






一.正则表达式
通配符匹配文件(而且是已存在的文件)
- 基本正则表达式
- 扩展正则表达式
可以使用 man 手册帮助
正则表达式:匹配的是文章中的字符
通配符:匹配的是文件名 任意单个字符
1.元字符(字符匹配)
元字符:
. 匹配任意单个字符,可以是一个汉字
[ ] 匹配指定范围内的任意单个字符,示例:[zhou] [0-9] [ ] [a-zA-Z] [:alpha]
[^] 匹配指定范围外的任意单个字符,示例:[^zhou] [^a.z] [a.z]
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
\w #匹配单词构成部分,等价于[_[:alnum:]]
\W #匹配非单词构成部分,等价于[^_[:alnum:]]
\S #匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意
Unicode 正则表达式会匹配全角空格符元字符点(.)
[root@localhost ~]#ls /etc/|grep rc[.0-6]
#此处的点代表字符
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@localhost ~]#ls /etc/ | grep 'rc\.'
#点值表示点需要转义
rc.d
rc.local
[root@localhost ~]# grep r..t /etc/passwd
#r..t ..代表任意两个字符
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
[root@localhost ~]# echo abc |grep a.c
#表示原来的点需要加\转义
abc
[root@localhost ~]# echo abc |grep a\.c
#不加引号有时匹配会有出入
abc
[root@localhost ~]# echo abc |grep 'a\.c'
#标准格式需要加'' 或者""
[root@localhost ~]# ls |grep '[zhou].txt'
#匹配[]中任意一个字符
h.txt
o.txt
u.txt
z.txt
[root@localhost ~]# ls [a-d].txt
#通配符
a.txt A.txt b.txt B.txt c.txt C.txt d.txt
[root@localhost ~]# ls |grep '[a-d].txt'
#真正的小写在正则表达式中
a.txt
b.txt
c.txt
d.txt
[root@localhost ~]# ls |grep '[^a-z].txt'
#显示非小写字母
A.txt
B.txt
[root@localhost ~]# ls |grep '[^a.z].txt'
#[]里就是本意不需要转义
space空格
[root@localhost ky15]#grep [[:space:]] zhen.txt
hhh
jj l
kkk
[root@localhost ky15]#grep [[:space:]] zhen.txt |cat -A
hhh $
jj^I^Il$
kkk $
[root@localhost ~]#ls /etc/ |grep "rc[.0-6]"
[root@localhost ~]#ls /etc/ |grep "rc[.0-6]."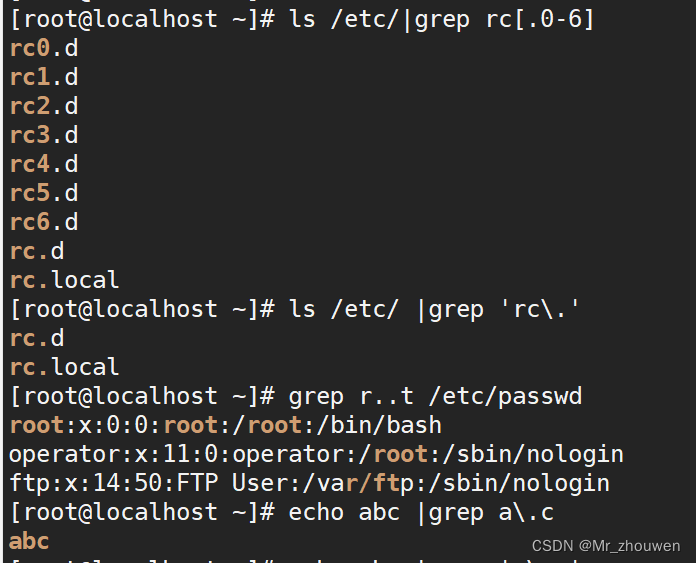
2.表示次数
* #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配(0-正无穷次)
.* #任意长度的任意字符,不包括0次
\? #匹配其前面的字符出现0次或1次,即:可有可无
\+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次(1到正无穷次)
\{n\} #匹配前面的字符出现n次
\{m,n\} #匹配前面的字符至少m次,至多n次
\{,n\} #匹配前面的字符至多n次,<=n
\{n,\} #匹配前面的字符至少n次
ifconfig ens33|grep netmask|grep -o
[0-9] [0 1 2 3 4 5 6 7 8 9]
ifconfig ens33|grep netmask|grep -o '[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+'|head -n1
ifconfig ens33|grep netmask|grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}'|head -n1例:
[root@localhost ~]# echo google |grep 'go\{2\}gle'
#带表前面的o出现2次
google
[root@localhost ~]# echo gooooogle |grep 'go\{2,\}gle'
#带表前面的o出现2次以上
gooooogle
[root@localhost ~]# echo gooooogle |grep 'go\{2,5\}gle'
#带表前面的o出现2次以上5次以下
gooooogle
[root@localhost ~]# echo goooooogle |grep 'go\{2,5\}gle'
[root@localhost ~]#
[root@localhost ~]# echo goooooogle |grep 'go*gle'
#表示0次到任意次
goooooogle
[root@localhost ~]# echo ggle |grep "go*gle"
ggle
[root@localhost ~]# echo gggle |grep "go*gle"
#grep 包含最前面的g不匹配
gggle
[root@localhost ~]# echo gdadadadgle |grep "g.*gle"
#.*代表任意匹配所有
gdadadadgle
[root@localhost ~]# echo ggle |grep "go\?gle"
# \?一次或者0次
ggle
[root@localhost ~]# echo gogle |grep "go\?gle"
gogle
[root@[root@localhost ~]# echo google |grep "go\+gle"
#一个以上
google
[root@localhost ~]# echo gogle |grep "go\+gle"
gogle
[root@localhost ~]# echo ggle |grep "go\+gle"
[root@localhost ~]# echo google |grep "go\?gle"
3.位置锚定
^ #行首锚定, 用于模式的最左侧
$ #行尾锚定,用于模式的最右侧
^PATTERN$ #用于模式匹配整行 (单独一行 只有root)
^$ #空行
^[[:space:]]*$ # 空白行
\< 或 \b #词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)
\> 或 \b #词尾锚定,用于单词模式的右侧
\<PATTERN\> #匹配整个单词例:
过滤出不是已#号开头的非空行
[root@localhost ~]#grep "^[^#]" /etc/fstab
[root@localhost data]#grep "^google$" test.txt
#只匹配google 这个字符
[root@localhost ~]#grep "^[[:space:]]*$" /etc/fstab
[root@localhost ~]#echo hello-123 |grep "\<123"
#除了 字母 数字 下划线其他都算 单词的分隔符
hello-123
[root@localhost ~]#echo hello 123 |grep "\<123"
hello 123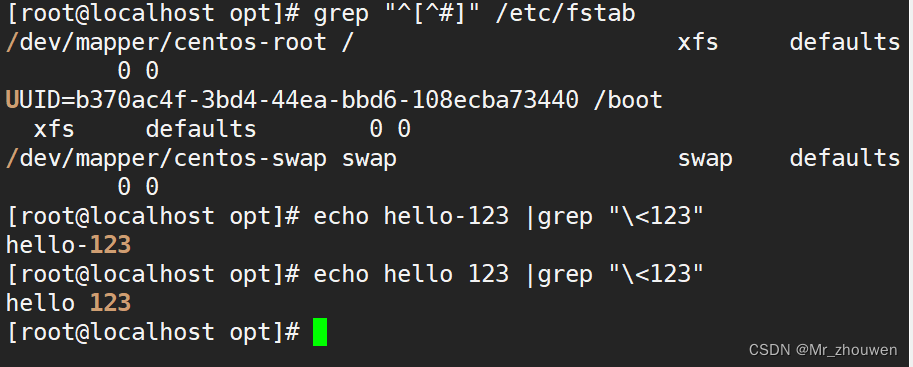
4.分组或其他
分组:( )将多个字符捆绑在一起,当作一个整体处理,如(root)+后向引用;分组括号中的模式匹配到的内容会背正则表达式引擎记录于内部的变量中,这些变量的命名方式为:\1,\2,\3,...
\1表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
或者 : \|
例:
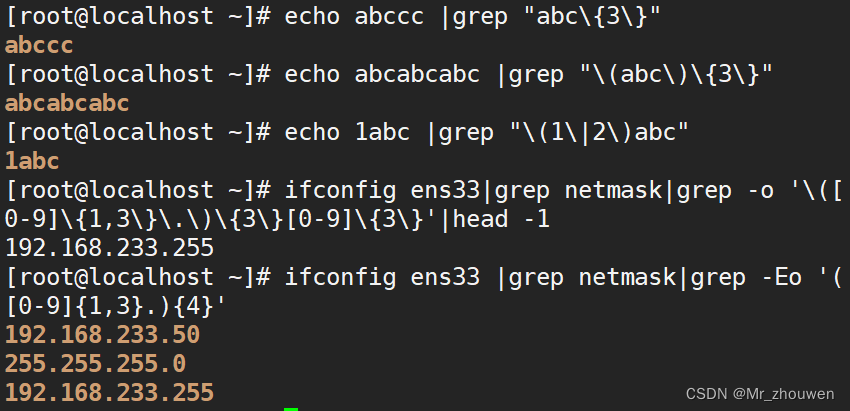
[root@localhost ~]#echo abccc |grep "abc\{3\}"
abccc
[root@localhost ~]#echo abcabcabc |grep "\(abc\)\{3\}"
#分组 匹配abc
abcabcabc
[root@localhost ~]#echo 1abc |grep "1\|2abc"
#只匹配了1
1abc
[root@localhost ~]#echo 1abc |grep "\(1\|2\)abc"
#1abc或者2abc
1abc
[root@localhost ~]#ifconfig ens33|grep netmask|grep -o '\([0-9]\{1,3\}\.\)\{3\}[0-9]\{3\}'|head -1
192.168.91.100
[root@localhost ~] ens33 |grep netmask|grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}'|head -1
[root@localhost ky15]#ifconfig ens33 |grep netmask|grep -Eo '([0-9]{1,3}.){4}'
5.扩展正则表达式(表示字符相差不大)
grep -E
egrep
表示次数
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
{,n} #匹配前面的字符至多n次,<=n,n可以为0
{n,} #匹配前面的字符至少n次,<=n,n可以为0表示分组
( ) 分组
分组:( ) 将多个字符捆绑在一起,当作一个整体处理,如:\(root\)+
后向引用:\1, \2, ...
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat练习
1.表示qq号
[root@localhost ~]#echo "aa940132245" |grep "\b[0-9]\{6,12\}\b"2.表示邮箱
echo "zhou@qq.com" |grep -E "[[:alnum:]_]+@[[:alnum:]_]+\.[[:alnum:]_]+"3.表示手机号
echo "13705173391"|grep -E "\b1[3456789][0-9]{9}\b"二.grep
grep [选项]...查找条件 目标文件
选项:
-color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
grep -m 1 root /etc/passwd #多个匹配只取第一个
-v 显示不被pattern匹配到的行,即取反
grep -Ev '^[[:space:]]*#|^$' /etc/fstab
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
grep -c root /etc/passwd #统计匹配到的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
grep -A3 root /etc/passwd #匹配到的行后3行业显示出来
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
grep -E root|bash /etc/passwd
-w 匹配整个单词
grep -w root /etc/passwd
useradd rooter
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接grep root /etc/passwd
grep "USER" /etc/passwd
grep 'USER' /etc/passwd
grep whoami /etc/passwd[root@test1 opt]# cat 123.txt |grep -v '^$' >test.txt //将非空行写入到test.txt文件
[root@test1 opt]# grep "^b" 123.txt //过滤已b开头
[root@test1 opt]#grep '/$' 123.txt //过滤已/结尾
[root@test1 opt]# grep -v "^$" 123.txt //过滤非空行3 备份与
[root@localhost yum.repos.d]# ifconfig ens33 |grep -o "[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+"
192.168.91.100
255.255.255.0
192.168.91.255
[root@localhost yum.repos.d]# ifconfig ens33 |grep -o "[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+"|head -1
192.168.91.100
###面试题 统计当前主机的连接状态
[root@localhost ~]# ss -nta | grep -v '^State' |cut -d" " -f1|sort |uniq -c
3 ESTAB
17 LISTEN
#####统计当前连接主机数
[root@localhost ~]#ss -nt |tr -s " "|cut -d " " -f5|cut -d ":" -f1 |sort|uniq -c
3 192.168.91.1
1 192.168.91.101
1 Address三.AWK
awk(语言):读取一行处理一行
在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,默认以空格或tab键作为分隔符作为分隔,并按模式或者条件执行编辑命令。而awk比较倾向于将一行分成多个字段然后进行处理。AWK信息的读入也是逐行
指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互
的情况下实现相当复杂的文本操作,被广泛应用于 Shell 脚本,完成各种自动化配置任务。
awk工作过程
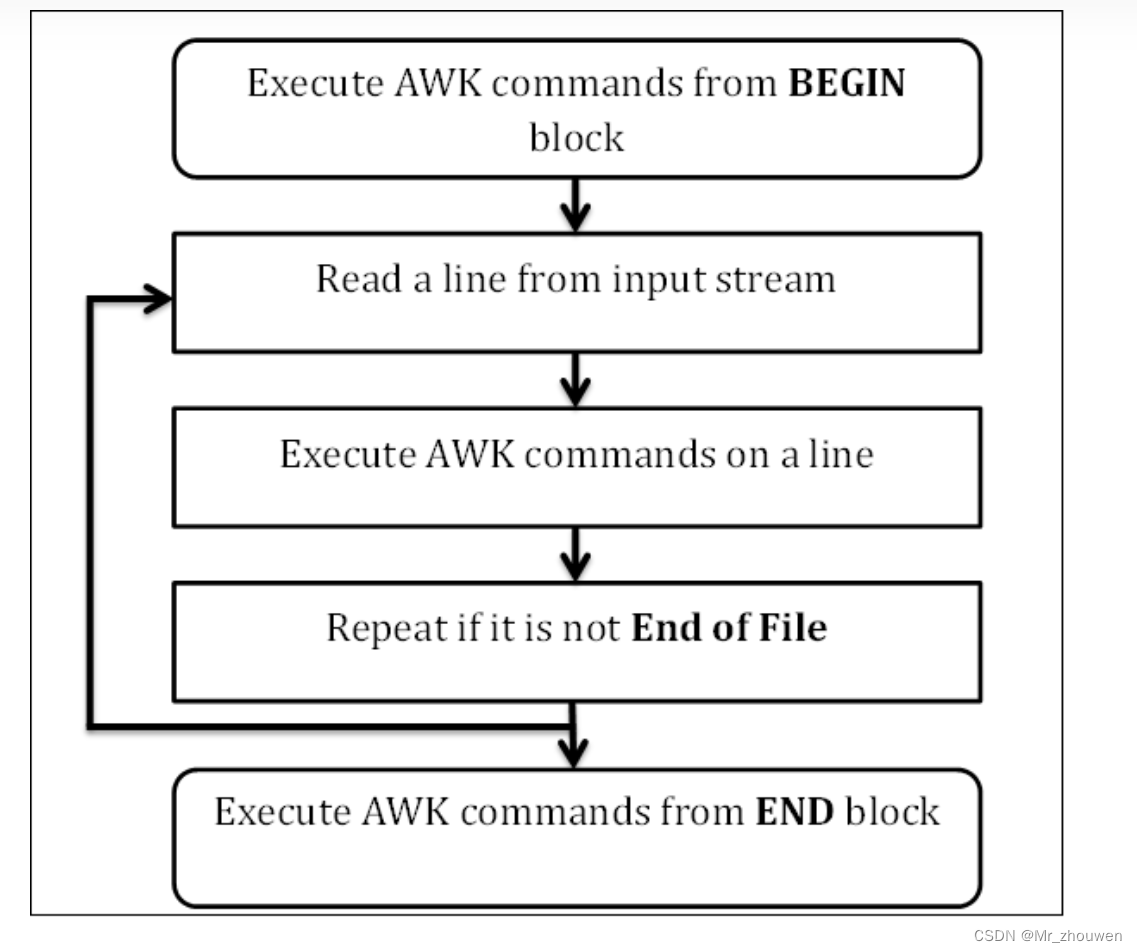
第一步:执行BEGIN{action;… }语句块中的语句
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,
从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{action;…}语句块
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
工作原理:
awk 倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
-F 指定分隔符
-v 自定义变量
-f 脚本
格式:
awk [options] 'program' var=value file…
awk 选项 模式 处理的动作
指定 '{print }'
awk [options] -f programfile var=value file…
#说明:
program通常是被放在单引号中,并可以由三种部分组成
BEGIN语句块
模式匹配的通用语句块
END语句块
pattern{action statements;..}
pattern:决定动作语句何时触发及触发事件,比如:BEGIN,END,正则表达式等
action statements:对数据进行处理,放在{}内指明,常见:print, printf
#常见选项:
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-v(小v) var=value 变量赋值
awk [选项] '模式条件{操作}' 文件1 文件2....
awk -f|-v 脚本文件 文件1 文件2.....例:
awk '{print $1}'
awk -F: '{print $1}'
NR==2
awk 'NR==2{print $1}'
awk '/^root/,/bash$/{print $1}'
NF
awk -F'[ %]'
([:space:]|%)
1.print
awk '{print $n}' 以空格为分隔符取第n列 n大于等于0
[root@localhost ~]#awk 'patterm{action}'
[root@localhost ~]#awk ''
#什么都不写 空没有效果
[root@localhost ~]#awk '{print}'
##在打印一遍
dd
dd
[root@localhost ~]#awk '{print "hello"}'
#字符串需要添加双引号,单引号已被使用
1
hello
1
hello
[root@localhost ~]#awk '{print "hello"}' < /etc/passwd
[root@localhost ~]#ls | awk '{print "hello"}'
[root@localhost ~]#awk 'BEGIN{print 100+200}'
#运算
300
##############BEGIN ###################
[root@localhost ky15]#awk 'BEGIN {print "hello"}'
#BEGIN比较特殊值打一行 pattern
hello
[root@localhost ~]#awk -F: 'BEGIN {print "hello"} {print $1}' /etc/passwd |head -n3
#先处理BEGIN 中的式子
hello
root
bin
[root@localhost ~]#awk '{print 100}'
#数字不需要
1
100
[root@localhost ~]#awk -F: '{print "root"}' /etc/passwd
#打印root 多少行=passwd里的行数
[root@localhost ky15]#echo {a..b} |awk '{print $1}'
#连续的空白符也可以
a
[root@localhost ky15]#df|awk '{print $5}'
#分区利用率
已用%
8%
0%
0%
1%
0%
4%
0%
1%
[root@localhost ky15]#cat /etc/passwd|awk -F: '{print $1,$3}'
#指定冒号作为分隔符,打印第一列和第三列
[root@localhost ky15]#cat /etc/passwd|awk -F: '{print $1":"$3}'
#用冒号分隔开
[root@localhost ky15]#cat /etc/passwd|awk -F: '{print $1"\t"$3}'
[root@localhost ~]#df|awk -F"( +|%)" '{print $5}'
[root@localhost ky15]#df |awk -F"[[:space:]]+|%" '{print $5}'
[root@localhost ky15]#df |awk -F"[ %]+" '{print $5}'
取 ip地址
[root@localhost ky15]#ifconfig ens33|sed -n '2p' |awk '{print $2}'
[root@localhost ky15]#hostname -I|awk {print $1}
192.168.91.100 192.168.122.1 [root@localhost ~]#wc -l /etc/passwd
45 /etc/passwd
[root@localhost ~]#awk -F: '{print $0}' /etc/passwd
#$0代表全部元素
[root@localhost ~]#awk -F: '{print $1}' /etc/passwd
#代表第一列
[root@localhost ~]#awk -F: '{print $1,$3}' /etc/passwd
#代表第一第三列
[root@localhost ky15]#awk '/^root/{print}' passwd
#已root为开头的行
[root@localhost ky15]#grep -c "/bin/bash$" passwd
#统计当前已/bin/bash结尾的行
2
##### BEGIN{}模式表示,在处理指定的文本前,需要先执行BEGIN模式中的指定动作; awk再处理指定的文本,之后再执行END模式中的指定动作,END{}语句中,一般会放入打印结果等语句。
[root@localhost ky15]#awk 'BEGIN {x=0};/\/bin\/bash$/;{x++};END{print x}' passwd
## 先定义变量
[root@localhost ky15]#awk 'BEGIN {x=0};/\/bin\/bash$/ {x++;print x,$0};END{print x}' passwd2.awk内置变量
awk 选项 '模式{print }'
-
FS :指定每行文本的字段分隔符,缺省为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:"
-
OFS:输出时的分隔符
-
NF:当前处理的行的字段个数
-
NR:当前处理的行的行号(序数)
-
$0:当前处理的行的整行内容
-
$n:当前处理行的第n个字段(第n列)
-
FILENAME:被处理的文件名
-
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n
NF字段的个数
倒数第一列 $NF
倒数第二列 $(NF-1)
NR只显示行号 NR=2只显示第二行 奇数行 偶数行
awk 'NR==2{print $1}'
[root@localhost ky15]#awk -v FS=':' '{print $1FS$3}' /etc/passwd
#此处FS 相当于于变量 -v 变量赋值 相当于 指定: 为分隔符
[root@localhost ky15]#awk -F: '{print $1":"$3}' /etc/passwd
shell中的变量
[root@localhost ky15]#fs=":";awk -v FS=$fs '{print $1FS$3}' /etc/passwd
#定义变量传给FS
######### 支持变量 ##################
[root@localhost ky15]#fs=":";awk -v FS=$fs -v OFS="+" '{print $1,$3}' /etc/passwd
#输出分隔符
-F -FS一起使用 -F 的优先级高
############ OFS ##########
[root@localhost ~]#awk -v FS=':' -v OFS='==' '{print $1,$3}' /etc/passwd
root==0
bin==1
daemon==2
adm==3
lp==4
sync==5
######## RS #######
默认是已 /n (换行符)为一条记录的分隔符
不动他
[root@localhost ~]#echo $PATH | awk -v RS=':' '{print $0}'
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/root/bin
################## NF ###################
代表字段的个数
[root@localhost ky15]#awk -F: '{print NF}' /etc/passwd
[root@localhost ky15]#awk -F: '{print $NF}' /etc/passwd
#$NF最后一个字段
[root@localhost ky15]#df|awk -F: '{print $(NF-1)}'
#倒数第二行
[root@localhost ky15]#df|awk -F "[ %]+" '{print $(NF-1)}'
################ NR ######################
行号
[root@localhost ky15]#awk '{print $1,NR}' /etc/passwd
##行号
[root@localhost ky15]#awk 'NR==2{print $1}' /etc/passwd
#只取第二行的第一个字段
[root@localhost ky15]#awk 'NR==1,NR==3{print}' passwd
#打印出1到3 行
[root@localhost ky15]#awk 'NR==1||NR==3{print}' passwd
#打印出1和3行
[root@localhost ky15]#awk '(NR%2)==0{print NR}' passwd
#打印出函数取余数为0行
[root@localhost ky15]#awk '(NR%2)==1{print NR}' passwd
#打印出函数取余数为1的行
[root@localhost ky15]#awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd
[root@localhost ky15]#seq 10|awk 'NR>5 && NR<10'
#取 行间
6
7
8
9
[root@localhost ky15]#awk '$3>1000{print}' /etc/passwd
#注意分隔符
#打印出普通用户 第三列 大于1000 的行
################ FNR ############
[root@localhost data]#cat /etc/issue |wc -l
3
[root@localhost data]#cat /etc/os-release |wc -l
16
[root@localhost data]#awk '{print FNR}' /etc/issue /etc/os-release
1
2
3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
################ FILENAME ############
[root@localhost ~]#awk -F: 'NR==2{print FILENAME}' /etc/passwd
/etc/passwd
面试题
从几点几分到几点几分的日志文件
awk '/几点几分/,/几点几分/'日志文件.
3.自定义变量
[root@localhost ~]#awk -v test='hello' 'BEGIN{print test}'
hello
awk -v test1=test2="hello" 'BEGIN{test1=test2="hello";print test1,test2}'
awk -v test='hello gawk' '{print test}' /etc/fstab
awk -v test='hello gawk' 'BEGIN{print test}'
awk 'BEGIN{test="hello,gawk";print test}'
awk -F: '{sex="male";print $1,sex,age;age=18}' /etc/passwd
printf
awk -F: 'BEGIN{printf "--------------------------------\n%-20s|%10s|\n--------------------------------\n","username","uid"}{printf "%-20s|%10d|\n--------------------------------\n",$1,$3}' /etc/passwd














 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









