







 超级会员免费看
超级会员免费看
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路
本文的验证码网址如下,使用base64解码获得
aHR0cHM6Ly9jcHF1ZXJ5LmNwb25saW5lLmNuaXBhLmdvdi5jbi9jaGluZXNlcGF0ZW50L2luZGV4
注意,本文随时会删,如果涉及法律法规等私信我删除文章即可
来看实现
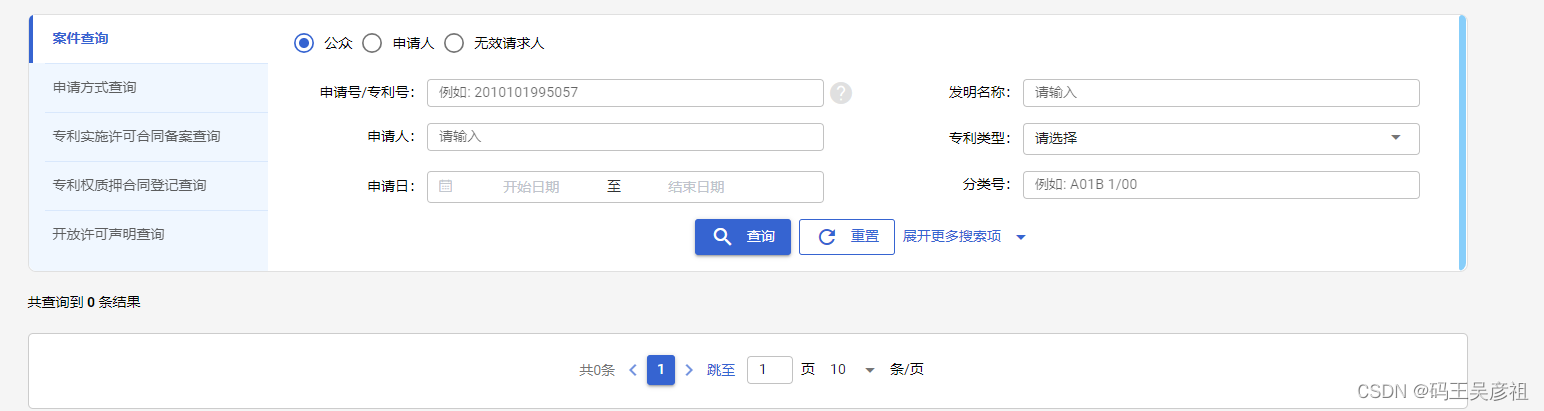
打开控制台调试后,经典的瑞数反爬
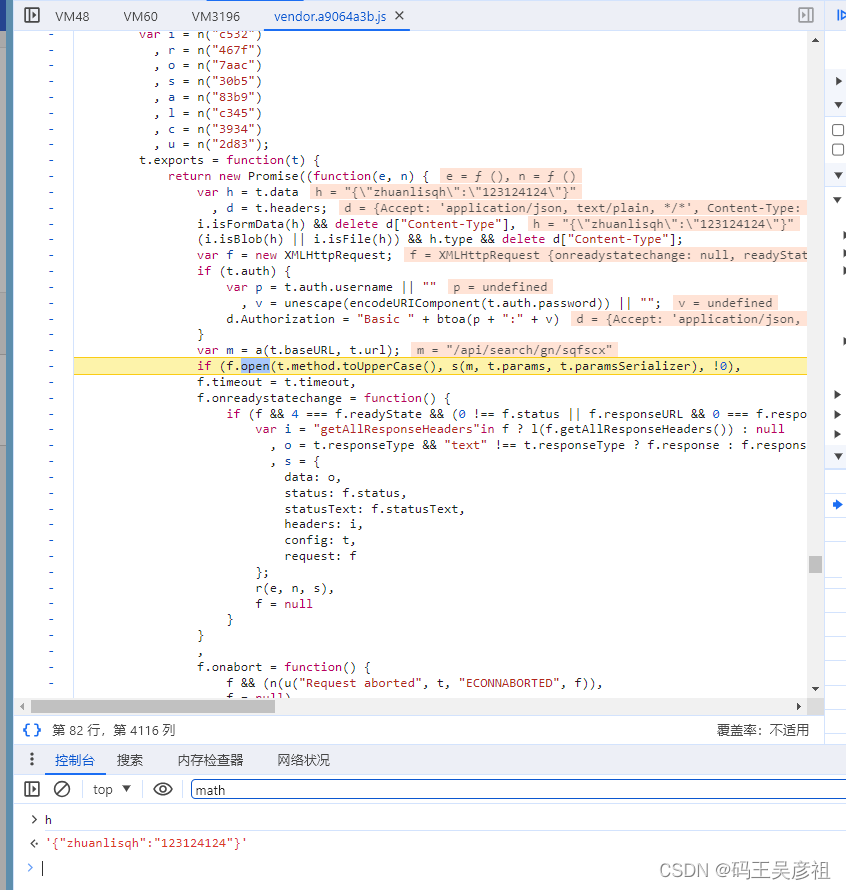
由于现在网上涉及到需要瑞数的解决方案,这里使用补环境的方法解决,拿到最终cookie
下面组装content、加密js,这里展示部分代码,需要补的环境有window、navigator、location、document、div等
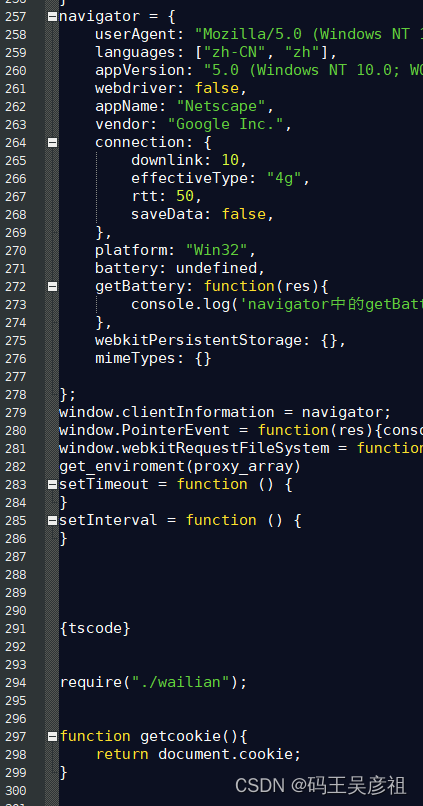
运行js后拿到cookie

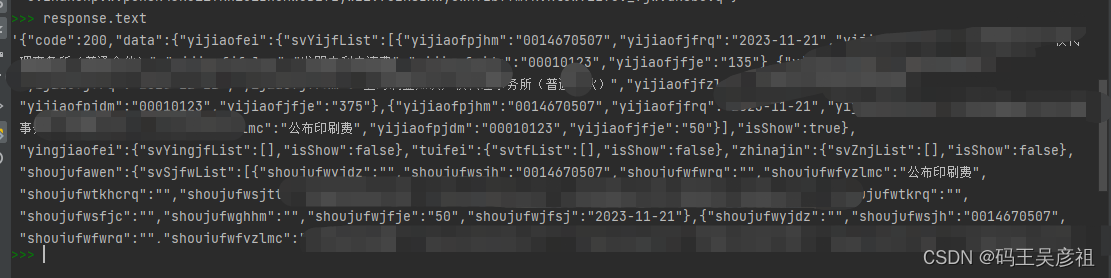
使用cookie请求后拿到最终数据















 3859
3859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











