







事务
事务是一组操作的集合,事务会把所有操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
基本操作:
-- 1. 查询张三账户余额
select * from account where name = '张三';
-- 2. 将张三账户余额-1000
update account set money = money - 1000 where name = '张三';
-- 此语句出错后张三钱减少但是李四钱没有增加
模拟sql语句错误
-- 3. 将李四账户余额+1000
update account set money = money + 1000 where name = '李四';
-- 查看事务提交方式
SELECT @@AUTOCOMMIT;
-- 设置事务提交方式,1为自动提交,0为手动提交,该设置只对当前会话有效
SET @@AUTOCOMMIT = 0;
-- 提交事务
COMMIT;
-- 回滚事务
ROLLBACK;
-- 设置手动提交后上面代码改为:
select * from account where name = '张三';
update account set money = money - 1000 where name = '张三';
update account set money = money + 1000 where name = '李四';
commit;
操作方式二:
开启事务:
START TRANSACTION 或 BEGIN TRANSACTION;
提交事务:
COMMIT;
回滚事务:
ROLLBACK;
操作实例:
start transaction;
select * from account where name = '张三';
update account set money = money - 1000 where name = '张三';
update account set money = money + 1000 where name = '李四';
commit;
一、四大特性ACID
- 原子性(Atomicity):事务是不可分割的最小操作但愿,要么全部成功,要么全部失败
- 一致性(Consistency):事务完成时,必须使所有数据都保持一致状态
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
二、并发事务
| 问题 | 描述 |
|---|---|
| 脏读 (读未提交) | 一个事务读A到另一个事务B还没提交的数据 |
| 读已提交 | 事务A只能读取B提交之后的数据 |
| 可重复读 | 事务A开启后,不管是多久,A读取的是一致的,即使B已修改并提交(幻读) |
| 序列号/串行化 | 事务排队,不能并发 |
并发事务隔离级别:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read(默认) | × | × | √ |
| Serializable | × | × | × |
- √表示在当前隔离级别下该问题会出现
- Serializable 性能最低;Read uncommitted 性能最高,数据安全性最差
查看事务隔离级别:
SELECT @@TRANSACTION_ISOLATION;
设置事务隔离级别:
SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE };
SESSION 是会话级别,表示只针对当前会话有效,GLOBAL 表示对所有会话有效
存储引擎
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表而不是基于库的,所以存储引擎也可以被称为表引擎。
默认存储引擎是InnoDB。
相关操作:
-- 查询建表语句
show create table account;
-- 建表时指定存储引擎
CREATE TABLE 表名(
...
) ENGINE=INNODB;
查看当前数据库支持的存储引擎show engines;
一、InnoDB
Mysql的体系结构:
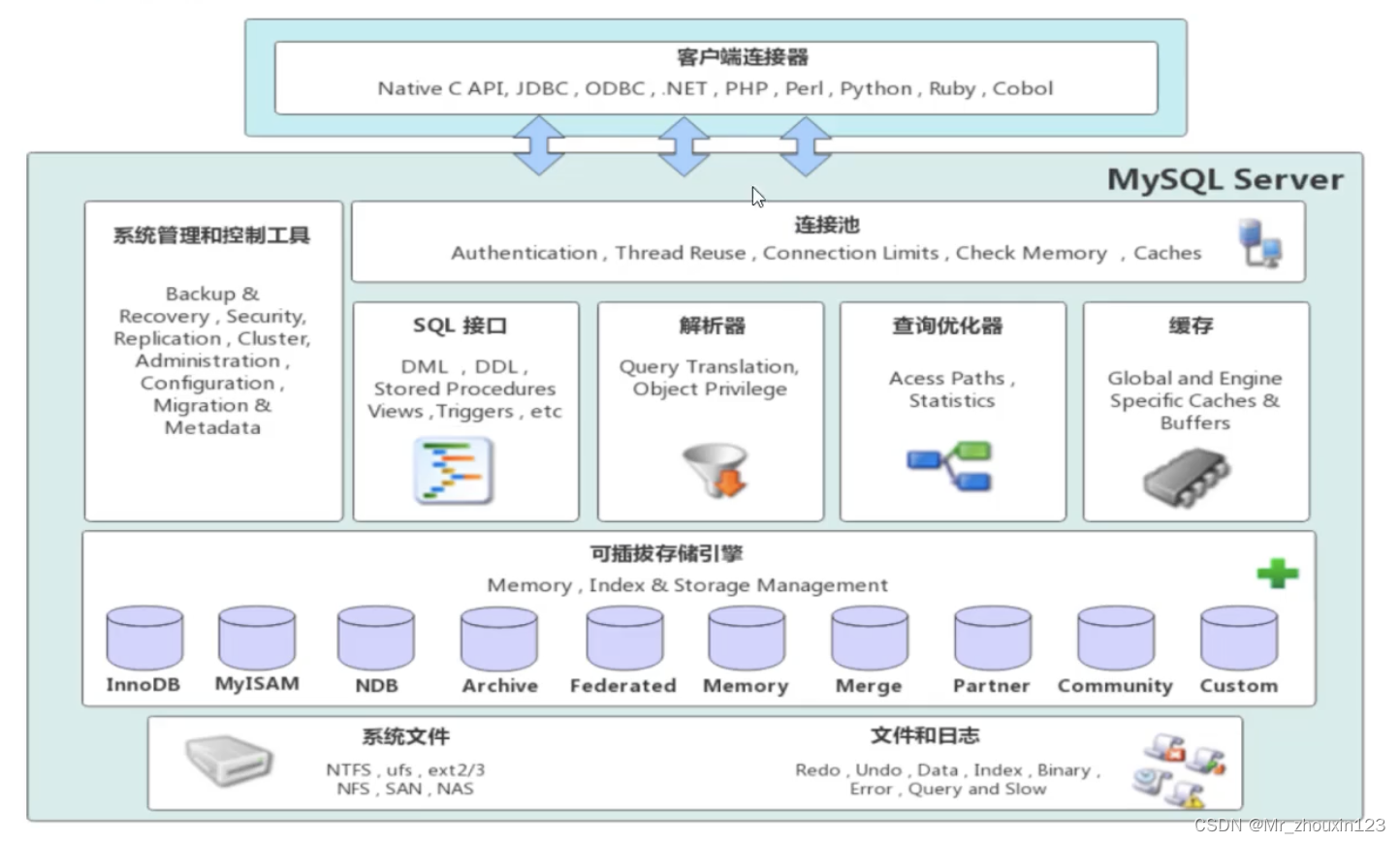
最上层表示每个语言连接数据库,连接池:完成连接授权等操作,比如输入账户密码啥的。接下来就是服务层,DML/DDL/语句的实现。再往下就是存储引擎(存储提取方式)。最下就是数据文件,日志等。
InnoDB 是一种兼顾高可靠性和高性能的通用存储引擎,在 MySQL 5.5 之后,InnoDB 是默认的 MySQL 引擎。
特点:
- DML 操作遵循 ACID 模型,支持事务
- 行级锁,提高并发访问性能
- 支持外键约束,保证数据的完整性和正确性
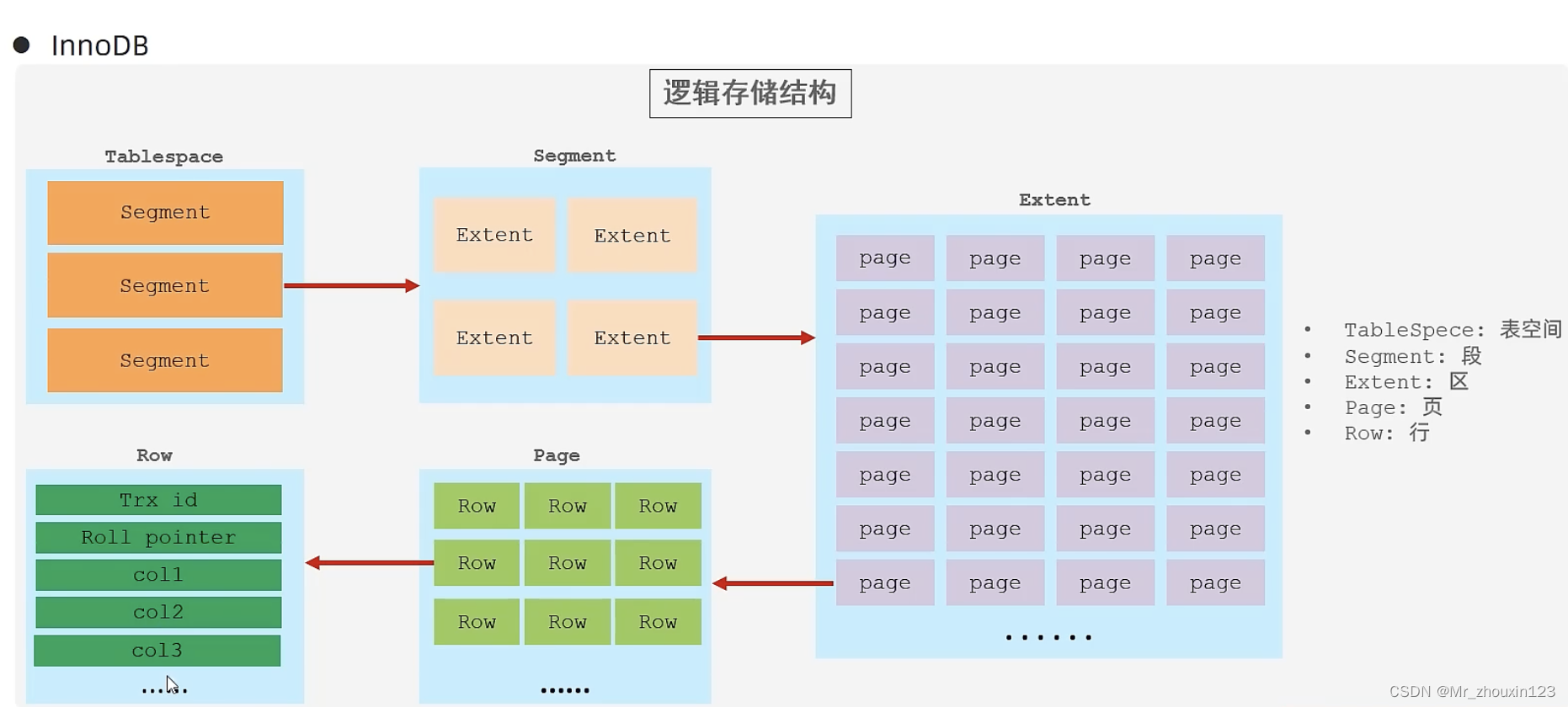
xxx.ibd: xxx代表表名,InnoDB 引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引。
参数:innodb_file_per_table,决定多张表共享一个表空间还是每张表对应一个表空间
知识点:
查看 Mysql 变量:
show variables like 'innodb_file_per_table';
从idb文件提取表结构数据:
(在cmd运行)
ibd2sdi xxx.ibd
二、MyISAM
MyISAM 是 MySQL 早期的默认存储引擎。
特点:
- 不支持事务,不支持外键
- 支持表锁,不支持行锁
- 访问速度快
文件:
- xxx.sdi: 存储表结构信息
- xxx.MYD: 存储数据
- xxx.MYI: 存储索引
三、Memory
Memory 引擎的表数据是存储在内存中的,受硬件问题、断电问题的影响,只能将这些表作为临时表或缓存使用。
特点:
- 存放在内存中,速度快
- hash索引(默认)
文件:
- xxx.sdi: 存储表结构信息(只有这个,数据存在内存中)
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
四、存储引擎的选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
- InnoDB: 如果应用对事物的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,则 InnoDB 是比较合适的选择
- MyISAM: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不高,那这个存储引擎是非常合适的。
- Memory: 将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。Memory 的缺陷是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性
电商中的足迹和评论适合使用 MyISAM 引擎,缓存适合使用 Memory 引擎。
索引
索引是帮助 MySQL 高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查询算法,这种数据结构就是索引。
例如:在age列维护一个二叉树。
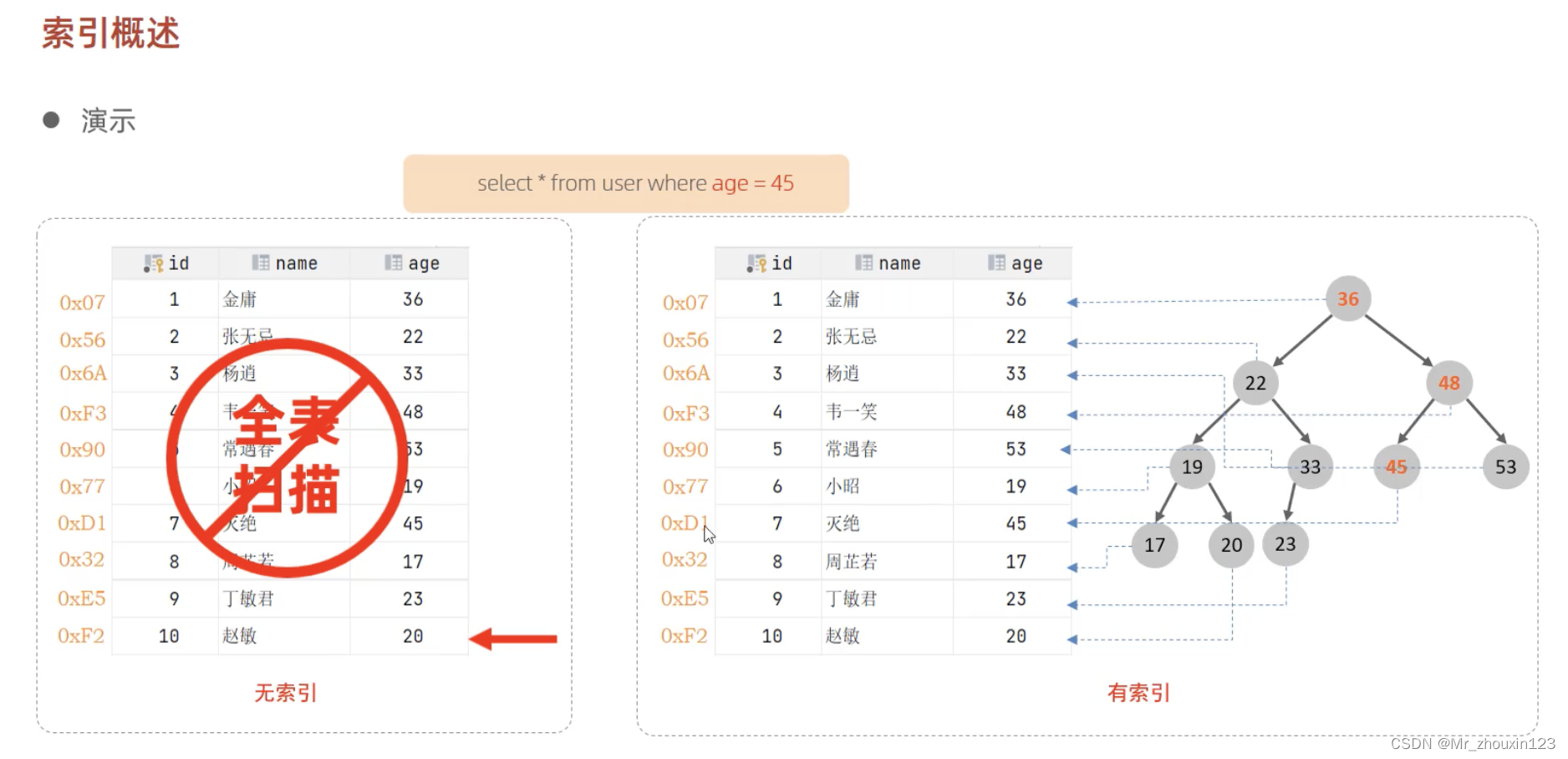
优点:
- 提高数据检索效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点:
- 索引列也是要占用空间的
- 索引大大提高了查询效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
索引结构
| 索引结构 | 描述 |
|---|---|
| B+Tree | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash | 底层数据结构是用哈希表实现,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-Tree(空间索引) | 空间索引是 MyISAM 引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-Text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式,类似于 Lucene, Solr, ES |
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本后支持 | 支持 | 不支持 |















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









