






Python自学指令合集
线程
线程一 开启线程
#导入模块
import time
import threading
from time import ctime,sleep
#定义函数
def A(n):
print('ok A', ctime())
sleep(1)
print ('end A', ctime())
def B(n):
print('ok B', ctime())
sleep(2)
print('end B', ctime())
#创建线程t1和t2
t1 = threading.Thread(target=A, args=(10,))
t2 = threading.Thread(target=B, args=(20,))
#开启线程t1和t2
t1.start()
t2.start()
#输出主函数
print('________________main_________________', ctime())
输出结果:
ok A Fri Aug 16 11:27:51 2019
ok B Fri Aug 16 11:27:51 2019
main_____ Fri Aug 16 11:27:51 2019
end A Fri Aug 16 11:27:52 2019
end B Fri Aug 16 11:27:53 2019
线程二 线程中join()方法的使用
1.在程序不使用join方法的时候:
#导入模块
import time
import threading
from time import ctime,sleep
#定义函数
def A(n):
print('ok A', ctime())
sleep(1)
print ('end A', ctime())
def B(n):
print('ok B', ctime())
sleep(3)
print('end B', ctime())
创建线程t1和t2
t1 = threading.Thread(target=A, args=(10,))
t2 = threading.Thread(target=B, args=(20,))
开启线程t1和t2
t1.start()
t2.start()
#使用join方法
#t1.join()
#t2.join()
输出主函数
print('________________main_________________', ctime())
输出结果是:
ok A Fri Aug 16 11:52:10 2019
ok B Fri Aug 16 11:52:10 2019
_ main__ Fri Aug 16 11:52:10 2019
end A Fri Aug 16 11:52:11 2019
end B Fri Aug 16 11:52:13 2019
结论:
在没有使用join方法的时候,首先输出的线程一二和主线程,然后输出线程一二。
2.在使用join方法的情况下:
#导入模块
import time
import threading
from time import ctime,sleep
#定义函数
def A(n):
print('ok A', ctime())
sleep(1)
print ('end A', ctime())
def B(n):
print('ok B', ctime())
sleep(3)
print('end B', ctime())
创建线程t1和t2
t1 = threading.Thread(target=A, args=(10,))
t2 = threading.Thread(target=B, args=(20,))
开启线程t1和t2
t1.start()
t2.start()
#使用join方法
t1.join()
t2.join()
#输出主函数
print('________________main_________________', ctime())
输出结果:
ok A Fri Aug 16 11:54:57 2019
ok B Fri Aug 16 11:54:57 2019
end A Fri Aug 16 11:54:58 2019
end B Fri Aug 16 11:55:00 2019
_ main__ Fri Aug 16 11:55:00 2019
结论:
在使用join方法的情况下,主函数main会等待线程运行结束后,再执行主函数。
3.当join方法放置位置不同的时候:
#导入模块
import time
import threading
from time import ctime,sleep
#定义函数
def A(n):
print('ok A', ctime())
sleep(1)
print ('end A', ctime())
def B(n):
print('ok B', ctime())
sleep(3)
print('end B', ctime())
#创建线程t1和t2
t1 = threading.Thread(target=A, args=(10,))
t2 = threading.Thread(target=B, args=(20,))
#开启线程t1和t2
t1.start()
t1.join()
t2.start()
#使用join方法
t2.join()
#输出主函数
print('________________main_________________', ctime())
输出:
ok A Fri Aug 16 11:57:51 2019
end A Fri Aug 16 11:57:52 2019
ok B Fri Aug 16 11:57:52 2019
end B Fri Aug 16 11:57:55 2019
__ main___ Fri Aug 16 11:57:55 2019
结论:
可以看出,此时的结果如同串行结果,子啊线程一执行完成之后,再开始执行线程二,可以将join方法理解为阻塞。
线程三:锁的概念
第一步:
一个减一的多线程程序
#导入模块
import threading
import time
from time import ctime,sleep
num=100
#定义函数
def addNum():
global num
num-=1
# 创建列表
thread_list=[]
# 写一个循环,同时执行100个线程
for i in range(100):
t=threading.Thread(target=addNum)
t.start()
thread_list.append(t)
# 给每个线程添加一个join方法,为了让print函数随后输出
for t in thread_list:
t.join()
# 输出print函数
print ('final num:',num)
输出结果:
final num: 0
结论:没有任何问题,就是一个减一的操作。
第二步:
对原始程序进行修改:
def addNum():
global num
# num-=1
temp=num
num=temp-1
print()
#修改部分
现程序:
#导入模块
import threading
import time
from time import ctime,sleep
num=1000
#定义函数
def addNum():
global num
temp=num
sleep(0.001)
num=temp-1
# num-=1
# 创建列表
thread_list=[]
# 写一个循环,同时执行100个线程
for i in range(1000):
t=threading.Thread(target=addNum)
t.start()
thread_list.append(t)
# 给每个线程添加一个join方法,为了让print函数随后输出
for i in thread_list:
t.join()
# 输出print函数
print ('final num:',num)
输出:
final num: 916(在变化)
结论:

如图所示, python解释器调用原生线程,在cpu上执行,由于sleep,会自动释放gil,此时并没有执行减一,所以导致出现这种情况。
第三步:加锁
修改代码
r=threading.Lock()
#定义函数
def addNum():
global num
r.acquire()
temp=num
sleep(0.1)
num=temp-1
r.release()
修改后代码:
##导入模块
import threading
import time
from time import ctime,sleep
num=100
r=threading.Lock()
#定义函数
def addNum():
global num
r.acquire()
temp=num
sleep(0.1)
num=temp-1
r.release()
# num-=1
# 创建列表
thread_list=[]
# 写一个循环,同时执行100个线程
for i in range(100):
t=threading.Thread(target=addNum)
t.start()
thread_list.append(t)
# 给每个线程添加一个join方法,为了让print函数随后输出
for i in thread_list:
t.join()
# 输出print函数
print ('final num:',num)
运行结果:
final num: 0
结论:
加锁之后,程序就会将锁住的地方执行完成再释放gil。
不用join反而用锁的原因是,如果用了join,整个函数里面就是串行的了,如果使用锁,则只有锁住的地方才是串行,而函数的其余地方任然是多线程。
线程四:守护线程
# !/usr/bin/python
# coding=utf-8
import threading
import time
def a():
time.sleep(3)
print('a hanshu')
w =threading.Thread(target=a)
w.setDaemon(True)
w.start()
print('main_____')
一旦主线程结束后,子线程也就结束。
队列
Queue模块 队列模块
FIFO——先进先出
q=queue.Queue(4) 创建一个队列含四个坑位
q.put(‘a’) 在q中填满第一个坑位
q.put(‘b’) 在q中填满第二个坑位
q.full() 判断q队列是否为满的
q.empty() 判断q队列是否为空的
q.qsize() 判断当前队列中的数量
q.get() 从q中取出第一个值
Subprocess
subproces.call 默认将回显打印打印出来
stdout 将回显指定位置放置
subprocess.call(['ping', '118.25.52.128', '-n' ,'1' ],shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
模块
sys模块
sys模块:
(和python解释器进行交互)
1.sys.argv
效果:

2.sys.path
相当于环境变量,打印出来是一个列表:

当我们使用import导入的时候,会从按照这个顺序进行查找。
如果没有,则需要我们自行进行添加
添加的方式例如:sys.path.insert(0,path)
示例:
当前环境
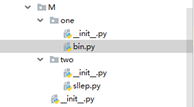
我们在two中写一个普通的函数,我们在one中进行调用
Step one:
在bin中输出sys.path查看当前的环境
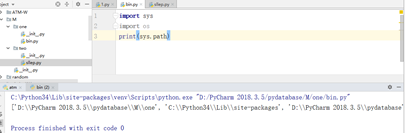
发现,当前环境查找顺序为:当前目录——site-packetage——pydatabase,并无我们需要的two路径,所以需要我们自行添加
Step two:
添加sys.path

3.sys.platform
Windows——输出win32
Linux(kali)——输出linux2
文件读写
读:
打开文本: f=open(r’D:\abc.txt’)
设置文本指针: f.seek(0)
打开所有文本: f.read()
打开指定字符数量文本:f.read(5)
读行数: f.readline()
读所有行数: f.readlines(0)
关闭文件: f.close()
写: f=open(r’D:\abc.txt’,’w’)
写入: fw.write(‘woaini’) 覆盖原有
追加: f=open(r’D:\abc.txt’,’a’)
写入: fa.writelines([fa mode write’,’2kfja’])
Json
当我们想把一个字典放入一个文件中时,文件报错,提示字符类型必须是str。
a= {'height':180,'sex':'boy'}
with open('a.txt','w') as f:
f.write(a)
#程序报错
#TypeError: write() argument must be str, not dict
a= {'height':180,'sex':'boy'}
import json
with open('a.txt','w') as f:
f.write(json.dumps(a))
#程序正常执行,成功存入
#a.txt内容——{"height": 180, "sex": "boy"}
with open('a.txt','r') as f:
data=json.load(f)
print(data)
print(type(data))
#加载(读取)a.txt中的内容
pickle
Json对函数对象无法进行序列化,而pickle可以
用法同json
模块
OS模块
os.getcwd() 获取当前工作目录
os.chdir(r’D:) 修改工作目录
os.curdir 一个.
os.pardir 两个…
os.makedirs('a/b/c;) 生成多层递归目录
os.mkdir(‘a’) 生成目录,只能一个一个创建
os.removedirs(‘a/b/c’) 删除目录,如果目录上一级是空的,则一并删除
os.rmdir(‘a/b/c’) 删除指定文件
os.listdir(‘D://’) 显示当前目录内容
os.sep 当前目录下的分隔符
os.linesep 行终止符
os.pathsep 文件路径分隔符
os.system(‘dir’) 运行shell命令,直接显示
os.environ 环境变量
os.path.abspath(’./1.py’) 拿文件的绝对路径
os.path.split(r’D:\PyCharm 2018.3.5\pydatabase\魔法方法’)
效果:(‘D:\PyCharm 2018.3.5\pydatabase’, ‘魔法方法’)
os.path.dirname(D:\a\b’) 显示当前文件所在目录
os.path.basename(‘D:\PyCharm 2018.3.5\pydatabase’, ‘魔法方法’) 返回路径最后的文件名
os.path.join(‘ss’+‘c’) 字符拼接
SYS模块
sys.platform #返回当前操作系统名称
sys.argv #返回程序本身路径,可在后添加参数
sys.path #打印程序环境变量
sys.stdin.readline().strip() #标准输入
sys.version #返回当前系统版本
RE模块
#元字符
#1.通配符((((.))))
a=re.findall('w..l','hello world')
print ('1',a)
print('')
#(((.)))代指所有得符号 除了换行符
#只能代指任意一个字符
#2.尖角符(((^)))
#只看开始,从开头开始匹配
b=re.findall('^h...o','henlojadflkjfehello')
print('2',b)
print('')
#3.dollor符((($)))
#只看结尾,从结尾开始匹配
ret=re.findall('a..x$','fasdjflkasjdfkljakljealexakdx')
print('3',ret)
print('')
#4.重复匹配(((*)))
#【0,+无穷】
ret=re.findall('ab*','csdfsdfdsfweabbbbbbb')
print('4',ret)
print('')
#5.重复匹配(((+)))
#可以匹配a和【1,无穷】个b
#【1,+无穷】
ret=re.findall('ab+','csdfsdfdsfweabbbb')
print('5',ret)
print('')
#6.重复匹配(((?)))
#【0,1】
ret=re.findall('a?b','acsdfsdabfdsfweba')
print('6',ret)
print('')
#7.重复匹配((({})))
#贪婪匹配
#【a,b】
#{1,}代表1到正无穷
ret=re.findall('a{1,3}b','aaaasdab')
print('7',ret)
print('')
#8.选择(((【】)))
选择
ret=re.findall('a[c,d]b','acb adb acdb')
print('8',ret)
ConfigParser模块
import configparser
config=configparser.ConfigParser()
config['DEFAULT']={'AA':'1','BB':'2'}
config['A']={'CC':'3','DD':'4'}
config['B']={'EE':'5','FF':'6'}
with open('cons','w') as configfile:
config.write(configfile) #将文件保存在cons这个文件里面
Logging模块
logging.basicConfig(
level=logging.DEBUG,
# 日志格式
# 时间、代码所在文件名、代码行号、日志级别名字、日志信息
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
# 打印日志的时间
datefmt='%a, %d %b %Y %H:%M:%S',
# 日志文件存放的目录(目录必须存在)及日志文件名
filename='test.log',
# 打开日志文件的方式
filemode='a'
)
logger=logging.getLogger()
fh=logging.FileHandler(‘test.log’)#文件对象
ch=logging.StreamHandler()#屏幕对象
formatter=logging.Formatter(’%(asctime)s’)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh)
logger.addHandler(ch)
logger.setLevel(logging.DEBUG)
logging.debug(‘debug message1’)
logging.info(‘info message1’)
logging.warning('warning1 ')#默认
logging.error(‘error message1’)
logging.critical(‘critical message1’)
函数
静态方法
'''静态方法'''
class foo:
@staticmethod
def sta():
print('123')
foo.sta()
多继承
class A:
def a(self):
print("i am 'a'")
self.m()
def m(self):
print("i am 'm'")
class B:
def m(self):
print("i am 'Mb'")
class W(B,A):
pass
obj=W()
obj.a()
输出:
i am ‘a’
i am ‘Mb’
闭包
def outer():
x=10
def inner():#条件一 内部函数
print(x)#条件二 外部环境的一个变量
return inner#结论: 内部函数inner就是一个闭包
闭包:
闭包=内部函数+内置函数的环境
闭包的定义:如果在一个内部函数里,对在外部作用域(但不是再全局作用域)的变量进行应用,那么内部函数就呗认为是闭包。
如上所示,我的inner函数脱离了outer()但是依然可以用x=10 这个值
@property@setter@deleter
class BB:
#@property
def foo(self):
print('hello')
a =BB()
a.foo()
class BB:
@property
def foo(self):
print('hello')
a =BB()
a.foo
@property 使调用方法的时候可以像调用属性一样调用
class Student(object):
x=100
@property
def per(self):
x=100
return x
@per.setter
def per(self,val):
print(val)
@per.deleter
def per(self):
print(666)
obj=Student()
obj.per = 123
del obj.per
#setter是设置参数















 756
756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









