







一、概述

Apache Spark是一个快如闪电的统一分析引擎(并没有提供数据存储的方案)
快如闪电(相比于传统的大数据处理方案MapReduce):
- Spark将一个复杂的计算任务Job拆分为多个细粒度的Stage,每一个Stage都可以分布式并行计算;对于MapReduce初代的计算引擎,它将任务拆分了粗粒度的MapTask和ReduceTask,对于特别复杂的计算任务,我们需要将多个MapReduce Job串联起来;
- Spark内存式的计算引擎;对于MapReduce基于磁盘的计算引擎;
- Spark中间计算结果支持缓存的,极大提高计算效率,这种缓存可以应用于结果复用和故障恢复;对于MapReduce中间结果需要溢写在磁盘;
统一(提供了大数据处理的所有主流方案):
- 批处理(Batch Processing): Spark RDD,代替了Hadoop MapReduce
- 流处理(Streams Processing):Spark Streaming和Spark Structured Streaming,代替了Kafka Streams、Storm
- 交互式查询(SQL):Spark SQL,代替了Hive
- 机器学习(Machine Learning): Spark MLLib,代替了Mahout
- 图形计算(Graph):Spark Graphx,基于图形存储的NoSQL数据库的计算支持(Neo4J)
- Spark生态库: 解决其它大数据处理问题
特点
- 高效:实现高性能的批和流计算支持,使用了非常先进的DAG Scheduler(有向无环图调度器)是一种查询优化和物理执行引擎
- 易用:提供了超过80个高阶函数简化了分布式并行应用的开发,并且支持多种编程语言(Java、Python、Scala、R)
- 通用:集成了多种数据处理方案,如SQL、Batch、Streaming、ML、Graph;
- 运行环境:支持多种资源管理调度系统,如YARN、Apache Mesos、K8S、Standalone等;
二、MapReduce VS Spark
MapReduce作为第一代大数据处理框架,在设计初期只是为了满足基于海量数据级的海量数据计算的迫切需求。自2006年剥离自Nutch(Java搜索引擎)工程,主要解决的是早期人们对大数据的初级认知所面临的问题。

整个MapReduce的计算实现的是基于磁盘的IO计算,随着大数据技术的不断普及,人们开始重新定义大数据的处理方式,不仅仅满足于能在合理的时间范围内完成对大数据的计算,还对计算的实效性提出了更苛刻的要求,因为人们开始探索使用Map Reduce计算框架完成一些复杂的高阶算法,往往这些算法通常不能通过1次性的Map Reduce迭代计算完成。由于Map Reduce计算模型总是把结果存储到磁盘中,每次迭代都需要将数据磁盘加载到内存,这就为后续的迭代带来了更多延长。
2009年Spark在加州伯克利AMP实验室诞生,2010首次开源后该项目就受到很多开发人员的喜爱,2013年6月份开始在Apache孵化,2014年2月份正式成为Apache的顶级项目。Spark发展如此之快是因为Spark在计算层方面明显优于Hadoop的Map Reduce这磁盘迭代计算,因为Spark可以使用内存对数据做计算,而且计算的中间结果也可以缓存在内存中,这就为后续的迭代计算节省了时间,大幅度的提升了针对于海量数据的计算效率。

Spark也给出了在使用MapReduce和Spark做线性回归计算(算法实现需要n次迭代)上,Spark的速率几乎是MapReduce计算10~100倍这种计算速度。

不仅如此Spark在设计理念中也提出了One stack ruled them all战略,并且提供了基于Spark批处理至上的计算服务分支例如:实现基于Spark的交互查询、近实时流处理、机器学习、Grahx 图形关系存储等。
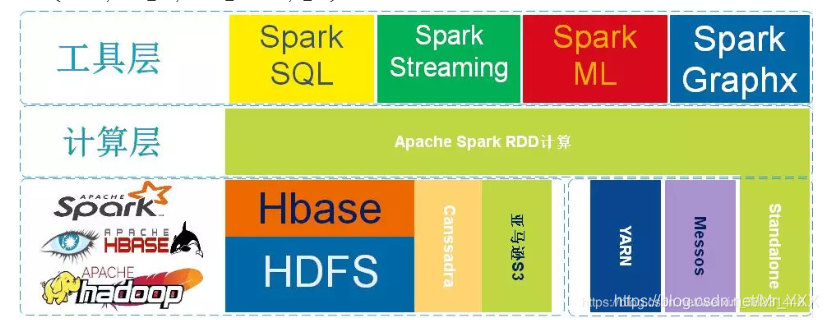
从图中不难看出Apache Spark处于计算层,Spark项目在战略上启到了承上启下的作用,并没有废弃原有以hadoop为主体的大数据解决方案。因为Spark向下可以计算来自于HDFS、HBase、Cassandra和亚马逊S3文件服务器的数据,也就意味着使用Spark作为计算层,用户原有的存储层架构无需改动。
三、计算流程
因为Spark计算是在MapReduce计算之后诞生,吸取了MapReduce设计经验,极大地规避了MapReduce计算过程中的诟病,先来回顾一下MapReduce计算的流程。
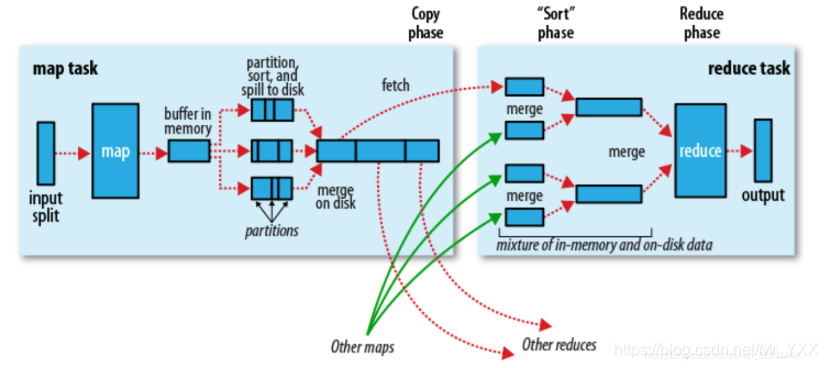
总结一下几点缺点:
1)MapReduce虽然基于矢量编程思想,但是计算状态过于简单,只是简单的将任务分为Map state和Reduce State,没有考虑到迭代计算场景。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









