







1、字符串的驻留机制
1.字符串:
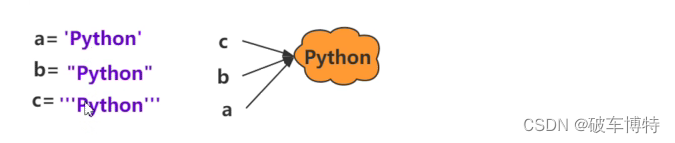
在Python中字符串是基本数据类型,是一个不可变的字符序列,可用单引号:’ ‘,双引号:" ",三引号:’‘’ ‘’’ 进行定义。
2.什么叫字符串驻留机制呢?
:仅保存一-份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
3.字符串驻留机制的优缺点
●当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的。
●在需要进行字符串拼接时建议使用str类型的join方法, 而非+ ,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率要比"+"效率高
a = 'okcj'
b = "okcj"
c = '''okcj'''
d = """okcj"""
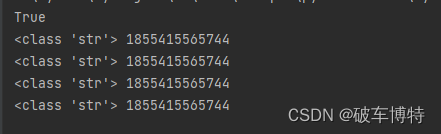
print(a == b == c == d)
print(type(a), id(a))
print(type(b), id(b))
print(type(c), id(c))
print(type(d), id(d))
结果:
2、字符串的常用操作
2.1查询操作
s = "123321cyh789cyh"
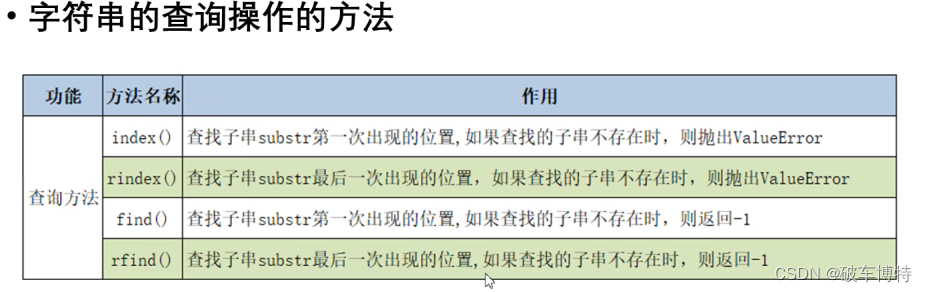
# index(),rindex()
print(s.index("cyh")) # 6 返回该子字符串第一次出现的索引
# print(s.index("myname")) # 没有找到该字符串在当前字符串中出现的位置,抛出异常ValueError
print(s.rindex("cyh")) # 12
# find(),rfind
print(s.find("cyh")) # 6
print(s.find("myname")) # -1
print(s.rfind("cyh")) # 12
2.2.查询操作

s = "AbCdMyname tom"
# 注:以下方法,都会生成新的字符串,原来字符串并没有被修改
print(s.lower()) # abcdmyname tom
print(s.upper()) # ABCDMYNAME TOM
print(s.swapcase()) # aBcDmYNAME TOM
print(s.capitalize()) # Abcdmyname tom
print(s.title()) # Abcdmyname Tom :识别为空格间隔为一个单词
2.3.对齐

s1 = "myname is cyh"
# 注1:以下函数如果传入的第一个参数小于本身字符串,那么返回本身
# 注2:以下函数均产生了新的字符串,原字符串并没有被修改
print(s1.center(20,"*"))
print(s1.ljust(20,"*"))
print(s1.rjust(20,"*"))
print(s1.zfill(20))
print(s1)
s2 = s1.center(20,"*")
print(s2)
运行结果如下:

2.4字符串的分割
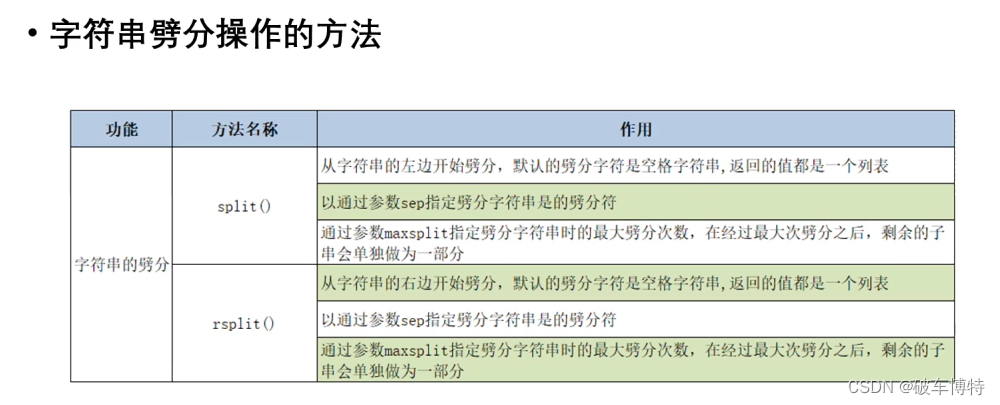
# 字符串的分割
s1 = "Hello Word My Python "
# 没有指定分割符,默认空格作为分隔符,最后返回列表对象
ls01 = s1.split()
print(ls01) # ['Hello', 'Word', 'My', 'Python']
# 指定参数作为分割符,sep=分割符 ,maxsplit=分割次数
s2 = "Hello|Word|My02|Python"
print(s2.split(sep="|", maxsplit=2)) # ['Hello', 'Word', 'My02', 'Python']
# rsplit() 从右边开始分割
print(s2.rsplit(sep="|",maxsplit=1)) # ['Hello|Word|My02', 'Python']
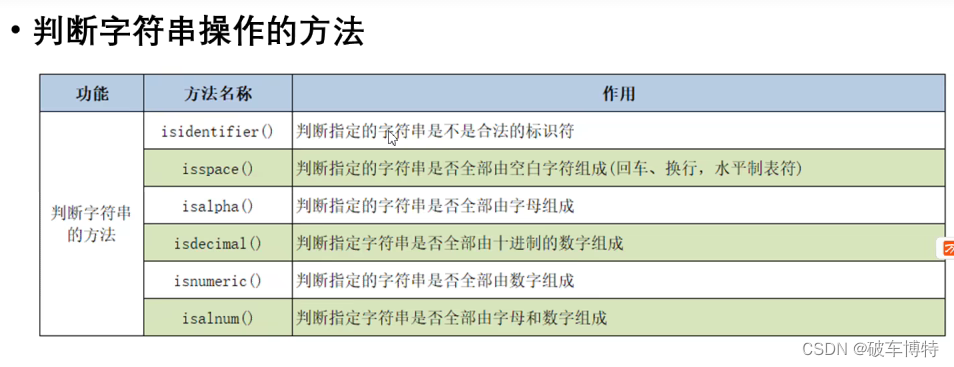
2.5 字符串的判断
# 判断字符串
s1 ="123_adb "
s2 =" "
s3 = "dasjdka王德发"
s4 = "12313217889"
# isidentifier():判断字符串是否是合法标识符
print(s1.isidentifier())
# isspace():判断字符串是否全部由空格,回车,tab键组成
print(s2.isspace())
# isalpha():判断字符串是否全部有字母组成(汉字也算字母)
print(s1.isalpha())
print(s3.isalpha())
# isdecimal():判断字符串是否全部有十进制数组成
print(s4.isdecimal())
# isalnum():判断字符串是否全部由数字,字母组成
print(s1.isalnum())
2.6 字符串的其他操作

注意:join()函数,列表/元组中的元素必须全为str类型
# replace():字符串替换(原字符串不进行修改,产生新的字符串)
# 参数解释:第一个参数为被替换对象,第二个参数为以该对象替换,第三参数为:替换的次数
s1 = "myname is cyh ,cyh is me,cyh very good!"
print(s1.replace("cyh", "ccyyhh", 2)) # myname is ccyyhh ,ccyyhh is me,cyh very good!
print(s1) # myname is cyh ,cyh is me
# join() :将列表或元组以某个字符串为中介进行连接为字符串
# 注:列表/元组中的元素只能为str类型
ls01 = ["My", "Name", "OK"]
print("-".join(ls01))
3、字符串的比较

# 字符串的比较
s1 = "abcd"
s2 = "bcd"
s3 = "abce"
s4 = "abcd"
# 内置函数:ord()
print(ord(s1[0])) # 首字符为a :97
print(ord(s2[0])) # 首字符为b :98
# 内置函数:chr()
print(chr(97)) # a
print(chr(98)) # b
print(s1 > s2) # False
print(s1 > s3) # False
4、字符串的切片操作
基本语法:字符串[start🔚step]
参数解释:
第一参数:起始下标 (默认0开始)
第二参数:结束下标(不包括该下标元素)(默认最后一个元素)
第三参数:步长/方向, 当步长为:1 表示:以步长为1进行正向截取,当步长为:-1 表示逆向以步长为1进行截取step正数表示左到右,负数表示右到左实际使用的时候需要根据具体实例,进行方向的确定,以下例子就很好的诠释了该方向的使用。
s1 = "abcadsa"
# 参数解释:
# 第一参数:起始下标 第二参数:结束下标(不包括该下标元素)
# 第三参数:步长/方向, 当步长为:1 表示:以步长为1进行正向截取,当步长为:-1 表示逆向以步长为1进行截取
print(s1[:4:2]) # ac :默认从0开始
print(s1[0:4:2]) # ac :步长为2,也就是间隔截取
print(s1[::-1]) # asdacba : 逆向
# 错误示范: print(s1[5:1:1]) ,方向必须一致,step正数表示左到右,负数表示右到左
print(s1[-4:-1:1]) # 由-4 ---> -1 左到右,step需要为正数
print(s1[5:1:-1]) # sdac
5、格式化字符串

一共有三种格式化字符串的方式:
第一种:使用百分号:%做占位符
第二种:使用花括号做占位符
第三种:使用f.string 形式,表示格式化(这种方式,比较明确)
具体用法看如下代码:
# 格式化字符串
# 第一种:使用百分号:%做占位符
# 格式为: "字符串" % (value1,value2......) 对应占位符应该有对应的类型值
name = "CYH"
age = 12
print("我叫%s,现在%d岁,%d" % (name, age, age))
# 第二种:使用花括号
# 格式如下:{ format中元组值下标 } 做占位符
print("我叫{0},今年{1}岁了".format(name,age))
# 第三种:使用f.string 形式,表示格式化(这种方式,比较明确)
print(f"我叫{name},今年{age}岁了")
表达具体字符串宽度和精度:
# 字符串表示精度和宽度
s = '%.3f' % 3.1415926 # 表示保留三位小数
s1 = "%10d" % 99 # 表示共占十个字符位置
s2 = "%10.3f" % 3.14159 # 表示共占十个字符位置,保留三位小数(四舍五入)
print(s)
print(s1)
print(s2)
print(type(s)) # str
print(type(s1)) # str
print(type(s2)) # str
# 第二种方式
print('{0:5.2f},{1:5}'.format(3.1415926, 3333333333333333)) # 当宽度小于字符串本身的时候,不起作用
print('{0:5.2f},{1:20.2f}'.format(3.1415926, 3333333333333333))
6、字符串的编码转换
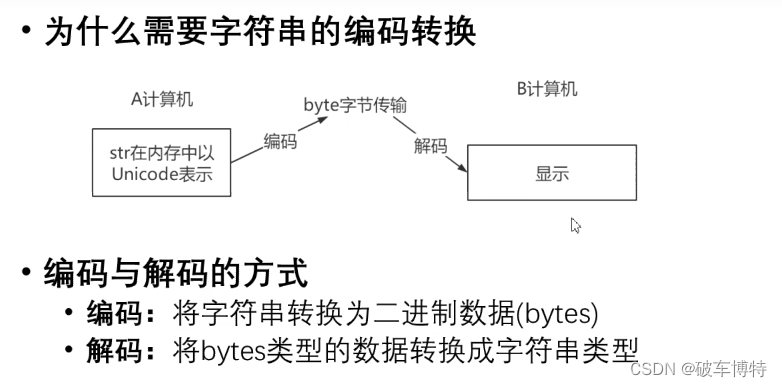
# 字符串编码和解码
# 编码
s = "明月几时有"
print(s.encode(encoding="UTF_8")) # 在UTF-8的字符编码的格式下一个汉字占3个字节
print(s.encode(encoding="GBK")) # 在GBK的字符编码的格式下一个汉字占2个字节
s01 = s.encode(encoding="UTF_8")
print(type(s01)) # <class 'bytes'>
# 解码(使用什么编码类型编,就用什么解码)
print(s01.decode(encoding="UTF-8"))














 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









