










- 回顾: 函数的类型包括哪些?
1.无参数,无返回值,一般用于提示信息打印。
2.无参数,有返回值,多用于数据采集中,比如获取系统信息。
3.有参数,无返回值,多用在设置某些不需要返回值的参数设置。
4.有参数,有返回值,一般是计算型的,需要参数,最终也要返回结果。
1、关于变量
1.1、局部变量
- 局部变量: 就是定义在函数内部的变量【作用域仅限于在该函数中使用,跳出该函数体,不再生效】
不同的函数可以定义相同的局部变量,互不影响。 - 局部变量的作用:为了临时的保存数据,需要在函数中定义来进行存储
#局部变量
def info():
name='peter'
age=20
print(name,age)
pass
print(info())
def info2():
name='tom'
age=19
sex='男'
print(name,age,sex)
pass
print(info2())
1.2、全局变量
- 全局变量: 函数外部定义的变量,一旦定义,所有函数均可调用
#全局变量
job='数据分析师'
pos='成都'
def info3():
name='jack'
age=10
pos = '上海'
job='java架构师'
print(name,age,pos,job) # 全局变量定义了jpo和job ,但是当函数体中再次定义局部变量,此时局部变量将覆盖原来定义的全局变量
pass
print(info3())
def info4():
name='jack'
age=10
global pos
pos='北京' # 通过global 关键字修改全局变量
print(name,age,pos,job)
pass
print(info4())
结果如下:

2、函数参数引用传值
- 参数传递: python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。(即python中不存在所谓的传值调用,一切传递的都是对象的引用,也可以认为是传址)。在python中,值是通过引用来传递的,可以用id()查看一个对象的引用是否相同,id是值保存在内存中的位置标识。
- 关于对象: a、可变对象( list,dict):对象的内容是可变的;b、不可变的对象(int,string,float,tuple):表示其内容不可变。
2.1、不可变对象
- 不可变对象: 整型(int),字符(string),浮点型(float),元组(tuple)。改变的是函数内变量的指向对象。
#不可变对象:int,string,float,tuple
def fun_id():
a = 100
b = a
print('100的内存地址是{}'.format(id(100)))
print('a的内存地址是{}'.format(id(a)))
print('b的内存地址是{}'.format(id(b)))
print(a is b) #is也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同
print('----------------b改变之后--------------')
b += 1
print('a的内存地址是{}'.format(id(a)))
print('b的内存地址是{}'.format(id(b)))
print(a is b)
pass
fun_id()
结果如下:

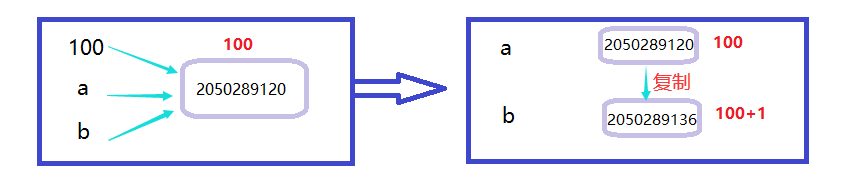
通过上诉我们知道,a变量最开始的值是100,其实并不是a这个值就是100,而是a这个变量指向了对象100,这个对象在内存中的地址是2050289120。当我们a赋给b时,其实就是让变量b也指向变量a所指向的内存空间(id相同,不变),对应的对象为100。 但是当我们修改b的值+1时,按道理a的值也应该发生变化,其实并不是,因为int是不可变对象,所以是b复制了一份到新的内存地址,然后+1 ,然后此时的b指向新分配的内存(id不同,变化),同样对应的对象也就变成了100+1,而不是原来内存所指的对象。
2.2、可变对象
- 可变对象: 列表(list),字典(dict)参数改变的是可变对象,其内容可以被修改。
# 可变对象:list,dict
def fun_id():
list1 = []
list2 = [1,2]
list3 = list2
print('list1的内存地址是{}'.format(id(list1)))
print('list2是:{},对应的内存地址是{}'.format(list2,id(list2)))
print('list3是:{},对应的内存地址是{}'.format(list3, id(list2)))
print(list2 is list3)
print('----------------list2改变之后--------------')
list2.extend(['python'])
print('list2是:{},对应的内存地址是{}'.format(list2, id(list2)))
print('list3是:{},对应的内存地址是{}'.format(list3, id(list2)))
print(list2 is list3)
pass
fun_id()
结果如下:
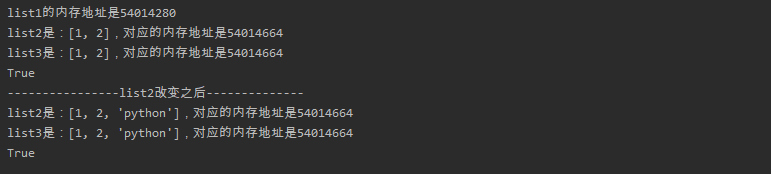
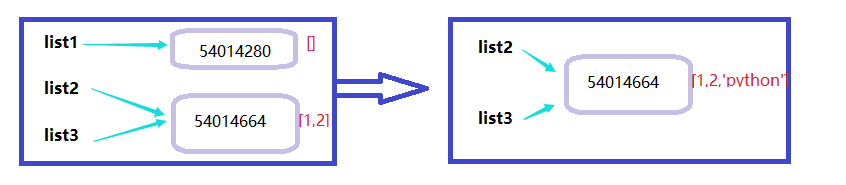
由上可知:list2最早的内存地址id是11416264,指向对象是一个列表[1,2] 然后把list2赋值给list3其实就是让变量list3的也指向list2所指向的内存空间。然后我们发现当list2发生变化后,list3也跟着发生变化了,因为list是可变类型,所以并不会复制一份再改变,而是直接在list2所指向的内存空间修改数据(即原来的内存id不变),而list3也是指向该内存空间的,自然list也就跟着改变了。
2.3、函数的参数传递
python中规定参数传递都是引用传递,也就是传递给函数的是原来变量所指向的内存地址(即对象),当我们修改的时候就会根据该引用的指向取修改内存中的内容,(那么就会考虑是不可变参数的话就相当于复制一份修改,可变参数就直接修改)进而对函数外部的变量是否产生影响。因此当传过来的参数是可变类型(list,dict)时,我们在函数内部修改就会影响函数外部的变量(直接修改所指向的内存地址),此时外部的同一个变量也会跟着指向修改的内存地址。而当我们传入的参数是不可变类似(int,float,tuple,string)时在函数内部修改就不会影响函数外部的变量(复制一份在修改),函数内部修改的已经指向另一个内存地址,函数外部的还是指向原来的内存地址。下面通过代码来说明:
def test(a_int, b_list):
a_int = a_int + 1
b_list.append('13')
print('函数内部a_int:{}' .format(a_int))
print('函数内部b_list:{}' .format(b_list))
pass
a_int=5
b_list=[10,11]
test(a_int,b_list)
print('函数外部a_int:{}'.format(a_int))
print('函数外部b_list:{}'.format(b_list))
结果如下:

由上可知:经过test()修改后,传递过来的int类型外部变量int_a并没有因函数内部的int_a发生改变而改变,而list这种可变类型则因为test()函数内部list_b的变化影响函数外部list_b的变化。python只允许引用传递是为方便内存管理,因为python使用的内存回收机制是计数器回收,就是每块内存上有一个计数器,表示当前有多少个对象指向该内存。每当一个变量不再使用时,就让该计数器-1,有新对象指向该内存时就让计数器+1,当计时器为0时,就可以收回这块内存了。
3、匿名函数
- 匿名函数: python使用lambda来创建匿名函数,定义方法:lambda 参数1,参数2,参数…:表达式
- lambda只是一个表达式,而并非一个代码块,函数体仅仅只有一行,比def函数体简单,匿名函数自带return,而这个return的结果就是表达式计算的结果。
- 调用:匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
- 三元运算(三目运算)在Python中也叫条件表达式。三元运算的语法非常简单,主要是基于True/False的判断。如下图:

#匿名函数
result=lambda x,y:x*y
sum=(lambda x,y:x+y)(10,20)#将匿名函数赋值给sum ,其实sum就相当于一个函数名
print(sum)
print(result(10,10))
def sum(x,y):
return x+y
#三元运算
db=lambda x,y:x if x>y else y
print(db(7,2))
#结果:
30
100
7

注意: lambda函数为了解决那些功能很简单的需求而设计的一句话函数,使用lambda表达式并不能提高代码的运行效率,它只能让你的代码看起来简洁一些。
4、递归函数
- 递归函数: 递归函数就是函数在内部调用自身。必须有一个明确的递归结束条件,称为递归出口。
# 递归函数
def fun_dg(n):
if n == 1:
return 1
else:
return n * fun_dg(n-1)
pass
print(fun_dg(5))
#fun_dg(5) # 第 1 次调用使用 5
#5 * fun_dg(4) # 第 2 次调用使用 4
#5 * (4 * fun_dg(3)) # 第 3 次调用使用 3
#5 * (4 * (3 * fun_dg(2))) # 第 4 次调用使用 2
#5 * (4 * (3 * (2 * fun_dg(1)))) # 第 5 次调用使用 1
#5 * (4 * (3 * (2 * 1))) # 从第 5 次调用返回
#5 * (4 * (3 * 2)) # 从第 4 次调用返回
#5 * (4 * 6) # 从第 3 次调用返回
#5 * 24 # 从第 2 次调用返回
#120 # 从第 1 次调用返回
#等价于迭代
def sum(n):
sum=1
for i in range(1,n+1):
sum*=i
pass
return sum
print(sum(5))
'''
os模块提供了多数操作系统的功能接口函数,和系统进行交互。当os模块被导入后,它会自适应于不同的操作系统平台,
根据不同的平台进行相应的操作,在python编程时,经常和文件、目录打交道,这时就离不了os模块
需要注意的是它接收的参数需要是一个绝对的路径(即完整的路径)
'''
import os #引入OS模块
print(os.listdir('E:\\学习')) #列出对应目录下所有的文件和目录名
print(os.sep) #用于系统路径的分隔符,windows:\\ linux:/
print(os.name) #指示正在使用的工作平台: windows:nt Linux:posix
print(os.getenv('path')) #读取环境变量
print(os.getcwd()) #获取当前路径
print(os.path.isdir('E:\\学习')) #判断对应路径下的文件是否是目录
print(os.path.isfile('E:\\学习')) #判断对应路径下的文件是否是目录
'''
os.path.join()函数:连接两个或更多的路径名组件
1.如果各组件名首字母不包含’/’,则函数会自动加上
2.如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃
3.如果最后一个组件为空,则生成的路径以一个’/’分隔符结尾
'''
# 遍历指定文件夹,列出所有文件
def listfile(filepath):
listA=os.listdir(filepath) #列出对应目录下的文件赋值给listA
for filename in (listA): #通过for循环开始开始遍历
fullpath=os.path.join(filepath,filename) #获取文件的完整路径
if os.path.isdir(fullpath): #必须接受绝对路径(即完整路径)
listfile(fullpath) #若为目录继续递归遍历
else:
print(fullpath) #不是目录即文件,输出文件名
pass
pass
else:
return
pass
listfile('E:\学习\linux')

参考资料:
1、可变对象与不可变对象区别.
2、可变对象与不可变对象.
3、Python 函数.
4、Python 基础.
5、OS 模块介绍
6、Python必学的OS模块详解















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









