










点个关注吧,球球啦!
spark源码剖析相关:
spark Standalone master启动流程 https://blog.csdn.net/Mr_kidBK/article/details/105131444
Standalone worker启动流程 https://blog.csdn.net/Mr_kidBK/article/details/105356632
前言
本文章是对standalone方式启动spark的源码角度说明从执行shell脚本到master启动主要步骤,spark版本2.1.x,信息来源为spark官网和源码,如果与网上其他文章有较大的偏差,建议以我为准!
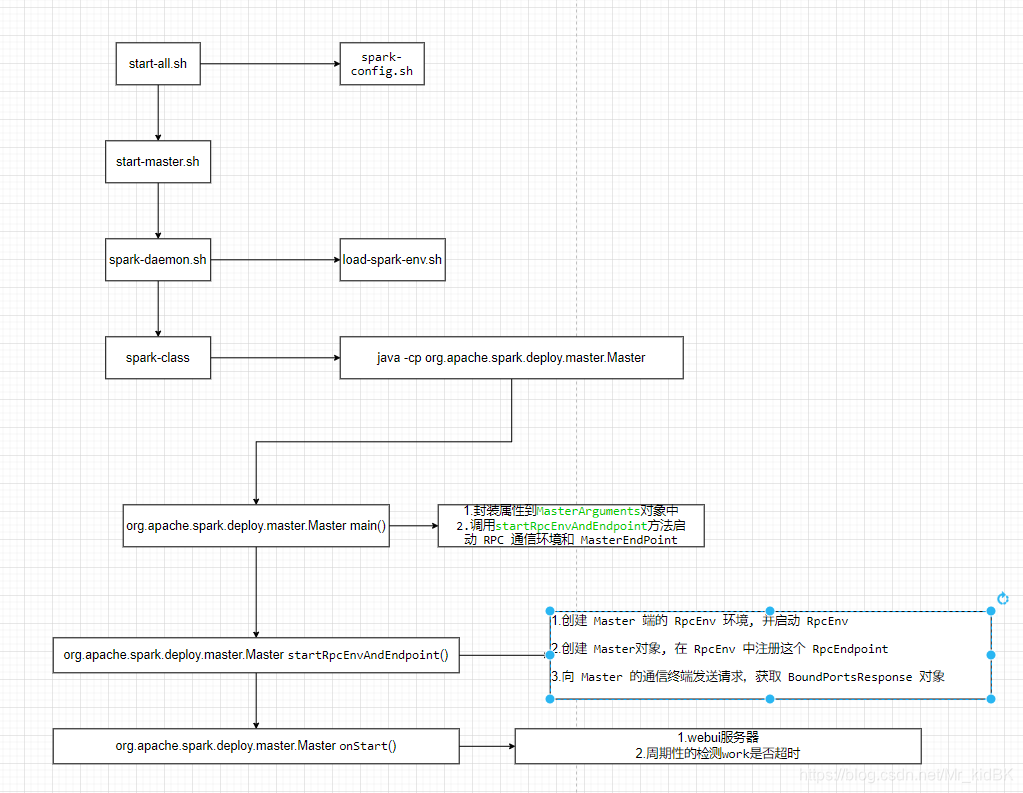
启动脚本
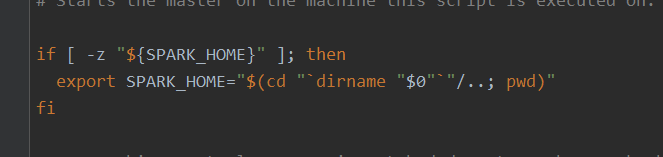
首先运行start-master.sh时,如果没有定义$SPARK_HOME脚本会自动帮我们创建SPARK_HOME变量
依次执行spark-config.sh load-spark-env.sh 加载配置
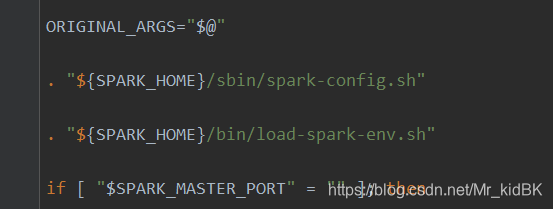
然后执行spark-daemon.sh start $CLASS,值得一提的是此时CLASS为CLASS=“org.apache.spark.deploy.master.Master”

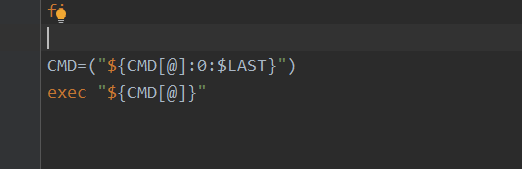
spark-daemon.sh 最终会执行spark-class脚本

spark-class 会执行java -cp命令运行jvm虚拟机,加载/jars中的所有jar包并从org.apache.spark.deploy.master.Master开始执行。
Master类
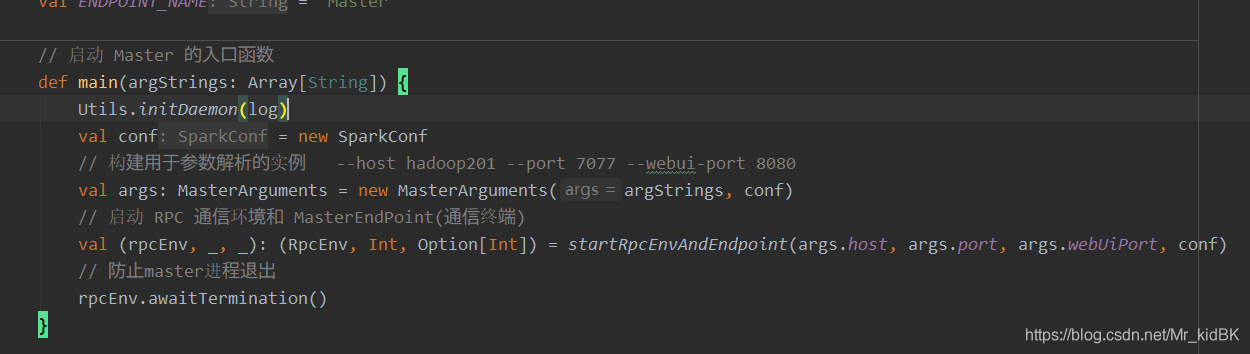
main方法一共做了两件事:
1 . 构建用于参数解析的实例
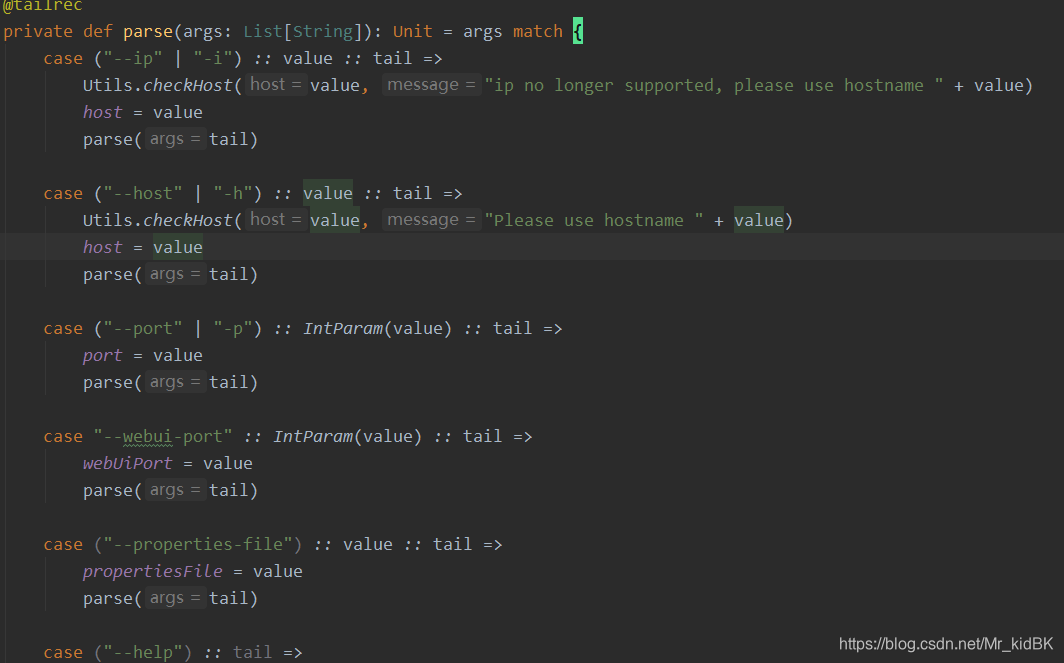
对传过来的参数进行封装,里面代码还是写的很巧妙的,使用了模式匹配+尾递归的方法,代码简洁且不会有栈溢出的风险,是值得学习的写法,大家有兴趣可以了解下。
2 . 创建 RPC 通信环境和 MasterEndPoint
创建RPCEnv环境,1.2之前用的是Akka1.3及以后用的是Netty通信框架,这里事实上是NettyRpcEnv

 创建master对象,并将这个对象在RPC环境中注册,最终将引用返回。
创建master对象,并将这个对象在RPC环境中注册,最终将引用返回。
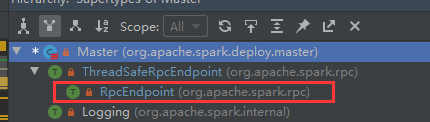
 你可能会问,为什么Master对象可以在RPCEnv注册,因为Master就是一个RpcEndpoint,它的爷爷是RpcEndpoint
你可能会问,为什么Master对象可以在RPCEnv注册,因为Master就是一个RpcEndpoint,它的爷爷是RpcEndpoint
 向终端发送ask请求,由于master有可能此时还没起来,所以这里使用了askWithRetry方法,保证请求发出。
向终端发送ask请求,由于master有可能此时还没起来,所以这里使用了askWithRetry方法,保证请求发出。

NettyRPC框架执行
你可能会问,这就完了?不,事情远没有那么简单,我们来看RPCEndPoint生命周期:
constructor -> onStart -> receive* -> onStop

可以看到这里框架会保证自动调用onstart方法
那么它究竟是如何调用的呢?
我们在创建NettyRPCEnv的时候,会初始化一个Dispatcher分发器
 在创建Master后注册到RPC环境时,会调用dispatcher的registerRpcEndpoint方法
在创建Master后注册到RPC环境时,会调用dispatcher的registerRpcEndpoint方法

在这个方法中会创建一个EndpointData对象,这个对象包含了maser在RPCEnv中的一些属性
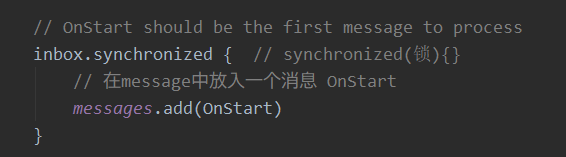
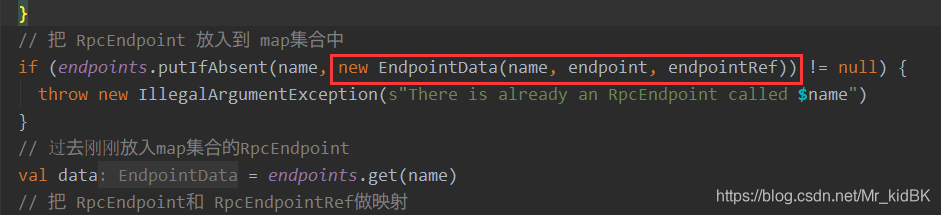 在这个EndPoint的收件箱Inbox对象被创建时,会初始化一个message,这个message必须是第一个被处理,且就是OnStart
在这个EndPoint的收件箱Inbox对象被创建时,会初始化一个message,这个message必须是第一个被处理,且就是OnStart
在process方法中我们可以找到RpcEndpoint的onStart方法
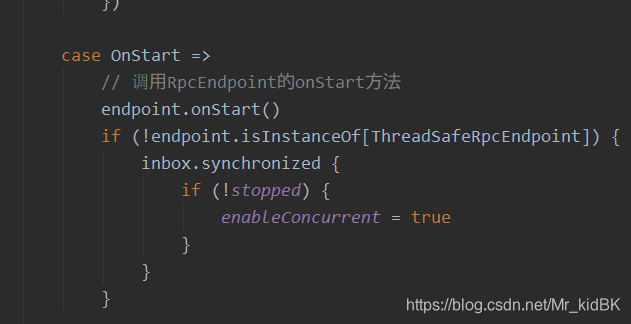
onStart方法:
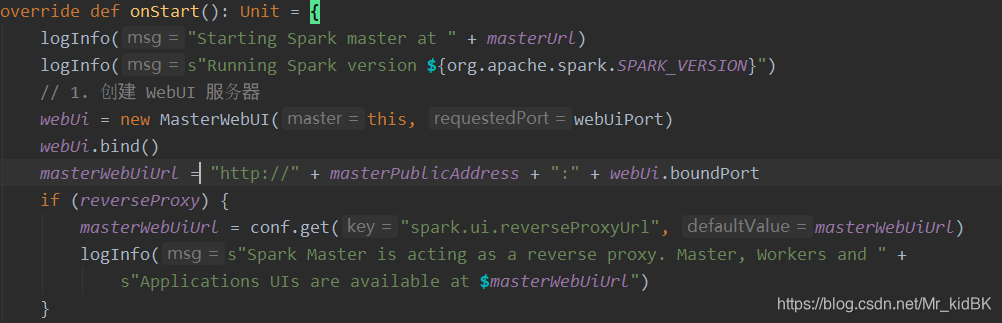
那么Master的onstart方法又做了什么事情呢
1 . 创建 WebUI 服务器
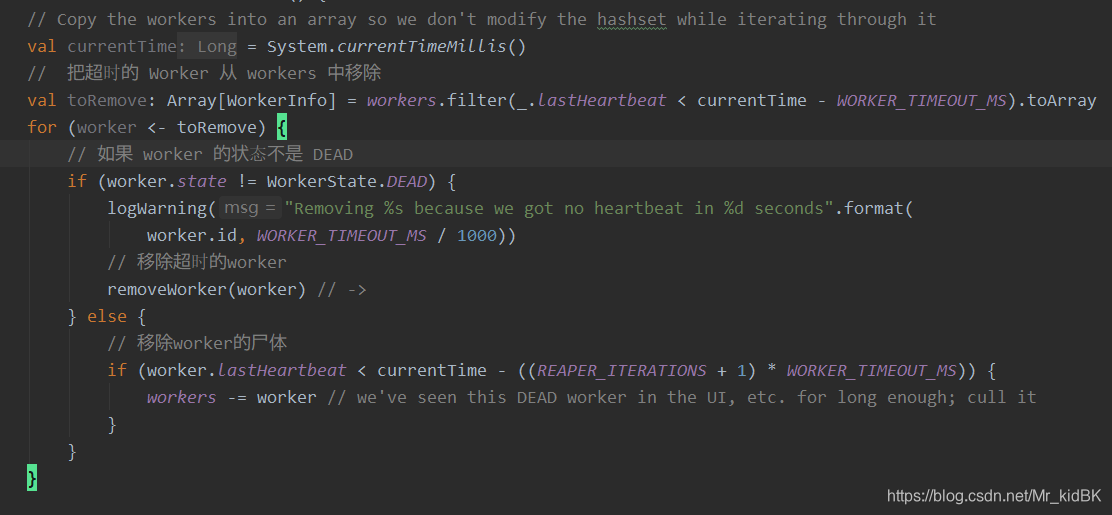
 2. 按照固定的频率去启动线程来检查 Worker 是否超时. 其实就是给自己发信息: CheckForWorkerTimeOut
2. 按照固定的频率去启动线程来检查 Worker 是否超时. 其实就是给自己发信息: CheckForWorkerTimeOut
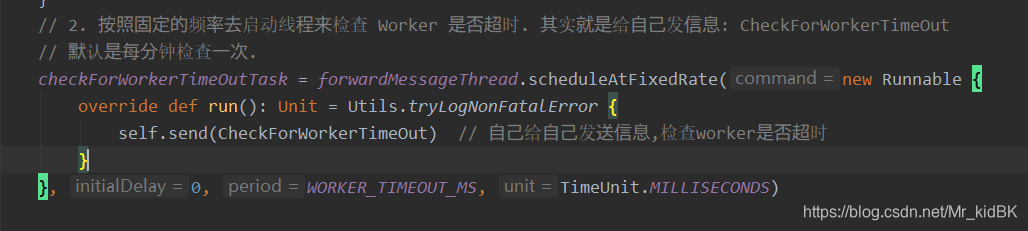 默认60秒超时
默认60秒超时

60秒内未向master发送心跳的worker会被移除
 原创不易,有空我会把woker的也整理出来,点个关注吧,球球啦!
原创不易,有空我会把woker的也整理出来,点个关注吧,球球啦!
点个赞再走,球球啦!
原创不易,白嫖不好,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
本博客仅发布于CSDN—一个帅到不能再帅的人 Mr_kidBK。转载请标明出处。
https://blog.csdn.net/Mr_kidBK
点赞!收藏!转发!!!么么哒!
点赞!收藏!转发!!!么么哒!
点赞!收藏!转发!!!么么哒!
点赞!收藏!转发!!!么么哒!
点赞!收藏!转发!!!么么哒!
————————————————
















 1973
1973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









