






本文是 MyScale 向量数据库对比系列的第二篇。在上一篇文章中,我们对 MyScale 和 Pinecone 进行了全面比较,这次将深入对比 MyScale 和 Zilliz。
在上一篇文章中,我们对向量数据库的关键概念和 MyScale 进行了介绍,在此不会赘述太多。接下来我们先介绍一下 Zilliz。
01 什么是 Zilliz
Zilliz 是一款构建于开源 Milvus 项目之上的强大云原生向量数据库,专为高性能相似度搜索和机器学习应用而设计。区别于用户自托管 Milvus,Zilliz 提供全托管云服务,并提供免费版和按需付费两种模式,尤其适合需要弹性扩展向量存储,且希望免除基础设施管理负担的用户。
在本博客中,我们将对 MyScale 和 Zilliz 的云服务进行全方位比较,帮助您选择更适合自身需求的向量数据库。首先,我们来比较一下两者的托管服务。
02 托管方式对比
数据库的托管方式是选择解决方案时需要考虑的关键因素,因为它直接影响到数据库的性能、可扩展性和运维管理。强大的托管选项能够确保数据库轻松应对不同的负载、保持高可用性并简化维护工作。
MyScale 和 Zilliz 都提供了灵活的托管方式,包括开源版本、云托管服务和本地部署方案。云托管服务提供免费版和付费版,我们稍后将详细介绍。
对于本地部署,Docker 镜像是一种常见的选择,它可以简化部署流程并提供环境一致性。例如,启动 MyScale Docker 镜像的方式如下:
docker run --name MyScale --net=host myscale/MyScale:1.6对于 Zilliz,我们可以使用 Docker compose 如下:
curl <https://github.com/milvus-io/milvus/releases/download/v2.0.2/milvus-standalone-docker-compose.yml> -o docker-compose.yml
docker-compose up -d03 核心功能对比
在这一部分,我们将深入比较 MyScale 和 Zilliz 两款数据库的核心功能,包括查询语言、API 支持、元数据支持以及支持的数据类型。
查询语言和 API 支持
Zilliz 和 MyScale 都为 Python、Node.js 和 Go 等多种编程语言提供了客户端 SDK。此外,Zilliz 还支持 C++、.NET(部分支持)、RESTful API 和 Ruby。
然而,MyScale 最大的优势在于其对 SQL 的全面支持。您可以使用熟悉的 SQL 查询语言与 MyScale 交互,无论是操作向量数据、传统结构化数据,还是两者混合的数据,都能获得无缝衔接的体验。
元数据支持
Zilliz 支持在元数据过滤中使用正则表达式,并在最新版本中引入了基于 Milvus 2.4 的标量反向索引功能。
MyScale 则通过与 ClickHouse 深度集成来实现强大的元数据过滤能力。ClickHouse 是一款以高性能著称的列式数据库,其强大的索引和并行处理能力为 MyScale 的元数据过滤提供了坚实的基础。这使得 MyScale 能够在处理海量数据集时依然保持高效的过滤性能。此外,MyScale 还采用了预过滤策略,在进行向量搜索之前先对数据集进行初步筛选,进一步提升了搜索性能和准确性。
数据类型支持
MyScale 和 Zilliz 都支持存储和查询向量数据。Zilliz 的最新版本还增加了对稀疏向量和二进制向量的支持。然而,MyScale 凭借其对 SQL 的全面支持,能够处理所有 SQL 数据类型,包括向量数据和其他结构化数据。
例如,以下示例展示了 MyScale 中包含向量数据(`body_vector`)和其他数据类型(在此示例中为`UInt64`和`String`)的表结构:
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 1024
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;索引方式
MyScale 和 Zilliz 都支持多种向量索引算法,包括 HNSW、IVF(及其变体)以及 FLAT 等。Zilliz 提供了自动索引功能,可以根据数据特征和查询模式自动选择和调整索引策略,并利用动态缓存和动态量化等技术优化索引性能。
而 MyScale 除了支持 Zilliz 已有的索引算法,还引入了多尺度树图(MSTG)算法,这是一种结合了层次化树聚类和基于图搜索的创新算法。MSTG 在搜索速度和资源消耗方面都表现出色,超越了许多现有算法。
过滤向量搜索和全文搜索
MyScale 通过 MSTG 算法和位掩码索引技术优化了过滤向量搜索。位掩码技术可以高效地处理大规模数据集上的过滤条件,而 ClickHouse 的高性能索引和并行处理能力进一步增强了 MyScale 的过滤效率。此外,MyScale 还采用了预过滤策略,在进行向量搜索之前先对数据集进行筛选,确保只处理最相关的数据,从而显著提升了搜索性能和准确性。
Zilliz 同样利用位掩码索引技术来管理和应用大规模数据集上的过滤条件,从而高效地执行复杂的过滤操作。
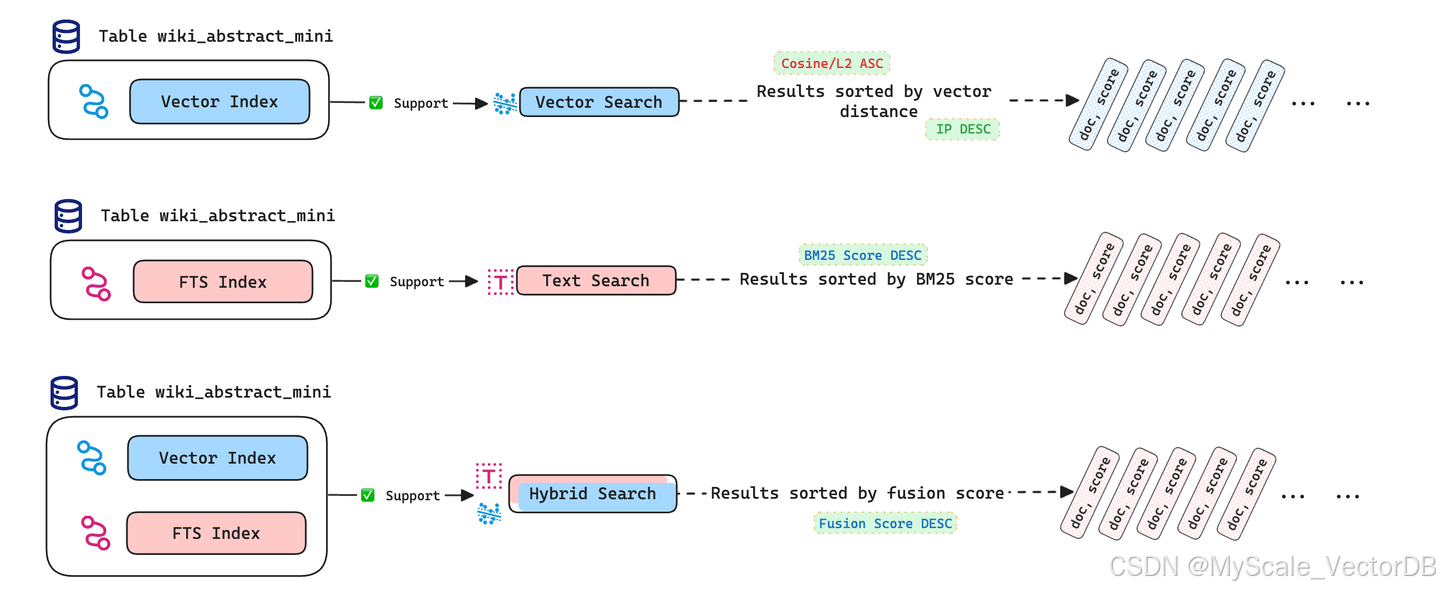
得益于对 Tantivy 搜索引擎的支持,MyScale 和 Zilliz 都具备强大的全文搜索能力,这在向量数据库中并不常见。两种数据库都支持混合搜索,即将向量搜索和全文搜索结合起来,提供更精准的检索结果。MyScale 通过 `HybridSearch()` 函数简化了混合搜索的操作,用户可以轻松地组合全文搜索和向量搜索的结果。
多向量搜索
MyScale 和 Zilliz 都支持多向量搜索,允许用户使用多个向量进行查询。此外,Zilliz 还提供了分组搜索功能,可以将存储在多个向量中的实体在搜索结果中进行分组,从而获得更综合的结果。
MyScale 则可以通过 SQL 中的 `GROUP BY` 子句实现类似的分组搜索功能,使用户能够高效地聚合和分组搜索结果,更方便地处理和分析大规模数据集。
地理搜索
地理搜索功能对于地图、GIS、物流配送等众多应用场景至关重要。MyScale 提供了一系列地理空间函数来支持地理搜索,例如计算地球上两点之间距离的函数:
greatCircleDistance(lon1Deg, lat1Deg, lon2Deg, lat2Deg)而 Zilliz 目前暂不支持地理搜索功能。
LLM API 集成
MyScale 和 Zilliz 都支持与 OpenAI、LLamaIndex、LangChain 等主流 LLM API 集成,并支持 Cohere 模型和 DSPy 进行自动提示工程。以下是一个将 LangChain 与 MyScale 集成的代码示例:
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs,embeddings)
output= docsearch.similarity_search("How LLMs operate?",3)04 定价对比
价格和性能是选择向量数据库时需要考虑的两个关键因素。在上一节中,我们详细比较了 MyScale 和 Zilliz 的核心功能,本节将重点关注两者的价格。
免费版
Zilliz 的免费版支持创建两个 Collection,每个 Collection 最多可存储 50 万个 768 维向量。
MyScale 的一个免费 Pod 则提供高达 500 万个 768 维向量的存储空间,相当于 Zilliz 免费版的 10 倍,或者说 5 个 Zilliz Collection 的总容量。这使得 MyScale 对于需要管理更大数据集但预算有限的用户更具吸引力。
付费版
免费版适用于实验和测试,但对于生产环境,我们通常需要付费版提供的更高性能和更大容量。
Zilliz 和 MyScale 都提供了两种付费托管模式:
注意:Zilliz 的物理节点称为 CU,而 MyScale 的物理节点称为 Pod。
- 容量优化:旨在最大化每个物理节点的存储容量。MyScale 的每个 Pod 提供 1000 万个向量的存储容量,而 Zilliz 的每个 CU 最多支持 500 万个向量。
- 性能优化:适用于对性能(低延迟、高 QPS)有较高要求的应用场景。MyScale 的每个 Pod 在性能优化模式下最多支持 500 万个向量,而 Zilliz 的每个 CU 最多支持 150 万个向量。
在了解这两种模式之前,我们还需要介绍下 Zilliz 的 Serverless 版本定价方式。
Zilliz 提供了 Serverless 部署选项,根据实际使用的计算资源(虚拟 CU)和存储容量收费。下表列出了 Zilliz 无服务器模式下,每月执行 100 万次读取和 100 万次写入操作,不同存储容量对应的费用:
| 向量容量 | 每小时费用(美元) | 每月费用(美元) |
|---|---|---|
| 100 万 | 0.09 | 64.8 |
| 500 万 | 0.21 | 151.2 |
| 1000 万 | 0.31 | 223.2 |
| 2000 万 | 0.47 | 338.4 |
| 4000 万 | 0.74 | 532.8 |
| 8000 万 | 1.15 | 828 |
注意: 以上价格仅供参考,实际费用可能因地区、用量和其他因素而有所差异。
Capacity-Optimized 版本
在 Capacity-Optimized 版本下,Zilliz 每个 CU 提供 500 万个向量的存储容量,而 MyScale 每个 Pod 提供 1000 万个向量。这意味着在相同存储容量下,MyScale 所需的物理节点数量更少,从而降低了成本。
下表比较了 Zilliz 和 MyScale 在容量优化模式下,不同存储容量对应的费用:
| 向量容量 | Zilliz (美元/小时) | 计算单元 (CUs) | MyScale (美元/小时) | Pods |
|---|---|---|---|---|
| 1000 万 | 0.276 | 2 | 0.094 | 1 |
| 2000 万 | 0.55 | 4 | 0.19 | 2 |
| 4000 万 | 1.1 | 8 | 0.38 | 4 |
| 8000 万 | 2.2 | 16 | 0.76 | 8 |
可以看出,在容量优化模式下,MyScale 的每小时成本始终低于 Zilliz。
Performance-Optimized 版本
在性能优化模式下,MyScale 每个 Pod 提供 500 万个向量的存储容量,而 Zilliz 每个 CU 仅提供 150 万个向量。尽管 MyScale 的单节点容量更高,但 Zilliz 在计费时存在一些不合理之处。
例如,存储 1000 万个向量理论上需要 6.67 个 CU (1000 / 150 = 6.67),但 Zilliz 实际收取 8 个 CU 的费用。同样地,存储 2000 万个向量理论上需要 13.33 个 CU,但 Zilliz 收取了更高的费用。
| 向量容量 | Zilliz (美元/小时) | CUs (实际) | CUs (理论) | MyScale (美元/小时) | Pods |
|---|---|---|---|---|---|
| 500 万 | 0.55 | 4 | 3.33 | 0.17 | 1 |
| 1000 万 | 1.1 | 8 | 6.67 | 0.33 | 2 |
| 2000 万 | 2.2 | 16 | 13.33 | 0.67 | 4 |
| 4000 万 | 3.84 | 28 | 26.67 | 1.33 | 8 |
| 8000 万 | 7.68 | 56 | 53.33 | 2.67 | 16 |
这种计费方式导致 Zilliz 在性能优化模式下的成本难以预测,并且可能高于 MyScale。
05 基准测试
为了公平比较 MyScale 和 Zilliz 的性能,我们选取了以下两种 Zilliz 配置进行基准测试:
- 2024-容量优化:1 个计算单元 (CU)
- 2024-性能优化:4 个计算单元 (CUs)
吞吐量
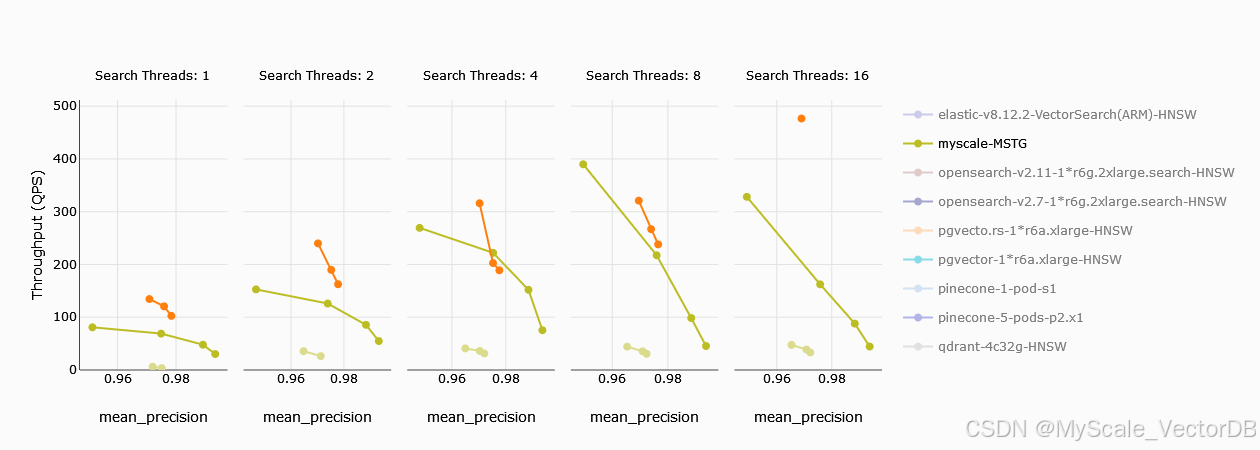
每秒查询数 (QPS) 是衡量向量数据库性能的重要指标。根据基准测试结果:
- MyScale (MSTG) 在单个计算单元的 Zilliz 节点上表现优异,展现出更高的 QPS。这意味着在相同硬件资源下,MyScale(绿色) 能够处理更多查询请求。
- 采用多个计算单元的 Zilliz (4 CUs) 在 QPS 方面优于 MyScale。这是因为 Zilliz(橙色)通过增加计算资源来提升性能。
平均查询延迟
除了吞吐量和精度,查询延迟也是评估向量数据库性能的重要指标。我们对比了 MyScale 和 Zilliz 在不同线程数下的平均查询延迟和 P95 延迟。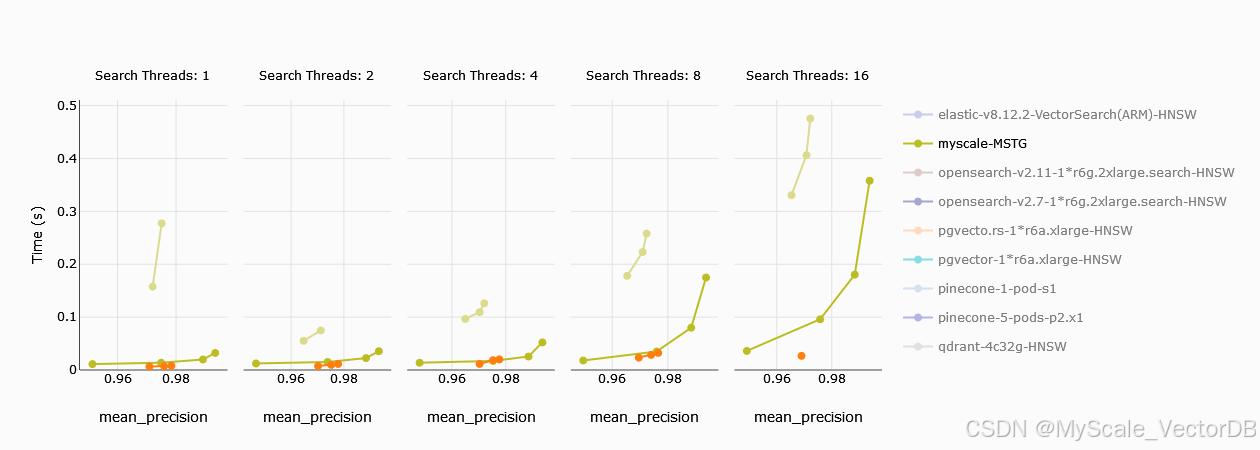
- MyScale 在单个计算单元的 Zilliz 节点上表现出色,平均查询延迟更低。这意味着在相同硬件资源下,MyScale 能够更快地返回查询结果。
- 随着线程数增加,MyScale 和 Zilliz 的平均查询延迟都呈上升趋势,但 MyScale 的延迟增幅更小,始终保持在较低水平。这表明 MyScale 在高并发场景下具有更好的性能稳定性。
- 当线程数达到 16 个时,采用 4 个 CU 的 Zilliz 在平均查询延迟方面略优于 MyScale。这是因为 Zilliz 通过增加计算资源来提升性能。
P95延迟
P95 延迟是指 95% 的查询请求都能在该时间内得到响应,用于衡量系统的稳定性和可靠性。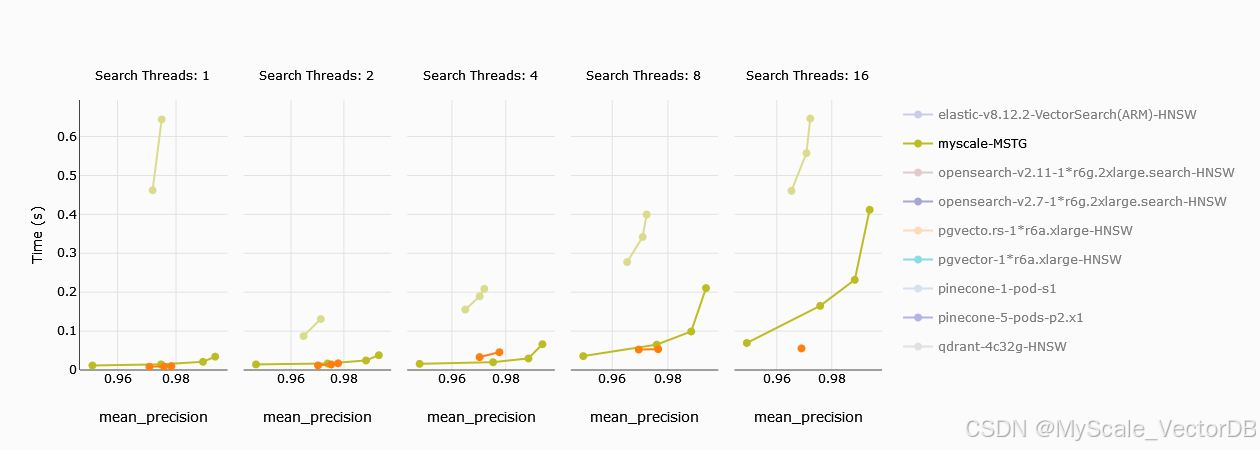
- 在 P95 延迟方面,MyScale 和 Zilliz 的表现趋势与平均查询延迟相似。
- 当线程数较低时,MyScale 的 P95 延迟优于 Zilliz,尤其是在单个计算单元的配置下。这表明 MyScale 在处理大部分查询请求时,能够提供更稳定和可预测的响应时间。
- 当线程数超过 8 个时,采用 4 个 CU 的 Zilliz 在 P95 延迟方面开始优于 MyScale。这再次说明了增加计算资源可以提升 Zilliz 的性能上限。
数据导入时间
数据导入时间是评估向量数据库效率的重要指标,它直接影响着系统的可用性和用户体验。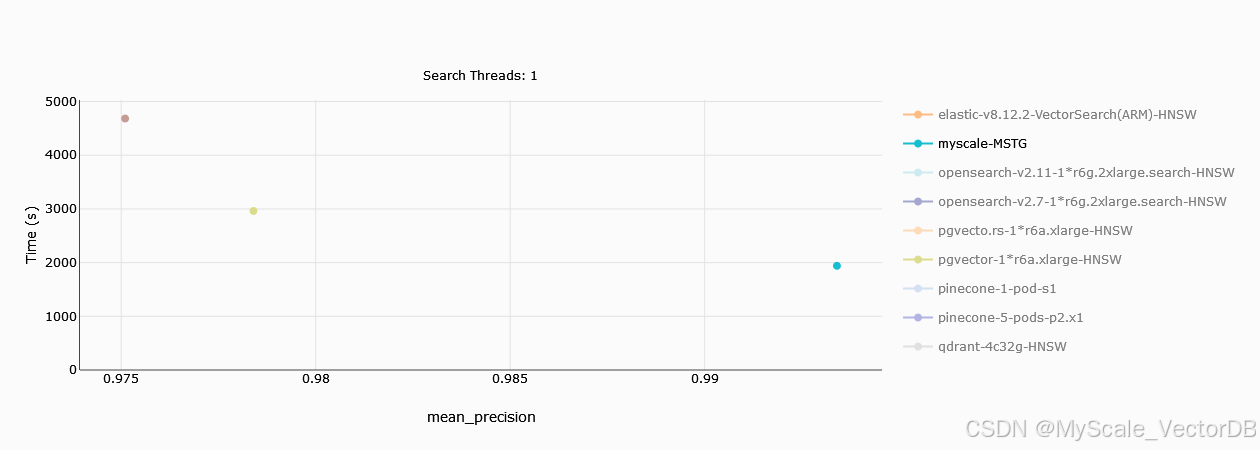
根据基准测试结果,MyScale 在数据导入速度方面明显优于 Zilliz。这意味着使用 MyScale 可以更快地将数据导入数据库,从而更快地开始查询和分析数据。
每月成本比较
成本是选择向量数据库时需要考虑的关键因素之一。我们对比了 MyScale 和 Zilliz 在不同配置下的月度成本。
- 对于单个 CU 的配置,Zilliz 的月度成本与 MyScale 相当,但 MyScale 仍然更具成本效益。这是因为 MyScale 在相同硬件资源下提供了更高的性能和更快的导入速度。
- 采用 4 个CU 的 Zilliz 比 MyScale 昂贵得多。虽然多 CU 的 Zilliz 可以提供更高的性能,但其成本也随之大幅增加。
结论:MyScale - 兼顾性能与成本效益的更优选择
Zilliz 和 MyScale 都是强大的向量数据库解决方案,但面向的用户群体和应用场景有所不同。Zilliz 功能丰富,但成本略高;而 MyScale 则在性能和成本效益之间取得了完美平衡,是更具吸引力的选择。
Zilliz 固然拥有多向量搜索、稀疏向量支持等前沿功能,但这些功能尚处于测试阶段,稳定性和可靠性仍待观察。此外,Zilliz 的定价较高,对于预算有限的用户来说可能难以承受。
MyScale 则在提供强大功能的同时,保持了极具竞争力的价格,在性价比方面表现出色。各项基准测试结果表明,MyScale 在高并发、大规模数据场景下,性能表现优异,而成本却远低于 Zilliz。
*MyScale Benchmark: MyScale Vector Database Benchmark

















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









