







上一节我们学会了如何使用HyperLogLog,知道在允许出现一定误差的情况下可以解决大数据量的统计分析。但是这有一个缺点,如果我们想知道某一个值是不是已经在 HyperLogLog 结构里面了,它就无能为力了。HyperLogLog只提供了pfadd和pfcount 命令。那我们常用的快手,抖音是怎么做到基本不重复的消息推送呢?我们好好思考下这个问题…
解决方式一:也是最容易想到的,将查看记录存进数据库,每次刷时再去数据库判断是否查看。如果是小数据量,十三举双手赞成。但是用户量一旦上来,数据库的这种方式就不适用了。那么在这种允许稍微出现一点重复的场景下,不妨试一试神奇的布隆过滤器。
解决方式二:emmmm…咱们先介绍下布隆过滤器如何。
Redis4.0的时候提供了一个插件实现过滤去重的功能。这个插件就是布隆过滤器了。它能够准备过滤掉已经展示过的数据,没有展示的可能会过滤极小一部分,大部分都不会过滤。那么他要怎么实现这个任务并且不占用太大空间呢?我们引入另外一个数据结构 bitmap(位图)
位图(bitmap)
布隆过滤器其中重要的实现就是位图的实现,也就是位数组并且在这个数组中每一个位置只占有1个bit,而每个bit只有0和1两种状态。(特别注意:位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte数组。我们可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit 等将 byte数组看成「位数组」来处理)
对位图感兴趣的小伙伴可以搜索一下bitmap 用户签到
布隆过滤器与位图的完美结合(布隆重要参数计算):
我们假设一种有k个哈希函数,且每个哈希函数的输出范围都大于m,接着将输出值对k取余(%m),就会得到k个[0, m-1]的值,由于每个哈希函数之间相互独立,因此这k个数也相互独立,最后将这k个数对应到bitmap上并标记为1(涂黑)。
等判断时,将输入对象经过这k个哈希函数计算得到k个值,然后判断对应bitmap的k个位置是否都为1(是否标黑),如果有一个不为黑,那么这个输入对象则不在这个集合中,也就不是黑名单了。如果都是黑,那说明在集合中,但有可能会误,由于当输入对象过多,而集合也就是bitmap过小,则会出现大部分为黑的情况,那样就容易发生误判!因此使用布隆过滤器是需要容忍错误率的。
通过上面的描述,我们可以知道,如果输入量过大,而bitmap空间的大小又很小,那么误判率就会上升。那么bitmap空间大小怎么确定呢?
假设输入对象个数为n,bitmap大小(也就是布隆过滤器大小)为m,所容忍的误判率p和哈希函数的个数k。计算公式如下:(小数向上取整)
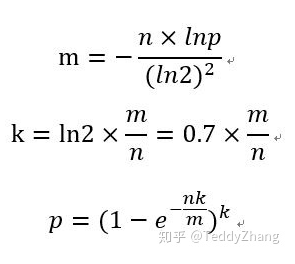
初步了解的布隆的算法构成,我们看看布隆过滤器实现:
1.每个布隆过滤器对应到 Redis 的数据结构里面就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
2.向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
3.向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,判断正确的概率就会很大,如果这个位数组比较拥挤,判断正确的概率就会降低。
那么在redis中是怎么使用的呢?我们一起来操作一下
使用docker安装插件:

布隆过滤器的使用:
bf.add添加元素,bf.exists查询元素是否存在。如需多个添加和查询,使用bf.madd,bf.mexists。

在默认的参数下,error_rate是0.01(错误率),initial_size是100(预计的元素数量)
提醒:一定要添加之前使用bf.reserve进行修改。
布隆过滤器的initial_size估计的过大,会浪费存储空间,估计的过小,就会影响准确率,用户在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出估计值很多。
…
布隆过滤器的error_rate越小,需要的存储空间就越大,对于不需要过于精确的场合,error_rate设置稍大一点也无伤大雅。比如在新闻去重上而言,误判率高一点只会让小部分文章不能让合适的人看到,文章的整体阅读量不会因为这点误判率就带来巨大的改变。
实际中很有可能出现的一种场景,当实际元素超出预计元素
在这种场景下,计算错误率,就需要引入一个公式:引入参数 t 表示实际元素和预计元素的倍数 t

当 t 增大时,错误率,f 也会跟着增大,分别选择错误率为 10%,1%,0.1% 的 k 值,咱们画出它的曲线进行直观观察。

从这个图中可以看出曲线还是比较陡峭的
错误率为 10% 时,倍数比为 2 时,错误率就会升至接近 40%,这个就比较危险了
错误率为 1% 时,倍数比为 2 时,错误率升至 15%,也挺可怕的
错误率为 0.1%,倍数比为 2 时,错误率升至 5%,也比较悬了。
所以啊,出现这种情况,测试背锅!!!!
最后的最后,我们梳理下。
这节的重点,没错,这节的精华就是测试背锅~














 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









