









前言
- 在之前的学习中 学习之旅11-R数据结构中,我们对数据结构有了一定的了解,也讨论了很多导入数据的方法,但是当我们将数据表示为矩阵或者数据框时,这仅仅是数据准备的第一步,我们在分析数据之前大部分的时间其实是花在数据的准备之上的,只有数据准备,清洗,整理完毕才能进行更好的数据分析。
4、基本数据管理
4.1 变量、因子
- 变量: 可以归纳为名义型、有序型、或连续型变量
(1)名义型变量: 名义型变量是没有顺序之分的类别变量。
(2)有序型变量: 有序型变量表示一种顺序关系,而非数量关系,比如某个状态high,mid,low,但是我们不知道具体之间的数量关系。
(3)连续型变量: 连续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量,比如年龄18,30这样的值以及其间的任意值,很明显15岁比14岁年长一岁。 - 因子: 名义型变量和有序型变量在R中都称为因子(factor),因子在R的整个框架中都尤为重要,我们在对数据进行分析时,就决定了数据的分析方式以及如果进行视觉呈现。
factor():以一个整数向量的形式存储类别值(名义型),整数的取值范围是[1… k ](其中k 是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。指定参数ordered=TRUE则表示有序型变量。给定向量sta1 <- c(“high”, “mid”, “high”, “low”),我们通过sta2 <- factor(sta1, orderd = TRUE),内部关联1=high, 2=low, 3=mid(这与我们需要的结果不一样,因为R会因字母顺序排序,此时需要我们自定义)
> data1 <- c("A","A","B","A","C") #data1中都是字符型,这些变量的唯一值个数为3,也就是上述中K 的值
> data2 <- factor(data1) #通过factor()函数将向量存储为(1, 1, 2, 1, 3),并在内部关联 为1=A,2=B,3=C,此时针对data2的任何分析都会将其作为名义变量对待
> data2
[1] A A B A C
Levels: A B C
> sta1 <- c("high", "mid", "high", "low")
> sta2 <- factor(sta1, ordered = TRUE)
> sta2
[1] high mid high low
Levels: high < low < mid
> sta3 <- factor(sta1, ordered = TRUE, levels = c("low", "mid", "high"))
> sta3
[1] high mid high low
Levels: low < mid < high
> #通过向量组组成编码因子,对于没有的变量则会被设置为缺失值,sta4中1=男,2=女,而nv没有的则为缺失值。
> sex <- c("男","男","女","男", "nv")
> sex
[1] "男" "男" "女" "男" "nv"
> sta4 <- factor(sex, levels = c(1, 2), labels = c("男", "女"))
> sta4
[1] <NA> <NA> <NA> <NA> <NA>
Levels: 男 女
> sta5 <- factor(sex, levels = c(1, 2, 3), labels = c("男", "女", "nv"))
> sta5
[1] <NA> <NA> <NA> <NA> <NA>
Levels: 男 女 nv
- 以下通过代码来具体分析普通因子与有序因子对数据分析的影响
> Pid <- c(1, 2, 3, 4, 5)
> name <- c("zs", "ls" ,"ww", "zl", "hq")
> age <- c(18, 23, 26, 31, 42)
> pos <- c("T1", "T2", "T2", "T1", "T3")
> lvl <- c("low", "mid", "low", "mid", "high")
> pos <- factor(pos) # 将pos作为普通因子即类别(名义)型变量。
> lvl <- factor(lvl, ordered = TRUE, levels = c("low", "mid", "high")) # 将lvl作为有序型变量(因子)
> Pdata <- data.frame(Pid, name, age, pos, lvl) # 合并为数据框
> str(Pdata) # 通过str()函数来查看Pdata数据框的信息,各变量的属性等
'data.frame': 5 obs. of 5 variables:
$ Pid : num 1 2 3 4 5
$ name: chr "zs" "ls" "ww" "zl" ...
$ age : num 18 23 26 31 42
$ pos : Factor w/ 3 levels "T1","T2","T3": 1 2 2 1 3
$ lvl : Ord.factor w/ 3 levels "low"<"mid"<"high": 1 2 1 2 3
> # 通过str()函数我们很明显知道pos为一个无序因子,而lvl为一个有序因子,以及内部如何编码的(这里我们自定义了)。
> summary(Pdata) #可以提供连续型变量(age)最小值、最大值、四分位数和均值,以及因子的频数统计。
Pid name age pos lvl
Min. :1 Length:5 Min. :18 T1:2 low :2
1st Qu.:2 Class :character 1st Qu.:23 T2:2 mid :2
Median :3 Mode :character Median :26 T3:1 high:1
Mean :3 Mean :28
3rd Qu.:4 3rd Qu.:31
Max. :5 Max. :42
4.1.1 创建变量
- 之前数据结构中:向量、矩阵、数据框都会通过创建变量或者对现有变量进行转换处理,这里的表达式可以是多样的(函数,关系运算等)
变量名 <- 表达式
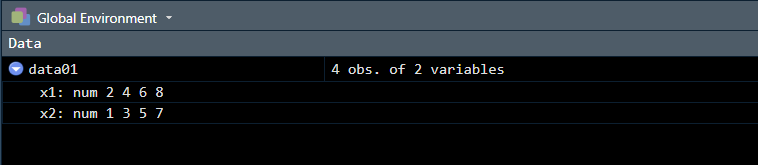
> data01 <- data.frame(x1 = c(2, 4, 6, 8), x2 = c(1, 3, 5, 7)); #此时我们创建了一个data01的数据框,其中有两个变量x1 ,x2,但是不在环境中
> data01
x1 x2
1 2 1
2 4 3
3 6 5
4 8 7
- 以上代码只会生成一个data01的数据框,x1,x2两个变量仅仅存在数据框里面,此时我们的内存中并没有单独将这两个变量列出来,此时我们调用这两个单独的变量就会报错。我们需要指定x1 ,x2来自哪个数据框。对于在数据框新增变量,我们可以采用多种方法:
> x1
错误: 找不到对象'x1'
> x2
错误: 找不到对象'x2'
> sum <- x1 + x2;
错误: 找不到对象'x1'
> data01$x1
[1] 2 4 6 8
> #方法一:指定数据框加变量
> data01$sum <- data01$x1+data01$x2 #需要指定来自哪个数据框,此时data01数据框新增了一个变量sum
> data01
x1 x2 sum
1 2 1 3
2 4 3 7
3 6 5 11
4 8 7 15
> #方法二:使用attach()函数将数据框添加的R搜索中
> attach(data01)
> data01$mean <- (x1 + x2)/2
> detach(data01)
> data01
x1 x2 sum mean
1 2 1 3 1.5
2 4 3 7 3.5
3 6 5 11 5.5
4 8 7 15 7.5
> detach(data01) #解除绑定
> 方法三:使用transform()函数
> data01
x1 x2 sum
1 2 1 3
2 4 3 7
3 6 5 11
4 8 7 15
> data02 <- transform(data01, dmean = (x1 + x2)/2)
> data02
x1 x2 sum dmean
1 2 1 3 1.5
2 4 3 7 3.5
3 6 5 11 5.5
4 8 7 15 7.5
使用attach()函数一定要特别注意,若我们环境中已经有sum这个变量或者之前已经被attach()绑定未释放,此时直接使用attach()会出现报错。transform(数据框名, 对数据框的一系列修改),这些修改中间用逗号分隔,不换行。transform()函数只能用于数据框改变,而within函数应用更宽泛一些,可以用于除数据框之外的数据对象的改变。
> sum <- data01$x1+data01$x2 #此时环境中已经有sum这个变量
> data01$sum <- data01$x1 + data01$x2 # 数据框新增一个sum变量
> attach(data01) #告知sum变量已经存在
The following object is masked _by_ .GlobalEnv:
sum
- 但是以下代码不仅生成data01的数据框,同时也生成了单独的x1,x2两个变量,这两个变量会单独存在内存中,我们可以直接调用:与上面不同的时这里不是用的 = ,而是用<- 符号。
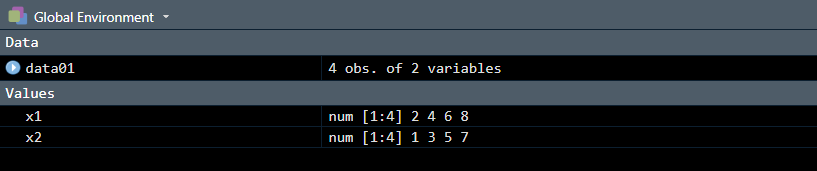
> data01 <- data.frame(x1 <- c(2, 4, 6, 8), x2 <- c(1, 3, 5, 7)); #此时我们创建了一个data01的数据框,其中有两个变量x1 ,x2在环境中
4.1.2 变量重编码
- 这里的重编码并不是关于字符集的编码,而是针对一个变量或多个变量的现有值创建新值的过程(修改连续型变量类型,将错误编码值改为正确值,通过数据来进行判断等)
> name <- c("zs","ls","ww","zl")
> sex <- c("男","男","女","男")
> age <- c(90,55,75,35)
> data03 <- data.frame(name,sex,age)
> data03
name sex age
1 zs 男 90
2 ls 男 55
3 ww 女 75
4 zl 男 35
- 对于以上数据,我们希望把年龄进行划分(“Y”,“M”,“O”),35及以下为Y,36-55为M,55以上为O。但是我们仅处理35及以下时,其他年龄会变为缺失值,若仅有两个值的判断,我们可以采用ifelse()进行逻辑判断。但是我们尽量使用attach()绑定数据框或者直接用withn()函数处理,with(data, exp1; exp2; …)与withn(data, exp1; exp2; …)的区别在于后者允许修改数据框,with函数的返回值是原语句的返回值。within跟with功能相同,但返回值不同,within会返回所有修改生效后的原始数据结构(列表、数据框等)。且两者后面都为表达式,应该换行或者用分号。
> data03$age_lv[data03$age <= 35] <- "young"
> data03
name sex age age_lv
1 zs 男 90 <NA>
2 ls 男 55 <NA>
3 ww 女 75 <NA>
4 zl 男 35 Y
> data03 <- data03[,-4] #恢复到原始data03
> data03$age_lv <- ifelse(data03$age <= 35,c("Y"),c("O"))
> data03
name sex age age_lv
1 zs 男 90 O
2 ls 男 55 O
3 ww 女 75 O
4 zl 男 35 Y
> data03 <- data03[,-4]
> data03$age_lv1 <- ifelse(data03$age <= 35,"young", ifelse(data03$age >55,"old","mid"))
> data03 <- data03[,-4]
> data05 <- within(data03, {age_lv[age <= 35] <- "Y"; age_lv[age >35 & age <=55] <- "M"; age_lv[age > 55] <- "O"})
> data03
name sex age age_lv1
1 zs 男 90 old
2 ls 男 55 mid
3 ww 女 75 old
4 zl 男 35 young
Error in age_lv[age <= 35] <- "Y" : 找不到对象'age_lv'
> #此时我们需要先定义age_lv
> age_lv <- c("Y","M","O")
> data05 <- within(data03, {age_lv[age <= 35] <- "Y"; age_lv[age >35 & age <=55] <- "M"; age_lv[age > 55] <- "O"})
> data05
name sex age age_lv
1 zs 男 90 O
2 ls 男 55 M
3 ww 女 75 O
4 zl 男 35 Y
关于变量重编码还有recode()函数以及cut()函数等,这里不展开讨论,可以参考其他资料学习。
4.1.3 变量重命名
- 对于一些变量的名称我们为了方便记忆和管理,有时会进行变量的重命名。比如data05中的age_lv 改为lv,可以通过fix(data05) 修改数据框来处理。
> data05
name sex age age_lv
1 zs 男 90 O
2 ls 男 55 M
3 ww 女 75 O
4 zl 男 35 Y
> fix(data05)

- 或者直接通过命令names(data05)[4] <- “lv”
> names(data05)[4] <- "lv" #对数据框data05的第4列变量重命名
> data05
name sex age lv
1 zs 男 90 O
2 ls 男 55 M
3 ww 女 75 O
4 zl 男 35 Y
- 或者通过rename()函数处理
plyr包可以进行类似于数据透视表的操作,将数据分割成更小的数据,对分割后的数据进行些操作,最后把操作的结果汇总,rename()函数就是其中的一个。rename(x, replace, warn_missing = TRUE, warn_duplicated = TRUE),
x: 重命名的对象
replace:命名的向量,c(old_name=“new_name”,…)
> install.packages("plyr")
> library(plyr) # 可以通过?plyr来查看该函数详细介绍
> data06 <- rename(data05, c(age = "age1", lv = "age_lv1"))
> data06
name sex age1 age_lv1
1 zs 男 90 O
2 ls 男 55 M
3 ww 女 75 O
4 zl 男 35 Y















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









