






1.1 初识分布式系统
1.1.1分布式系统的定义
”A distributed systemis one in which components located at networked computers communicate and coordinate their actions only by passing messages."
——Distributed Systems Concepts and Design (Third Edition)

我们来理解一下分布式系统的定义。首先分布式系统一定是由多个节点组成的系统,一般来说一个节点就是我们的一台计算机;然后这些节点不是孤立的,而是互相连通的;最后,这些连通的节点上部署了我们的组件,并且互相之间的操作会有协同。我们平时使用的互联网就是一个分布式系统。
1.1.2 分布式系统的意义
- 升级单机处理能力的性价比越来越低
- 单机处理能力存在瓶颈
- 处于稳定性和可用性的考虑
1.2 分布式系统的基础知识
1.2.1 组成计算机的5要素
输入设备、输出设备、运算器、控制器和存储器。存储器又分为外存和内存,在计算机断电时,内存中存储的数据会丢失,而外存仍然能够保持存储的数据。
1.2.2 线程与进程的执行模式
我们这里说的多线程,指的是单进程内的多线程。多线程开发的难度远远高于单线程。在多线程开发中,我们需要处理线程间的通信,需要对线程并发做控制,需要做好线程间的协调工作。
1.2.2.1 阿姆达尔定律

其中,P指的是程序中可并行部分的程序在单核上执行时间的占比,N表示处理器的个数(总核心数)。S(N)是指程序在N个处理器(总核心数)相对在单个处理器(单核)中的速度提升比。
这个公式告诉我们,程序中可并行的代码的比例决定你增加处理器(总核心数)所能带来的速度提升上限,是否能到达到这个上限,还取决于很多其他因素。可见在多核时代,并发程序的开发或者说提升程序的并发性是很重要的。
1.2.2.2 互不通信的多线程模式
在多线程程序中,多个线程会在系统中并发执行。如果线程之间不需要处理共享的数据,也不需要进行动作协调,那么将会非常简单,就是多个独立的线程各自完成自己线程中的工作。
1.2.2.3 基于共享容器协同的多线程模式
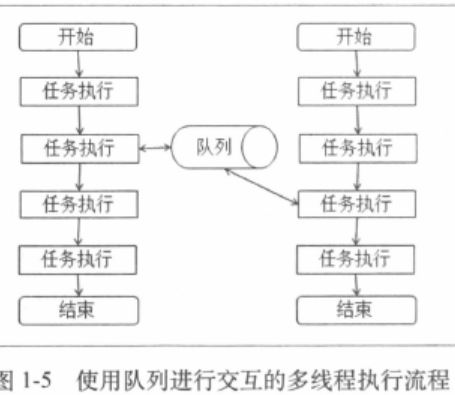
例如经典的生产者和消费者的例子,我们有一个队列用于生产和消费,那么这个队列就是多个线程会共享的一个容器或者是数据对象,多个线程会并发地访问这个队列,如图1-5所示。
对于这种在多线程环境下对同一份数据的访问,我们需要有所保护和控制以保证访问的正确性。对于存储数据的容器或者对象,有线程安全和线程不安全之分,而对于线程不安全的容器或对象,一般可以通过加锁或者通过Copy On Write的方式来控制并发访问。使用加锁方式时,如果数据在多线程中的读写比例很高,则一般会采用读写锁而非简单的互斥锁。对于线程安全的容器和对象,我们就可以在多线程环境下直接使用它们了。在这些线程安全的容器和对象中,有些是支持并发的,这种方式的效率会比简单的加互斥锁的实现更好,例如在Java领域,JDK中的java.util.concurrent包中有很多这样的容器类。不过需要在这里提一点的是,有时通过加锁把使用线程不安全容器的代码改为使用线程安全容器的代码是,会遇到笔者之前遇到过的一个陷阱,即在一个使用map存储信息后统计总数的例子中,map中的value整型使用线程不安全的HashMap代码是这样写的(以Java为例):
public class TestClass{
private HashMap<String, Integer> map = new HashMap<String, Integer>();
public synchronized void add(String key){
Integer value = map.get(key);
if(value == null){
map.put(key,1);
}
else{
map.put(key, value + 1);
}
}
}如果我们使用ConcurrentHashMap来替换HashMap,并且仅仅是去掉synchronized关键字,那么就出问题了。问题不太复杂,大家可以自己来思考答案(Java代码如下)。
public class TestClass{
private ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<String, Integer>();
public void add(String key){
Integer value = map.get(key);
if(value == null){
map.put(key,1);
}
else{
map.put(key, value + 1);
}
}
}补充学习:
1、synchronized,Java语言的关键字,可用来给对象和方法或者代码块加锁,当它锁定一个方法或者一个代码块的时候,同一时刻最多只有一个线程执行这个段代码。当两个并发线程访问同一个对象object中的这个加锁同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。然而,当一个线程访问object的一个加锁代码块时,另一个线程仍然可以访问该object中的非加锁代码块。
2、ConcurrentHashMap与HashMap的区别。
1.2.2.4 通过事件协同的多线程模式

如图1-6所示,右侧的线程,在执行到某个步骤时需要等待一个事件,而这个事件由左侧线程产生并通知。右侧线程一直阻塞直到事件通知到达后才继续自己的执行。我们也需要注意避免死锁的情况出现。一般来说,能够原子性地获取需要的多个锁,或者注意调整对多个锁的获取顺序,就会比较好地避免死锁。
下面来看一个死锁的例子。我们假设有两个锁A 和B,有两个线程T1和T2,T1和T2的某段代码都需要获取A和B两个锁,假设伪代码如下:
T1代码
……A.lock();B.lock();……T2代码B.lock();A.lock();……
那么,可能出现的死锁如图1-7所示。

这个时候,T1等不到B,而T2也等不到A。下面这种做法可以避免这样的死锁:
T1代码……A.lock();B.lock();……T2代码A.lock();B.lock();
……
和前面的代码相比,T2线程的获取锁的顺序发生了变化,现在和T1一样,都是先获取A,然后再获取B。这样就可以避免死锁。因为两个线程都是先获取A才会接着获取B,就不会出现之前一个线程持有A等待B,而另一个线程持有B等待A的情况了。
此外我们还有另一种实现方式来避免死锁:
T1代码……GetLocks(A,B);……T2代码……GetLocks(A,B);……
可以看到我们使用了一个GetLocks函数,一次性获取两个锁。
1.2.2.5多进程模式
我们在前面看到的是单进程中的线程模型,下面我们将要关注的是进程间的关系,而不讨论进程内部是单线程还是多线程。
线程是属于进程的,一个进程内的多个线程共享了进程的内存空间;而多个进程之间的内存空间是独立的,因此多个进程间通过内存共享、交换数据的方式与多个线程间的方式就有所不同。此外,进程间的通信、协调,以及通过一些事件通知或者等待一些互斥锁的释放方面,也会与多线程不一样。这些在不同的平台上所支持的方式不同。
多进程相对于单进程多线程的方式来说,资源控制会更容易实现,此外,多进程中的单个进程问题,不会造成整体不可用。这两点是区别于单进程多线程方式的两个特点。多进程间可以共享数据,但是其代价比多线程要大,会涉及序列化与反序列化的开销。
分布式系统是多机组成的系统,可以近似看做是把单机多进程变为了多机多进程。多机系统也带来了一个好处,即当单个机器出现问题时,如果处理得好,就不会影响整体的集群。
单进程和单进程多线程的程序在遇到机器故障、OS问题或者自身的进程问题时,会导致整个功能不可用。
对于多进程的系统,如果遇到机器故障或者OS问题,那么功能也会整体不可以,而如果是多进程中的某个进程问题,那么是有可能保持系统的部分功能正常的——当然这取决于多进程系统自身的实现方式。
1.2.3 网络通信基础知识
1.2.3.1 OSI与TCP/IP网络模型


1.2.3.2 网络IO实现方式
1、BIO方式
BIO即Blocking IO,采用阻塞的方式实现。也就是一个Socket套接字需要使用一个线程来进行处理。发生建立连接、读数据、写数据的操作时,都可能会阻塞。这个模式的好处是简单,这样做带来的主要问题是使得一个线程只处理一个Socket,如果是Server端,那么在支持并发连接时,就需要更多的线程来完成这个工作。

2、NIO方式
NIO即Nonblocking IO,基于事件驱动思想,采用的是Reactor模式(如图1-11所示)。相对于BIO,NIO的一个明显的好处是不需要为每个Socket套接字分配一个线程,而可以在一个线程中处理多个Socket套接字相关的工作。

to be continued……















 2165
2165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









