







如有侵权、联系本人下架
以下面两个网站为例
1.aHR0cDovL3d3dy5mYW5nZGkuY29tLmNuL25ld19ob3VzZS9uZXdfaG91c2VfZGV0YWlsLmh0bWw=
2.aHR0cHM6Ly93d3cubm1wYS5nb3YuY24veWFvd2VuL3lwamd5dy9pbmRleC5odG1s
首先明确一下目标,我们要先获取网页200的源代码,RS5代第一次响应为412,第二次为200。如果是200就表示正常
以下为某 yjj RS5请求成功的结果,具体流程请看完文章,源-码–答-案也会在末 尾公 布

当我们不带任何cookie访问的时候,会返回一个202的响应码,并且附带一个set-cookie。响应体里面会加载一段混淆了的js代码,生成另一个cookie,携带这两个cookie再次访问网站,就可以获取200的源代码
所以,我们的目标就是分析这一段混淆的了js代码,看看另一个cookie是如何生成的
使用无痕浏览器,打开网页前,首先开启脚本断点
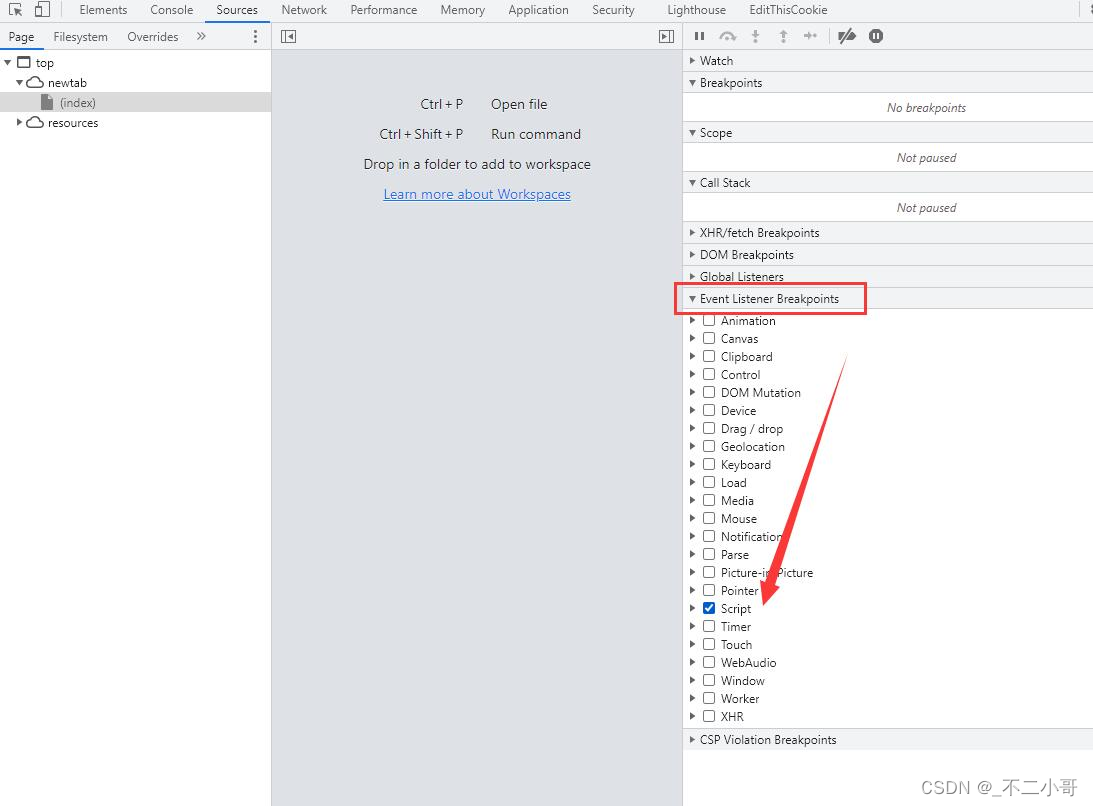
这时再访问网站,会在一个js页面断下
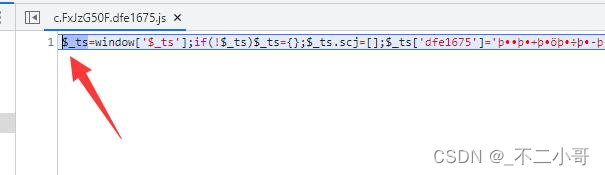
这是这个以【$_ts】开头的js文件,后面的一段乱码是给首层js代码还原的,继续运行来看看首页代码
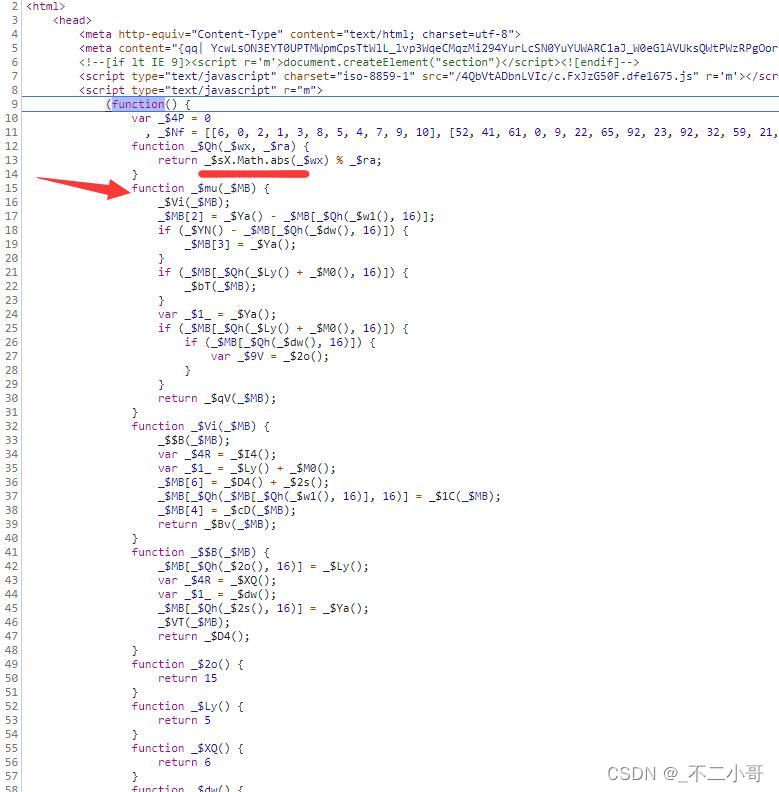
首层代码主要的有两部分,第一部分是这个【Math.abs】下面的这个函数,这个是用来生成最后cookie aes加密所需要的key,等用到的时候再具体分析
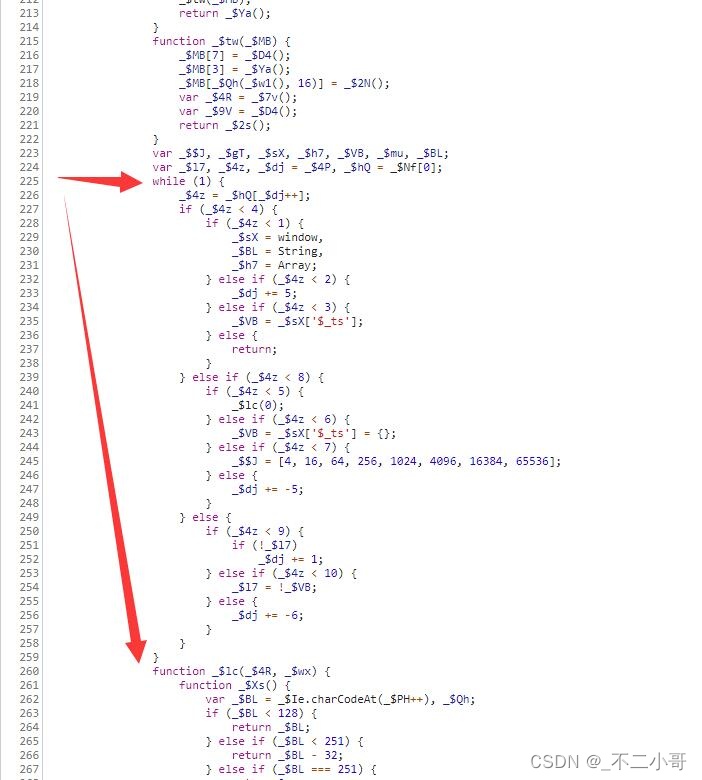
第二部分是第一个【while (1)】与下一个函数,这里主要的功能是把前面js里面的乱码还原成eval层的代码,并且生成【$_ts】的部分值给eval层代码使用。
那么eval层的代码在哪里进入呢?有一个很好的方法,就是搜索【call】
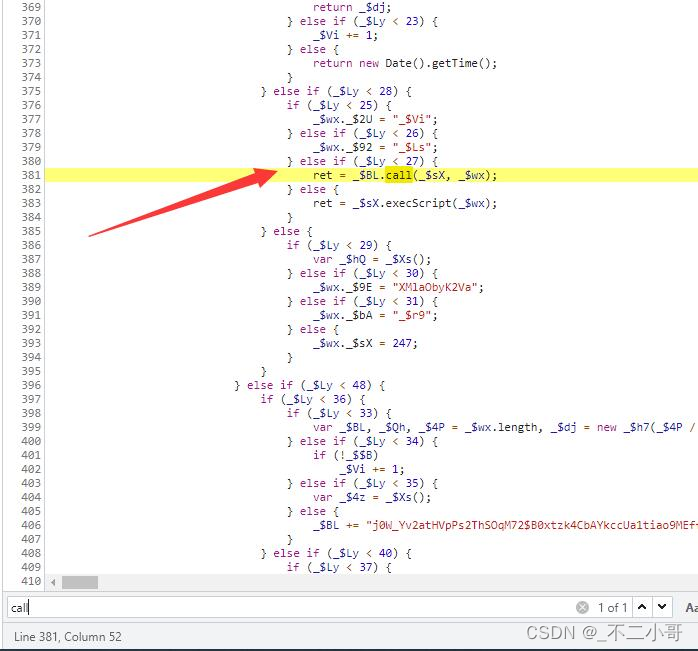
就只有一个结果,这里函数调用的第二个参数【_$wx】就是已经生成好的eval层代码
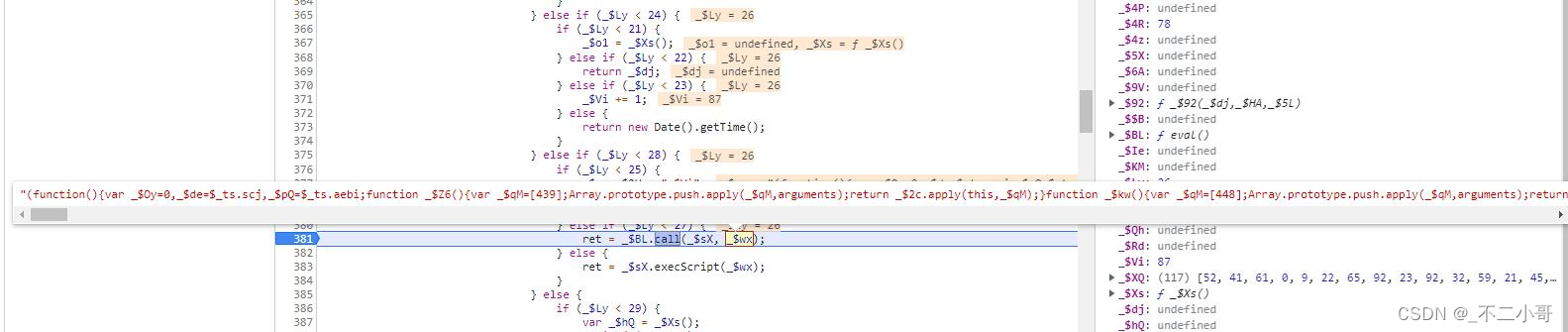
进入后又是一段混淆了的代码,而我们需要找的cookie生成算法,就是在这eval层的代码里面
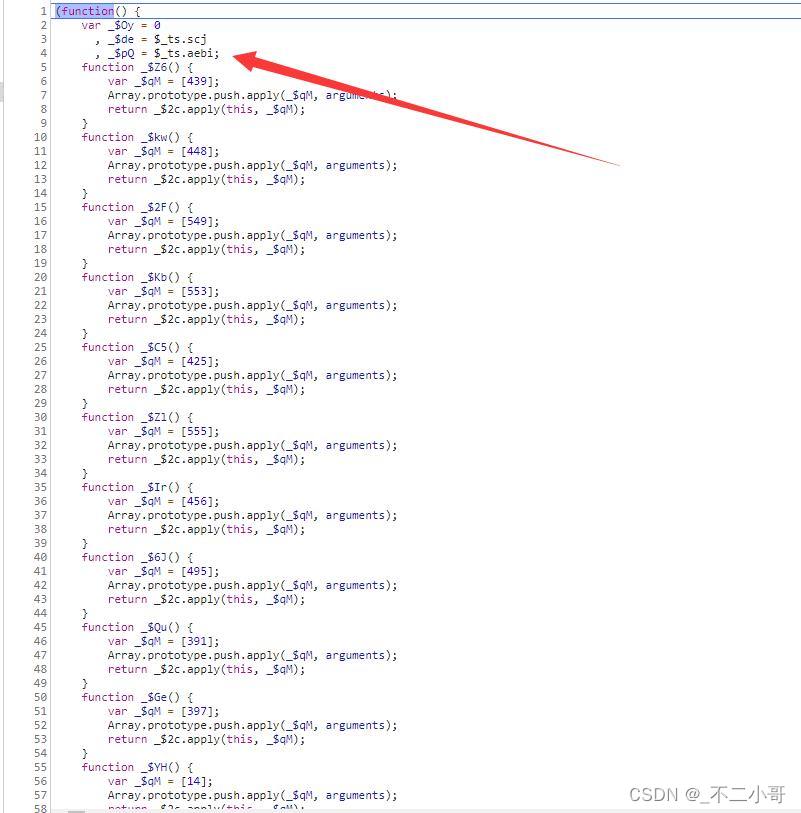
里面也用到了【 t s 】这个变量,那么第一步,我们就是需要拿到 e v a l 的函数,和进入 e v a l 时 _ts】这个变量,那么第一步,我们就是需要拿到eval的函数,和进入eval时 ts】这个变量,那么第一步,我们就是需要拿到eval的函数,和进入eval时_ts的具体内容
写一段代码浅尝一下
import requests_html
def main():
requests = requests_html.HTMLSession()
response = requests.get(url)
print(response.status_code)
print(response.text)
if __name__ == '__main__':
main()
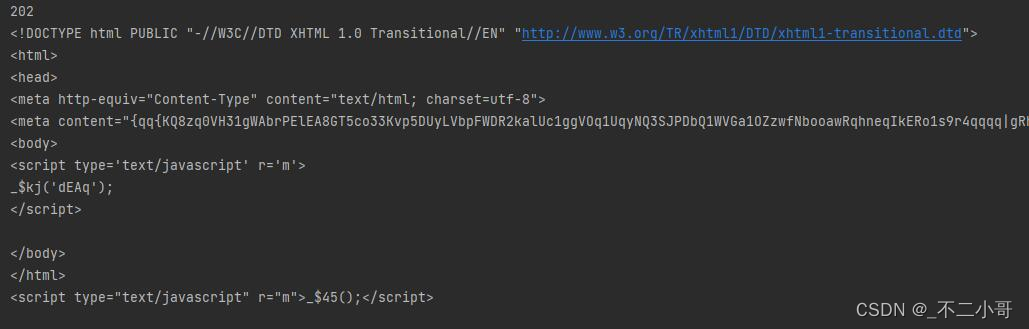
非常符合预期的202页面,接着把js内容和js链接抽取出来
import requests_html
from urllib import parse
def main():
requests = requests_html.HTMLSession()
response = requests.get(url)
print(response.status_code)
html_js = filter(lambda n: '(function()' in n.text, response.html.find('script')).__next__().find('script', first=True).text
js_url = response.html.find('script[charset="iso-8859-1"]', first=True).attrs['src']
encrypt_js = requests.get(parse.urljoin(url, js_url)).content.decode('iso-8859-1')
print(html_js)
print(encrypt_js)
if __name__ == '__main__':
main()

网页返回的js代码和js链接中的代码都拿到了,前面我们知道,当运行到call的时候,就进入到eval层的代码,但是我们并不想它运行,只是想拿到eval层的代码和$_ts的具体内容,那么就要在call的地方修改一下
用正则匹配出call的语句,并且替换成打印,并强制退出,我们就可以在控制台拿到想要的内容
我们使用nodejs运行代码来获取,所以需要先安装nodejs。因为我们文件不下地,这里就使用node的pipe通道的提交代码执行
import re
import subprocess
import requests_html
from urllib import parse
def main():
requests = requests_html.HTMLSession()
response = requests.get(url)
html_js = filter(lambda n: '(function()' in n.text, response.html.find('script')).__next__().find('script', first=True).text
js_url = response.html.find('script[charset="iso-8859-1"]', first=True).attrs['src']
encrypt_js = requests.get(parse.urljoin(url, js_url)).content.decode('iso-8859-1')
ret = re.findall('ret=.{4}\.call.{12}', html_js)[0]
ret_name = ret[-6: -2]
ff = subprocess.Popen('node', stdin=subprocess.PIPE, stdout=subprocess.PIPE, encoding='utf-8') # 需要安装node环境
ff.stdin.write("window = global;\nwindow['$_ts'] = {}\n")
ff.stdin.write(encrypt_js)
ff.stdin.write(html_js.replace(ret, "ret={};window['$_ts']['js']=" + ret_name + ";console.log(JSON.stringify(window['$_ts']));process.exit(0)"))
ff.stdin.close()
ts_json = ff.stdout.read()
print(ts_json)
if __name__ == '__main__':
main()
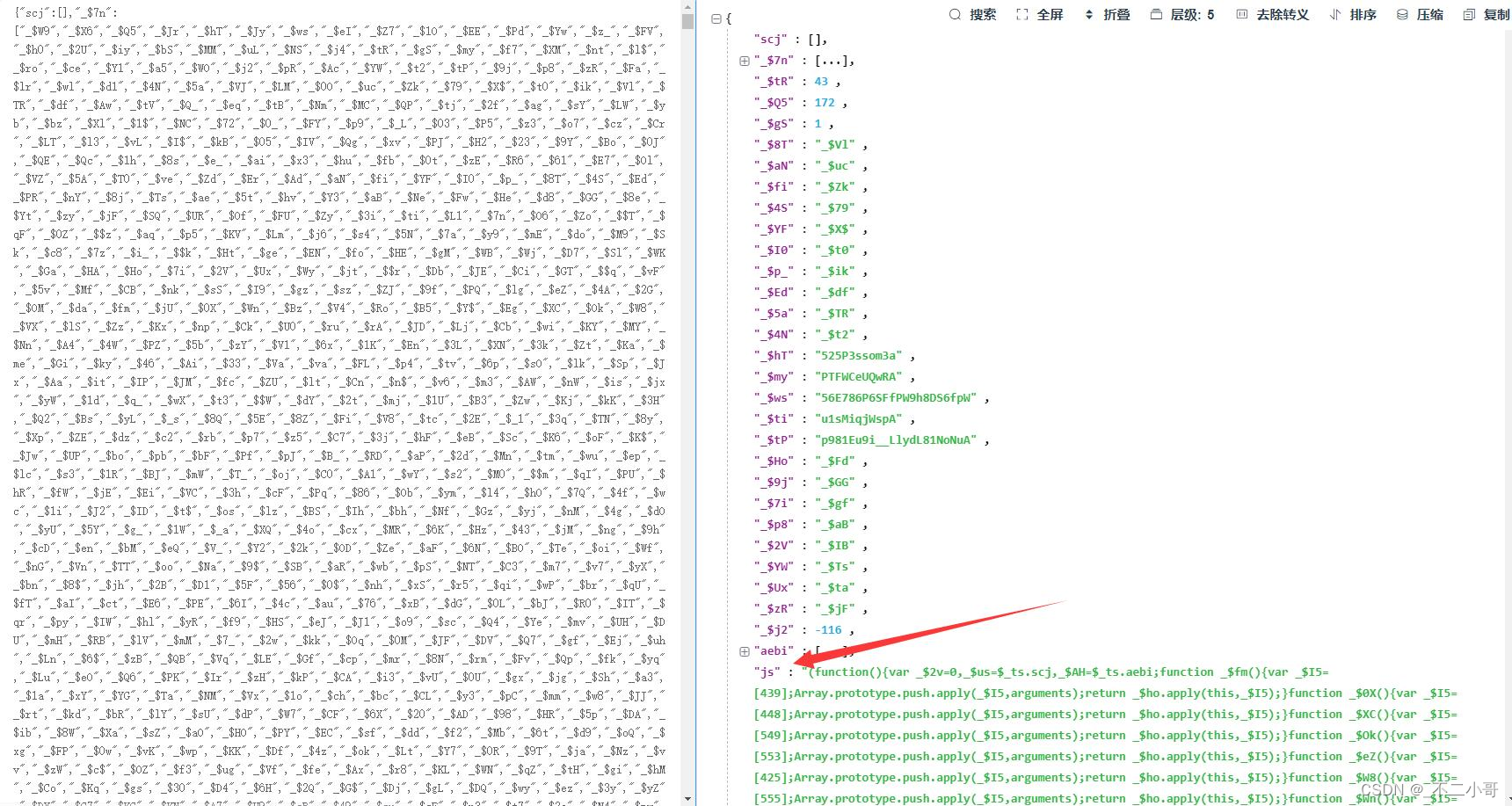
此时打印的内容就是【$_ts】具体的值,并且我们把js的内容也顺便放到一起返回了,接着我们就可以进一步分析eval层的代码
今天我们完成了第一步,获取了eval层的代码和$_ts具体的值
今天分享到这里就结束了,欢迎大家关注下期文章,我们不见不散⛽️
详细调试 vx-> jy2001aaa
















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









