







安装
splinter安装
pip安装
pip install splinter以上安装会同时安装selenium。

源码安装
git clone git://github.com/cobrateam/splinter.git
cd splinter
python setup.py installSplinter的使用必修依靠Cython、lxml、selenium这三个软件.selenium在安装splinter会自动被安装。
pip install Cython
pip install lxml安装测试
安装完成后,可以直接在python的交互环境中验证是否安装成功。
>>> from splinter.browser import Browser
>>> browser = Browser()#默认使用Firefox,如果未安装会报错
>>> b = Browser("chrome")#指定浏览器,使用chrome浏览器如果没有错误会打开Chrome浏览器。
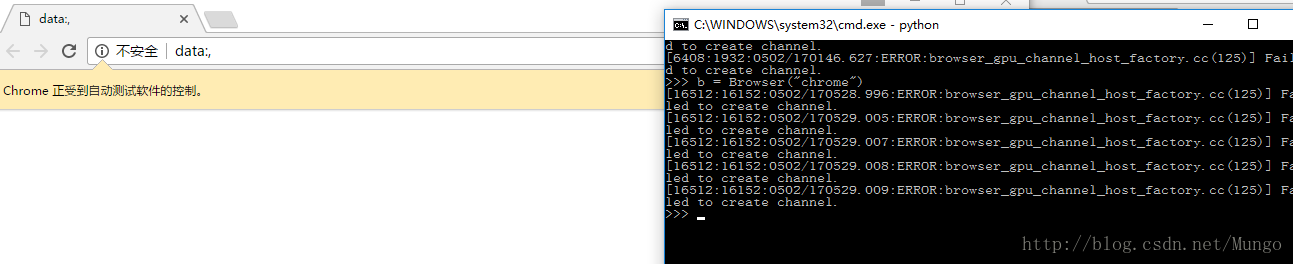
下面的代码,会让上面打开的浏览器里打开百度首页。
>>> b.visit("http://www.baidu.com/")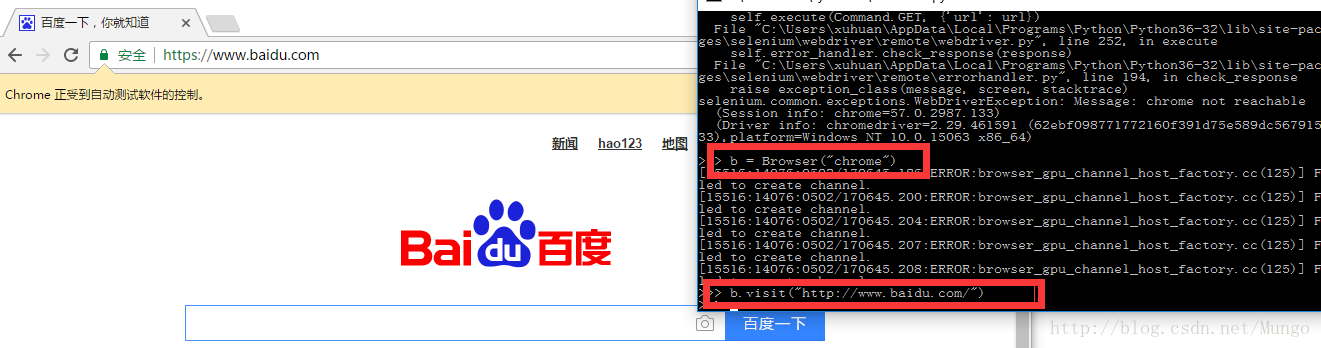
异常
执行可能会出如下错误:
1.geckodriver’ executable needs to be in PATH.
Traceback (most recent call last):
File "C:\Users\xuhuan\AppData\Local\Programs\Python\Python36-32\lib\site-packages\selenium\webdriver\common\service.py", line 74, in start
stdout=self.log_file, stderr=self.log_file)
File "C:\Users\xuhuan\AppData\Local\Programs\Python\Python36-32\lib\subprocess.py", line 707, in __init__
restore_signals, start_new_session)
File "C:\Users\xuhuan\AppData\Local\Programs\Python\Python36-32\lib\subprocess.py", line 990, in _execute_child
startupinfo)
FileNotFoundError: [WinError 2] 系统找不到指定的文件。这是缺少geckodriver,到https://github.com/mozilla/geckodriver/releases下载指定的版本,然后将解压的位置放入系统的环境变量中。
2.未安装Firefox浏览器
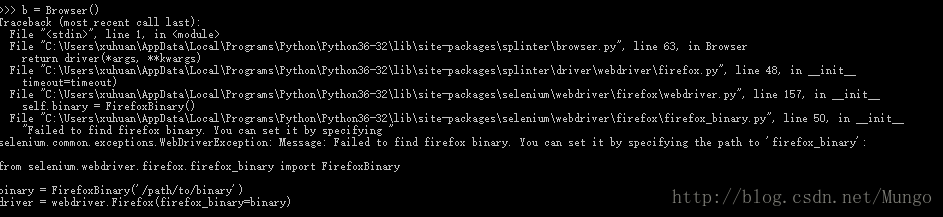
报错原因,splinter默认使用浏览器firefix。
如果要splinter支持Chrome浏览器,需安装chromedriver。到https://chromedriver.storage.googleapis.com/index.html下载指定版本的chromedriver,同geckodriver一样,将解压的位置放入系统的环境变量中。
使用
利用百度搜索
百度的首页应该都见过,关键就是一个输入框,一个百度一下的按钮。搜索发起就是在文本框输入想输入的内容,点击百度一下的按钮即可。目前百度搜索可以只在文本框输入内容就会自动发起搜索。但是如果多次搜索操作,还是需要点击百度一下的按钮的。
所以要实现百度自动搜索只需要两步:
- 将要搜索的内容填充到搜索框
- 点击百度一下按钮
先来分析下百度首页,如下图:
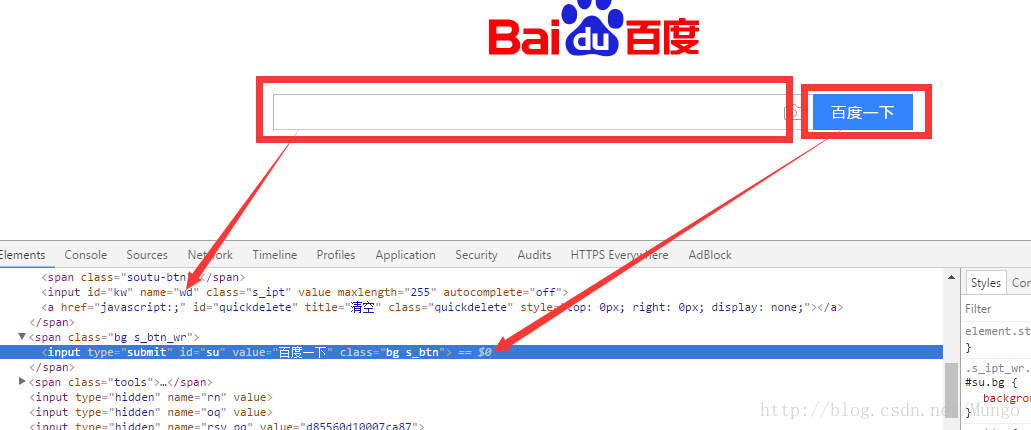
由上可以发现,百度搜索框input的id=kw,name=wd。百度一下按钮的id=su。
下面就是splinter如何操作浏览器了。
splinter操作浏览器使用splinter的Browser。通过API发现可以我们想要的填充数据和点击方法。
填充数据
| 方法 | 描述 |
|---|---|
| fill(name, value) | 通过控件name赋值 |
| fill_form(field_values) | 通过控件name赋值,参数是字典类型,即key为控件的name,字典项为要赋的值。支持text, password, textarea, checkbox, radio and select.checkbox必须制定字段字典项为boolean 类型 |
通过api可以看出,使用fill或fill_form填充数据似乎只能通过name填充。
选中页面某个控件
| 方法 | 描述 |
|---|---|
| find_by_css(css_selector) | 按css选择器查找页面元素 |
| find_by_id(id) | 按id查找页面元素 |
| find_by_name(name) | 按name查找页面元素 |
| find_by_tag(tag) | 按tag查找页面元素 |
| find_by_text(text) | 按text查找页面元素 |
| find_by_xpath(xpath) | 使用xpath选择器查询当前页面内容 |
| find_link_by_href(href) | 通过href查找当前页面中link |
| find_link_by_partial_href(partial_href) | 通过部分href值匹配link |
| find_link_by_partial_text(partial_text) | 通过部分text值匹配link |
| find_link_by_text(text) | 通过text查找link |
| find_option_by_text(text) | 通过text查找option元素 |
| find_option_by_value(value) | 通过value查找option元素 |
可以看出,splinter提供了丰富的api来进行页面的匹配。
通过上面的介绍,应该可以取得我们想要的元素了,下面就是对取得元素的操作。
这里只先说点击的操作,其他的可以参见splinter元素操作api.
| 方法 | 描述 |
|---|---|
| click() | 单击该元素 |
通过上面的介绍,自动百度搜索的代码就呼之欲出了。
# -*- coding: utf-8 -*-
from splinter.browser import Browser
b = Browser("chrome")
b.visit("http://www.baidu.com")
dict={"wd":"splinter"}
#b.fill("wd","splinter")
b.fill_form(dict)
button = b.find_by_value(u"百度一下")
button.click()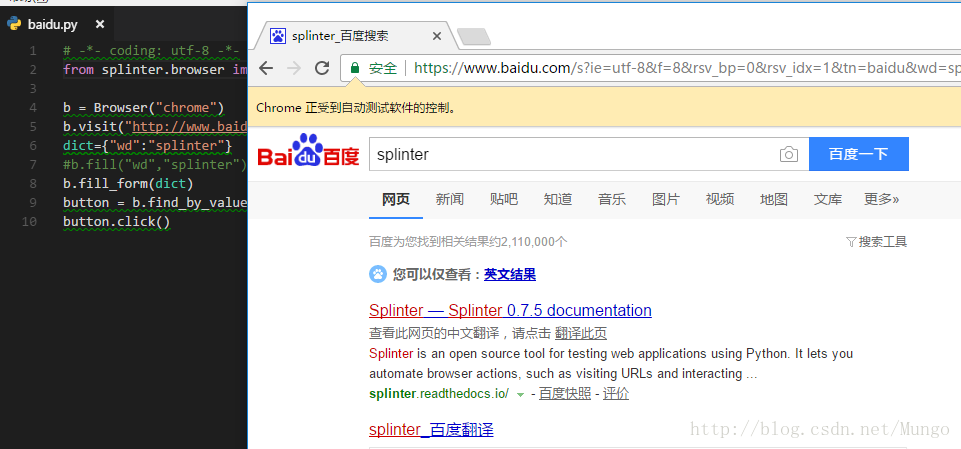
当然上面的实现只是一种方式,通过api列表就可以发现好多不同的实现方式。比如,查看splinter元素操作api发现一个fill(value)的方法,也可以对选中的元素赋值,而不需要使用Browser对象。
text = b.find_by_id("kw")
text.fill("splinter")这样同样可以实现
dict={"wd":"splinter"}
或
b.fill("wd","splinter")














 2577
2577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









