







文章目录
Reuqests笔记
一、发送请求
requests提供了几乎所有的HTTP请求功能:GET、OPTIONS、HEAD、POST、PUT、PATCH、DELETE。
r=requests.get('http://example.com/'):发送GET请求r=requests.post('http://example.com/'):发送POST请求r=requests.put('http://example.com/'):发送PUT请求r=requests.delete('http://example.com/'):发送DELETE请求r=requests.head('http://example.com/'):发送HEAD请求r=requests.options('http://example.com/'):发送OPTIONS请求r=requests.patch('http://example.com/'):发送PATCH请求
这些函数的返回值都是一个Response对象,这个对象中存放着我们所想要的信息。

r=requests.options(url)会返回服务器支持那些HTTP请求类型。这些请求类型在r.headers['allow']中查看。
二、为URL传递参数
requests允许你使用params关键字传递参数,该参数是一个字典,从而构建带查询字符串的URL。如:
r=requests.get('http://example.com/',params={'key1':value1,'key2':value2})。
通过打印输出Response对象的url属性,你可以看到URL正确解码。
params字典里如果有值为None,则对应的键不会添加到URL的查询字符串里。

三、响应内容
1. 文本响应内容
requests会自动解码来自服务器的内容。大多数unicode字符集都能够被无缝地解码。请求发出之后,requests会基于HTTP头部对响应的编码做出有根据的推测。当你方位r.text时,requests会使用推测的文本编码。
requests会首先在响应头部检测是否存在指定的编码方式;如果不存在则会去猜测编码方式。
你可以使用r.encoding来查看requests的编码;也可以通过赋值r.encoding='UTF-8'来显式的指定编码。如果你改变了编码,则每当你访问r.text时,requests会使用r.encoding的最新值。

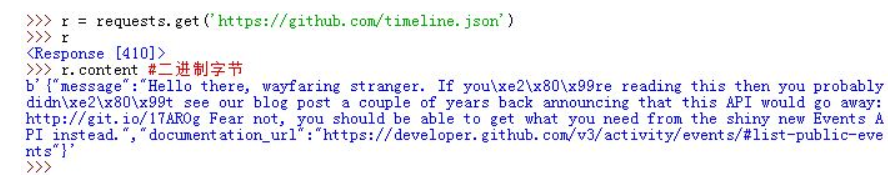
2. 二进制响应内容
你也可以通过r.content用字节的方式访问响应内容。requests会自动为你解码gzip和deflate传输编码的响应数据。
3. JSON响应内容
requests内置了一个JSON解码器,r.json()通过它将数据解析成JSON格式。如果解析失败则抛出ValueError异常。

4. 原始响应内容
有时候你可能像获取来自于服务器的原始套接字响应,那么r.raw可以访问到该套接字响应。但是前提是你在初始请求中设置了stream=True。
为了处理原始数据,你需要使用Response.iter_content()方法。当使用流下载时,优先使用该方法。

三、请求与响应对象
任何时候通过requests发送请求,它都在做两件事情:
- 构建一个
Request对象,该对象将被发送到某个服务器请求或者查询一些资源。 - 一旦
requests得到一个从服务器返回的响应就会产生一个Response对象。该对象包含服务器返回的所有信息,也包含你原来创建的Request对象。如:r.headers包含了服务器返回的响应头部信息,r.request.headers包含了发送请求的请求头部信息。
r.request包含了发送的请求。

四、响应体内容工作流
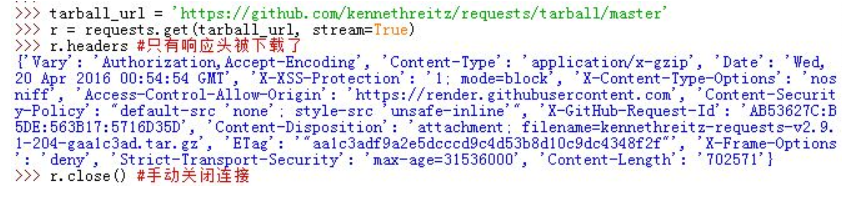
默认情况下,当你进行网络请求后,响应体会立即被下载。你可以通过stream=True参数覆盖这个行为,推迟下载响应体直到访问Response.content属性。此时仅有响应头被下载下来,连接保持打开状态。
- 可以根据响应头里的信息判断,从而决定是否应该访问
Response.content属性从而下载响应体。 - 也可以进一步使用
Response.iter_content和Response.iter_lines方法来控制工作流,或者以Response.raw从底层读取。
注意:当你对一个请求设置了stream=True参数之后,Request会保持连接一直到你读取了所有的响应内容(包括响应体)或者你手动调用Response.close之后才会关闭连接并释放连接。如果你只是读取了部分响应内容,则你需要手动调用Response.close来关闭连接。
1. 流式迭代
通常在设置stream=True之后,使用requests.Response.iter_lines()来进行流式迭代。如:
import json
import requests
r = requests.get('http://httpbin.org/stream/20', stream=True)
for line in r.iter_lines():
# filter out keep-alive new lines
if line:
print(json.loads(line))
五、定制请求头
如果你想为请求添加HTTP头不,则通过headers关键字参数传入一个字典即可,如r=requests.get('http://example.com/',headers={'key1':value1,'key2':value2})。
六、定制请求头以及请求体
有的时候你希望在发送请求之前修改它的头部或者请求体内容。你可以通过下面的方法:
from requests import Request, Session
s = Session()
req = Request('GET', url,
data=data,
headers=header
)
prepped = req.prepare()
# do something with prepped.body
# do something with prepped.headers
resp = s.send(prepped,
stream=stream,
verify=verify,
proxies=proxies,
cert=cert,
timeout=timeout
)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Aau2auaI-1620231527915)(./imgs/requests/custom_request.JPG)]
在创建Request对象之后,通过Session实例发送或者通过requests.*发送PreparedRequest实例。其中PreparedRequest实例是由Request实例的.prepare()方法返回。
但是上述方法对于Session有个缺陷:它无法使用Session的机制。Session会默认在每个请求直接共享Cookie,但是按照上面手动创建PreparedRequest的方法,共享的Cookie并不会被添加进本次请求对象中来。可以通过Session实例的prepare_request()方法来改进:
from requests import Request, Session
s = Session()
req = Request('GET', url,
data=data,
headers=header
)
prepped = s.prepare_request(req) #利用了Session的共享机制
...
七、更加复杂的POST请求
1. POST表单数据
如果你需要实现POST表单数据的效果,你可以通过data关键字参数传入一个字典即可。你的数据字典在发出请求的时候会自动编码为表单形式。如r=requests.post('http://example.com/',data={'key1':value1,'key2':value2})。

如果你要POST的数据并非编码为表单形式的,如string而不是dict,那么数据会被直接发布出去。

2. POST 一个多部分编码的文件
a. 流式上传
通过POST请求中指定files关键字参数,你可以上传一个文件。如:
r=requests.post('http://example.com/',files={'file':open('expl.xls','rb'},仅仅需要为你的请求体提供一个类文件对象即可。这称之为流式上传,它允许你发送大的数据流或者文件而无需先把他们读入内存中。这里要求以二进制打开文件。
你也可以显式的指定文件名和请求头。如:
r=requests.post('http://example.com/',files={'file':('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})})
你也可以将字符串作为当作文件来上传一个文件。此时在服务器端会生成一个文件,该文件的内容就是你发送的字符串。如:
r=requests.post('http://example.com/',files={'file':('report.txt', 'data to send\n data to send\n')})

b. 块编码请求
对于出去和进来的请求,requests也支持分块传输编码。要发送一个块编码请求,只需要为你的请求体提供一个生成器(或者一个没有具体长度的迭代器,有具体长度的则不行)。如
def gen():
yield 'hi'
yield 'there'
requests.post('http://some.url/chunked', data=gen())
c. POST一个多部分编码文件
为了在一个POST中上传多个文件,你可以将文件放入一个tuple列表中,tuple为(form_filed_name,file_info)。
如:
url = 'http://httpbin.org/post'
multiple_files = [('images', ('foo.png', open('foo.png', 'rb'), 'image/png')),
('images', ('bar.png', open('bar.png', 'rb'), 'image/png'))]
r = requests.post(url, files=multiple_files)
八、响应状态码
-
通过
r.status_code来返回响应的状态码 -
requests附带了一个内置的状态码查询对象:r.status_code==requests.codes.ok。 -
如果发送了一个失败请求(非200请求),我们可以通过
r.raise_for_status()来抛出异常。但是如果发送的请求成功(200请求),则r.raise_for_status()不做任何事情。

九、响应头
通过 r.headers查看一个Python字典形式展示的服务器响应头。但是这个字典比较特殊:它是仅仅为了HTTP头部而生成的,由于HTTP头部是大小写不敏感的,因此我们可以以任意大写形式来访问这些响应头字段。

十、Cookie
在响应中如果包含一些Cookie,你可以通过r.cookies['key']来访问它。如果你想发送Cookie数据到服务器,可以使用cookies关键字参数传入作为Cookie的字典。

十一、Session
Session对象能够让你跨请求保持某些参数。同一个Session实例发出的所有请求直接也会保持Cookie。Session对象具有主要的requests API的所有方法。
-
Session可用于跨请求保持一些Cookie。 -
Session可用于为请求方法提供缺省数据,这是通过为Session对象的属性提供数据来实现 -
任何传递给请求方法的字典都会与已经设置的
Session数据合并。方法层的参数会覆盖Session的参数。因此如果想删除Session中的某些数据,可以在方法层中,通过关键字参数将它设为None即可这里的
Session与服务器编程中的session不同。服务器编程的session值得是在服务器端保持的会话。而这里的Session是在用户端保持的。

十二、重定向
默认情况下,除了HEAD请求之外,requests会自动处理所有的请求的重定向。
-
可以使用
r.history来追踪重定向。r.history是一个requests.Response对象的列表,表示为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行了排序。 -
如果你使用的是
GET、OPTIONS、POST、PUT、PATCH、或者DELETE请求,则可以通过allow_redirects=False参数禁用重定向处理。 -
如果你使用的是
HEAD,你也可以通过allow_redirects=True来启用重定向处理。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6ZhsnDZn-1620231527923)(./imgs/requests/redirect.JPG)]
十三、超时
你可以指定requests在经历过某个时长之后,如果服务器未能响应则抛出异常。方法为:在请求中添加timeout关键字参数,其值为浮点数表示的秒数。如r=requests.get('http://example.com', timeout=0.001)。
如果timeout=None,则表示永不超时(你会一直等待对方服务器响应)。
另外这个超时时间可以提供一个二元的元组如(3,27)。第一个数表示connect超时时间(即TCP连接建立的超时时间),第二个数是数据处理时间(即服务器响应数据的第一个字节到达本地的时间)。前述的超市时间是这两个时间的总和。而这里是分别设定超时时间。
超时针对的是连接过程,而不是响应体的下载。
timeout并不是整个下载响应的时间限制,而是说如果服务器在timeout秒内没有应答,则引发超时。
十四、SSL证书验证
requests可以为HTTPS请求验证SSL证书,就像web浏览器一样。通过在请求中使用verify关键字参数,其值为True,从而开启SSL证书验证。如requests.get('https://github.com', verify=True)
- 如果你将
verify设置为False,则requests忽略对SSL证书的验证。默认情况下verify为True。 - 你可以指定一个本地证书作为客户端证书。可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组。如
requests.get('https://kennethreitz.com', cert=('/path/server.crt', '/path/key'))。
如果指定了一个错误路径或者一个无效证书,则抛出SSLError异常。
十五、持久连接
归功于urllib3,同一个会话内的持久连接完全是自动处理的。同一会话内你发出的任何请求都会自动复用恰当的连接。
但是可能连接池已空。比如你将stream=True之后,并没有手动关闭该链接或者读取响应的内容,此时该连接并不释放回连接池。如果这种连接非常多,则会 快速消耗连接池。
十六、代理
你可以为请求方法提供proxies关键字参数来配置单个请求的代理。也可以通过环境变量设置HTTP_PROXY和HTTPS_PROXY来配置代理。
如:
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
十七、错误与异常
- 遇到网络问题(如DNS查询失败、拒绝连接等):
requests抛出一个ConnectionError异常 - 遇到无效的HTTP响应:
requests抛出一个HTTPError异常 - 请求超时:
requests抛出一个Timeout异常 - 请求超过了设定的最大重定向次数:
requests抛出一个TooManyRedirects异常
所有requests显式抛出的异常都继承自requests.exceptions.RequestException
十八、身份认证
1. 基本身份认证
许多身份认证的web服务都接受HTTP Basic Auth。这是一种最简单的身份认证。在requests中使用基本身份认证的方式为:
requests.get('http://example.com',auth=requests.auth.HTTPBasicAuth('user','password')- 简写方式为:
requests.get('http://example.com',auth=('user','password')
2.摘要式身份认证
另一种流行的HTTP身份认证形式是摘要式身份认证,requests中使用摘要式身份认证的方式为:
requests.get('http://example.com',auth=requests.auth.HTTPDigestAuth('user','password')

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











