







高效导入数据:

javaAPI通过put缓存导入数据
这种方法对于动态的少量的数据导入适用,效率比较慢,会先通过java写入hbase中的缓存中,然后等待满足条件后再刷写落盘
参考链接:缓存方式 https://blog.csdn.net/asd136912/article/details/100825957
bulk loading工具
这种方式适用于大量的静态的数据,效率较高,不经过内存,直接生成hfile文件
参考:Hadoop权威指南594页
示例:导入csv文件
0,准备表:
create "tb_a" , "info1"
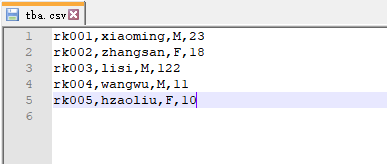
1,准备测试文件:tba.csv
2,上传测试文件到hdfs
hdfs dfs -put ./tba.csv /test/3,使用importtsv将测试文件转为hfile
linux命令行中执行:
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=, -Dimporttsv.columns='HBASE_ROW_KEY,info1:name,info1:gender,info1:age' -Dimporttsv.bulk.output=/test/out tb_a /test/tba.csv
说明:
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.separator=, \ --指定分隔符
-Dimporttsv.columns='HBASE_ROW_KEY,info1:name,info1:gender,info1:age' \ --Hbase列族和列名
-Dimporttsv.bulk.output=/test/out \ --输出Hfile文件在hdfs中的路径
tb_a \ -- hbase中的表
/test/tba.csv --源数据文件(HDFS中的路径)
执行成功后hdfs中生成Hfile文件:

4,将hfile注入hbase
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /test/out/ tb_a导入成功:

经测试:如果csv文件中少了部分字段也可以导入到hbase中(,,之间空的话会插入一个空值的cell),但格式要正确















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









