










文章目录
本文主要部分是:8playbook案例——结合项目,带你快速了解playbook编写
1.playbook介绍
playbook是由一个或多个"play"组成的列表,play的主要功能在于将预定义的一组主机,装扮成事先通过ansible中的task定义好的角色。
个人理解:就是在task定义好执行流程,然后执行ansible的时候定义怎么去执行。
2.playbook执行流程
ansible命令调用yaml文件(playbook文件) =》 一个playbook包含多个play(这是个plays列表) ,每个play都有一个task相对于的操作 =》 然后调用moudle模块,应用在主机清单上(一个任务就是一个对 ansible 模块的调用,主机清单是要控制的主机或设备) =》通过ssh控制其他主机或设备
3.yaml优点
YAML是一个可读性高的用来表达资料序列的格式。它具备以下特性:
·YAML的可读性好
·YAML和脚本语言的交互性好
·YAML使用实现语言的数据类型
·YAML有一个一致的信息模型
·YAML易于实现
·YAML可以基于流来处理
·YAML表达能力强,扩展性好
4.playbook核心元素
Hosts 执行的远程主机列表(应用在哪些主机上)
Tasks 任务集
Variables 内置变量或自定义变量在playbook中调用
Templates模板 可替换模板文件中的变量并实现一些简单逻辑的文件
Handlers和notify结合使用,由特定条件触发的操作,满足条件方才执行,否则不执行
tags标签 指定某条任务执行,用于选择运行playbook中的部分代码。
ansible具有幂等性,因此会自动跳过没有变化的部分,
即便如此,有些代码为测试其确实没有发生变化的时间依然会非常地长。
此时,如果确信其没有变化,就可以通过tags跳过此些代码片断
ansible-playbook -t tagsname useradd.yml
5.playbook的运行方式
格式:ansible-playbook <filename.yml> … [options]
通过执行ansible-playbook -h 可以查看有哪些参数
#ansible-playbook常用选项:
--check or -C #只检测可能会发生的改变,但不真正执行操作
--list-hosts #列出运行任务的主机
--list-tags #列出playbook文件中定义所有的tags
--list-tasks #列出playbook文件中定义的所以任务集
--limit #主机列表 只针对主机列表中的某个主机或者某个组执行
-f #指定并发数,默认为5个
-t #指定tags运行,运行某一个或者多个tags。(前提playbook中有定义tags)
-v #显示过程 -vv -vvv更详细
6.playbook的语法
①playbook使用yaml语法格式,后缀可以是yaml,也可以是yml。
②在单一一个playbook文件中,可以连续三个连子号(—)区分多个play。还有选择性的连续三个点好(…)用来表示play的结尾,也可省略。
③次行开始正常写playbook的内容,一般都会写上描述该playbook的功能。
④使用#号注释代码。
⑤缩进必须统一,不能空格和tab混用。
⑥缩进的级别也必须是一致的,同样的缩进代表同样的级别,程序判别配置的级别是通过缩进结合换行实现的。
⑦YAML文件内容和Linux系统大小写判断方式保持一致,是区分大小写的,k/v的值均需大小写敏感。
⑧k/v的值可同行写也可以换行写。同行使用:分隔,v可以是个字符串,也可以是一个列表。
⑨一个完整的代码块功能需要最少元素包括 name: task。
7.playbook的hosts设置
在一个playbook开始时,最先定义的是要操作的主机和用户
- hosts: 192.168.1.31
remote_user: root
除了上面的定义外,还可以在某一个tasks中定义要执行该任务的远程用户
- name: run df -h
remote_user: test
shell: name=df -h
还可以定义使用sudo授权用户执行该任务
tasks:
- name: run df -h
sudo_user: test
sudo: yes
shell: name=df -h
8.playbook案例——结合项目
项目中playbook目录
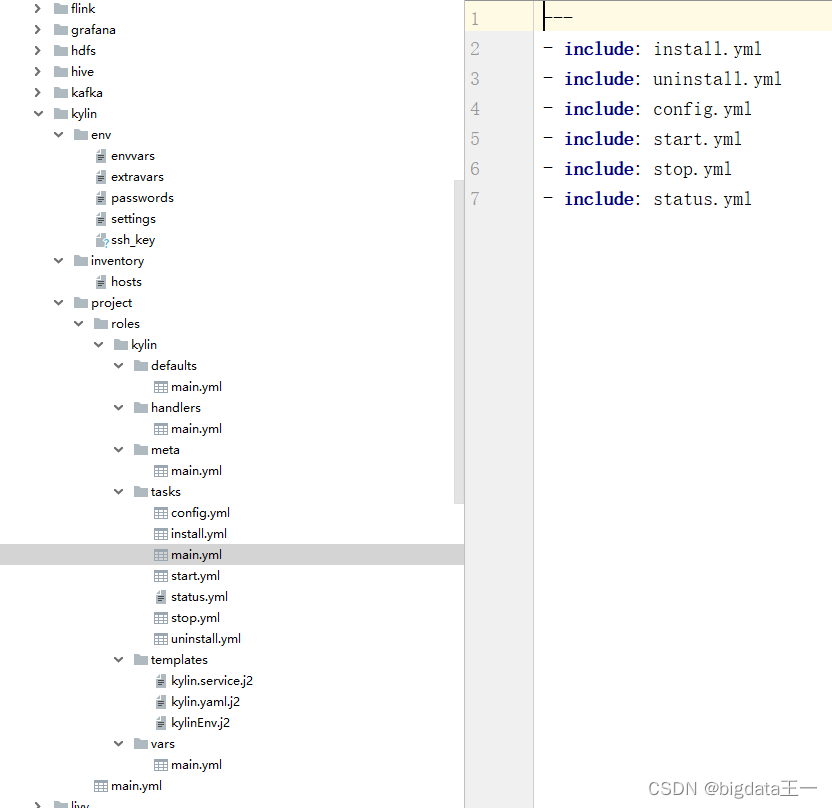
我觉得直接看一个项目的demo,更有助于快速理解playbook的编写。文中的{{}}是我们传入的变量,其他的我用#编写说明
以下内容name是自定义的步骤的名字,tags是该步骤的标签,可以通过 -t 和–skip-tags来决定执行哪个标签。执行install的tag,ansible-playbook -t install install.yml或者不执行install的tag,ansible-playbook --skip-tags install install.yml
主要看name和install之间的部分~~~
案例 install.yaml
#三个横线是yaml文件之间的分隔符
---
#创建文件夹
- name: create install directory
file: path={{ install_dir }} state=directory
tags: "install"
# copy的命令,复制文件,src是源路径,dest是目标路径
- name: copy package
copy: src={{ package_dir }}/{{ package_name }}-{{ package_version }}.{{ compress_suffix }} dest={{ install_dir }} mode=0755
tags: "install"
# stat判断文件夹状态(文件是否存在):true和false,命名为file_status,当然也可以是file_status_a,file_status_b......
- name: check hdfs installed
stat:
path: "{{ install_dir }}/{{ package_name }}-{{ package_version }}"
register: file_status
tags: "install"
# 当file_status为false,当文件夹不存在,进行解压,{{ install_dir }}/{{ package_name }}-{{ package_version }}.{{ compress_suffix }}在我们程序中是gtar类的压缩包
# mode是赋权
- name: unachieve package
unarchive: src={{ install_dir }}/{{ package_name }}-{{ package_version }}.{{ compress_suffix }} dest={{ install_dir }} copy=no mode=0755
when: file_status.stat.exists == False
tags: "install"
# 软连接,path路径 -> src路径
- name: Symlink install directory
file: src={{ install_dir }}/{{ package_name }}-{{ package_version }} path={{ install_dir }}/yarn state=link
tags: "install"
# Templates 模板文件的使用,具体目录可以参考我的截图
#该步骤主要是将playbook中的.j2文件复制到dest指定的目录下并且重新命名。
# 该步骤是将env.j2复制到{{ install_dir }}/yarn目录下并命名为env
- name: create hadoop env file
template: src=env.j2 dest={{ install_dir }}/yarn/env
tags: "install"
# 描述同上,该步骤是将nodemanager.service.j2文件复制到/usr/lib/systemd/system目录下并命名为nodemanager.service
- name: add to systmed
template: src=nodemanager.service.j2 dest=/usr/lib/systemd/system/nodemanager.service
when: "package_version.startswith('3.')"
tags: "install"
# 该步骤是使用shell命令
- name: append yarn-env.sh
shell: result=`cat {{ install_dir }}/yarn/etc/hadoop/yarn-env.sh | grep "nodemanager.yaml"`;if [[ -z "$result" ]];then echo -e export YARN_NODEMANAGER_OPTS='"' -javaagent:{{install_dir}}/monitor/jmx_prometheus_javaagent-0.16.1.jar={{ prometheus_port }}:{{ install_dir }}/monitor/hadoop/nodemanager.yaml '$YARN_NODEMANAGER_OPTS''"' >> {{ install_dir }}/yarn/etc/hadoop/yarn-env.sh; fi
tags: "install"
# 该步骤是使用shell命令,when是加入判断条件,当传入的变量package_version以2开头的时候执行
- name: append yarn-env.sh
shell: result=`cat {{ install_dir }}/yarn/etc/hadoop/yarn-env.sh | grep "nodemanager.yaml"`;if [[ -z "$result" ]];then echo -e YARN_NODEMANAGER_OPTS='"' -javaagent:{{install_dir}}/monitor/jmx_prometheus_javaagent-0.16.1.jar={{ prometheus_port }}:{{ install_dir }}/monitor/hadoop/nodemanager.yaml '$YARN_NODEMANAGER_OPTS''"' >> {{ install_dir }}/yarn/etc/hadoop/yarn-env.sh; fi
when: "package_version.startswith('2.')"
tags: "install"
案例 config.yaml
# 以三个横线开头分割yaml
---
# copy命令,src目录下的文件复制并覆盖到dest目录下文件。
# with_items迭代。遍历configs参数下的所有内容
- name: update config
copy: src={{ tmp_config_dir }}/{{ item }} dest={{ install_dir }}/yarn/etc/hadoop/{{ item }}
with_items:
- "{{ configs }}"
tags: "config"
# state=absent表示遗弃,在playbook中经常用作删除
- name: delete tmp config
file: path={{ tmp_config_dir }} state=absent
tags: "config"
注:迭代也可以这么写
with_items: #定义with_items
- httpd
- vsftpd
- nginx
嵌套迭代
---
- hosts: all
remote_user: root
tasks:
- name: Create New Group
group: name={{ item }} state=present
with_items:
- group1
- group2
- group3
- name: Create New User
user: name={{ item.name }} group={{ item.group }} state=present
with_items:
- { name: 'user1', group: 'group1' }
- { name: 'user2', group: 'group2' }
- { name: 'user3', group: 'group3' }
9.playbook的变量传入方式
①命令行指定变量
执行playbook时候通过参数-e传入变量,这样传入的变量在整个playbook中都可以被调用,属于全局变量
test.yaml文件内容:
- hosts: all
remote_user: root
tasks:
- name: test var
yum: name={{ 变量 }}
ansible-playbook -e “pkg=httpd” test.yml
②hosts文件中定义变量
在/etc/ansible/hosts文件中定义变量,可以针对每个主机定义不同的变量,也可以定义一个组的变量,然后直接在playbook中直接调用。注意,组中定义的变量没有单个主机中的优先级高。
vi /etc/ansible/hosts
[apache]
192.168.1.36 webdir=/opt/test #定义单个主机的变量
192.168.1.33
[apache:vars] #定义整个组的统一变量
webdir=/web/test
[nginx]
192.168.1.3[1:2]
[nginx:vars]
webdir=/opt/web
yaml文件引用变量
- hosts: all
remote_user: root
tasks:
- name: create webdir
file: name={{ webdir }} state=directory #引用变量
执行: ansible-playbook variables.yml
③playbook文件中定义变量
yaml文件内容如下。直接执行
---
- hosts: all
remote_user: root
vars: #定义变量
pkg: nginx #变量1
dir: /tmp/test1 #变量2
tasks:
- name: install pkg
yum: name={{ pkg }} state=installed #引用变量
- name: create new dir
file: name={{ dir }} state=directory #引用变量
如果执行时候又重新指定了变量的值,那么会已重新指定的为准。如执行的时候设置:ansible-playbook -e “dir=/tmp/test2” variables.yml
④调用setup模块获取变量
setup模块默认是获取主机信息的,有时候在playbook中需要用到,所以可以直接调用。常用的参数参考
yaml文件内容:
---
- hosts: all
remote_user: root
tasks:
- name: create file
file: name={{ ansible_fqdn }}.log state=touch #引用setup中的ansible_fqd
⑤独立的变量yaml文件中自定义
为了方便管理将所有的变量统一放在一个独立的变量YAML文件中,laybook文件直接引用文件调用变量即可。
YAML文件存放变量:
var1: vsftpd
var2: httpd
playbook:
---
- hosts: all
remote_user: root
vars_files: #引用变量文件
- ./var.yml #指定变量文件的path(这里可以是绝对路径,也可以是相对路径)
tasks:
- name: install package
yum: name={{ var1 }} #引用变量
- name: create file
file: name=/tmp/{{ var2 }}.log state=touch #引用变量
执行:ansible-playbook variables.yml















 3399
3399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









