









接下来要修改底层,NettyRuntime类 这个部分(即 设置可用处理器)
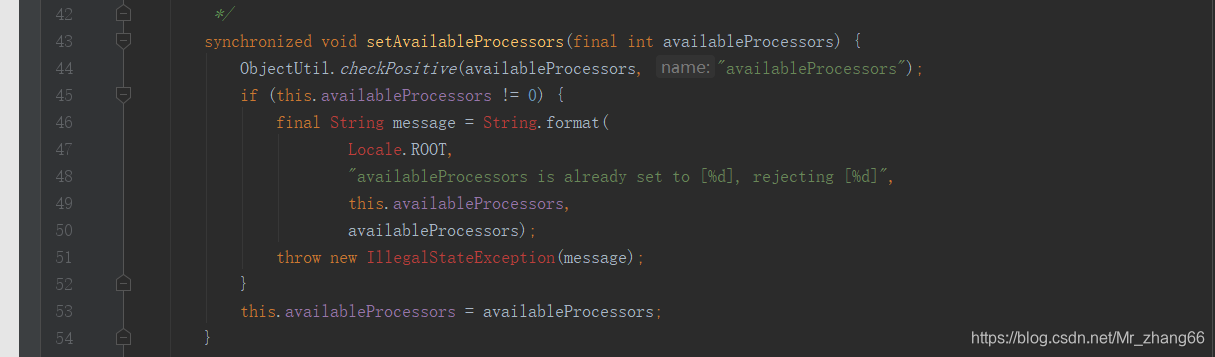
"availableProcessors is already set to [%d], rejecting [%d]",
翻译:availableProcessors 已经被设置好了。
会报这个错,因为 redis和elastic search都基于Netty,所以会导致底层有冲突,所以报错。
冲突主要体现在es代码上,这个setAvailableProcessors方法是由es调用的,在Netty4Utils类中(一个es底层封装的类),
代码如下:
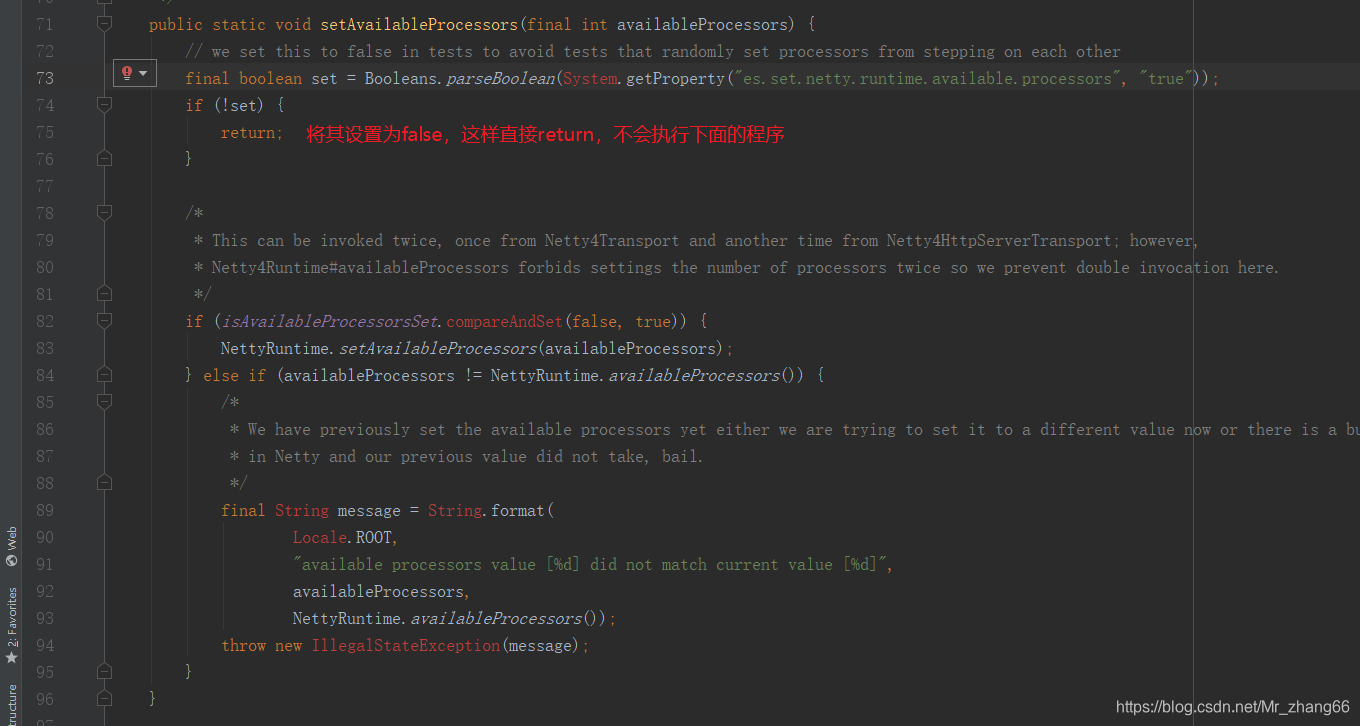
为了设置,要在community application中,添加
@PostConstruct//管理bean声明周期的注解
public void init() {
// 解决netty启动冲突问题
// see Netty4Utils.setAvailableProcessors()
System.setProperty("es.set.netty.runtime.available.processors", "false");
}
接着需要配置,
在discusspost中,原先是这样的,
在每个属性之前添加注解,
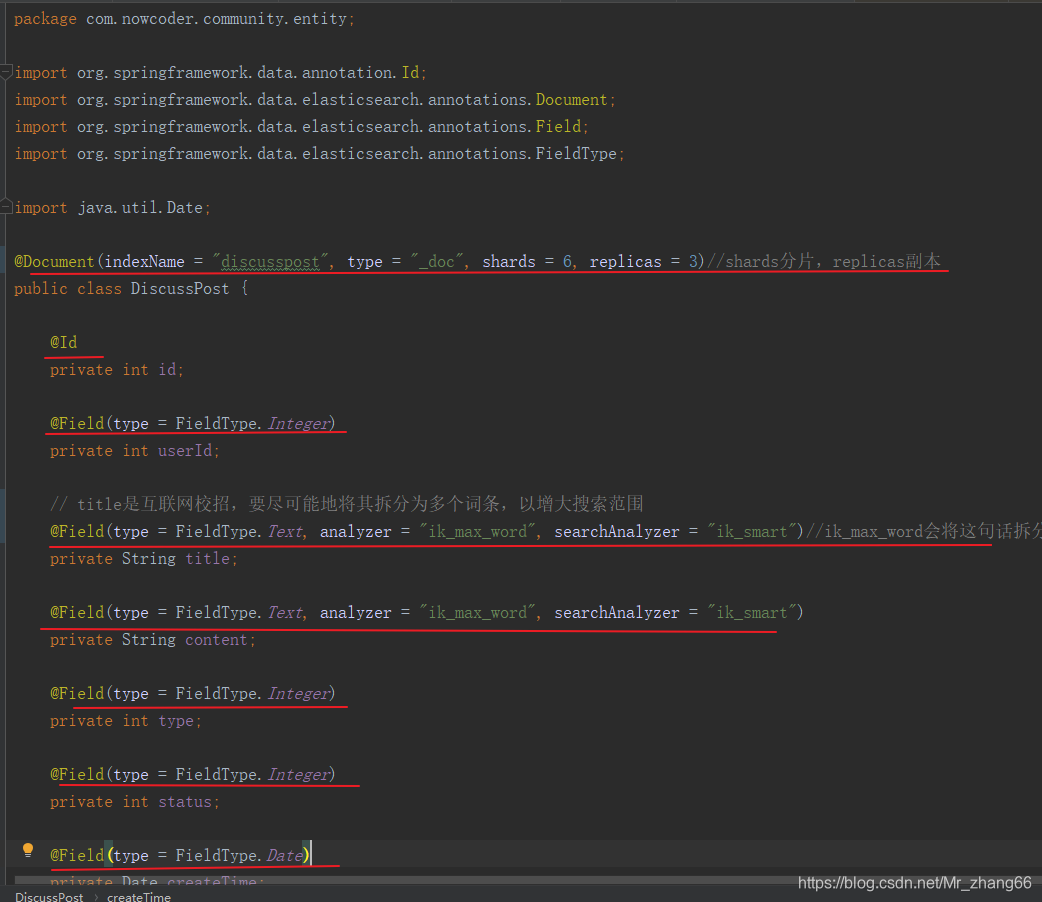
实体类加上这些注解后,和es之间便建立了联系,每个字段和es中的每个字段都建立了关系
接下来定义repository这个接口。
在dao中创建DiscussPostRepository接口
package com.nowcoder.community.dao.elasticsearch;
import com.nowcoder.community.entity.DiscussPost;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository //@mapper是mybatis的注解,Repository是spring提供的针对数据访问层的注解
public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost, Integer> {//接口要处理的实体类DiscussPost,实体类中的组件Integer
//该接口不需要新的,只继承 Elasticsearch即可
}
新建测试类
先查询。发现只要一个索引
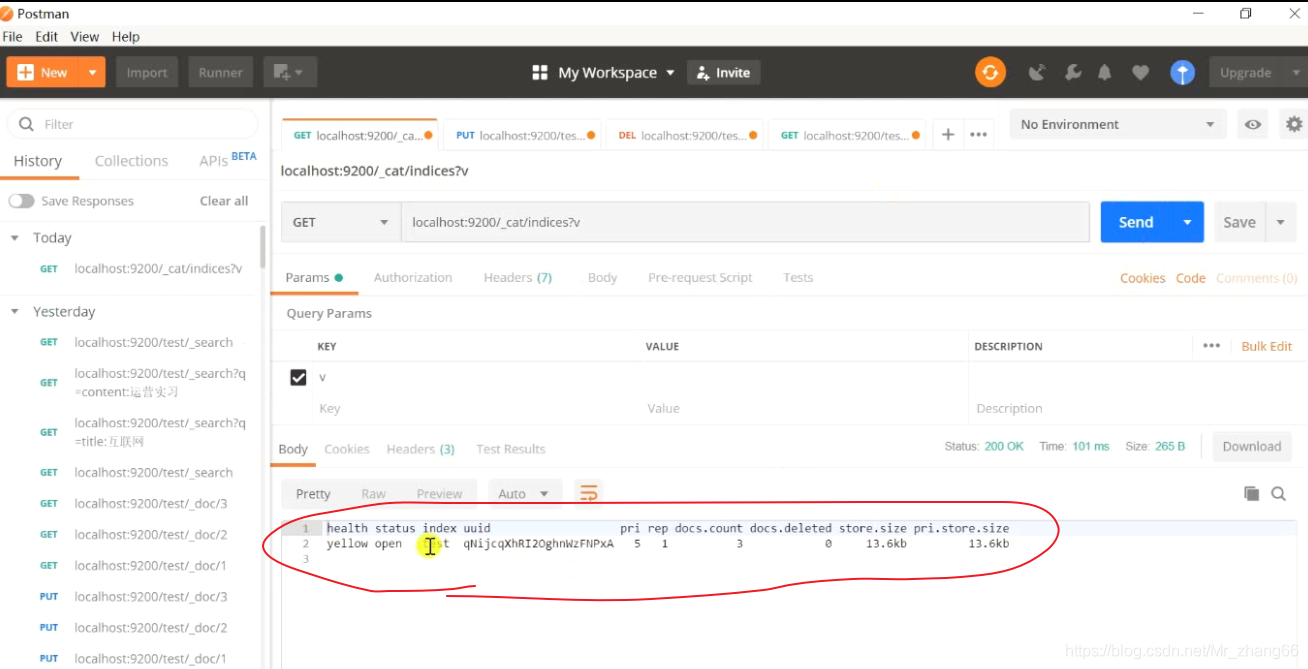
把mysql中这三条数据插入,

@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class ElasticsearchTests {
@Autowired
private DiscussPostMapper discussMapper;//注入discussMapper,方便从mysql中取出数据
@Autowired
private DiscussPostRepository discussRepository;//方便查数据
@Autowired
private ElasticsearchTemplate elasticTemplate;//有些情况ElasticsearchRepository 处理不了,需要ElasticsearchTemplate来处理
@Test
public void testInsert() {//往es里插入单条数据
discussRepository.save(discussMapper.selectDiscussPostById(241));
discussRepository.save(discussMapper.selectDiscussPostById(242));
discussRepository.save(discussMapper.selectDiscussPostById(243));
}
可以在其中查到:
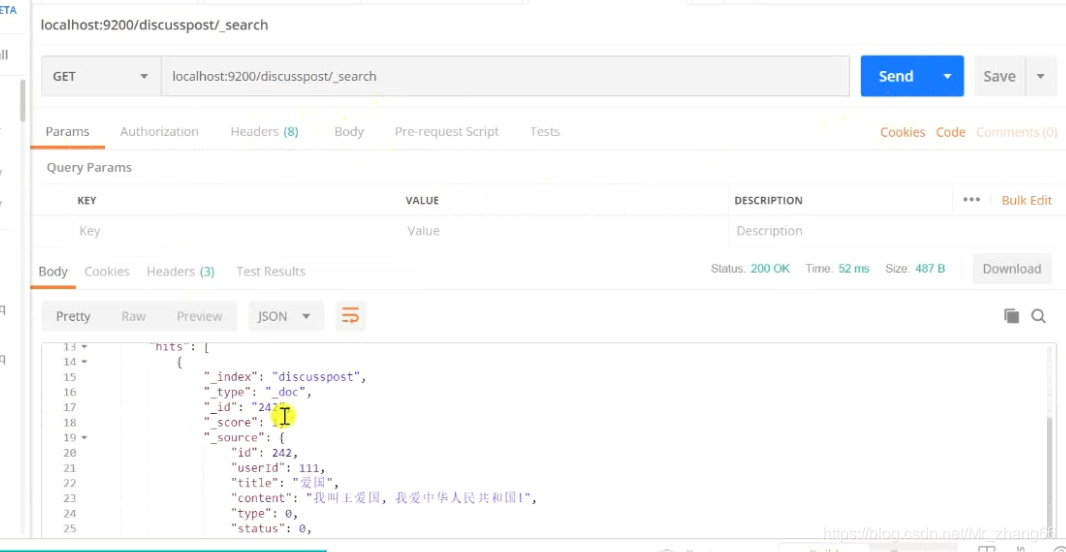
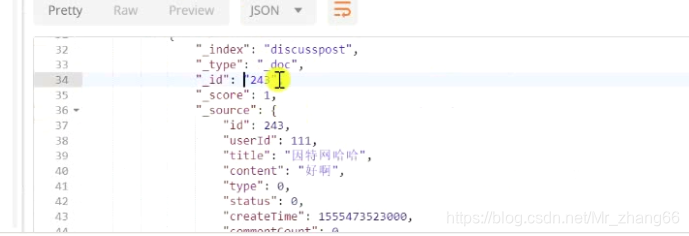
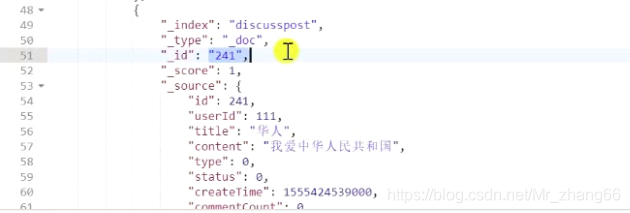
@Test
public void testInsertList() {//往es里插入多条数据
discussRepository.saveAll(discussMapper.selectDiscussPosts(101, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(102, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(103, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(111, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(112, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(131, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(132, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(133, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(134, 0, 100));
}
没有报错
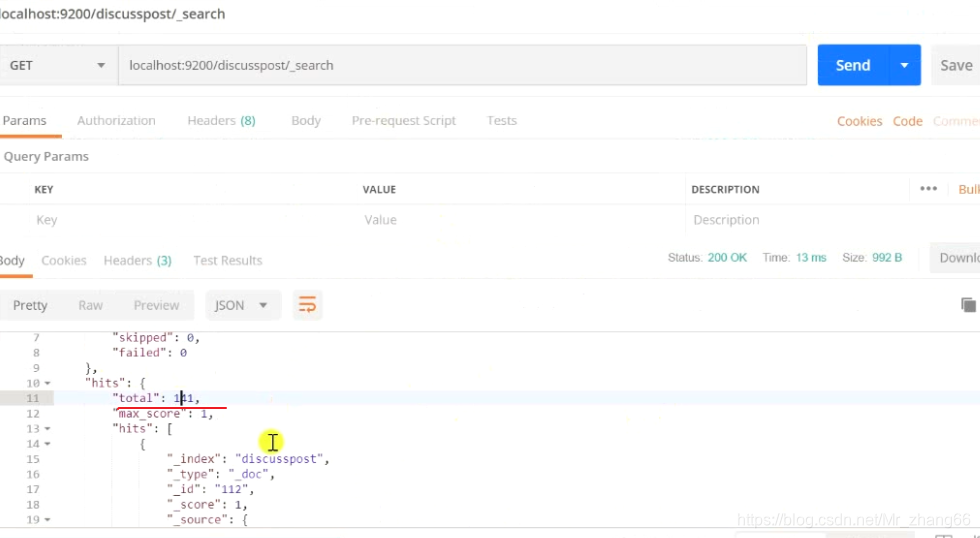
命中了141条数据,没有全列出来
测试:更改数据

更改其内容为:
@Test
public void testUpdate() {//修改数据
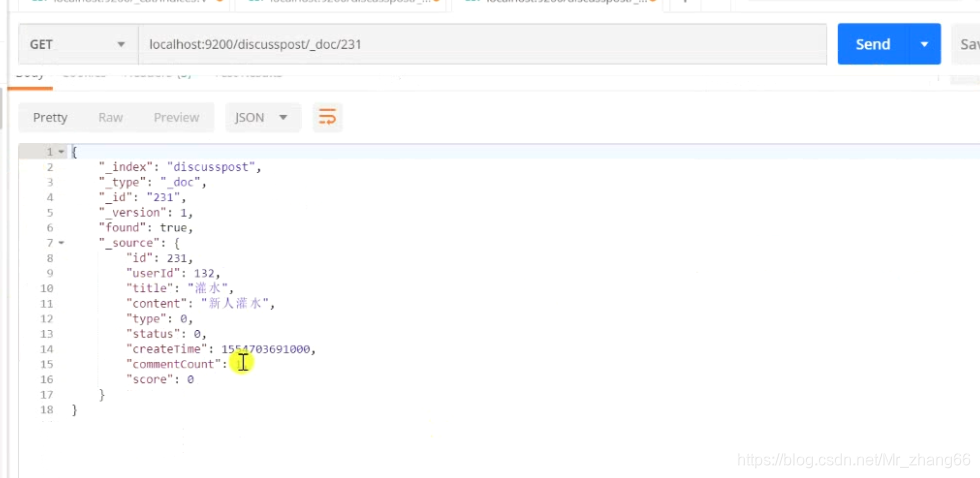
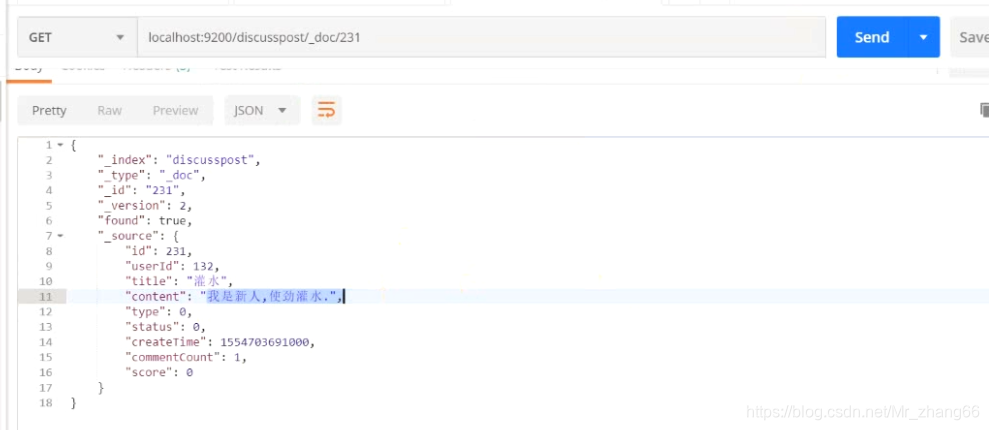
DiscussPost post = discussMapper.selectDiscussPostById(231);//被修改的数据
post.setContent("我是新人,使劲灌水.");
discussRepository.save(post);
}
再次查询:
测试删除数据
@Test
public void testDelete() {//删除数据
// discussRepository.deleteById(231);
discussRepository.deleteAll();删除索有数据
}
搜索,es最核心的功能。es可以把返回的关键词点亮,实现的机制是把标签点亮

@Test
public void testSearchByRepository() {//搜索,es最核心的功能。es可以把返回的关键词点亮,实现的机制是把标签点亮
SearchQuery searchQuery = new NativeSearchQueryBuilder()//spring提供的searchQuery接口
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))//NativeSearchQueryBuilder构建的实现类。withQuery里面是搜索条件。multiMatchQuery是多字段全文的搜索。"互联网寒冬"是搜索内容。
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))//构造排序条件。QueryBuilders是查询条件,SortBuilders是排序条件。type=1意味着置顶。status=1意味着加精。DESC是倒序排列,这样=1的会被排在前面
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))//状态加精会 算成一个分数,按分数来排序
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))//前两个都一样的话,按创造时间排序
.withPageable(PageRequest.of(0, 10))//从第0页开始,一页最多显示10条数据
.withHighlightFields(//指定哪些字段高亮显示
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),//title里面,preTags前置标签<em>,后置标签</em>
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();//build方法一执行会返回searchQuery
Page<DiscussPost> page = discussRepository.search(searchQuery);//用Page对象封装 查询到的
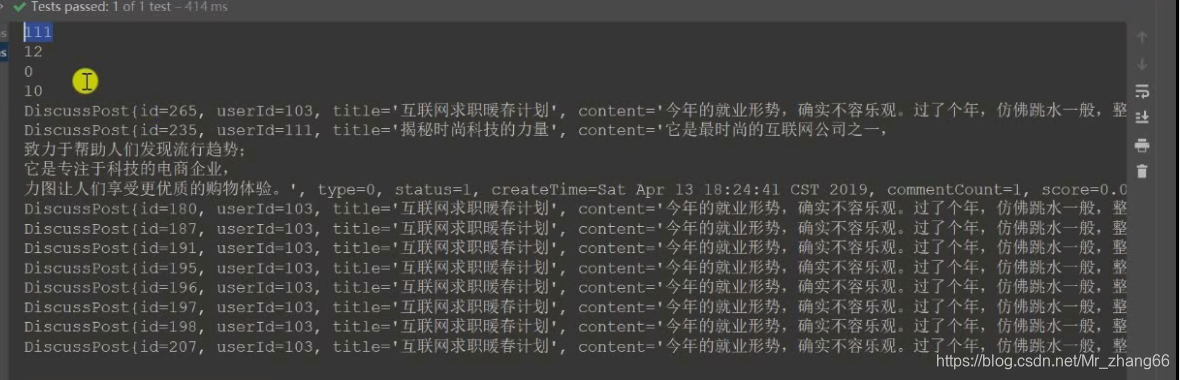
System.out.println(page.getTotalElements());//一共多少个数据匹配,111
System.out.println(page.getTotalPages());//一共有多少页,12(111条数据,每页显示10条,共有12页)
System.out.println(page.getNumber());//当前在第几页 0
System.out.println(page.getSize());//每页最多显示几条数据 10
for (DiscussPost post : page) {//遍历page
System.out.println(post);
}
}
结果:
但是里面没有加em,也没有高亮显示,因此添加一句:
// elasticTemplate.queryForPage(searchQuery, class, SearchResultMapper) 把高亮的数据整合到原始数据中,做个替换才可以。class是哪个类型数据
// elastic底层 调用了此方法获取得到了高亮显示的值, 但是没有返回.
测试:
@Test
public void testSearchByTemplate() {//为了能够高亮显示,直接用Template 方法测试
SearchQuery searchQuery = new NativeSearchQueryBuilder()//searchQuery和之前一模一样 不用动
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(0, 10))
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
Page<DiscussPost> page = elasticTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {//设置Query,DiscussPost.class实体类型
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits();//得到封装的多条数据
if (hits.getTotalHits() <= 0) {//说明没查到数据
return null;
}
List<DiscussPost> list = new ArrayList<>();//声明一个集合,集合里面装的是DiscussPost
for (SearchHit hit : hits) {
DiscussPost post = new DiscussPost();//实例化 实体类
String id = hit.getSourceAsMap().get("id").toString();//hit.getSourceAsMap()得到map形式的数据,之后得到id 并转为字符串
post.setId(Integer.valueOf(id));
String userId = hit.getSourceAsMap().get("userId").toString();
post.setUserId(Integer.valueOf(userId));
String title = hit.getSourceAsMap().get("title").toString();//原始显示的title,而不是高亮显示的
post.setTitle(title);
String content = hit.getSourceAsMap().get("content").toString();//原始显示的content,而不是高亮显示的
post.setContent(content);
String status = hit.getSourceAsMap().get("status").toString();
post.setStatus(Integer.valueOf(status));
String createTime = hit.getSourceAsMap().get("createTime").toString();
post.setCreateTime(new Date(Long.valueOf(createTime)));
String commentCount = hit.getSourceAsMap().get("commentCount").toString();
post.setCommentCount(Integer.valueOf(commentCount));
// 处理高亮显示的结果
HighlightField titleField = hit.getHighlightFields().get("title");//获取与title 有关的 高亮显示的内容
if (titleField != null) {
post.setTitle(titleField.getFragments()[0].toString());//覆盖掉post原先没有高亮的title。从titleField中取到 高亮显示的值,getFragments返回的是数组。[0]表示只返回第一段。
}
HighlightField contentField = hit.getHighlightFields().get("content");//覆盖掉post原先没有高亮的content
if (contentField != null) {
post.setContent(contentField.getFragments()[0].toString());
}
list.add(post);//将其放入集合
}
return new AggregatedPageImpl(list, pageable,
hits.getTotalHits(), response.getAggregations(), response.getScrollId(), hits.getMaxScore());// hits.getTotalHits()表示一共多少条数据
}
});
System.out.println(page.getTotalElements());
System.out.println(page.getTotalPages());
System.out.println(page.getNumber());
System.out.println(page.getSize());
for (DiscussPost post : page) {
System.out.println(post);
}
}
运行结果:
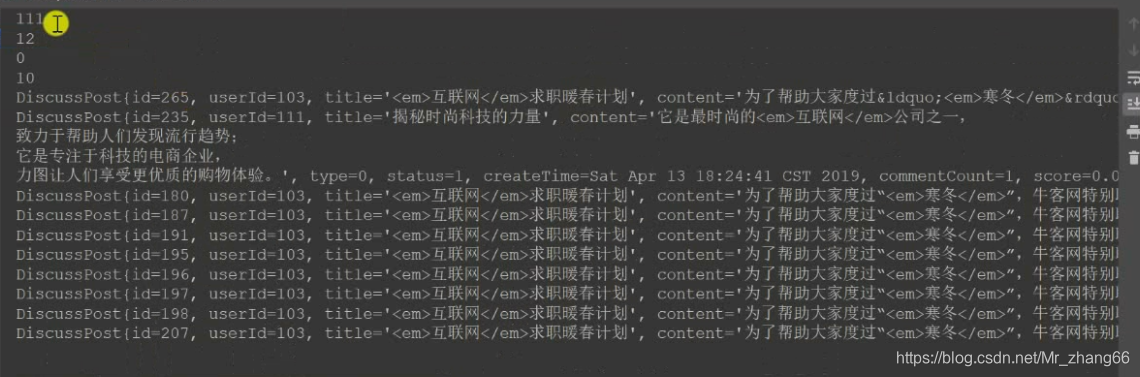
111条数据,12页,当前第0页,每页10条,后面跟着10条数据















 2940
2940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









