







概念:HyperLogLog是用来进行基数统计的算法。在redis里面,每个HyperLogLog只需要花费12Kb内存在标准误差0.81%的情况下就可以算出2的64次方不同元素的基数。但是HyperLogLog只会计算存入的基数并不会保存数据。
HyperLogLog提供两个指令:pfadd和pfcount,增加计数和统计计数。
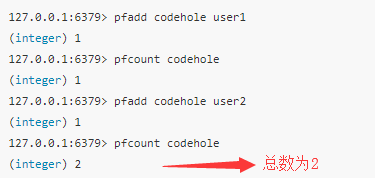
测试误差:

输出结果:

以十万数据进行测试,误差277个。误差率也不是很高,并且将上面脚本再跑一边,输出结果也是99723,说明具有去重。
先了解一个概念,什么是基数?
用来统计集合中不重复的个数。
HyperLogLog算法:HLL中实际存储的是一个长度为M大数组S,将待统计的数据集合划分成m组,每组根据算法记录成一个统计值存入S数组中。数组的大小M由算法方自己决定。在redis中,这个大小16834,数组越大基数误差越小。
实现过程:
- 通过hsah函数输入对应的比特串
- 比特串的低t位对应的数字用来找到数组S对应的位置i
- t+1位开始寻找第一个1出现的位置k,将k计入数组Si位置
- 基于数组S记录的所有数据统计值,计算整体基数值
先让我们来思考下:
- 为什么要记录第一个1的位置
- 为什么要将数组S分为m组(分桶数组)
回答1:
因为HyperLogLog基于的是概率算法。拿抛硬币来说,进行n次试验。每次分别记录第一次抛出正面的次数k,那么可以n次试验中最大抛出次数Kmax来预估每次试验抛的总数。
所以在HyperLogLog中记录第一次出现1的位置K,就可以根据这个得到集合的基数。
回答2:
HyperLogLog基本思想是根据比特串第一次出现1的位置的最大值来预估集合的基数。但是这种方式存在比较大的误差。由此提出了两个概念:分桶平均,偏差修正。
分桶平均:将统计数据划分为m个桶,每个桶分别统计各自最大位置k并获取基数n。然后对于基数n求平均得到整体的基数估计值。若是整体量过低,HyperLogLog会采用调和平均数进行优化。所以分桶数组是为了减少偶然性带来的误差,提高了准确性。
偏差修正:通过分桶平均,误差已经很低了,在这种情况下HLL的标准误差为1.1%。根据数学分析,这并不是一种无偏差估计。作者给出了一种分阶段修正。在一开始,数据并不很多,数组大部分空间都没有数据。这个阶段引入一个小范围修正方法。当数据量很大的时候引入大范围修正方法。















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









