







ClickHouse教程 — 第一章 ClickHouse单机版安装
0 Clickhouse下载地址
见 2.1 、 3.1 部分
1 版本区别
1.1 重要提示
golang在使用 github.com/ClickHouse/clickhouse-go/v2 时,如果报如下错误【即go的客户端不支持这个版本的clickhouse】:
WARNING: version 21.3.19 of ClickHouse is not supported by this client
ClickHouse (clickhouse-standalone) server version 21.3.19 revision 54447 (timezone Asia/Shanghai)
经最终测试发现不是clickhouse版本的问题,而是clickhouse-go/v2具体版本导致的,所以只需要把 clickhouse-go/v2降级就行,安装 clickhouse 时按照 2 clickhouse21.1.9.41以上版本 操作。
go.mod的变化:
降级前:
module clickhouse_demo
go 1.19
require github.com/ClickHouse/clickhouse-go/v2 main
执行 go mod tidy 后导入的具体版本
module clickhouse_demo
go 1.19
require github.com/ClickHouse/clickhouse-go/v2 v2.4.1
降级后:
module clickhouse_demo
go 1.19
require github.com/ClickHouse/clickhouse-go/v2 v2.2.0
1.2 clickhouse21.1.9.41以上版本
clickhouse-client-21.1.9.41以上版本的都是tgz格式的文件,属于最新版本的安装包。所以 2 clickhouse21.1.9.41以上版本 都是针对tgz格式的安装教程。但是golang在使用 github.com/ClickHouse/clickhouse-go/v2时会提示如下信息:
WARNING: version 21.3.19 of ClickHouse is not supported by this client
ClickHouse (clickhouse-standalone) server version 21.3.19 revision 54447 (timezone Asia/Shanghai)
1.3 clickhouse21.1.9.41以下版本
clickhouse-client-21.1.9.41以下版本的都是rpm格式的文件,属于旧版本的安装包,对应的安装教程是 3 clickhouse21.1.9.41以下版本。
2 clickhouse21.1.9.41以上版本
这里以 clickhouse22.2.2.1 为例
2.1 下载
官方下载地址:https://packages.clickhouse.com/tgz/stable
阿里云下载地址:https://mirrors.aliyun.com/clickhouse/tgz/stable
一共需要下载4个文件:
- clickhouse-client-22.2.2.1.tgz
- clickhouse-common-static-22.2.2.1.tgz
- clickhouse-common-static-dbg-22.2.2.1.tgz
- clickhouse-server-22.2.2.1.tgz
2.2 解压安装
将下载后的四个安装文件上传到服务器,这里是上传到linux的/opt/soft/clickhouse/下。
依次将这四个安装包解压,并且每解压一个,执行一下解压文件夹下的install下的doinst.sh脚本。
① clickhouse-common-static-22.2.2.1.tgz
tar -zxvf clickhouse-common-static-22.2.2.1.tgz
./clickhouse-common-static-22.2.2.1/install/doinst.sh
② clickhouse-common-static-dbg-22.2.2.1.tgz
tar -zxvf clickhouse-common-static-dbg-22.2.2.1.tgz
./clickhouse-common-static-dbg-22.2.2.1/install/doinst.sh
③ clickhouse-server-22.2.2.1.tgz
注意:在运行doinst.sh时,clickhouse会默认创建一个default的用户,让你设置密码,不设置密码可以按回车。
tar -zxvf clickhouse-server-22.2.2.1.tgz
./clickhouse-server-22.2.2.1/install/doinst.sh
④ clickhouse-client-22.2.2.1.tgz
tar -zxvf clickhouse-client-22.2.2.1.tgz
./clickhouse-client-22.2.2.1/install/doinst.sh
2.3 启动
#查看命令
clickhouse --help
#启动
clickhouse start
启动结果:
chown --recursive clickhouse '/var/run/clickhouse-server/'
Will run su -s /bin/sh 'clickhouse' -c '/usr/bin/clickhouse-server --config-file /etc/clickhouse-server/config.xml --pid-file /var/run/clickhouse-server/clickhouse-server.pid --daemon'
Waiting for server to start
Waiting for server to start
Server started
连接clickhouse
clickhouse-client
连接结果:
ClickHouse client version 22.2.2.1.
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 22.2.2 revision 54455.
2.4 clickhouse相关目录
# 命令目录
/usr/bin
ll |grep clickhouse
-------------------------------------------
# 配置文件目录
cd /etc/clickhouse-server/
-------------------------------------------
# 日志目录
cd /var/log/clickhouse-server/
-------------------------------------------
# 数据文件目录
cd /var/lib/clickhouse/
-------------------------------------------
2.5 允许远程访问
clickhouse 默认不允许远程访问,需要修改配置文件:
cd /etc/clickhouse-server/
vim config.xml
注意:只需要把 <listen_host>::</listen_host> 这一个的注释放开即可。
放开后的配置:
<?xml version="1.0"?>
<!--
NOTE: User and query level settings are set up in "users.xml" file.
If you have accidentally specified user-level settings here, server won't start.
You can either move the settings to the right place inside "users.xml" file
or add <skip_check_for_incorrect_settings>1</skip_check_for_incorrect_settings> here.
-->
<clickhouse>
<logger>
<!-- Possible levels [1]:
- none (turns off logging)
- fatal
- critical
- error
- warning
- notice
- information
- debug
- trace
- test (not for production usage)
[1]: https://github.com/pocoproject/poco/blob/poco-1.9.4-release/Foundation/include/Poco/Logger.h#L105-L114
-->
<level>trace</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<!-- Rotation policy
See https://github.com/pocoproject/poco/blob/poco-1.9.4-release/Foundation/include/Poco/FileChannel.h#L54-L85
-->
<size>1000M</size>
<count>10</count>
<!-- <console>1</console> --> <!-- Default behavior is autodetection (log to console if not daemon mode and is tty) -->
<!-- Per level overrides (legacy):
For example to suppress logging of the ConfigReloader you can use:
NOTE: levels.logger is reserved, see below.
-->
<!--
<levels>
<ConfigReloader>none</ConfigReloader>
</levels>
-->
<!-- Per level overrides:
For example to suppress logging of the RBAC for default user you can use:
(But please note that the logger name maybe changed from version to version, even after minor upgrade)
-->
<!--
<levels>
<logger>
<name>ContextAccess (default)</name>
<level>none</level>
</logger>
<logger>
<name>DatabaseOrdinary (test)</name>
<level>none</level>
</logger>
</levels>
-->
</logger>
<!-- Add headers to response in options request. OPTIONS method is used in CORS preflight requests. -->
<!-- It is off by default. Next headers are obligate for CORS.-->
<!-- http_options_response>
<header>
<name>Access-Control-Allow-Origin</name>
<value>*</value>
</header>
<header>
<name>Access-Control-Allow-Headers</name>
<value>origin, x-requested-with</value>
</header>
<header>
<name>Access-Control-Allow-Methods</name>
<value>POST, GET, OPTIONS</value>
</header>
<header>
<name>Access-Control-Max-Age</name>
<value>86400</value>
</header>
</http_options_response -->
<!-- It is the name that will be shown in the clickhouse-client.
By default, anything with "production" will be highlighted in red in query prompt.
-->
<!--display_name>production</display_name-->
<!-- Port for HTTP API. See also 'https_port' for secure connections.
This interface is also used by ODBC and JDBC drivers (DataGrip, Dbeaver, ...)
and by most of web interfaces (embedded UI, Grafana, Redash, ...).
-->
<http_port>8123</http_port>
<!-- Port for interaction by native protocol with:
- clickhouse-client and other native ClickHouse tools (clickhouse-benchmark, clickhouse-copier);
- clickhouse-server with other clickhouse-servers for distributed query processing;
- ClickHouse drivers and applications supporting native protocol
(this protocol is also informally called as "the TCP protocol");
See also 'tcp_port_secure' for secure connections.
-->
<tcp_port>9000</tcp_port>
<!-- Compatibility with MySQL protocol.
ClickHouse will pretend to be MySQL for applications connecting to this port.
-->
<mysql_port>9004</mysql_port>
<!-- Compatibility with PostgreSQL protocol.
ClickHouse will pretend to be PostgreSQL for applications connecting to this port.
-->
<postgresql_port>9005</postgresql_port>
<!-- HTTP API with TLS (HTTPS).
You have to configure certificate to enable this interface.
See the openSSL section below.
-->
<!-- <https_port>8443</https_port> -->
<!-- Native interface with TLS.
You have to configure certificate to enable this interface.
See the openSSL section below.
-->
<!-- <tcp_port_secure>9440</tcp_port_secure> -->
<!-- Native interface wrapped with PROXYv1 protocol
PROXYv1 header sent for every connection.
ClickHouse will extract information about proxy-forwarded client address from the header.
-->
<!-- <tcp_with_proxy_port>9011</tcp_with_proxy_port> -->
<!-- Port for communication between replicas. Used for data exchange.
It provides low-level data access between servers.
This port should not be accessible from untrusted networks.
See also 'interserver_http_credentials'.
Data transferred over connections to this port should not go through untrusted networks.
See also 'interserver_https_port'.
-->
<interserver_http_port>9009</interserver_http_port>
<!-- Port for communication between replicas with TLS.
You have to configure certificate to enable this interface.
See the openSSL section below.
See also 'interserver_http_credentials'.
-->
<!-- <interserver_https_port>9010</interserver_https_port> -->
<!-- Hostname that is used by other replicas to request this server.
If not specified, than it is determined analogous to 'hostname -f' command.
This setting could be used to switch replication to another network interface
(the server may be connected to multiple networks via multiple addresses)
-->
<!--
<interserver_http_host>example.yandex.ru</interserver_http_host>
-->
<!-- You can specify credentials for authenthication between replicas.
This is required when interserver_https_port is accessible from untrusted networks,
and also recommended to avoid SSRF attacks from possibly compromised services in your network.
-->
<!--<interserver_http_credentials>
<user>interserver</user>
<password></password>
</interserver_http_credentials>-->
<!-- Listen specified address.
Use :: (wildcard IPv6 address), if you want to accept connections both with IPv4 and IPv6 from everywhere.
Notes:
If you open connections from wildcard address, make sure that at least one of the following measures applied:
- server is protected by firewall and not accessible from untrusted networks;
- all users are restricted to subset of network addresses (see users.xml);
- all users have strong passwords, only secure (TLS) interfaces are accessible, or connections are only made via TLS interfaces.
- users without password have readonly access.
See also: https://www.shodan.io/search?query=clickhouse
-->
<listen_host>::</listen_host>
<!-- Same for hosts without support for IPv6: -->
<!-- <listen_host>0.0.0.0</listen_host> -->
<!-- Default values - try listen localhost on IPv4 and IPv6. -->
<!--
<listen_host>::1</listen_host>
<listen_host>127.0.0.1</listen_host>
-->
<!-- Don't exit if IPv6 or IPv4 networks are unavailable while trying to listen. -->
<!-- <listen_try>0</listen_try> -->
<!-- Allow multiple servers to listen on the same address:port. This is not recommended.
-->
<!-- <listen_reuse_port>0</listen_reuse_port> -->
<!-- <listen_backlog>4096</listen_backlog> -->
<max_connections>4096</max_connections>
<!-- For 'Connection: keep-alive' in HTTP 1.1 -->
<keep_alive_timeout>3</keep_alive_timeout>
<!-- gRPC protocol (see src/Server/grpc_protos/clickhouse_grpc.proto for the API) -->
<!-- <grpc_port>9100</grpc_port> -->
<grpc>
<enable_ssl>false</enable_ssl>
<!-- The following two files are used only if enable_ssl=1 -->
<ssl_cert_file>/path/to/ssl_cert_file</ssl_cert_file>
<ssl_key_file>/path/to/ssl_key_file</ssl_key_file>
<!-- Whether server will request client for a certificate -->
<ssl_require_client_auth>false</ssl_require_client_auth>
<!-- The following file is used only if ssl_require_client_auth=1 -->
<ssl_ca_cert_file>/path/to/ssl_ca_cert_file</ssl_ca_cert_file>
<!-- Default transport compression type (can be overridden by client, see the transport_compression_type field in QueryInfo).
Supported algorithms: none, deflate, gzip, stream_gzip -->
<transport_compression_type>none</transport_compression_type>
<!-- Default transport compression level. Supported levels: 0..3 -->
<transport_compression_level>0</transport_compression_level>
<!-- Send/receive message size limits in bytes. -1 means unlimited -->
<max_send_message_size>-1</max_send_message_size>
<max_receive_message_size>-1</max_receive_message_size>
<!-- Enable if you want very detailed logs -->
<verbose_logs>false</verbose_logs>
</grpc>
<!-- Used with https_port and tcp_port_secure. Full ssl options list: https://github.com/ClickHouse-Extras/poco/blob/master/NetSSL_OpenSSL/include/Poco/Net/SSLManager.h#L71 -->
<openSSL>
<server> <!-- Used for https server AND secure tcp port -->
<!-- openssl req -subj "/CN=localhost" -new -newkey rsa:2048 -days 365 -nodes -x509 -keyout /etc/clickhouse-server/server.key -out /etc/clickhouse-server/server.crt -->
<certificateFile>/etc/clickhouse-server/server.crt</certificateFile>
<privateKeyFile>/etc/clickhouse-server/server.key</privateKeyFile>
<!-- dhparams are optional. You can delete the <dhParamsFile> element.
To generate dhparams, use the following command:
openssl dhparam -out /etc/clickhouse-server/dhparam.pem 4096
Only file format with BEGIN DH PARAMETERS is supported.
-->
<!-- <dhParamsFile>/etc/clickhouse-server/dhparam.pem</dhParamsFile> -->
<verificationMode>none</verificationMode>
<loadDefaultCAFile>true</loadDefaultCAFile>
<cacheSessions>true</cacheSessions>
<disableProtocols>sslv2,sslv3</disableProtocols>
<preferServerCiphers>true</preferServerCiphers>
</server>
<client> <!-- Used for connecting to https dictionary source and secured Zookeeper communication -->
<loadDefaultCAFile>true</loadDefaultCAFile>
<cacheSessions>true</cacheSessions>
<disableProtocols>sslv2,sslv3</disableProtocols>
<preferServerCiphers>true</preferServerCiphers>
<!-- Use for self-signed: <verificationMode>none</verificationMode> -->
<invalidCertificateHandler>
<!-- Use for self-signed: <name>AcceptCertificateHandler</name> -->
<name>RejectCertificateHandler</name>
</invalidCertificateHandler>
</client>
</openSSL>
<!-- Default root page on http[s] server. For example load UI from https://tabix.io/ when opening http://localhost:8123 -->
<!--
<http_server_default_response><![CDATA[<html ng-app="SMI2"><head><base href="http://ui.tabix.io/"></head><body><div ui-view="" class="content-ui"></div><script src="http://loader.tabix.io/master.js"></script></body></html>]]></http_server_default_response>
-->
<!-- Maximum number of concurrent queries. -->
<max_concurrent_queries>100</max_concurrent_queries>
<!-- Maximum memory usage (resident set size) for server process.
Zero value or unset means default. Default is "max_server_memory_usage_to_ram_ratio" of available physical RAM.
If the value is larger than "max_server_memory_usage_to_ram_ratio" of available physical RAM, it will be cut down.
The constraint is checked on query execution time.
If a query tries to allocate memory and the current memory usage plus allocation is greater
than specified threshold, exception will be thrown.
It is not practical to set this constraint to small values like just a few gigabytes,
because memory allocator will keep this amount of memory in caches and the server will deny service of queries.
-->
<max_server_memory_usage>0</max_server_memory_usage>
<!-- Maximum number of threads in the Global thread pool.
This will default to a maximum of 10000 threads if not specified.
This setting will be useful in scenarios where there are a large number
of distributed queries that are running concurrently but are idling most
of the time, in which case a higher number of threads might be required.
-->
<max_thread_pool_size>10000</max_thread_pool_size>
<!-- Number of workers to recycle connections in background (see also drain_timeout).
If the pool is full, connection will be drained synchronously. -->
<!-- <max_threads_for_connection_collector>10</max_threads_for_connection_collector> -->
<!-- On memory constrained environments you may have to set this to value larger than 1.
-->
<max_server_memory_usage_to_ram_ratio>0.9</max_server_memory_usage_to_ram_ratio>
<!-- Simple server-wide memory profiler. Collect a stack trace at every peak allocation step (in bytes).
Data will be stored in system.trace_log table with query_id = empty string.
Zero means disabled.
-->
<total_memory_profiler_step>4194304</total_memory_profiler_step>
<!-- Collect random allocations and deallocations and write them into system.trace_log with 'MemorySample' trace_type.
The probability is for every alloc/free regardless to the size of the allocation.
Note that sampling happens only when the amount of untracked memory exceeds the untracked memory limit,
which is 4 MiB by default but can be lowered if 'total_memory_profiler_step' is lowered.
You may want to set 'total_memory_profiler_step' to 1 for extra fine grained sampling.
-->
<total_memory_tracker_sample_probability>0</total_memory_tracker_sample_probability>
<!-- Set limit on number of open files (default: maximum). This setting makes sense on Mac OS X because getrlimit() fails to retrieve
correct maximum value. -->
<!-- <max_open_files>262144</max_open_files> -->
<!-- Size of cache of uncompressed blocks of data, used in tables of MergeTree family.
In bytes. Cache is single for server. Memory is allocated only on demand.
Cache is used when 'use_uncompressed_cache' user setting turned on (off by default).
Uncompressed cache is advantageous only for very short queries and in rare cases.
Note: uncompressed cache can be pointless for lz4, because memory bandwidth
is slower than multi-core decompression on some server configurations.
Enabling it can sometimes paradoxically make queries slower.
-->
<uncompressed_cache_size>8589934592</uncompressed_cache_size>
<!-- Approximate size of mark cache, used in tables of MergeTree family.
In bytes. Cache is single for server. Memory is allocated only on demand.
You should not lower this value.
-->
<mark_cache_size>5368709120</mark_cache_size>
<!-- If you enable the `min_bytes_to_use_mmap_io` setting,
the data in MergeTree tables can be read with mmap to avoid copying from kernel to userspace.
It makes sense only for large files and helps only if data reside in page cache.
To avoid frequent open/mmap/munmap/close calls (which are very expensive due to consequent page faults)
and to reuse mappings from several threads and queries,
the cache of mapped files is maintained. Its size is the number of mapped regions (usually equal to the number of mapped files).
The amount of data in mapped files can be monitored
in system.metrics, system.metric_log by the MMappedFiles, MMappedFileBytes metrics
and in system.asynchronous_metrics, system.asynchronous_metrics_log by the MMapCacheCells metric,
and also in system.events, system.processes, system.query_log, system.query_thread_log, system.query_views_log by the
CreatedReadBufferMMap, CreatedReadBufferMMapFailed, MMappedFileCacheHits, MMappedFileCacheMisses events.
Note that the amount of data in mapped files does not consume memory directly and is not accounted
in query or server memory usage - because this memory can be discarded similar to OS page cache.
The cache is dropped (the files are closed) automatically on removal of old parts in MergeTree,
also it can be dropped manually by the SYSTEM DROP MMAP CACHE query.
-->
<mmap_cache_size>1000</mmap_cache_size>
<!-- Cache size in bytes for compiled expressions.-->
<compiled_expression_cache_size>134217728</compiled_expression_cache_size>
<!-- Cache size in elements for compiled expressions.-->
<compiled_expression_cache_elements_size>10000</compiled_expression_cache_elements_size>
<!-- Path to data directory, with trailing slash. -->
<path>/var/lib/clickhouse/</path>
<!-- Path to temporary data for processing hard queries. -->
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>
<!-- Policy from the <storage_configuration> for the temporary files.
If not set <tmp_path> is used, otherwise <tmp_path> is ignored.
Notes:
- move_factor is ignored
- keep_free_space_bytes is ignored
- max_data_part_size_bytes is ignored
- you must have exactly one volume in that policy
-->
<!-- <tmp_policy>tmp</tmp_policy> -->
<!-- Directory with user provided files that are accessible by 'file' table function. -->
<user_files_path>/var/lib/clickhouse/user_files/</user_files_path>
<!-- LDAP server definitions. -->
<ldap_servers>
<!-- List LDAP servers with their connection parameters here to later 1) use them as authenticators for dedicated local users,
who have 'ldap' authentication mechanism specified instead of 'password', or to 2) use them as remote user directories.
Parameters:
host - LDAP server hostname or IP, this parameter is mandatory and cannot be empty.
port - LDAP server port, default is 636 if enable_tls is set to true, 389 otherwise.
bind_dn - template used to construct the DN to bind to.
The resulting DN will be constructed by replacing all '{user_name}' substrings of the template with the actual
user name during each authentication attempt.
user_dn_detection - section with LDAP search parameters for detecting the actual user DN of the bound user.
This is mainly used in search filters for further role mapping when the server is Active Directory. The
resulting user DN will be used when replacing '{user_dn}' substrings wherever they are allowed. By default,
user DN is set equal to bind DN, but once search is performed, it will be updated with to the actual detected
user DN value.
base_dn - template used to construct the base DN for the LDAP search.
The resulting DN will be constructed by replacing all '{user_name}' and '{bind_dn}' substrings
of the template with the actual user name and bind DN during the LDAP search.
scope - scope of the LDAP search.
Accepted values are: 'base', 'one_level', 'children', 'subtree' (the default).
search_filter - template used to construct the search filter for the LDAP search.
The resulting filter will be constructed by replacing all '{user_name}', '{bind_dn}', and '{base_dn}'
substrings of the template with the actual user name, bind DN, and base DN during the LDAP search.
Note, that the special characters must be escaped properly in XML.
verification_cooldown - a period of time, in seconds, after a successful bind attempt, during which a user will be assumed
to be successfully authenticated for all consecutive requests without contacting the LDAP server.
Specify 0 (the default) to disable caching and force contacting the LDAP server for each authentication request.
enable_tls - flag to trigger use of secure connection to the LDAP server.
Specify 'no' for plain text (ldap://) protocol (not recommended).
Specify 'yes' for LDAP over SSL/TLS (ldaps://) protocol (recommended, the default).
Specify 'starttls' for legacy StartTLS protocol (plain text (ldap://) protocol, upgraded to TLS).
tls_minimum_protocol_version - the minimum protocol version of SSL/TLS.
Accepted values are: 'ssl2', 'ssl3', 'tls1.0', 'tls1.1', 'tls1.2' (the default).
tls_require_cert - SSL/TLS peer certificate verification behavior.
Accepted values are: 'never', 'allow', 'try', 'demand' (the default).
tls_cert_file - path to certificate file.
tls_key_file - path to certificate key file.
tls_ca_cert_file - path to CA certificate file.
tls_ca_cert_dir - path to the directory containing CA certificates.
tls_cipher_suite - allowed cipher suite (in OpenSSL notation).
Example:
<my_ldap_server>
<host>localhost</host>
<port>636</port>
<bind_dn>uid={user_name},ou=users,dc=example,dc=com</bind_dn>
<verification_cooldown>300</verification_cooldown>
<enable_tls>yes</enable_tls>
<tls_minimum_protocol_version>tls1.2</tls_minimum_protocol_version>
<tls_require_cert>demand</tls_require_cert>
<tls_cert_file>/path/to/tls_cert_file</tls_cert_file>
<tls_key_file>/path/to/tls_key_file</tls_key_file>
<tls_ca_cert_file>/path/to/tls_ca_cert_file</tls_ca_cert_file>
<tls_ca_cert_dir>/path/to/tls_ca_cert_dir</tls_ca_cert_dir>
<tls_cipher_suite>ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:AES256-GCM-SHA384</tls_cipher_suite>
</my_ldap_server>
Example (typical Active Directory with configured user DN detection for further role mapping):
<my_ad_server>
<host>localhost</host>
<port>389</port>
<bind_dn>EXAMPLE\{user_name}</bind_dn>
<user_dn_detection>
<base_dn>CN=Users,DC=example,DC=com</base_dn>
<search_filter>(&(objectClass=user)(sAMAccountName={user_name}))</search_filter>
</user_dn_detection>
<enable_tls>no</enable_tls>
</my_ad_server>
-->
</ldap_servers>
<!-- To enable Kerberos authentication support for HTTP requests (GSS-SPNEGO), for those users who are explicitly configured
to authenticate via Kerberos, define a single 'kerberos' section here.
Parameters:
principal - canonical service principal name, that will be acquired and used when accepting security contexts.
This parameter is optional, if omitted, the default principal will be used.
This parameter cannot be specified together with 'realm' parameter.
realm - a realm, that will be used to restrict authentication to only those requests whose initiator's realm matches it.
This parameter is optional, if omitted, no additional filtering by realm will be applied.
This parameter cannot be specified together with 'principal' parameter.
Example:
<kerberos />
Example:
<kerberos>
<principal>HTTP/clickhouse.example.com@EXAMPLE.COM</principal>
</kerberos>
Example:
<kerberos>
<realm>EXAMPLE.COM</realm>
</kerberos>
-->
<!-- Sources to read users, roles, access rights, profiles of settings, quotas. -->
<user_directories>
<users_xml>
<!-- Path to configuration file with predefined users. -->
<path>users.xml</path>
</users_xml>
<local_directory>
<!-- Path to folder where users created by SQL commands are stored. -->
<path>/var/lib/clickhouse/access/</path>
</local_directory>
<!-- To add an LDAP server as a remote user directory of users that are not defined locally, define a single 'ldap' section
with the following parameters:
server - one of LDAP server names defined in 'ldap_servers' config section above.
This parameter is mandatory and cannot be empty.
roles - section with a list of locally defined roles that will be assigned to each user retrieved from the LDAP server.
If no roles are specified here or assigned during role mapping (below), user will not be able to perform any
actions after authentication.
role_mapping - section with LDAP search parameters and mapping rules.
When a user authenticates, while still bound to LDAP, an LDAP search is performed using search_filter and the
name of the logged in user. For each entry found during that search, the value of the specified attribute is
extracted. For each attribute value that has the specified prefix, the prefix is removed, and the rest of the
value becomes the name of a local role defined in ClickHouse, which is expected to be created beforehand by
CREATE ROLE command.
There can be multiple 'role_mapping' sections defined inside the same 'ldap' section. All of them will be
applied.
base_dn - template used to construct the base DN for the LDAP search.
The resulting DN will be constructed by replacing all '{user_name}', '{bind_dn}', and '{user_dn}'
substrings of the template with the actual user name, bind DN, and user DN during each LDAP search.
scope - scope of the LDAP search.
Accepted values are: 'base', 'one_level', 'children', 'subtree' (the default).
search_filter - template used to construct the search filter for the LDAP search.
The resulting filter will be constructed by replacing all '{user_name}', '{bind_dn}', '{user_dn}', and
'{base_dn}' substrings of the template with the actual user name, bind DN, user DN, and base DN during
each LDAP search.
Note, that the special characters must be escaped properly in XML.
attribute - attribute name whose values will be returned by the LDAP search. 'cn', by default.
prefix - prefix, that will be expected to be in front of each string in the original list of strings returned by
the LDAP search. Prefix will be removed from the original strings and resulting strings will be treated
as local role names. Empty, by default.
Example:
<ldap>
<server>my_ldap_server</server>
<roles>
<my_local_role1 />
<my_local_role2 />
</roles>
<role_mapping>
<base_dn>ou=groups,dc=example,dc=com</base_dn>
<scope>subtree</scope>
<search_filter>(&(objectClass=groupOfNames)(member={bind_dn}))</search_filter>
<attribute>cn</attribute>
<prefix>clickhouse_</prefix>
</role_mapping>
</ldap>
Example (typical Active Directory with role mapping that relies on the detected user DN):
<ldap>
<server>my_ad_server</server>
<role_mapping>
<base_dn>CN=Users,DC=example,DC=com</base_dn>
<attribute>CN</attribute>
<scope>subtree</scope>
<search_filter>(&(objectClass=group)(member={user_dn}))</search_filter>
<prefix>clickhouse_</prefix>
</role_mapping>
</ldap>
-->
</user_directories>
<!-- Default profile of settings. -->
<default_profile>default</default_profile>
<!-- Comma-separated list of prefixes for user-defined settings. -->
<custom_settings_prefixes></custom_settings_prefixes>
<!-- System profile of settings. This settings are used by internal processes (Distributed DDL worker and so on). -->
<!-- <system_profile>default</system_profile> -->
<!-- Buffer profile of settings.
This settings are used by Buffer storage to flush data to the underlying table.
Default: used from system_profile directive.
-->
<!-- <buffer_profile>default</buffer_profile> -->
<!-- Default database. -->
<default_database>default</default_database>
<!-- Server time zone could be set here.
Time zone is used when converting between String and DateTime types,
when printing DateTime in text formats and parsing DateTime from text,
it is used in date and time related functions, if specific time zone was not passed as an argument.
Time zone is specified as identifier from IANA time zone database, like UTC or Africa/Abidjan.
If not specified, system time zone at server startup is used.
Please note, that server could display time zone alias instead of specified name.
Example: W-SU is an alias for Europe/Moscow and Zulu is an alias for UTC.
-->
<!-- <timezone>Europe/Moscow</timezone> -->
<!-- You can specify umask here (see "man umask"). Server will apply it on startup.
Number is always parsed as octal. Default umask is 027 (other users cannot read logs, data files, etc; group can only read).
-->
<!-- <umask>022</umask> -->
<!-- Perform mlockall after startup to lower first queries latency
and to prevent clickhouse executable from being paged out under high IO load.
Enabling this option is recommended but will lead to increased startup time for up to a few seconds.
-->
<mlock_executable>true</mlock_executable>
<!-- Reallocate memory for machine code ("text") using huge pages. Highly experimental. -->
<remap_executable>false</remap_executable>
<![CDATA[
Uncomment below in order to use JDBC table engine and function.
To install and run JDBC bridge in background:
* [Debian/Ubuntu]
export MVN_URL=https://repo1.maven.org/maven2/ru/yandex/clickhouse/clickhouse-jdbc-bridge
export PKG_VER=$(curl -sL $MVN_URL/maven-metadata.xml | grep '<release>' | sed -e 's|.*>\(.*\)<.*|\1|')
wget https://github.com/ClickHouse/clickhouse-jdbc-bridge/releases/download/v$PKG_VER/clickhouse-jdbc-bridge_$PKG_VER-1_all.deb
apt install --no-install-recommends -f ./clickhouse-jdbc-bridge_$PKG_VER-1_all.deb
clickhouse-jdbc-bridge &
* [CentOS/RHEL]
export MVN_URL=https://repo1.maven.org/maven2/ru/yandex/clickhouse/clickhouse-jdbc-bridge
export PKG_VER=$(curl -sL $MVN_URL/maven-metadata.xml | grep '<release>' | sed -e 's|.*>\(.*\)<.*|\1|')
wget https://github.com/ClickHouse/clickhouse-jdbc-bridge/releases/download/v$PKG_VER/clickhouse-jdbc-bridge-$PKG_VER-1.noarch.rpm
yum localinstall -y clickhouse-jdbc-bridge-$PKG_VER-1.noarch.rpm
clickhouse-jdbc-bridge &
Please refer to https://github.com/ClickHouse/clickhouse-jdbc-bridge#usage for more information.
]]>
<!--
<jdbc_bridge>
<host>127.0.0.1</host>
<port>9019</port>
</jdbc_bridge>
-->
<!-- Configuration of clusters that could be used in Distributed tables.
https://clickhouse.com/docs/en/operations/table_engines/distributed/
-->
<remote_servers>
<!-- Test only shard config for testing distributed storage -->
<test_shard_localhost>
<!-- Inter-server per-cluster secret for Distributed queries
default: no secret (no authentication will be performed)
If set, then Distributed queries will be validated on shards, so at least:
- such cluster should exist on the shard,
- such cluster should have the same secret.
And also (and which is more important), the initial_user will
be used as current user for the query.
Right now the protocol is pretty simple and it only takes into account:
- cluster name
- query
Also it will be nice if the following will be implemented:
- source hostname (see interserver_http_host), but then it will depends from DNS,
it can use IP address instead, but then the you need to get correct on the initiator node.
- target hostname / ip address (same notes as for source hostname)
- time-based security tokens
-->
<!-- <secret></secret> -->
<shard>
<!-- Optional. Whether to write data to just one of the replicas. Default: false (write data to all replicas). -->
<!-- <internal_replication>false</internal_replication> -->
<!-- Optional. Shard weight when writing data. Default: 1. -->
<!-- <weight>1</weight> -->
<replica>
<host>localhost</host>
<port>9000</port>
<!-- Optional. Priority of the replica for load_balancing. Default: 1 (less value has more priority). -->
<!-- <priority>1</priority> -->
</replica>
</shard>
</test_shard_localhost>
<test_cluster_one_shard_three_replicas_localhost>
<shard>
<internal_replication>false</internal_replication>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
<replica>
<host>127.0.0.3</host>
<port>9000</port>
</replica>
</shard>
<!--shard>
<internal_replication>false</internal_replication>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
<replica>
<host>127.0.0.3</host>
<port>9000</port>
</replica>
</shard-->
</test_cluster_one_shard_three_replicas_localhost>
<test_cluster_two_shards_localhost>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards_localhost>
<test_cluster_two_shards>
<shard>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards>
<test_cluster_two_shards_internal_replication>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards_internal_replication>
<test_shard_localhost_secure>
<shard>
<replica>
<host>localhost</host>
<port>9440</port>
<secure>1</secure>
</replica>
</shard>
</test_shard_localhost_secure>
<test_unavailable_shard>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>localhost</host>
<port>1</port>
</replica>
</shard>
</test_unavailable_shard>
</remote_servers>
<!-- The list of hosts allowed to use in URL-related storage engines and table functions.
If this section is not present in configuration, all hosts are allowed.
-->
<!--<remote_url_allow_hosts>-->
<!-- Host should be specified exactly as in URL. The name is checked before DNS resolution.
Example: "yandex.ru", "yandex.ru." and "www.yandex.ru" are different hosts.
If port is explicitly specified in URL, the host:port is checked as a whole.
If host specified here without port, any port with this host allowed.
"yandex.ru" -> "yandex.ru:443", "yandex.ru:80" etc. is allowed, but "yandex.ru:80" -> only "yandex.ru:80" is allowed.
If the host is specified as IP address, it is checked as specified in URL. Example: "[2a02:6b8:a::a]".
If there are redirects and support for redirects is enabled, every redirect (the Location field) is checked.
Host should be specified using the host xml tag:
<host>yandex.ru</host>
-->
<!-- Regular expression can be specified. RE2 engine is used for regexps.
Regexps are not aligned: don't forget to add ^ and $. Also don't forget to escape dot (.) metacharacter
(forgetting to do so is a common source of error).
-->
<!--</remote_url_allow_hosts>-->
<!-- If element has 'incl' attribute, then for it's value will be used corresponding substitution from another file.
By default, path to file with substitutions is /etc/metrika.xml. It could be changed in config in 'include_from' element.
Values for substitutions are specified in /clickhouse/name_of_substitution elements in that file.
-->
<!-- ZooKeeper is used to store metadata about replicas, when using Replicated tables.
Optional. If you don't use replicated tables, you could omit that.
See https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replication/
-->
<!--
<zookeeper>
<node>
<host>example1</host>
<port>2181</port>
</node>
<node>
<host>example2</host>
<port>2181</port>
</node>
<node>
<host>example3</host>
<port>2181</port>
</node>
</zookeeper>
-->
<!-- Substitutions for parameters of replicated tables.
Optional. If you don't use replicated tables, you could omit that.
See https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replication/#creating-replicated-tables
-->
<!--
<macros>
<shard>01</shard>
<replica>example01-01-1</replica>
</macros>
-->
<!-- Reloading interval for embedded dictionaries, in seconds. Default: 3600. -->
<builtin_dictionaries_reload_interval>3600</builtin_dictionaries_reload_interval>
<!-- Maximum session timeout, in seconds. Default: 3600. -->
<max_session_timeout>3600</max_session_timeout>
<!-- Default session timeout, in seconds. Default: 60. -->
<default_session_timeout>60</default_session_timeout>
<!-- Sending data to Graphite for monitoring. Several sections can be defined. -->
<!--
interval - send every X second
root_path - prefix for keys
hostname_in_path - append hostname to root_path (default = true)
metrics - send data from table system.metrics
events - send data from table system.events
asynchronous_metrics - send data from table system.asynchronous_metrics
-->
<!--
<graphite>
<host>localhost</host>
<port>42000</port>
<timeout>0.1</timeout>
<interval>60</interval>
<root_path>one_min</root_path>
<hostname_in_path>true</hostname_in_path>
<metrics>true</metrics>
<events>true</events>
<events_cumulative>false</events_cumulative>
<asynchronous_metrics>true</asynchronous_metrics>
</graphite>
<graphite>
<host>localhost</host>
<port>42000</port>
<timeout>0.1</timeout>
<interval>1</interval>
<root_path>one_sec</root_path>
<metrics>true</metrics>
<events>true</events>
<events_cumulative>false</events_cumulative>
<asynchronous_metrics>false</asynchronous_metrics>
</graphite>
-->
<!-- Serve endpoint for Prometheus monitoring. -->
<!--
endpoint - mertics path (relative to root, statring with "/")
port - port to setup server. If not defined or 0 than http_port used
metrics - send data from table system.metrics
events - send data from table system.events
asynchronous_metrics - send data from table system.asynchronous_metrics
status_info - send data from different component from CH, ex: Dictionaries status
-->
<!--
<prometheus>
<endpoint>/metrics</endpoint>
<port>9363</port>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
<status_info>true</status_info>
</prometheus>
-->
<!-- Query log. Used only for queries with setting log_queries = 1. -->
<query_log>
<!-- What table to insert data. If table is not exist, it will be created.
When query log structure is changed after system update,
then old table will be renamed and new table will be created automatically.
-->
<database>system</database>
<table>query_log</table>
<!--
PARTITION BY expr: https://clickhouse.com/docs/en/table_engines/mergetree-family/custom_partitioning_key/
Example:
event_date
toMonday(event_date)
toYYYYMM(event_date)
toStartOfHour(event_time)
-->
<partition_by>toYYYYMM(event_date)</partition_by>
<!--
Table TTL specification: https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree/#mergetree-table-ttl
Example:
event_date + INTERVAL 1 WEEK
event_date + INTERVAL 7 DAY DELETE
event_date + INTERVAL 2 WEEK TO DISK 'bbb'
<ttl>event_date + INTERVAL 30 DAY DELETE</ttl>
-->
<!-- Instead of partition_by, you can provide full engine expression (starting with ENGINE = ) with parameters,
Example: <engine>ENGINE = MergeTree PARTITION BY toYYYYMM(event_date) ORDER BY (event_date, event_time) SETTINGS index_granularity = 1024</engine>
-->
<!-- Interval of flushing data. -->
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
<!-- Trace log. Stores stack traces collected by query profilers.
See query_profiler_real_time_period_ns and query_profiler_cpu_time_period_ns settings. -->
<trace_log>
<database>system</database>
<table>trace_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</trace_log>
<!-- Query thread log. Has information about all threads participated in query execution.
Used only for queries with setting log_query_threads = 1. -->
<query_thread_log>
<database>system</database>
<table>query_thread_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_thread_log>
<!-- Query views log. Has information about all dependent views associated with a query.
Used only for queries with setting log_query_views = 1. -->
<query_views_log>
<database>system</database>
<table>query_views_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_views_log>
<!-- Uncomment if use part log.
Part log contains information about all actions with parts in MergeTree tables (creation, deletion, merges, downloads).-->
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>
<!-- Uncomment to write text log into table.
Text log contains all information from usual server log but stores it in structured and efficient way.
The level of the messages that goes to the table can be limited (<level>), if not specified all messages will go to the table.
<text_log>
<database>system</database>
<table>text_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<level></level>
</text_log>
-->
<!-- Metric log contains rows with current values of ProfileEvents, CurrentMetrics collected with "collect_interval_milliseconds" interval. -->
<metric_log>
<database>system</database>
<table>metric_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<collect_interval_milliseconds>1000</collect_interval_milliseconds>
</metric_log>
<!--
Asynchronous metric log contains values of metrics from
system.asynchronous_metrics.
-->
<asynchronous_metric_log>
<database>system</database>
<table>asynchronous_metric_log</table>
<!--
Asynchronous metrics are updated once a minute, so there is
no need to flush more often.
-->
<flush_interval_milliseconds>7000</flush_interval_milliseconds>
</asynchronous_metric_log>
<!--
OpenTelemetry log contains OpenTelemetry trace spans.
-->
<opentelemetry_span_log>
<!--
The default table creation code is insufficient, this <engine> spec
is a workaround. There is no 'event_time' for this log, but two times,
start and finish. It is sorted by finish time, to avoid inserting
data too far away in the past (probably we can sometimes insert a span
that is seconds earlier than the last span in the table, due to a race
between several spans inserted in parallel). This gives the spans a
global order that we can use to e.g. retry insertion into some external
system.
-->
<engine>
engine MergeTree
partition by toYYYYMM(finish_date)
order by (finish_date, finish_time_us, trace_id)
</engine>
<database>system</database>
<table>opentelemetry_span_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</opentelemetry_span_log>
<!-- Crash log. Stores stack traces for fatal errors.
This table is normally empty. -->
<crash_log>
<database>system</database>
<table>crash_log</table>
<partition_by />
<flush_interval_milliseconds>1000</flush_interval_milliseconds>
</crash_log>
<!-- Session log. Stores user log in (successful or not) and log out events. -->
<session_log>
<database>system</database>
<table>session_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</session_log>
<!-- Parameters for embedded dictionaries, used in Yandex.Metrica.
See https://clickhouse.com/docs/en/dicts/internal_dicts/
-->
<!-- Path to file with region hierarchy. -->
<!-- <path_to_regions_hierarchy_file>/opt/geo/regions_hierarchy.txt</path_to_regions_hierarchy_file> -->
<!-- Path to directory with files containing names of regions -->
<!-- <path_to_regions_names_files>/opt/geo/</path_to_regions_names_files> -->
<!-- <top_level_domains_path>/var/lib/clickhouse/top_level_domains/</top_level_domains_path> -->
<!-- Custom TLD lists.
Format: <name>/path/to/file</name>
Changes will not be applied w/o server restart.
Path to the list is under top_level_domains_path (see above).
-->
<top_level_domains_lists>
<!--
<public_suffix_list>/path/to/public_suffix_list.dat</public_suffix_list>
-->
</top_level_domains_lists>
<!-- Configuration of external dictionaries. See:
https://clickhouse.com/docs/en/sql-reference/dictionaries/external-dictionaries/external-dicts
-->
<dictionaries_config>*_dictionary.xml</dictionaries_config>
<!-- Configuration of user defined executable functions -->
<user_defined_executable_functions_config>*_function.xml</user_defined_executable_functions_config>
<!-- Uncomment if you want data to be compressed 30-100% better.
Don't do that if you just started using ClickHouse.
-->
<!--
<compression>
<!- - Set of variants. Checked in order. Last matching case wins. If nothing matches, lz4 will be used. - ->
<case>
<!- - Conditions. All must be satisfied. Some conditions may be omitted. - ->
<min_part_size>10000000000</min_part_size> <!- - Min part size in bytes. - ->
<min_part_size_ratio>0.01</min_part_size_ratio> <!- - Min size of part relative to whole table size. - ->
<!- - What compression method to use. - ->
<method>zstd</method>
</case>
</compression>
-->
<!-- Configuration of encryption. The server executes a command to
obtain an encryption key at startup if such a command is
defined, or encryption codecs will be disabled otherwise. The
command is executed through /bin/sh and is expected to write
a Base64-encoded key to the stdout. -->
<encryption_codecs>
<!-- aes_128_gcm_siv -->
<!-- Example of getting hex key from env -->
<!-- the code should use this key and throw an exception if its length is not 16 bytes -->
<!--key_hex from_env="..."></key_hex -->
<!-- Example of multiple hex keys. They can be imported from env or be written down in config-->
<!-- the code should use these keys and throw an exception if their length is not 16 bytes -->
<!-- key_hex id="0">...</key_hex -->
<!-- key_hex id="1" from_env=".."></key_hex -->
<!-- key_hex id="2">...</key_hex -->
<!-- current_key_id>2</current_key_id -->
<!-- Example of getting hex key from config -->
<!-- the code should use this key and throw an exception if its length is not 16 bytes -->
<!-- key>...</key -->
<!-- example of adding nonce -->
<!-- nonce>...</nonce -->
<!-- /aes_128_gcm_siv -->
</encryption_codecs>
<!-- Allow to execute distributed DDL queries (CREATE, DROP, ALTER, RENAME) on cluster.
Works only if ZooKeeper is enabled. Comment it if such functionality isn't required. -->
<distributed_ddl>
<!-- Path in ZooKeeper to queue with DDL queries -->
<path>/clickhouse/task_queue/ddl</path>
<!-- Settings from this profile will be used to execute DDL queries -->
<!-- <profile>default</profile> -->
<!-- Controls how much ON CLUSTER queries can be run simultaneously. -->
<!-- <pool_size>1</pool_size> -->
<!--
Cleanup settings (active tasks will not be removed)
-->
<!-- Controls task TTL (default 1 week) -->
<!-- <task_max_lifetime>604800</task_max_lifetime> -->
<!-- Controls how often cleanup should be performed (in seconds) -->
<!-- <cleanup_delay_period>60</cleanup_delay_period> -->
<!-- Controls how many tasks could be in the queue -->
<!-- <max_tasks_in_queue>1000</max_tasks_in_queue> -->
</distributed_ddl>
<!-- Settings to fine tune MergeTree tables. See documentation in source code, in MergeTreeSettings.h -->
<!--
<merge_tree>
<max_suspicious_broken_parts>5</max_suspicious_broken_parts>
</merge_tree>
-->
<!-- Protection from accidental DROP.
If size of a MergeTree table is greater than max_table_size_to_drop (in bytes) than table could not be dropped with any DROP query.
If you want do delete one table and don't want to change clickhouse-server config, you could create special file <clickhouse-path>/flags/force_drop_table and make DROP once.
By default max_table_size_to_drop is 50GB; max_table_size_to_drop=0 allows to DROP any tables.
The same for max_partition_size_to_drop.
Uncomment to disable protection.
-->
<!-- <max_table_size_to_drop>0</max_table_size_to_drop> -->
<!-- <max_partition_size_to_drop>0</max_partition_size_to_drop> -->
<!-- Example of parameters for GraphiteMergeTree table engine -->
<graphite_rollup_example>
<pattern>
<regexp>click_cost</regexp>
<function>any</function>
<retention>
<age>0</age>
<precision>3600</precision>
</retention>
<retention>
<age>86400</age>
<precision>60</precision>
</retention>
</pattern>
<default>
<function>max</function>
<retention>
<age>0</age>
<precision>60</precision>
</retention>
<retention>
<age>3600</age>
<precision>300</precision>
</retention>
<retention>
<age>86400</age>
<precision>3600</precision>
</retention>
</default>
</graphite_rollup_example>
<!-- Directory in <clickhouse-path> containing schema files for various input formats.
The directory will be created if it doesn't exist.
-->
<format_schema_path>/var/lib/clickhouse/format_schemas/</format_schema_path>
<!-- Default query masking rules, matching lines would be replaced with something else in the logs
(both text logs and system.query_log).
name - name for the rule (optional)
regexp - RE2 compatible regular expression (mandatory)
replace - substitution string for sensitive data (optional, by default - six asterisks)
-->
<query_masking_rules>
<rule>
<name>hide encrypt/decrypt arguments</name>
<regexp>((?:aes_)?(?:encrypt|decrypt)(?:_mysql)?)\s*\(\s*(?:'(?:\\'|.)+'|.*?)\s*\)</regexp>
<!-- or more secure, but also more invasive:
(aes_\w+)\s*\(.*\)
-->
<replace>\1(???)</replace>
</rule>
</query_masking_rules>
<!-- Uncomment to use custom http handlers.
rules are checked from top to bottom, first match runs the handler
url - to match request URL, you can use 'regex:' prefix to use regex match(optional)
methods - to match request method, you can use commas to separate multiple method matches(optional)
headers - to match request headers, match each child element(child element name is header name), you can use 'regex:' prefix to use regex match(optional)
handler is request handler
type - supported types: static, dynamic_query_handler, predefined_query_handler
query - use with predefined_query_handler type, executes query when the handler is called
query_param_name - use with dynamic_query_handler type, extracts and executes the value corresponding to the <query_param_name> value in HTTP request params
status - use with static type, response status code
content_type - use with static type, response content-type
response_content - use with static type, Response content sent to client, when using the prefix 'file://' or 'config://', find the content from the file or configuration send to client.
<http_handlers>
<rule>
<url>/</url>
<methods>POST,GET</methods>
<headers><pragma>no-cache</pragma></headers>
<handler>
<type>dynamic_query_handler</type>
<query_param_name>query</query_param_name>
</handler>
</rule>
<rule>
<url>/predefined_query</url>
<methods>POST,GET</methods>
<handler>
<type>predefined_query_handler</type>
<query>SELECT * FROM system.settings</query>
</handler>
</rule>
<rule>
<handler>
<type>static</type>
<status>200</status>
<content_type>text/plain; charset=UTF-8</content_type>
<response_content>config://http_server_default_response</response_content>
</handler>
</rule>
</http_handlers>
-->
<send_crash_reports>
<!-- Changing <enabled> to true allows sending crash reports to -->
<!-- the ClickHouse core developers team via Sentry https://sentry.io -->
<!-- Doing so at least in pre-production environments is highly appreciated -->
<enabled>false</enabled>
<!-- Change <anonymize> to true if you don't feel comfortable attaching the server hostname to the crash report -->
<anonymize>false</anonymize>
<!-- Default endpoint should be changed to different Sentry DSN only if you have -->
<!-- some in-house engineers or hired consultants who're going to debug ClickHouse issues for you -->
<endpoint>https://6f33034cfe684dd7a3ab9875e57b1c8d@o388870.ingest.sentry.io/5226277</endpoint>
</send_crash_reports>
<!-- Uncomment to disable ClickHouse internal DNS caching. -->
<!-- <disable_internal_dns_cache>1</disable_internal_dns_cache> -->
<!-- You can also configure rocksdb like this: -->
<!--
<rocksdb>
<options>
<max_background_jobs>8</max_background_jobs>
</options>
<column_family_options>
<num_levels>2</num_levels>
</column_family_options>
<tables>
<table>
<name>TABLE</name>
<options>
<max_background_jobs>8</max_background_jobs>
</options>
<column_family_options>
<num_levels>2</num_levels>
</column_family_options>
</table>
</tables>
</rocksdb>
-->
</clickhouse>
重启clickhouse:
clickhouse restart
在浏览器输入服务器ip:8123验证一下,显示OK即可。
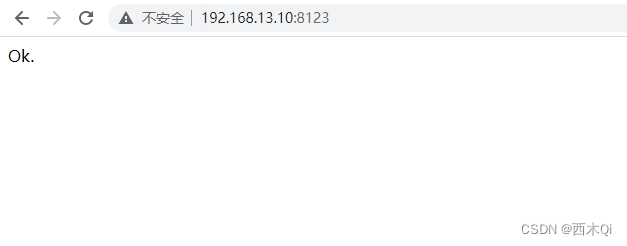
如果访问不了,可能需要开放端口或关闭防火墙。
开放 http_port:8123、tcp_port:9000、mysql_port:9004、interserver_http_port:9009端口
firewall-cmd --zone=public --add-port=8123/tcp --permanent
firewall-cmd --zone=public --add-port=9000/tcp --permanent
firewall-cmd --zone=public --add-port=9004/tcp --permanent
firewall-cmd --zone=public --add-port=9009/tcp --permanent
重启防火墙:
firewall-cmd --reload
查看开放的端口:
firewall-cmd --list-port
关闭firewall:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
3 clickhouse21.1.9.41以下版本
3.1 下载
下载地址:https://packagecloud.io/Altinity/clickhouse
一共需要下载4个文件:
clickhouse-server-common-20.8.3.18-1.el7.x86_64.rpm
clickhouse-server-20.8.3.18-1.el7.x86_64.rpm
clickhouse-common-static-20.8.3.18-1.el7.x86_64.rpm
clickhouse-client-20.8.3.18-1.el7.x86_64.rpm
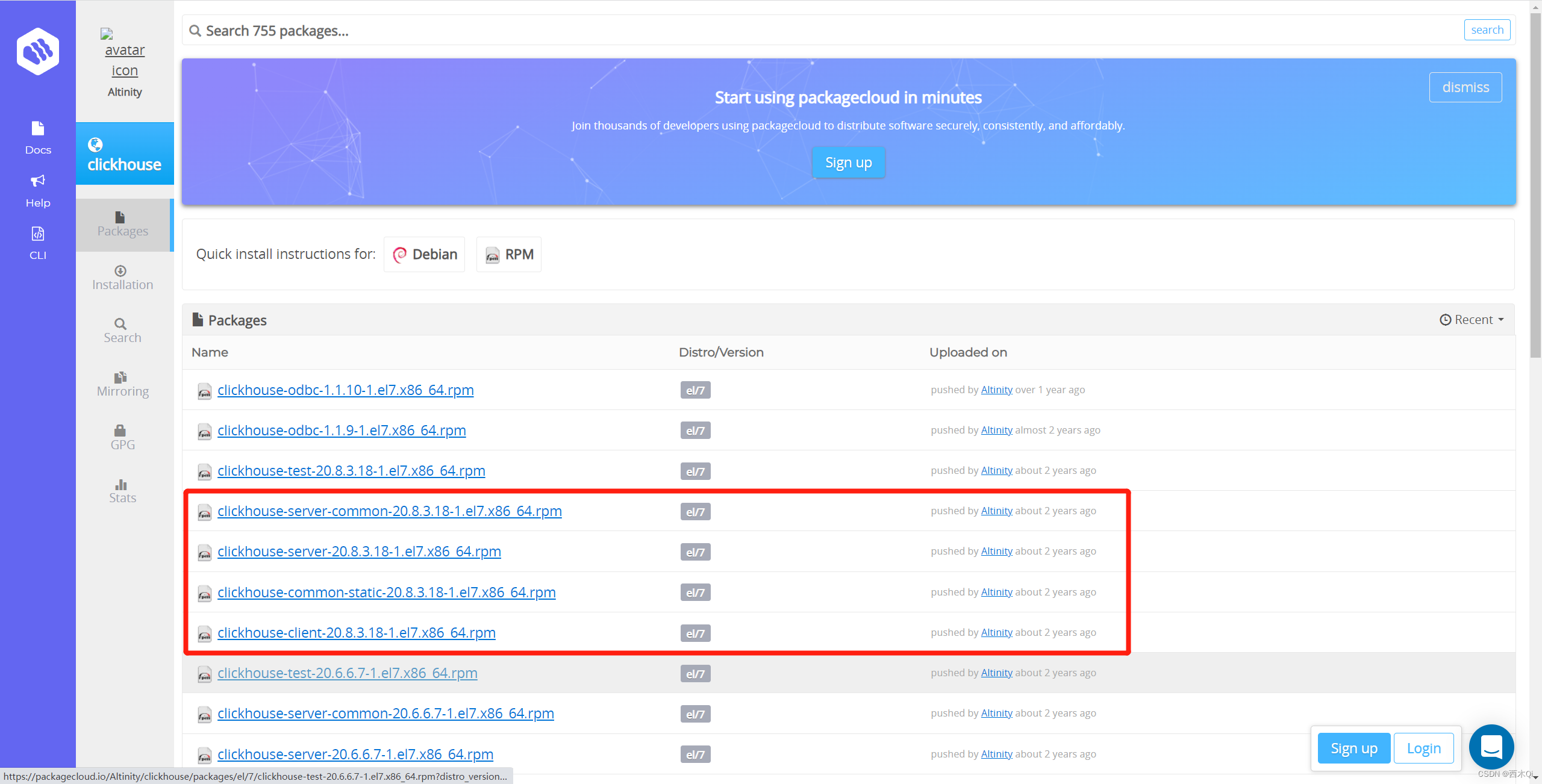
注意:右上角有下载按钮。可以直接下载对应的rpm文件。
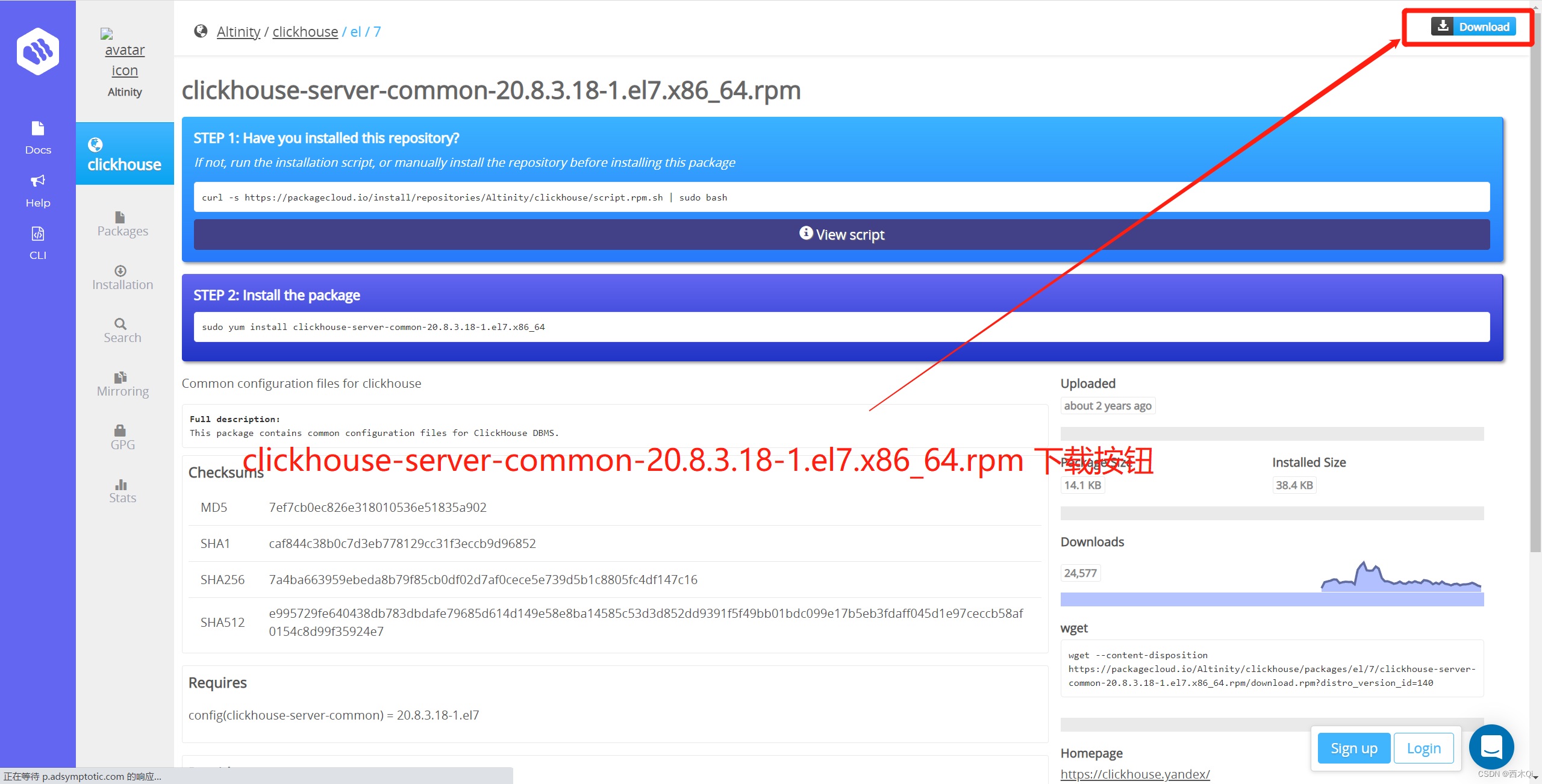
3.2 安装
rpm -ivh clickhouse-common-static-20.8.3.18-1.el7.x86_64.rpm
rpm -ivh clickhouse-server-common-20.8.3.18-1.el7.x86_64.rpm
rpm -ivh clickhouse-server-20.8.3.18-1.el7.x86_64.rpm
rpm -ivh clickhouse-client-20.8.3.18-1.el7.x86_64.rpm
3.4 允许远程访问
同 2.5 允许远程访问
3.5 启动
service clickhouse-server start
3.6 进入客户端
clickhouse-client(未设置密码登录)
clickhouse-client --multiline --password(设置密码登录)
3.7 卸载
参考1:clickhouse下载与安装
4 使用DBeaver连接Clickhouse
DBeaver的安装:DBeaver下载安装与连接MySQL数据库
DBeaver连接Clickhouse:DBeaver连接Clickhouse
SQL—》选择ClickHouse
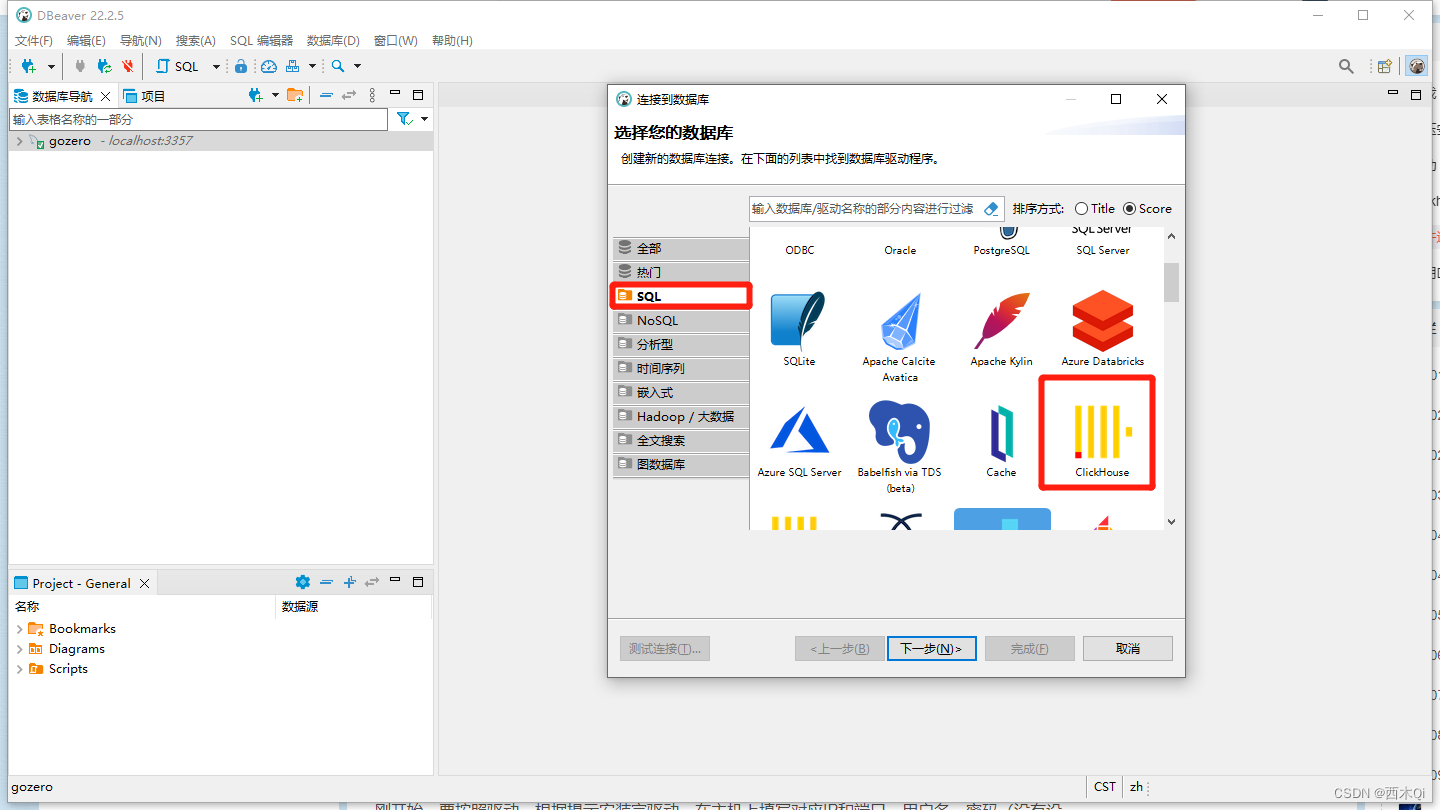
第一次连接需要安装驱动,根据提示操作即可安装成功。
注意:修改url,用户名默认是default,密码未设置则不填写。
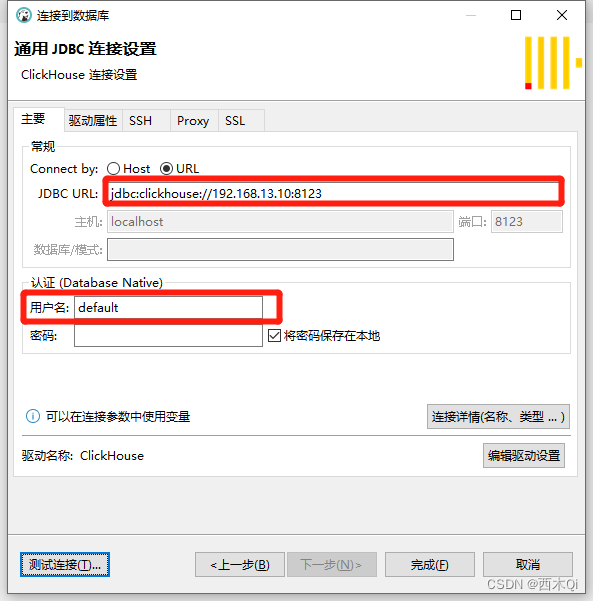
4.1 clickhouse时区不对的问题
关于插入的时间和查询的时间少8个小时的问题,这个问题主要出在DBeaver上,实际clickhouse存储的时间是正确的。
解决办法:
数据库—》驱动管理器
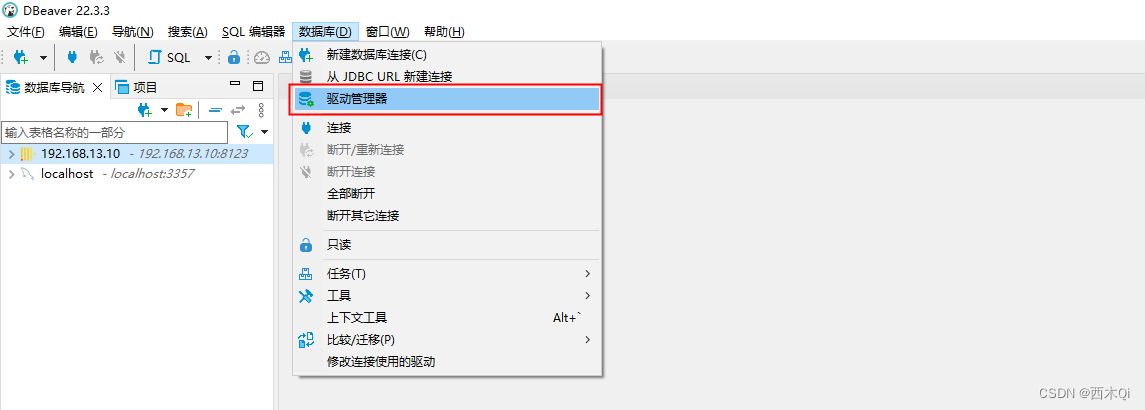
选择Clickhouse(注意:Legacy主要是低版本clickhouse的连接)
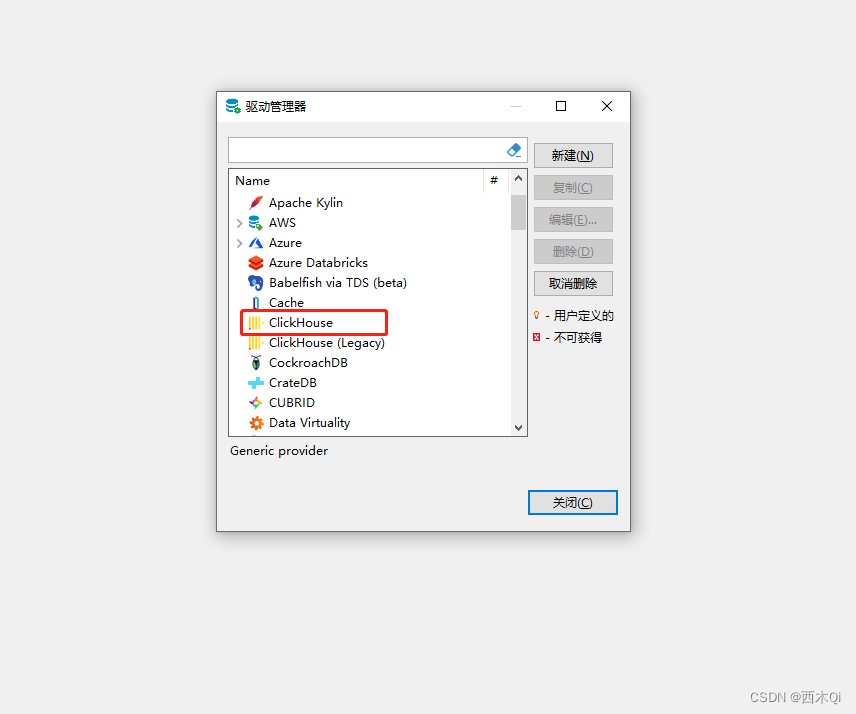
编辑驱动—》连接属性
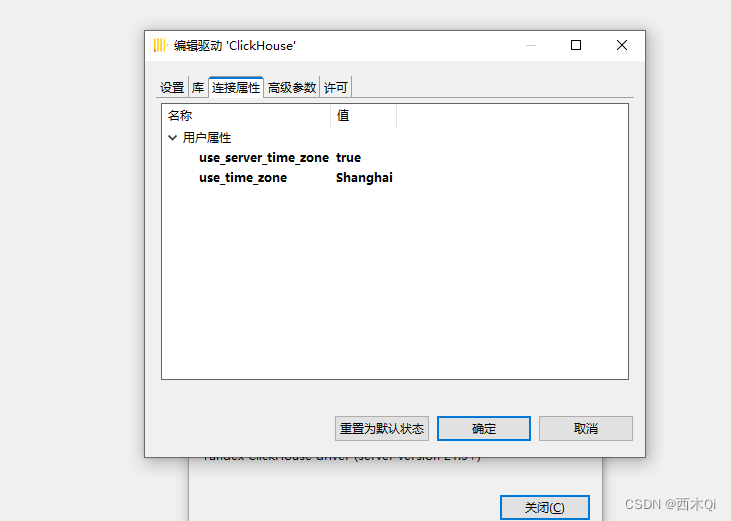
设置:
use_server_time_zone:true
use_time_zone:Shanghai
设置好后,删除已建立的连接,重新再建新连接即可。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









