






 本文对比了MyScale、PostgreSQL和OpenSearch在向量搜索、性能、成本和索引构建时间方面的优劣,MyScale凭借其在过滤向量搜索和成本效益上的优势脱颖而出。
本文对比了MyScale、PostgreSQL和OpenSearch在向量搜索、性能、成本和索引构建时间方面的优劣,MyScale凭借其在过滤向量搜索和成本效益上的优势脱颖而出。
MyScale 是一款提供完整 SQL 支持的集成向量数据库,而 PostgreSQL 和 OpenSearch 是两个最近都添加了向量相似性搜索功能的传统数据库。本文将对 MyScale 、PostgreSQL 和 OpenSearch 进行比较。
随着大语言模型(LLMs)的出现,人们对将对话界面集成到各种应用程序中的兴趣不断增加,例如搜索引擎、代码生成器和数据分析工具。向量相似性搜索是一项关键技术,在通过检索增强生成(RAG)提高 LLMs 性能方面起着至关重要的作用。
如今,市场上各种各样的向量数据库产品层出不穷;这些数据库大致可以分为以下几类:专门设计用于向量索引的专用向量数据库,集成向量数据库,以及扩展支持了向量搜索的通用数据库。
集成向量数据库与专用向量数据库相比,具有一些明显的优势,包括:
- 将向量和结构化数据存储在同一个数据库中,便于进行更复杂的筛选搜索,以及 SQL 和向量联合查询。
- 利用强大且广泛使用的查询语言(如 SQL)进行结构化和向量数据分析。
- 利用成熟的工具和与通用数据库集成。
- 减少了运维另一个专用数据库的额外成本和购买其许可的费用。
- MyScale:基于 ClickHouse 开发的集成向量数据库,通过完整的 SQL 支持将向量相似性搜索的能力与结构化数据检索能力结合于统一的数据库中。
- PostgreSQL:通过 pgvector 插件提供向量搜索支持
- OpenSearch:在 2.9.0 版本中整合了神经(向量)搜索
正如下文所述,我们全面的基准评估表明,MyScale 在过滤向量搜索的准确性、性能表现、成本效益和索引构建时间方面明显超过其他产品。重要的是,以各种过滤比率下提供良好的搜索准确性和 QPS 为基准,MyScale 是唯一通过测试的产品。
此外,MyScale 在性能方面也优于专用向量数据库,参考文末拓展阅读。如下图所示,完整的 SQL 支持和高性能的向量搜索集合,使MyScale 成为了管理 AI/LLM 相关数据(结构化数据与向量数据)非常有竞争力的选择。
基准设置
我们对MyScale、OpenSearch 和两个 Postgres 向量搜索插件进行了基准测试。设置详情如下:
| 每月成本(美元) | |||
我们使用了 500 万个 768 维的向量进行向量搜索和过滤向量搜索测试,需要说明的是这些向量是从 LAION 2B 图像数据集生成的。
注意:完整的代码、数据集和结果可以在我们的基准测试页面上(链接见拓展阅读2)找到。
我们为每个数据库选择了最小的 Pod 类型,来托管所有向量。
由于最新版本的 pgvector 和 pgvector.rs 尚未被 PostgreSQL 云服务广泛采用,我们在运行基准测试时选择了自行托管。不过为了进行比较,我们在上表中使用了 Amazon RDS for PostgreSQL 的定价。
注意:PostgresSQL 云服务(如 Supabase 和 TimeScaleDB)在类似硬件配置情况下的成本可能会更高。
而 OpenSearch 的 Pod 类型,我们选择了 r6g.2xlarge.search(64GB 内存),因为在 r6g.xlarge.search(32GB 内存)实例上构建向量索引时遇到了一些问题。总的来说,MyScale 仍然是最具成本效益的集成向量数据库。
基准结果
向量搜索
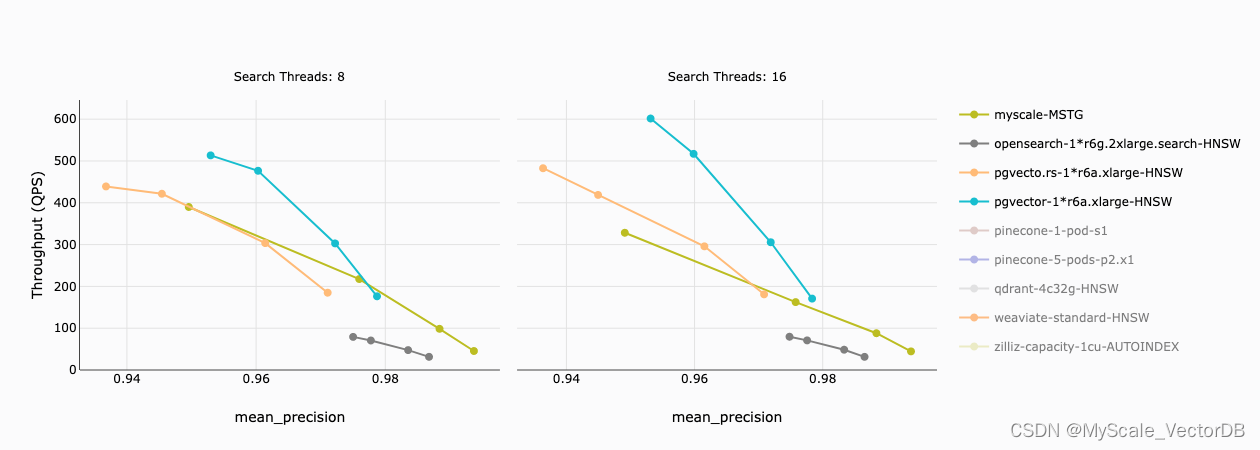
在下图中,x 轴表示准确性(precision),y 轴表示每个向量数据库的吞吐量(query per second, QPS)。我们发现:
- MyScale 和两个 Postgres 插件在 97% 准确性时具有相似的吞吐量
- pgvector 和 pgvecto.rs 在较低准确性下可以实现更高的吞吐量,但成本明显高于MyScale
- OpenSearch 在所有准确性下速度都落后于其他数据库
过滤向量搜索
在实际情况下,纯向量搜索远远不够。向量通常带有元数据,用户需要对这些元数据应用一个或多个过滤器。
下图描述了MyScale (以及其他集成向量数据库)在具有 1% 过滤比的数据集上的 QPS。1% 的过滤比意味着在应用了过滤条件后仍剩余 50K 个向量(1% x 5M 个向量)。
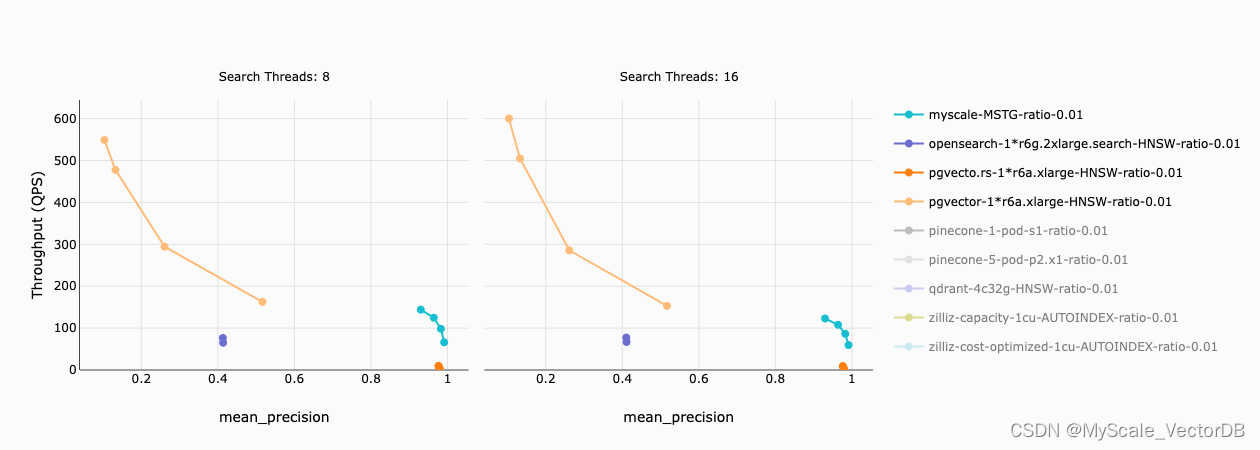
我们的研究结果如下:
- pgvector 和 OpenSearch 的准确性低于 50%,在实践中几乎无法使用
- pgvecto.rs 的吞吐量相对较低,低于 10 QPS
- 只有MyScale 保持合理的吞吐量(66-144 QPS)和准确性(93%-99%)。
后过滤
后过滤方法是指先进行向量搜索,然后删除不符合过滤条件的结果。不过使用这种方法有两个比较大的缺点:
pgvector 和 OpenSearch 的准确性低归因于它们使用的是后过滤。与之相对,MyScale 和 pgvector.rs 采用了另一种方法——前过滤。首先应用过滤器,然后将位图传递给向量索引来执行向量搜索。
在我们的基准测试中,pgvector.rs 使用的 HNSW 算法在过滤比低的时候性能较差。此外,PostgreSQL 是行存数据库,这对前过滤所需的大规模扫描操作并不友好,会进一步加剧性能下降。而MyScale 结合 ClickHouse 的快速列式 SQL 执行引擎而开发,再加上专有的 MSTG 向量索引算法克服了这个问题。
评估成本效益:纯向量搜索与过滤向量搜索
在选择数据库时,不仅要考虑原始性能,还要考虑投入产出比。对企业而言,成本效益成为了是否广泛应用向量搜索的关键标准,特别是在高准确性水平(如95%)下的成本效益。
纯向量搜索
为了清晰了解成本效益,我们通过测试每个数据库的每月成本与约 95% 准确性下实现的每秒查询数(QPS)的关系,得出了每个数据库的性能成本,从而提供了每个数据库每 100 QPS 的成本的指标。
如下所示的结果表明,MyScale 成本效益的优势是非常明显的,比最接近其的一个数据库高出 至少1.8 倍。
| 每月成本(美元)每 100 QPS | |
1% 过滤比下的过滤向量搜索
然而许多实际情况不仅要求进行纯向量搜索,还要对数据集进行过滤,来缩小结果范围。当我们评估 1% 过滤比的过滤向量搜索的成本效益时,情况发生了变化。值得注意的是,pgvector 和 OpenSearch 无法实现超过 50% 的准确性。这种低准确性使得数据库在大多数情况下是不可用的,在此分析中标记为 N/A。
| 每月成本(美元)每 100 QPS | |
总的来说,MyScale 在纯向量搜索中保持领先,在过滤向量搜索中,优势则更加明显。
索引构建时间
在向量数据库中插入向量后,用户必须在执行向量搜索之前创建一个向量索引。构建索引所需的时间对于快速返回搜索结果至关重要,下表中列出了四种向量数据库的构建时间:
上面的结果表明,MyScale 的索引构建时间明显更短,而 pgvector 由于缺乏并行构建支持,在构建 HNSW 向量索引时非常慢。快速构建索引在应用程序需要插入和更新大量向量的情况下(例如大规模在线聊天、文档编辑等)至关重要,另一方面也有利于减少索引构建和向量搜索之间的资源抢占。
结论
根据上面的分析结果,MyScale 始终保持优势地位,在过滤向量搜索和快速索引构建时间方面表现优异。在所有经过测试的产品中,MyScale 是唯一一个在各种过滤比下提供高搜索精度和 QPS 的集成向量数据库。
而 MyScale 优于其他产品的另外一个特点是其出色的成本效益。所以,对于希望充分利用集成向量数据库能力的企业来说,MyScale 既可以提供强大的性能表现,又可以降低使用成本,不失为一个优质选择


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









