






目录
一:Linux系统文件与目录内容检索
一、文件和目录内容检索处理命令
shirt
short
good
food
wood
wooooooood
gooood
adcxyzxyzxyz
abcABC
best
besssst
ofion
ofson
ofison
AxyzxyzC
#test
#tast
#hoo
#boo
#joo
ferd
1、grep筛选
在文本中查找指定的字符串所在的行。
语法:
grep [选项] file
选项:
| 选项 | 作用 |
|---|---|
| -i | 忽略大小写。 |
| -v | 反转匹配,只显示不匹配的行。 |
| -c | 计数,只输出匹配行的数量。 |
| -n | 显示匹配行及其行号。 |
| -l(小写L) | 只输出包含匹配字符串的文件名。 |
| -L | 只输出不包含匹配字符串的文件名。 |
| -q(暂时不用) | 静默模式,不输出任何匹配信息。 |
| -E | 使用扩展正则表达式。 |
| -o | 只输出匹配到的部分,而不是整行内容。 |
| -A [NUM] | 打印匹配行和之后的[NUM]行。 |
| -B [NUM] | 打印匹配行和之前的[NUM]行。 |
| -C [NUM] 或 --context=[NUM] | 打印匹配行及其前后的[NUM]行。 |
| -P | 使用Perl正则表达式。 |
| -r 或 --recursive | 递归搜索目录中的文件。 |
| -R 或 --text | 将二进制文件当作文本文件处理。 |
| -s 或 --no-messages | 不显示错误信息。 |
案例:
1)、忽略大小写
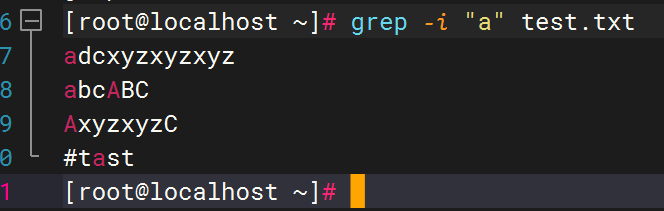
2)、根据关键字查找目录下文件内容并返回文件名称
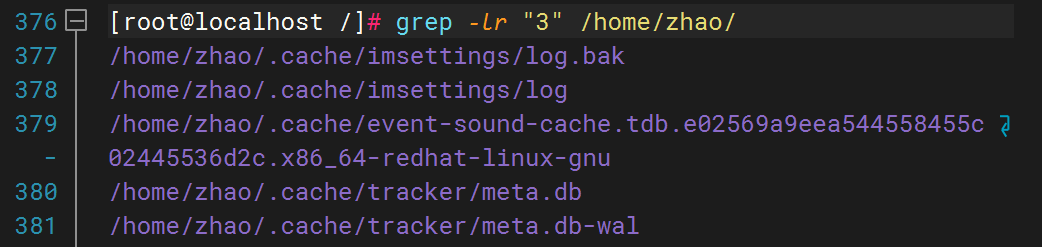
3)、根据通配符查找
^: 以什么什么开头
$:以什么什么结尾
.:表示单个字符
中间有两个字符的字符
过滤掉注释内容和空行内
grep 命令练习
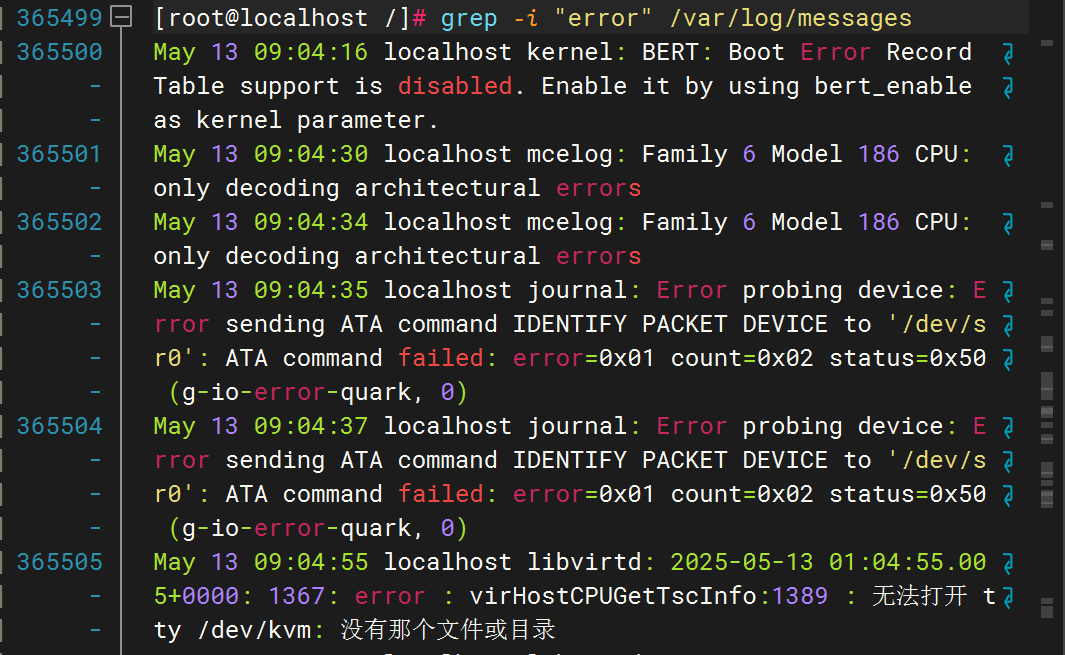
在 /var/log/messages 中查找所有包含 error 的行(忽略大小写)。
统计 /var/log/secure 中 Failed password 出现的次数

列出 /etc 目录下所有包含 root 的配置 文件名称。
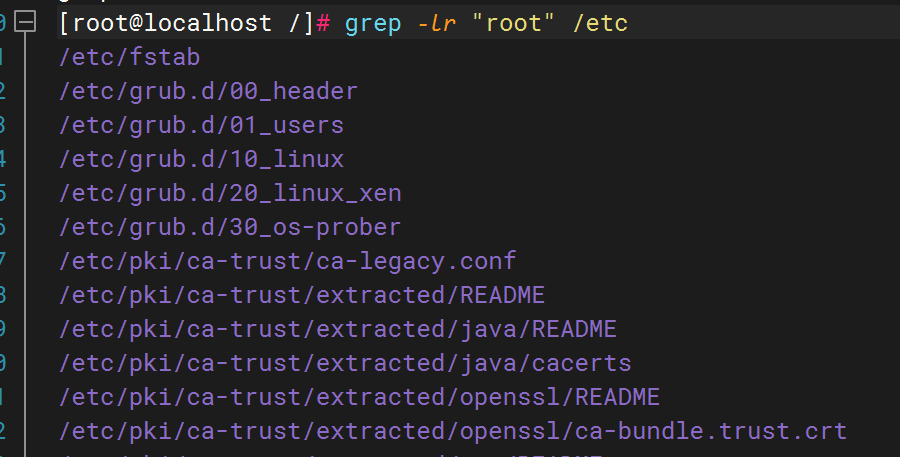
从 /etc/passwd 中提取所有以 /sbin/nologin 结尾的行。
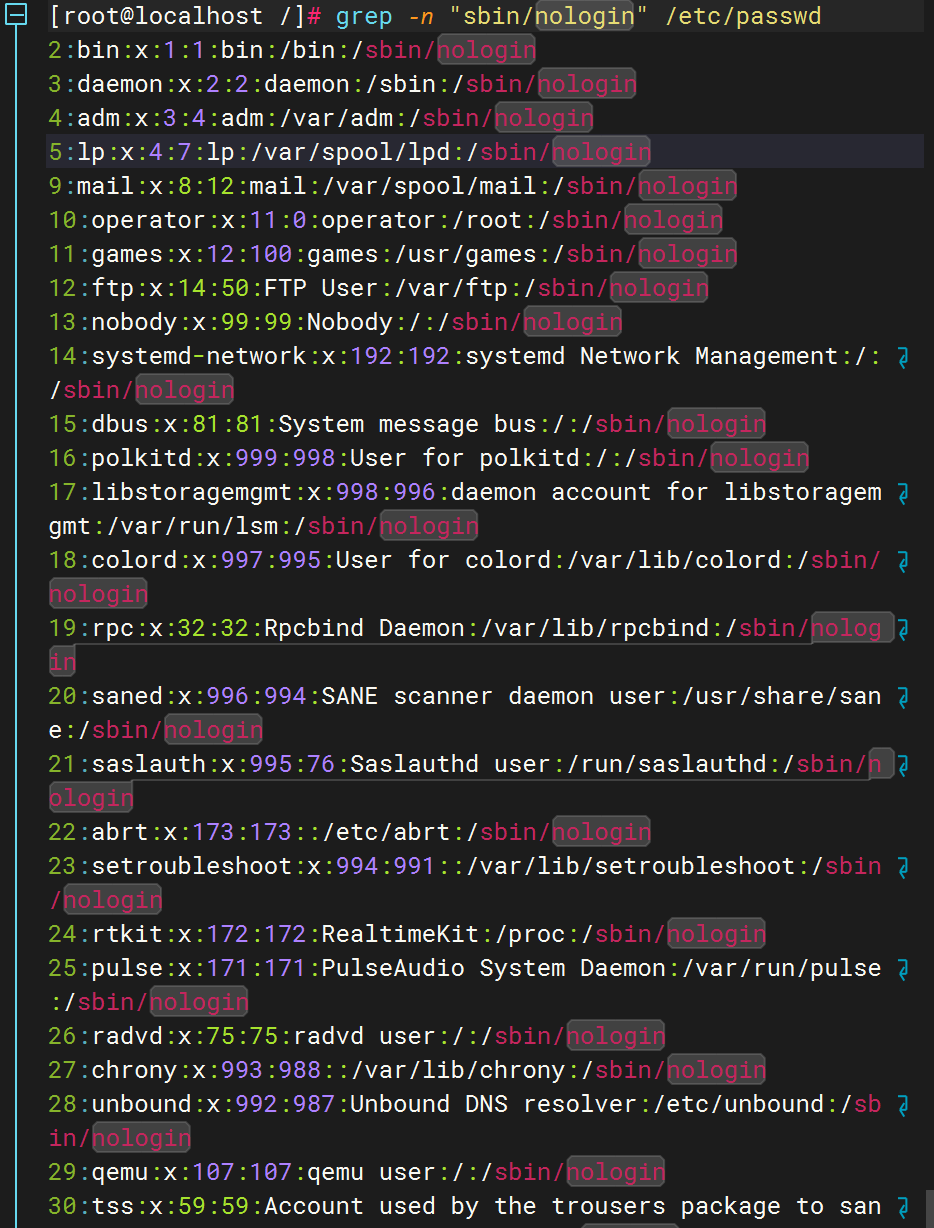
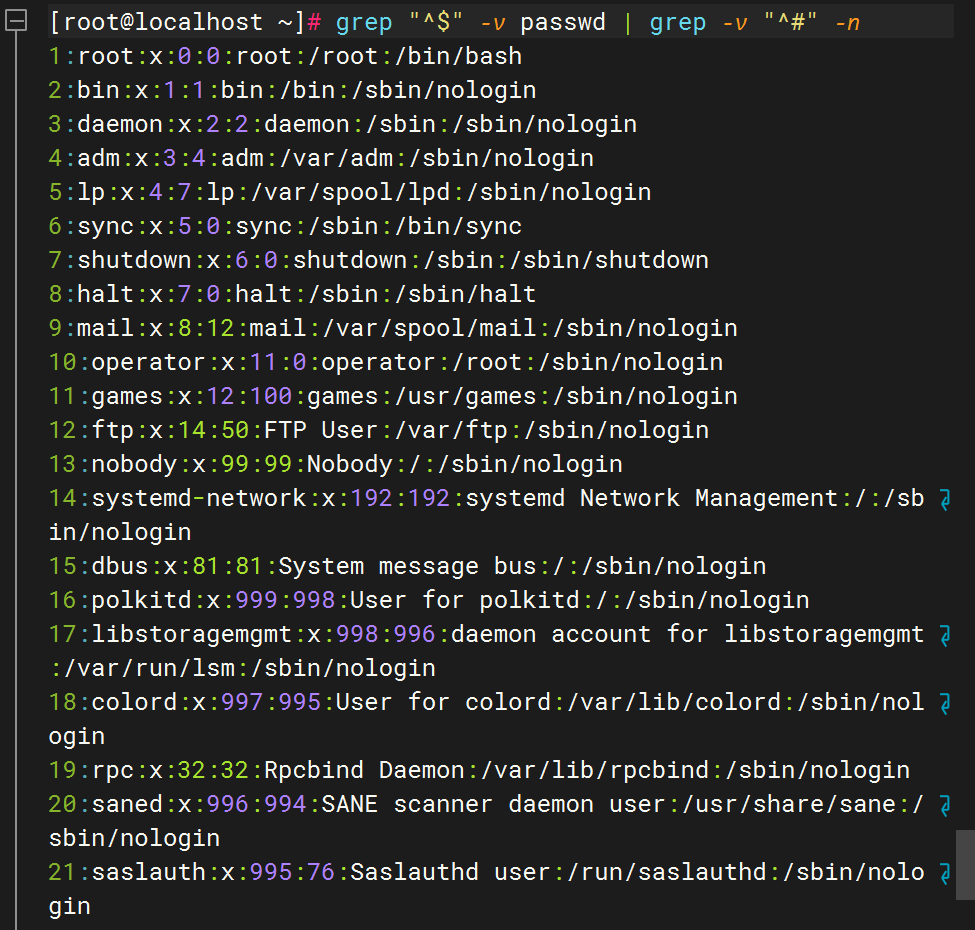
查找 /etc/ssh/sshd_config 中所有非注释行(排除以 # 开头的行)
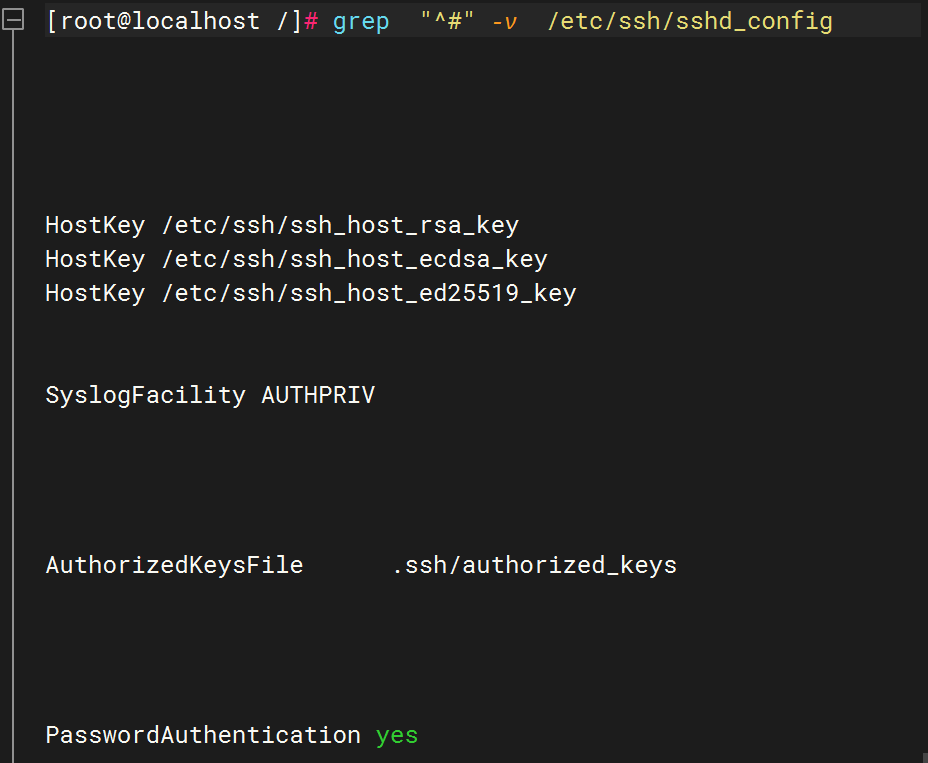
在 /var/log/boot.log 中显示匹配 fail 的行及其后 3 行内容(没有就更换目标)
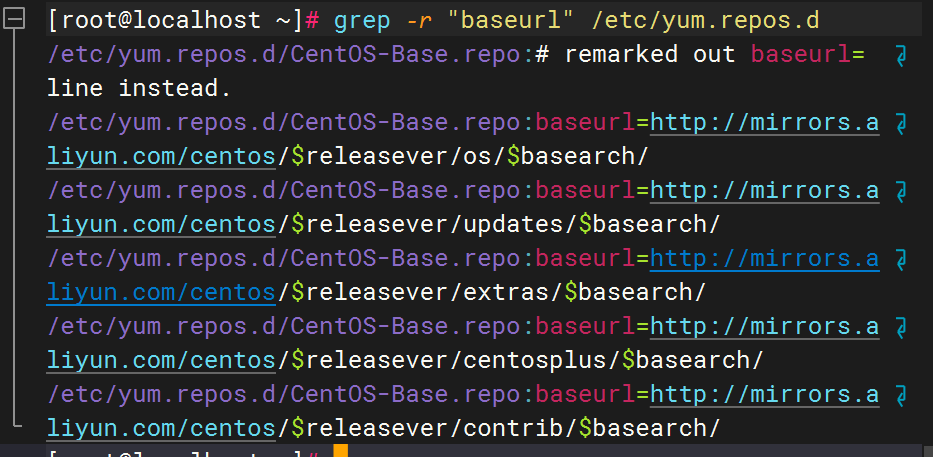
递归搜索 /etc/yum.repos.d/ 目录下所有包含 baseurl 的文件
查找 /etc/fstab 中所有空行并显示行号。

2、find查找
find - 递归地在层次目录中处理文件
选项:
| 选项 | 作用 |
|---|---|
| -name | 根据关键字查找,支持通配符* |
| -type | 根据文件类型查找 |
| -size | 根据文件大小查找 |
| -maxdepth | 指定查找时的路径深度 |
| -exec | 将find命令查找到的内容交给-exec后面的命令再次处理 |
| -user | 根据文件的属主进行查找 |
| -perm | 根据文件的权限进行查找 |
案例:
1)、根据关键字查找
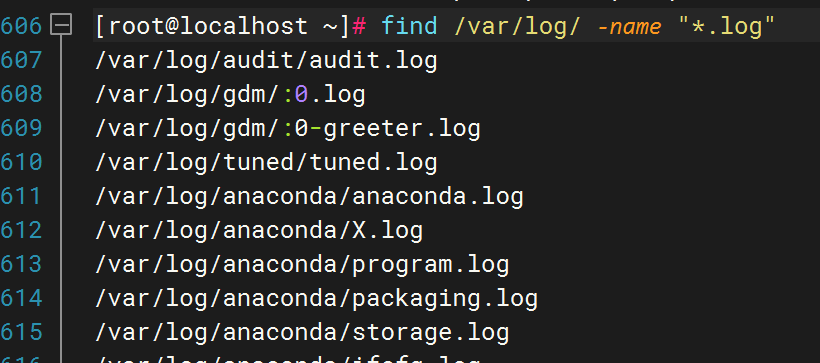
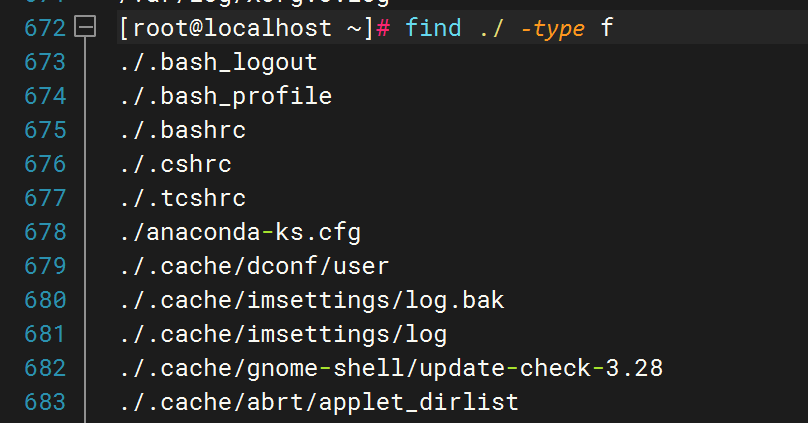
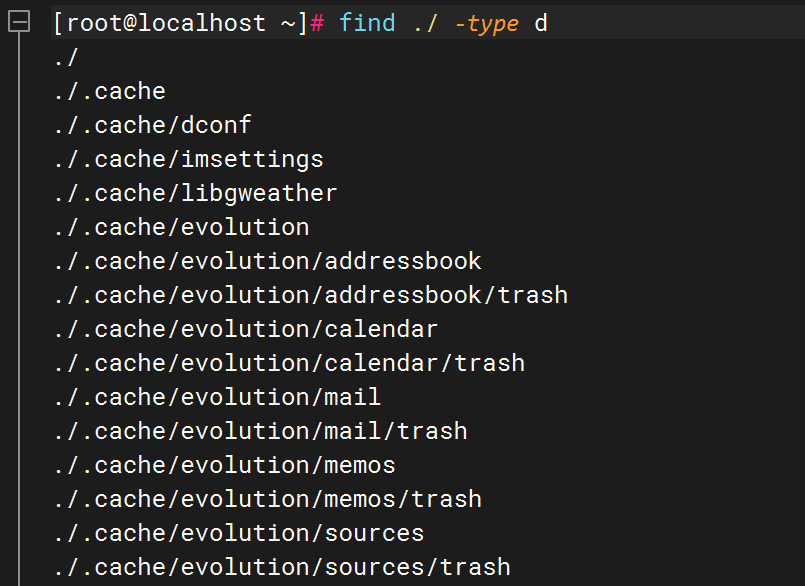
2)、根据文件类型查找
文件类型:
-
普通文件: f
-
-
目录:d
-
-
连接文件: l
-

-
字符设备文件: c
-

-
块设备文件: b
-

3)、根据文件大小查找
4)、多选项查找
查找文件类型为普通文件且文件后缀为.conf并且容量小于100M

5)、指定路径深度进行查找
[root@c2407 log]# find ./ -maxdepth 1 -name "*.log"
6)、使用-exec处理find查找到的结果
#查找普通文件容量小于100M并删除
[root@c2407 c2407-3]# find ./ -size -100M -type f -exec rm -rf {} \;
#查找普通文件容量大于100M并显示详细信息
[root@c2407 c2407-3]# find ./ -size +100M -type f -exec ls -lh {} \;
7)、find结合xargs命令进行结果的再处理
[root@c2407 c2407-3]# find /root/c2407-3/ -size +100M -type f | xargs rm -rf
find 命令练习
查找 /var/log/ 下所有大于 10MB 的日志文件
列出 /etc/ 下所有属主为 root 的 .conf 文件

将 /etc/nginx/ 目录下所有 .conf 文件输出到终端

查找 /home/ 下所有空文件。
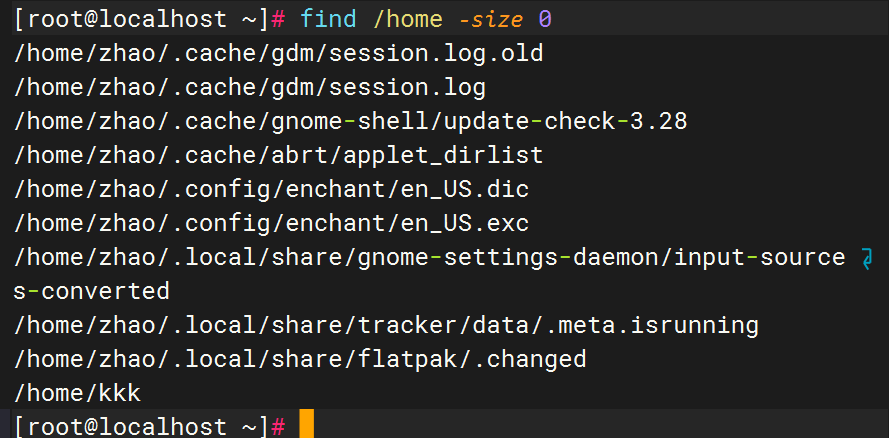
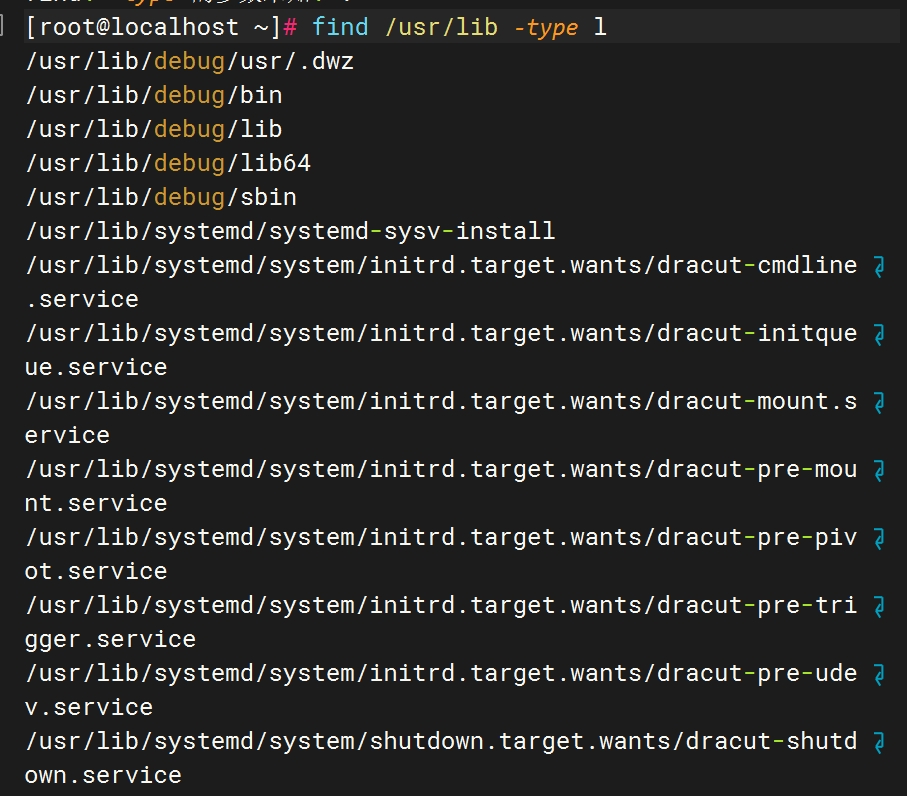
查找 /usr/lib/ 下所有符号链接文件。
统计 /var/log/ 目录下每个子目录中的文log件数量。

3、sort排序
以行对文件进行排序
| 选项 | 作用 |
|---|---|
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
| -n | 按照数值进行排序 |
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o<输出文件> | 将排序后的结果转存至指定文件 |
| -h | 友好显示 |
案例:
ls | sort -n
说明:
当使用sort -n对包含英文字母的文本进行排序时,它会尝试将英文字母按照其在字符编码中的顺序进行数值化解释并排序。
例如,假设有以下文本内容file.txt:
10
5
a
7
b
3
z
当执行sort -n file.txt时:
-
首先,对于纯数字10、5、3、7,它会按照数值大小正确排序为3、5、7、10。
-
对于字母a、b、z:
- 在 ASCII 编码中,字母有对应的数值编码。a的 ASCII 码值是 97,b是 98,z是 122(这里只是简单举例其数值编码情况,实际排序时会按照这种类似的数值化处理方式)。
- 按照sort -n的处理方式,它会将这些字母当作数值来处理,所以在上述数字排序之后,字母会按照其对应的编码值进行排序,结果可能类似3、5、7、10、a、b、z(这只是简单示意,实际输出格式可能因系统等因素略有不同)。
但需要注意的是,这种按照数值化处理字母的方式可能并不是你真正期望的合理排序结果。如果想要更合适的按照字母顺序的排序,可以考虑使用其他合适的选项,比如sort(默认按照字典序排序)。如果文本内容比较复杂,包含字母和数字的混合且有特定的排序需求,可能需要进一步对文本进行预处理或者采用更复杂的排序策略。
4、uniq去重
uniq 是 Unix 和类 Unix 系统中的命令,用于从排序的文本数据中去除重复行,仅保留唯一的行。它通常与 sort 命令结合使用,因为 uniq 只能删除相邻的重复行。
语法:
uniq [options] [input_file [output_file]]
选项:
| 选项 | 作用 |
|---|---|
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
| -i | 忽略大小写 |
案例:
-
删除输入文件中的重复行:
sort input.txt | uniq
-
仅显示重复的行:
sort input.txt | uniq -d
-
忽略大小写进行比较:
sort -i input.txt | uniq -i
sort & uniq 命令练习
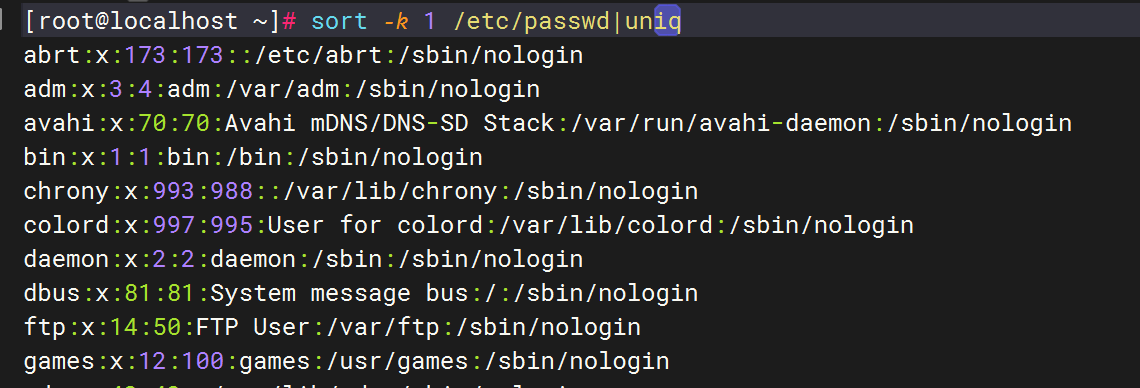
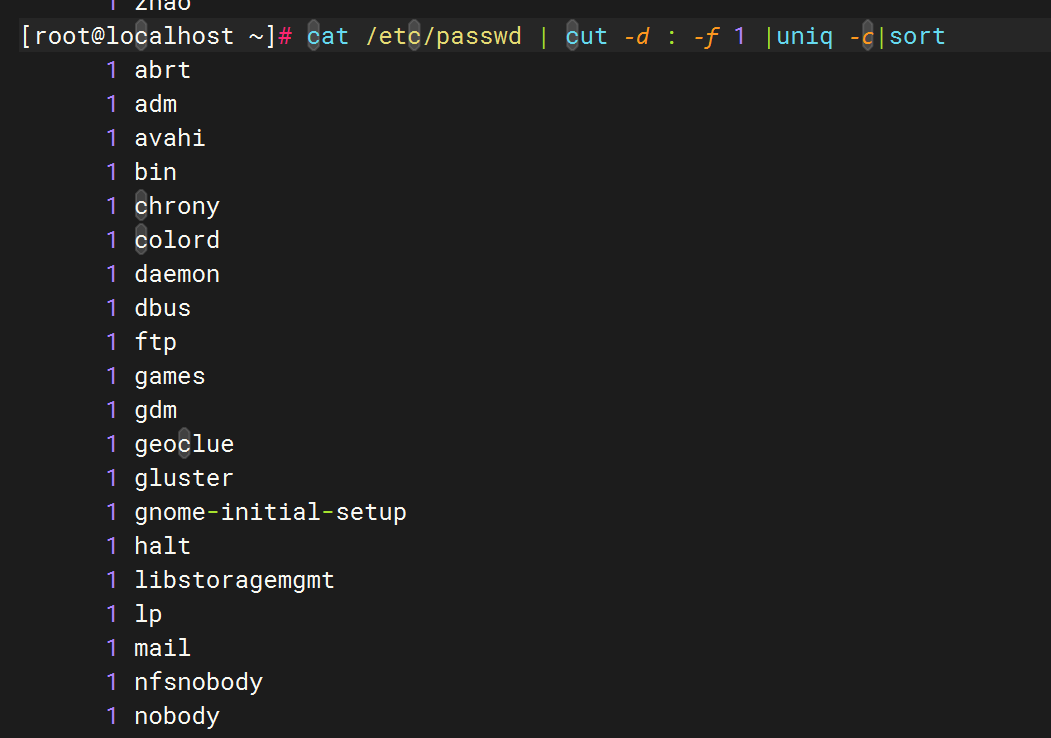
对 `/etc/passwd` 按用户名(第一列)排序并去重
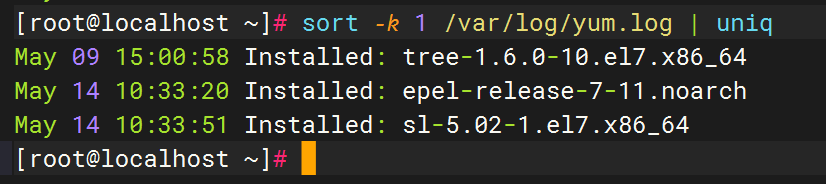
将 /var/log/yum.log 按日期(第一列)排序。
合并 /var/log/messages 和 /var/log/secure,去重后保存到 merged_logs.txt。

对 /etc/group 按组 ID(第三列)数值排序
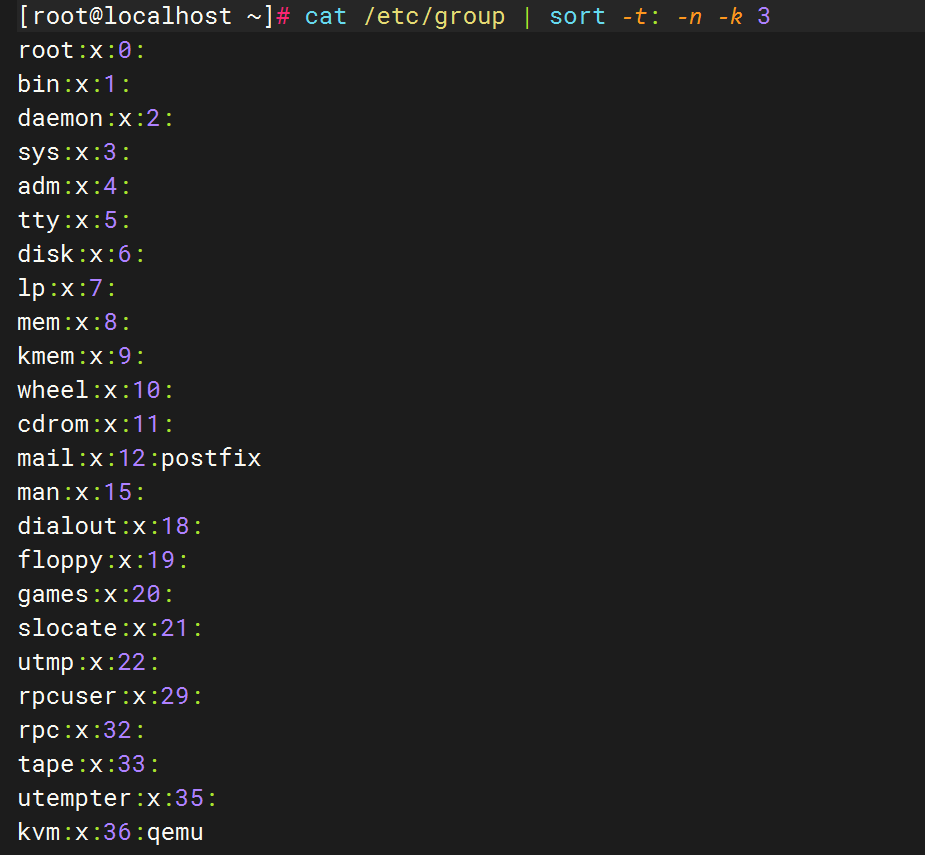
从 /var/log/maillog 中提取所有唯一的时间戳(格式 HH:MM:SS)
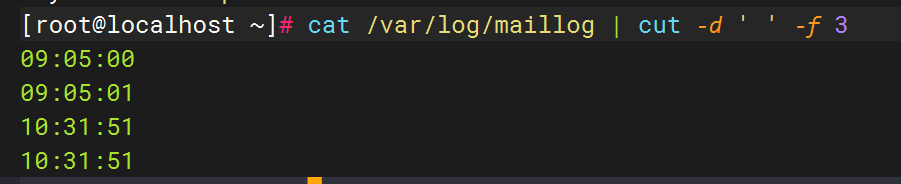
将 du -sh /var/log/* 的输出结果按文件大小降序排序
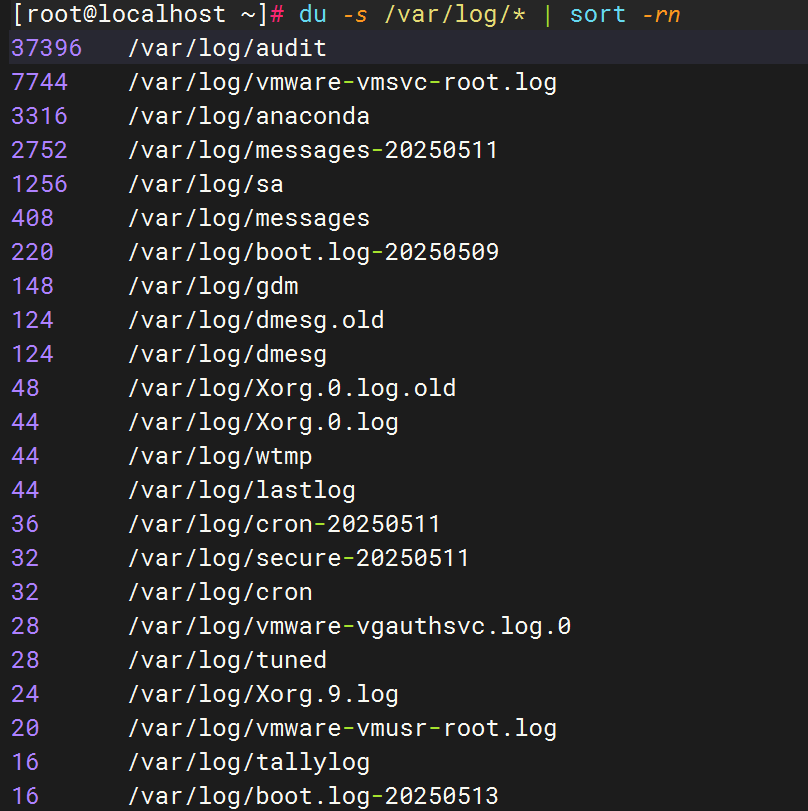
找出 /etc/passwd 中仅出现一次的用户名(第 1 列)
对 /var/log/yum.log 按日期排序,同日期时按时间排序

5、tr转换
tr 命令是 Unix 和类 Unix 系统中的一个用于字符转换或删除的实用程序。tr 命令通常用于处理文本数据,例如删除特定字符、替换字符、转换大小写等操作。
语法 :tr [options] set1 set2
选项:
| 选项 | 作用 |
|---|---|
| -c | 保留字符集1的字符,其他的字符用(包括换行符\n)字符集2替换 |
| -d | 删除所有属于字符集1(-d 后面的参数)的字符 |
| -s | 将重复出现的字符串压缩为一个字符串;用字符集2 替换 字符集1 |
| -t | 字符集2 替换 字符集1,不加选项同结果 |
案例:
将文本中的大写字母转换为小写字母:

删除文本中的空格:

将文本中的特定字符替换为另一个字符:

压缩重复字符:

去掉空白符:

6、cut切割
cut 是 Unix 和类 Unix 系统中的命令,用于根据指定的字符分隔符从输入中提取字段。cut 命令用于处理文本文件,通常与管道 (|) 和其他命令一起使用,以进一步处理和分析文本数据。
语法:cut [options] [field-spec]
选项:
| 选项 | 作用 |
|---|---|
| -f | 通过指定哪一个字段进行提取。cut命令使用“TAB”作为默认的字段分割符 |
| -d | “TAB”是默认的分隔符,使用此选项可更改为其他的分隔符 |
| -c | 以字符为单位进行分割 |
| - -complement | 用于排除所指定的字段 |
| - -output-delimiter | 更改输出内容的分隔符 |
| -s | 跳过空白字段 |
| -b, -B | 仅打印非空白的字段。 |
案例:
以下是使用 cut 命令的一些示例:(以文件passwd为基础操作)
-
提取指定范围内的字段:(连续)
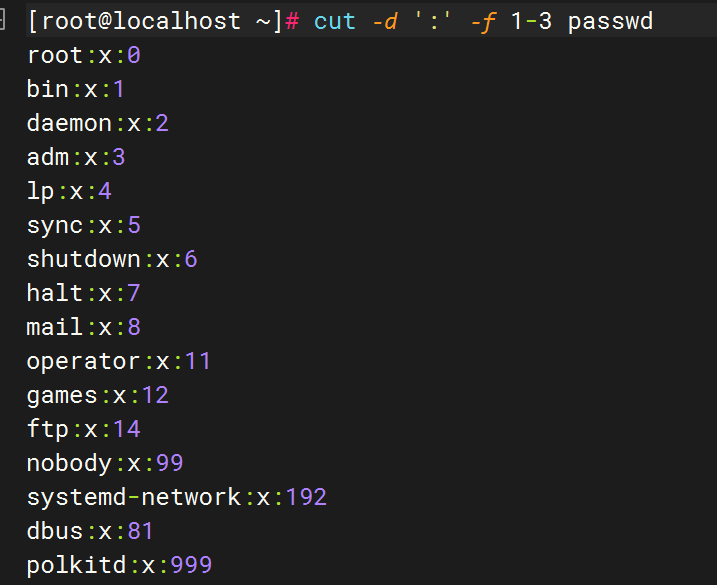
使用制表符作为分隔符提取字段:
cut -d $'\t' -f 1 file.txt
提取指定文件中的所有字段:
cut -d ':' -f * file.txt
仅提取非空白字段:
cut -b 3 file.txt
使用通配符提取多个字段:(可以不连续)
cut -d':' -f 1,2,3 file.txt
统计messages(系统)日志每个时间点产生日志的条目数量
cut -d' ' -f 4 messages | cut -d ':' -f 1 | uniq -c
统计web站点访问用户数
[root@c2407 nginx]# cat access.log | cut -d " " -f 1 | uniq -c
12 192.168.115.1
25 192.168.115.100
7、which命令
which 命令在 Unix 和类 Unix 系统中用于查找一个命令的完整路径。当您输入一个命令名称时,which 命令会告诉您该命令位于哪个文件系统中。which 命令通常用于确认命令是否存在于系统 PATH 中,或者用于在脚本中获取命令的确切路径。如果您想要查找的命令不存在于 PATH 中,which 命令将不会返回任何输出。
语法:
which [command]
选项:
| 选项 | 作用 |
|---|---|
| -a 或 --all | 打印所有匹配的命令路径,而不仅仅是第一个匹配的。 |
| -p 或 --print-path | 除了命令名称外,还打印出完整的路径。 |
| -v 或 --version | 打印 which 命令的版本信息。 |
案例:
8、whereis命令
whereis 命令在 Unix 和类 Unix 系统中用于查找二进制文件、源代码文件和手册页的位置。它搜索默认的文件系统路径来确定指定命令的相关文件。
语法:
whereis [-bms] [-u] [-f] [-h] [-L] [-M] [-S] [-version] [command]
选项:
| 选项 | 作用 |
|---|---|
| -b 或 --binary | 只查找二进制文件。 |
| -m 或 --manual | 只查找手册页。 |
| -s 或 --source | 只查找源代码文件。 |
| -u 或 --usage | 打印使用说明。 |
| -f 或 --follow | 跟随符号链接。 |
| -h 或 --help | 打印帮助信息。 |
| L 或 --logical | 搜索逻辑路径,不包含物理符号链接。 |
| -M 或 --physical | 搜索物理路径,不包含逻辑符号链接。 |
| -S 或 --size | 只查找指定大小的文件。 |
案例:
9、diff命令
语法:
diff [选项] 文件1 文件2
选项:
| 选项 | 作用 |
|---|---|
| -q 或 --quiet | 只输出文件差异的文件名,不显示详细差异。 |
| -c 或 --context | 以语境方式显示差异,默认显示3个字符的上下文。 |
| -u 或 --unified | 以统一的方式显示差异,这是默认模式,显示共同的祖先与当前文件之间的差异。 |
| -a 或 --text | 比较文本文件,忽略文件的格式差异。 |
| -b 或 --ignore-space-change | 忽略空白的差异(空格、制表符等)。 |
| -B 或 --ignore-space-at-eol | 忽略每行末尾的空白差异。 |
| -i 或 --ignore-case | 忽略大小写差异。 |
| -D 或 --horizontal-split | 以水平分割的方式显示差异。 |
| -E 或 --sideby-side | 以并排的方式显示差异。 |
| -l 或 --from-file | 只显示文件2相对于文件1的差异。 |
| -r 或 --recursive | 递归地比较目录。 |
| -N 或 --new-file | 当文件2是文件1不存在的文件时,只显示文件2的内容。 |
| -x 或 --exclude | 跳过指定模式的文件。 |
| -X 或 --exclude-from | 从指定的文件中读取排除模式。 |
| --from-file=FILE | 同 -l,指定比较的基准文件。 |
| --horizontalsplit | 同 -D,以水平分割的方式显示差异。 |
| --left-column | 只显示左侧列的差异。 |
| --no-dereference | 不解析符号链接。 |
| --old-file | 当文件1是文件2不存在的文件时,只显示文件1的内容。 |
| --recursive | 同 -r,递归地比较目录。 |
| --right-column | 只显示右侧列的差异。 |
| --speed-large-files | 用于大文件,减少内存使用。 |
案例:
[root@c2407 opt]# diff /etc/passwd ./passwd
44d43
< nginx:x:988:982:Nginx web server:/var/lib/nginx:/sbin/nologin
二、文件与目录归档压缩命令
1、tar
归档命令
语法:
tar [选项] [归档文件名] [-C] [解压路径]
选项:
| 选项 | 作用 |
|---|---|
| -z,--gzip | 用 gzip 对存档压缩 |
| -c, --create | 建立新的存档 |
| -v, --verbose | 详细显示处理的文件 |
| -f, --file | 指定存档文件路径及名称 |
| -j, --bzip2 | 通过 bzip2 过滤归档 |
| -x, --extract, --get | 从归档中解出文件 |
| -C | 指定解压后的存储路径 |
| tvf | 仅查看归档包中的文件内容 |
| --same-owner | 保留文件所有者(需root权限) |
| -J | 使用xz压缩 |
案例:
-
压缩
tar -czvf archive.tar.gz /path # 使用gzip压缩
tar -cjvf archive.tar.bz2 /path # 使用bzip2压缩
tar -cJvf archive.tar.xz /path # 使用xz压缩
-
解压
tar -xvf archive.tar -C /target/path # 解压到指定目录
2、zip/unzip
语法:
zip 压缩后的文件名 需要压缩的文件
解压缩命令:
unzip 压缩文件名
3、gzip / gunzip
默认压缩后源文件消失
语法:
gzip 需要压缩的文件
gzip -k filename # 保留原文件
解压缩命令:
默认解压后源文件消失
gunzip 压缩文件
gunzip -k 压缩文件
4、bzip2 / bunzip2
压缩后源文件消失,压缩率最高
语法:
bzip2 需要压缩的文件
解压缩命令:
解压后源文件消失
bunzip2 压缩文件
5、xz / unxz
-
压缩文件:
xz filename # 生成filename.xz -
解压文件:
unxz filename.xz
工具对比
| 工具/格式 | 压缩率 | 速度 | 典型扩展名 | 特点 |
|---|---|---|---|---|
| gzip | 中 | 快 | .gz | 通用,适合文本文件 |
| bzip2 | 高 | 慢 | .bz2 | 高压缩率,适合大文件 |
| xz | 极高 | 最慢 | .xz | 最高压缩率,资源消耗大 |
| zip | 中 | 中 | .zip | 跨平台(Windows兼容) |
| tar | 无 | 快 | .tar | 仅归档,需配合压缩工具使用 |
三、统计命令
1、wc
统计文件内容的行数、字符数、单词数
wc -l file.txt # 统计文件行数(常用日志分析)
wc -c file.txt # 统计字节数
wc -m file.txt # 统计字符数(与字节数区别在UTF-8环境)
wc -w file.txt # 统计单词数(以空格分隔)
wc -L file.txt # 统计最长行的长度
2、du
统计文件占用磁盘空间的容量
du -sh /path/to/dir # 统计目录总大小(-s汇总,-h人性化显示)
du -h --max-depth=1 /var # 显示/var下一级子目录大小
du -ah /path # 显示所有文件及子目录大小(含隐藏文件)
3、高级工具 ncdu
ncdu /path/to/dir # 交互式分析目录占用(按大小排序,支持删除)
ncdu -x / # 不跨越文件系统边界扫描


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









