的调用耗时占比最高,两者加起来接近98%。
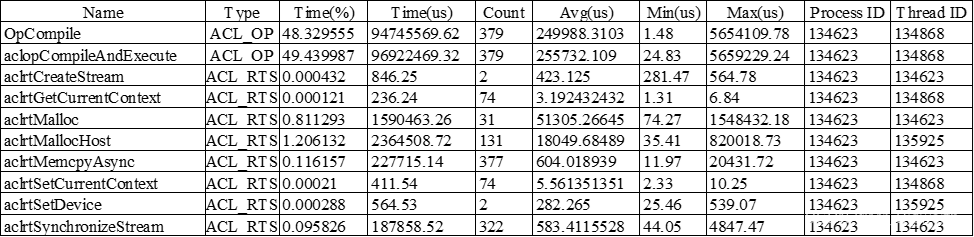
图21
- 算子下发各阶段耗时数据:生成的ge_op_execute_0_1.csv的内容截图如图22。
- 字段说明:字段Thread ID表示线程ID;OP Type表示算子名;Event Type表示事件类型;Start Time表示API执行开始时间,单位us;Duration表示API运行耗时,单位us。
- 数据说明:由该表可以看出,在resnet50的模型训练中,所有的事件类型都是0。
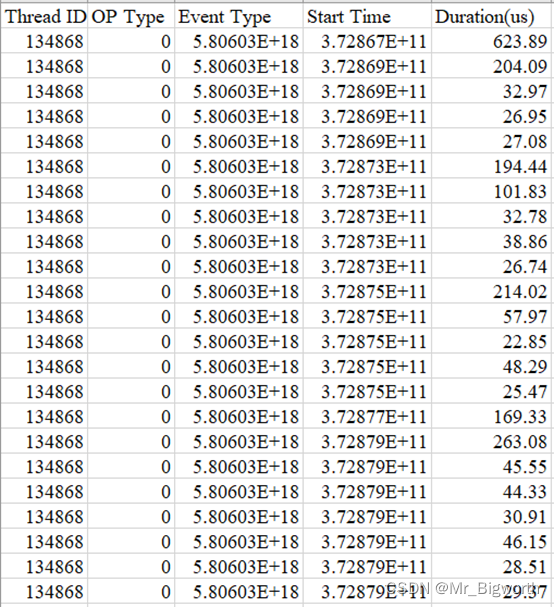
图22
表17 msprof默认配置采集的性能数据文件
| 文件夹 | 文件名 | 说明 |
| timeline | acl_*.json | AscendCL接口调用时序。 |
| ai_stack_time_*.json | 昇腾AI软件栈各组件(AscendCL,GE,Runtime,Task Scheduler等)运行时序。 | |
| step_trace_*.json | 迭代轨迹数据,每轮迭代的耗时。 | |
| task_time_*.json | Task Scheduler任务调度时序。 | |
| msprof_*.json | timeline数据总表。 | |
| summary | acl_*.csv | AscendCL API调用过程。 |
| acl_statistic_*.csv | AscendCL API数据统计。 | |
| op_summary_*.csv | AI Core和AI CPU算子数据。 | |
| op_statistic _*.csv | AI Core和AI CPU算子调用次数及耗时统计。 | |
| step_trace_*.csv | 迭代轨迹数据。 | |
| task_time_*.csv | Task Scheduler任务调度信息。 | |
| ai_stack_time_*.csv | 昇腾AI软件栈各组件(AscendCL,GE,Runtime,Task Scheduler等)信息。 | |
| 注:“*”表示{device_id}_{model_id}_{iter_id},其中{device_id}表示设备ID,{model_id}表示模型ID,{iter_id}表示某轮迭代的ID号。这些字段可以使用数据解析与导出完成数据解析后,使用数据解析与导出中的“查询Profiling数据文件信息查询功能”对结果文件进行查询得出,若查询某些字段显示为N/A(为空)则在导出的结果文件名中不展示。 | ||
九、经验总结
- 在模型训练结束后,Profiling数据解析时报错存储空间不足,或者循环显示开始准备解析的消息。

图23
解决办法:在执行Profiling数据解析前,提前删掉不需要的文件,或者多GPU分布式运行。
十、关于MindStudio更多的内容
如果需要了解关于MindStudio更多的信息,请查阅昇腾社区中MindStudio的[用户手册](https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/progressiveknowledge/index.html),里面模型训练、脚本转换、模型开发、算子开发、精度对比、AI Core Error分析工具、AutoML工具(Beta)、Benchmark工具、专家系统工具等各种使用安装操作的详细介绍。
如果在使用MindStudio过程中遇到任何问题,也可以在昇腾社区中的[昇腾论坛](https://www.huaweicloud.com)进行提问,会有华为内部技术人员对其进行解答,如下图。
图24
Enable GingerCannot connect to Ginger Check your internet connection
or reload the browserDisable in this text fieldRephraseRephrase current sentence99+Edit in Ginger×
or reload the browserDisable in this text fieldRephraseRephrase current sentence Edit in Ginger×















 2662
2662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









