






 本文详细探讨了Transformer中的关键组成部分,包括位置编码方法(如绝对和相对位置编码)、VisionTransformer中的可训练变换,以及词嵌入(如BPE和词向量模型)。同时介绍了层归一化和自注意力机制在Transformer架构中的作用,以及MLP在处理序列信息的方式。
本文详细探讨了Transformer中的关键组成部分,包括位置编码方法(如绝对和相对位置编码)、VisionTransformer中的可训练变换,以及词嵌入(如BPE和词向量模型)。同时介绍了层归一化和自注意力机制在Transformer架构中的作用,以及MLP在处理序列信息的方式。

Transformer
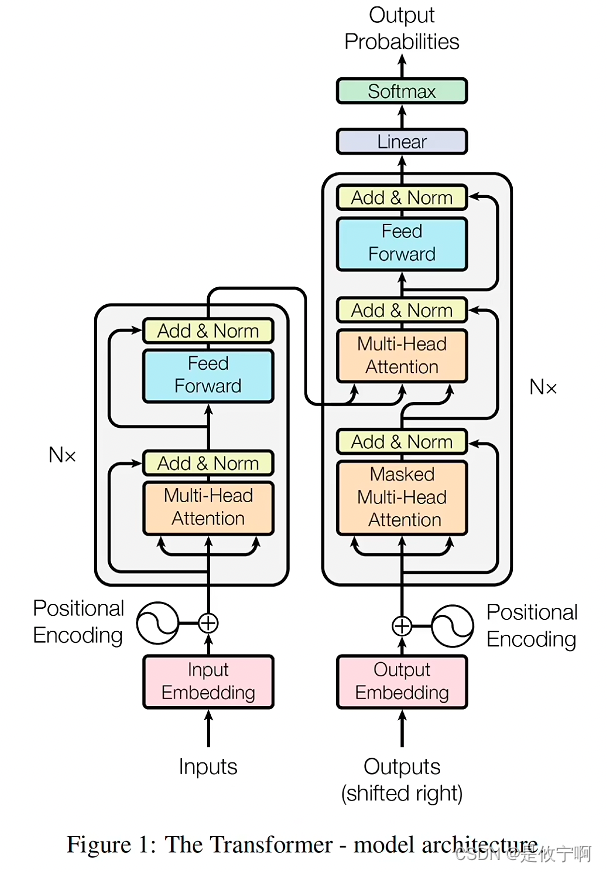
总览
encoder
decoder

Postion embedding:

1.Transformer中的位置编码是1d absolute sin/cos constant(是一个pos行,dim列的位置矩阵):

代码实现上述公式:

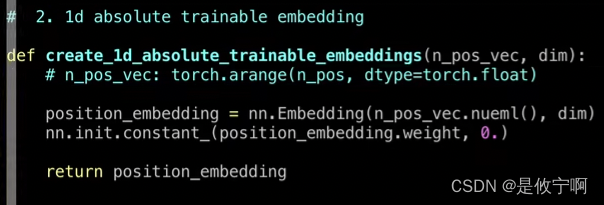
2.Vision Transformer中使用的是1d absolute traninable (是一个矩阵):
3.Swin Transformer 是 2d relative bias trainable,因为暂时用不到,故先不写
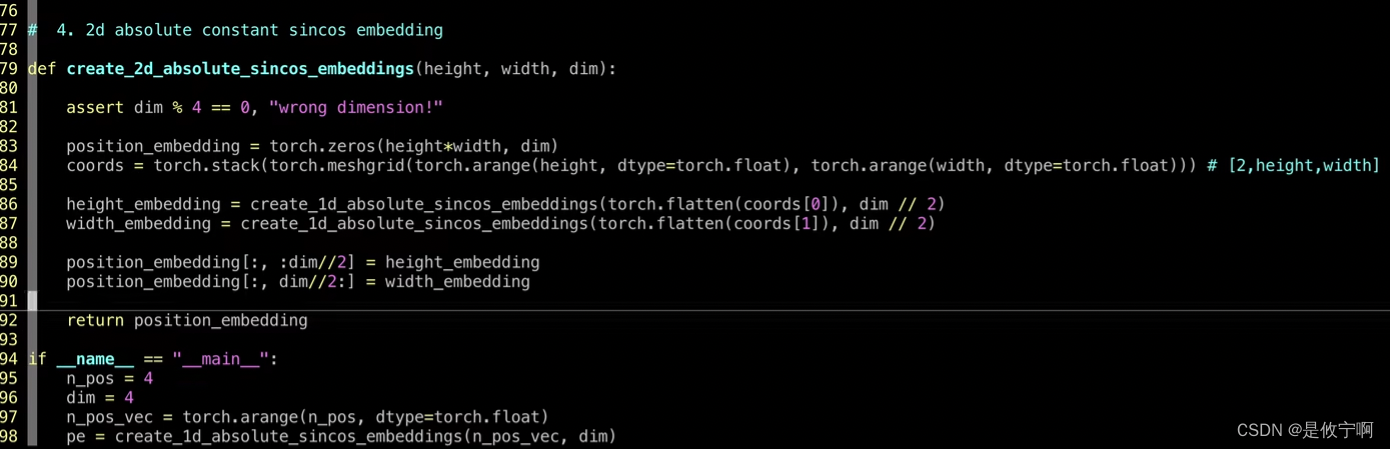
4.Masked AutoEncoder 是2d absolute sin/cos constant(x和y两个方向,每一个都有sin/cos),batch = height * weight(批大小)
Embedding(BPE)

以字符character为单位进行计算 :寻找一个字符串中出现频率最高的字符对,并且用一个未曾使用过的新的字符来代替,从而对原始的字符串进行压缩

步骤:


将词切分为子词,需要两步:
(1)建一个语料库:子词词汇表
(2)把任意一个语料切成一个或多个子词
(1)把单词中包含的字母都加入到vocabulary中

把出现最频繁的st 加入到词汇表和token pairs

不断重复上述过程
 最后没用重复的词对,第一步完成
最后没用重复的词对,第一步完成
(2)有了词汇表之后如何把一个新的语料切成子词
把每一个词切成字符的形式,然后递归的拿着邻接的

最后会加分隔符,以便保证单词完整的语意
![]()
![]()
word embedding
也称为词向量或词嵌入,是一种将词或短语映射到固定大小的向量空间的方法。这种方法通过学习词之间的上下文关系,将每个词表示为一个实数向量。这些向量捕获了词的语义信息,使得语义上相似的词在向量空间中彼此接近。常见的Word Embedding方法包括Word2Vec、GloVe和FastText等
NNLM

代码实现模型:

(1)构建单词表

(2)两个线性层
self.linear1 = nn.Linear(context_size * embedding_dim, 128) context_size是用前面几个单词来预测当前单词的数量,类似于CBOW,是隐含层
self.linear2 = nn.Linear2(nn.Linear(128,vocab_size))输出层,输出概率预测
word2vec
Prompt-Tuning——深度解读一种新的微调范式 - 知乎
分为两种,CBOW和skip-gram
text embedding & postion embedding
nn.Embedding 是 PyTorch 中用于词嵌入的模块。词嵌入是一种将词或标记表示为固定大小的向量的技术,这些向量捕获了词的语义信息。nn.Embedding 是 PyTorch 的 torch.nn 模块中的一部分,可以用于将整数索引转换为密集向量。
以下是 nn.Embedding 的源码概述和讲解:
源码概述
class Embedding(Module):
def __init__(self, num_embeddings, embedding_dim, padding_idx=None):
super(Embedding, self).__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.padding_idx = padding_idx
if padding_idx is not None:
self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))
self.weight[padding_idx] = torch.zeros(embedding_dim)
else:
self.weight = Parameter(torch.empty((num_embeddings, embedding_dim)))
self.reset_parameters()python复制代码
讲解
-
初始化函数
__init__:num_embeddings:嵌入层中的词汇表大小,即不同词的数量。embedding_dim:嵌入向量的维度。padding_idx:可选参数,表示在词汇表中用于表示填充或无效索引的索引。如果提供,则该索引处的嵌入将始终为零向量。
-
权重初始化:
权重矩阵self.weight是一个形状为(num_embeddings, embedding_dim)的矩阵,其中包含了所有的嵌入向量。如果指定了padding_idx,则在该索引处的嵌入向量初始化为零向量。否则,权重矩阵会随机初始化。 -
重置参数函数
reset_parameters:
这是一个可选的辅助函数,用于重置参数。默认情况下,它只是调用权重参数的.data.zero_()方法来将所有权重设置为零。这通常在训练后用于清零嵌入权重,以便进行下一次训练。 -
前向传播:
在forward方法中,给定一个整数张量indices(表示每个输入元素的索引),nn.Embedding会计算相应的嵌入向量。计算方式是通过从self.weight中选择与indices对应的行来完成的。 -
使用例子:
在使用nn.Embedding时,通常会创建一个实例并将其添加到模型中。然后,可以在前向传播过程中使用该嵌入层来获取嵌入向量。例如:
python复制代码
embedding = nn.Embedding(num_embeddings=1000, embedding_dim=50) | |
input = torch.LongTensor([10, 20, 30]) # 假设词汇表中这些索引对应的词分别为 "apple", "banana", "cherry" | |
output = embedding(input) # 输出形状为 (3, 50) 的张量,对应于每个输入词的嵌入向量 |
Layer Normalization

1.batch normalization和 layer norm
layer norm
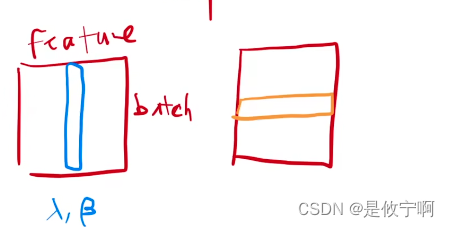
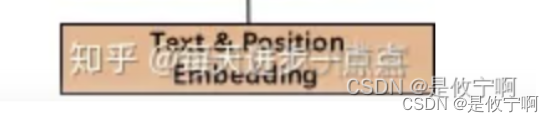
这是一个batch,每一行是一个样本,每一列是一个特征
batch norm是把每一列,即每一个特征,在一个小的mini-batch里,均值变为0,方差变为1
layer norm 是把每一行,即每一个样本,均值变为0,方差变为1

(batch_size, seq_len, feature)
batch norm是对每一个特征,均值变为0,方差变为1
layer norm是对每一个样本,均值变为0,方差变为1
但因为在时间序列中,每个样本的长度可能会变化,在算均值和方差的时候更方便一些
Batch Normalization(批标准化)和Layer Normalization(层标准化)都是神经网络中的标准化技术,它们对数据进行归一化处理以加速训练和提高模型的稳定性。
(1)Batch Normalization
是对每个batch的数据进行归一化处理,通过计算每个神经元的均值和方差,将数据规范化到均值为0、方差为1的分布。这样可以加速模型的收敛速度,提高模型的泛化能力。Batch Normalization主要用于卷积神经网络(CNN)等需要大量数据预处理的模型中。
是第l层的第i个样本(对一个minibatch内所有样本的同一维度去做归一化)


(2)Layer Normalization
在一个样本内进行归一化
则是对单个神经元或一个特征映射的所有神经元进行归一化处理,综合考虑一个层内所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入。Layer Normalization主要用于循环神经网络(RNN)和Transformer等需要序列数据的模型中,因为它可以更好地处理序列数据的特性。

对于每一层所有神经元,共享同样的均值和标准差,但每个样本有各自的参数。
如batchsize=10, 我们会有10套均值和标准差
只和神经元的数量有关,与batch size的大小无关
用到RNN中
1.层归一化对于每个时刻进行单独的归一化,归一化的参数跟神经元的个数有关,与batchsize大小无关
2.不同时刻所用到的增益和偏置是共享的,所以不用担心变长问题
是第t时刻的第i个隐藏神经元

总的来说,Batch Normalization和Layer Normalization都是为了解决神经网络中数据分布不一致的问题,它们的使用取决于具体的模型和任务需求
2.图解(三种归一化权重或数据改变的变与不变性)
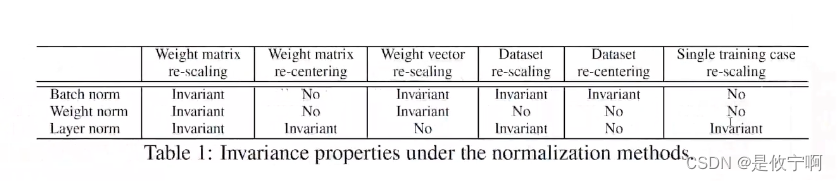
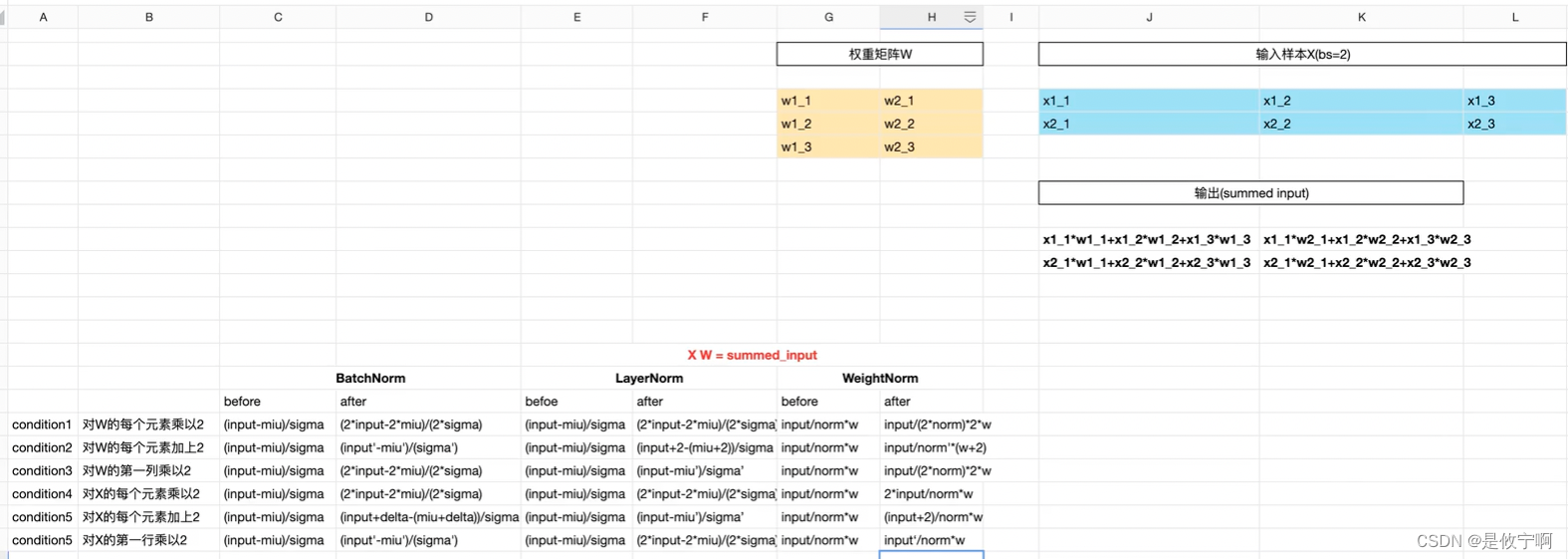
在input中:bn是一列(每一列的结果是代表一个batch中的数据*权重得到的结果),lb是对同一行(每一行的结果代表一个样本*权重所得到的结果)
3.层归一化代码
def layernorm(x, eps=1e-6):
"""
Layer Normalization function.
Args:
x (torch.Tensor): Input tensor.
eps (float): A small constant to prevent division by zero.
Returns:
Normalized tensor.
"""
# 计算均值和方差
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# 归一化处理
normalized = (x - mean) / (std + eps)
# 缩放和平移
scale = torch.ones_like(mean) # 缩放参数,默认为1
shift = torch.zeros_like(mean) # 平移参数,默认为0
return scale * normalized + shift自注意力机制

1.图解
+------------------------------------------------------------------------------+ | |
| Masked Multi-head Self-Attention | | |
+------------------------------------------------------------------------------+ | |
| Input: Query, Key, Value (Q, K, V) | | |
+------------------------------------------------------------------------------+ | |
| 1. Split the input tensor into multiple heads (num_heads) | | |
| 2. Apply scaled dot-product attention to each head (H_i) | | |
| 3. Concatenate the attention outputs from all heads | | |
| 4. Apply feed-forward network to the concatenated output | | |
| 5. Apply residual connection and layer normalization | | |
+------------------------------------------------------------------------------+ | |
| Output: Processed input tensor | | |
+------------------------------------------------------------------------------+ |
在图中,输入的Query、Key和Value首先被拆分成多个头(num_heads),然后每个头分别进行缩放点积注意力计算。接着,将所有头的注意力输出拼接在一起,并通过一个前馈网络进行处理。最后,通过残差连接和层归一化,将输入的tensor进行加工处理,得到输出结果。在整个过程中,掩码机制用于确保模型不会看到未来的信息,从而保证模型的正确性和稳定性。
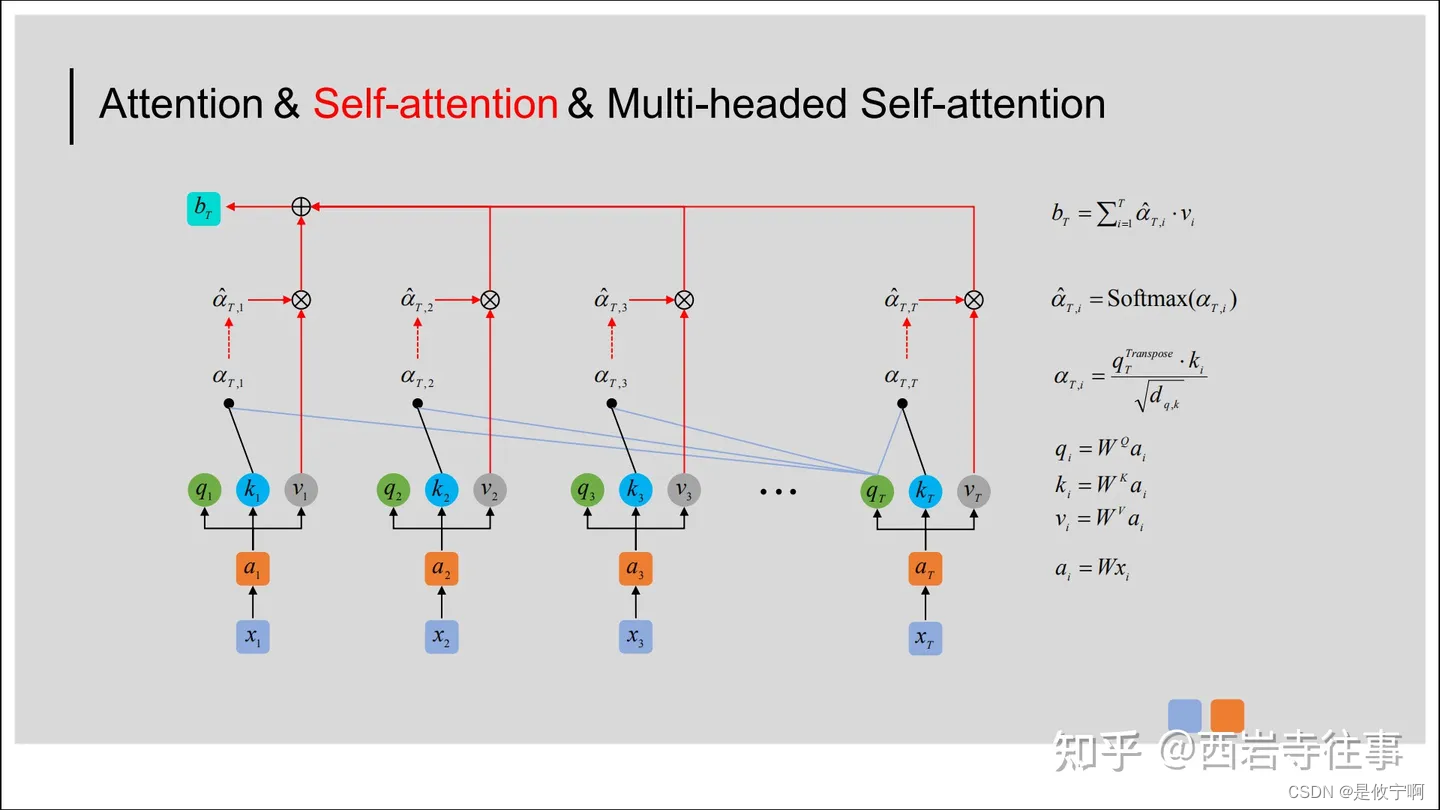
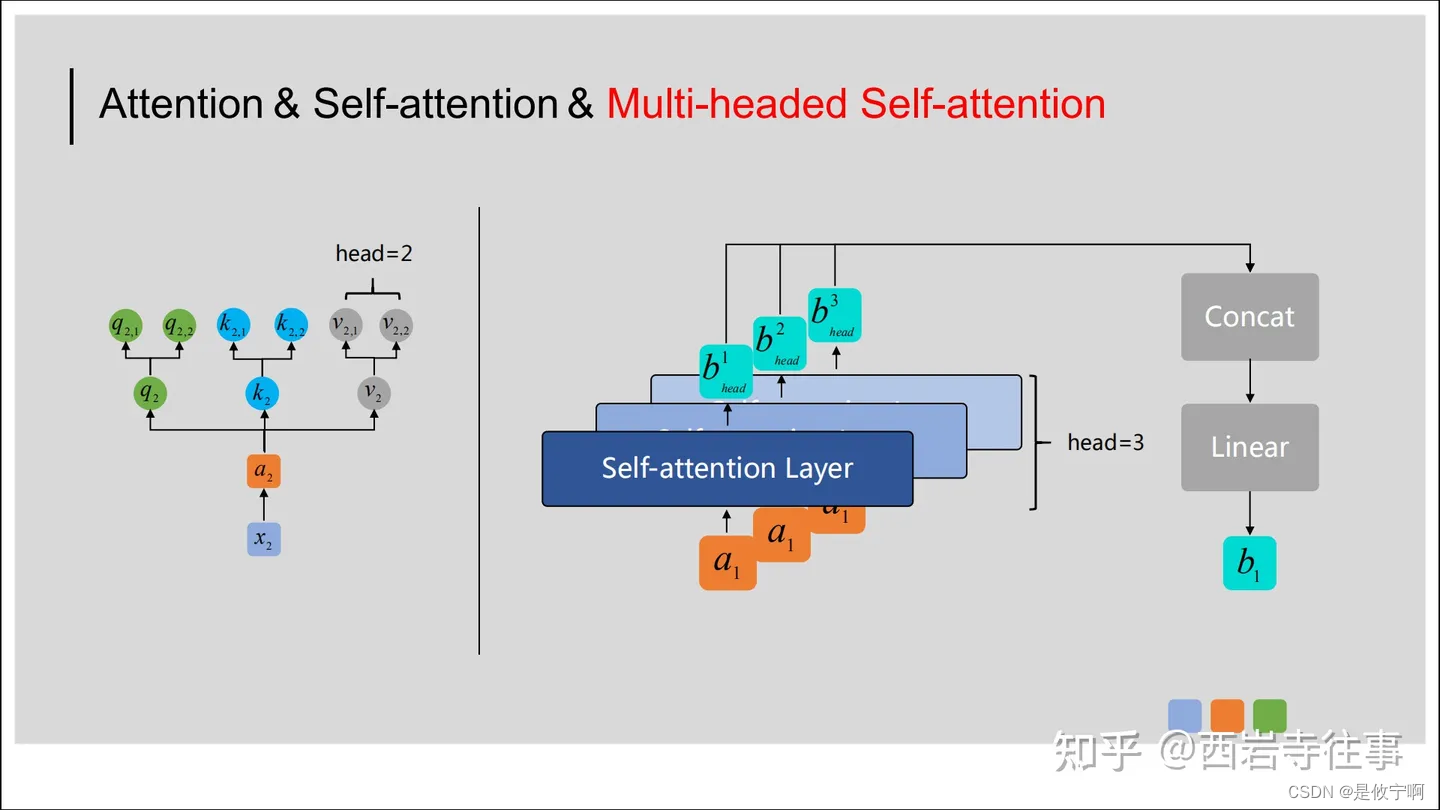
2.代码(因果自注意力的代码)
MLP(multi-layer perception)

1.概念
MLP层,即多层感知器层,是一种前向结构的人工神经网络,可以映射一组输入向量到一组输出向量。除了输入输出层,MLP中间可以有多个隐层,最简单的MLP只含一个隐层。MLP层与层之间是全连接的,即上一层的任何一个神经元与下一层的所有神经元都有连接。每个节点都是一个带有非线性激活函数的神经元,可以使用反向传播算法的监督学习方法进行训练。
即feedforward
MLP层
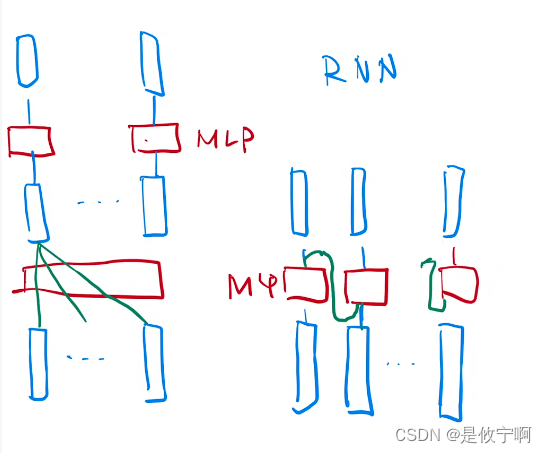
如何进行序列信息的传递:
Transformer:在attention层中已经提取了全局的序列信息,所以在MLP层做语意的转换(只需要对单点做就可以point-wise)
RNN:把上一个时刻的信息输出传到下一个时刻做输入
2.代码实现

Block
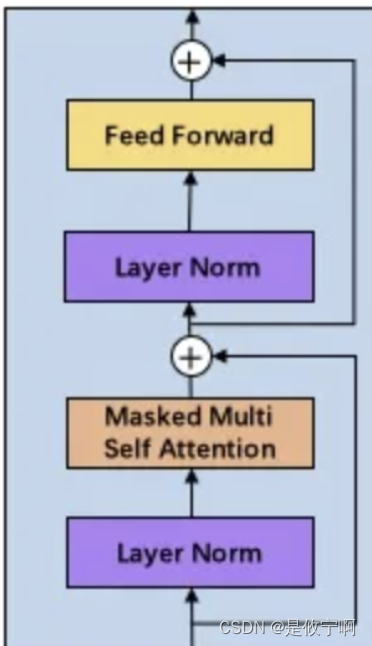

model
















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









