







文章目录
UV、IP 、PV 和 VV
首先知道这几个概念 UV 、IP、PV 和 VV(实习的时候也听到过。)
UV 是 Unique visitor,是指通过互联网访问、浏览这个网页的自然人,访问网站的一台电脑客户端为一个访客,24 小时内相同的客户端只被计算一次。一天内同个访客多次访问仅计算一个 UV。
IP 是 Internet Protocol,是指独立 IP,是指通过某站点的 IP 总数,以 用户的 IP 地址作为统计依据,24 小时内 相同的 IP 地址被计算一次。
UV 与 IP 的区别:我和我的家人用各自的账号在同一台电脑上登录新浪微博,则 IP +1,UV +2。
PV 是 Page View,页面浏览量 或 点击量,用户每一次对网站中的每个网页访问均被记录 1 个 PV,用户对同一页面的多次访问量会累计,用以衡量网站用户访问的网页数量。
VV 是 Visit VIew,用以统计所有访客 1 天内访问网站的次数,当访客完成所有浏览并最终关掉该网站的所有页面时便完成了一次访问,同一个访客 1 天内可能有多次访问行为,访问次数会累计。
PV 与 VV 的区别:我今天 10 点钟打开了百度,访问了它的 3 个页面;11 点钟又打开了百度,访问了它的两个页面,则 PV+5,VV +2。
一、HyperLogLog
思考这个业务问题:如果开发维护一个大型的网站,老板需要网站 每个网页 每天的 UV 数据,现在要来开发这个统计模块,应该如何实现?
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。
但是 UV 不一样,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是 登陆用户 还是 未登陆用户 都需要一个唯一ID 来标识。
现在可以想到一个简单的方案,那就是 为每一个页面一个独立的 set 集合来存储所有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。
但是,如果页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,不太值得蛤😢 。其实如果老板需要的数据又不需要太精确,比如 105w 和 106w 这两个数字对于老板们来说并没有多大区别,这就是本节要引入的一个解决方案,Redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了。很适合用于通过减少内存消耗来统计不同的用户操作。
HyperLogLog 数据结构是 Redis 的高级数据结构,它非常有用,但是令人感到意外的是,使用过它的人非常少。
使用方法
HyperLogLog 提供了两个指令 pfadd 和 pfcount,根据字面意义很好理解,一个是增加计数,一个是获取计数。pfadd 用法和 set 集合的 sadd 是一样的,来一个用户 ID,就将用户 ID 塞进去就是。pfcount 和 scard 用法是一样的,直接获取计数值。

可以看到,简单试了一下,还蛮精确的,一个没多也一个没少。 接下来我们使用脚本,往里面灌更多的数据,看看它是否还可以继续精确下去,如果不能精确,差距有多大。
代码如下:
import org.junit.Test;
import redis.clients.jedis.Jedis;
public class JedisTest {
public static void main(String[] args) {
Jedis jedis = new Jedis();
for (int i = 0; i < 100000; i++) {
jedis.pfadd("codehole", "user" + i);
}
long total = jedis.pfcount("codehole");
System.out.printf("%d %d\n", 100000, total);
jedis.close();
}
}
跑了约半分钟,运行结果:

差了 275 个,按百分比是 0.275%,对于上面的 UV 统计需求来说,误差率也不算高。
然后我们把上面的脚本再跑一边,也就相当于将数据重复加入一边,查看输出,可以发现,pfcount 的结果没有任何改变,还是 99725 😏, 说明它确实具备去重功能。
HyperLogLog 除了上面的 pfadd 和 pfcount 之外,还提供了第三个指令 pfmerge,用于将多个 pf 计数值累加在一起形成一个新的 pf 值。
比如在网站中我们有两个内容差不多的页面,运营说需要这两个页面的数据进行合并。其中页面的 UV 访问量也需要合并,那这个时候 pfmerge 就可以派上用场了。
再来看个例子:
统计一个小时内不同的用户,key 为 USER:LOGIN:2020122309,表示 2020 年 12 月 23 日上午 9 点到 10 点之间发生用户登录的非重复用户数。
假设用户 A、B、C、D、E 和 F 在这时登录了系统:

如果用户 A-F 和另外一个用户 G 在上午10 点到 11 点之间登录系统:

现在,有两个键 USER:LOGIN:2020122309 和 USER:LOGIN:2020122310 ,如果想知道在 9 点到 11 点 两个小时的间隔之间有多少不同的用户登录到系统中,可以直接使用 pfcount 命令对两个键进行合并计数:
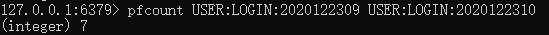
如果需要保留键值 而 避免一遍又一遍地计数,可以把键合并为一个键 USER:LOGIN:2020122309-10 ,然后直接对键进行 pfcount 操作:

再来看一个业务场景,要在滑动窗口中计算不同的用户,比如指定一个较小的粒度:分钟级,将用户行为保存在格式为 yyyyMMddHHmm 的键中,比如 USER;LOGIN:202012231056。当我们要统计最后 5 分钟的不同用户的操作时,只需要将 5 个键进行合并计算即可。由此看来,统计最近一小时我们需要 60 个键,统计最近一天需要 1440 个键,最近 7 天则需要 10080 个键。 我们拥有的键越多,合并它们时就需要耗费更多的时间进行计算。 因此,我们应该减少键的数量,不仅要保留具有 yyyyMMddHHmm 格式的键,还应保留小时、日和月的时间间隔,并使用 yyyyMM,yyyyMMdd,yyyyMMddHH,使用这些键,pfcount 操作可以花费更少的时间。
如果要计算用户最近一天的操作并且仅使用分钟键,你需要合并所有 1440 个键。但是,如果你在分钟键之外还使用小时键,则只需要 60 个分钟键和 24 个小时键,因此我们只需要 84 个键。
import org.apache.commons.lang3.time.DateUtils;
import java.text.SimpleDateFormat;
import java.util.*;
import java.util.stream.Collectors;
public class HLLUtils {
private static String TIME_FORMAT_MONTH_DAY = "MMdd";
private static String TIME_FORMAT_DAY_MINUTES = "MMddHHmm";
private static String TIME_FORMAT_DAY_HOURS = "MMddHH";
private static SimpleDateFormat FORMAT_MONTH_DAY = new SimpleDateFormat(TIME_FORMAT_MONTH_DAY);
private static SimpleDateFormat FORMAT_DAY_HOURS = new SimpleDateFormat(TIME_FORMAT_DAY_HOURS);
private static SimpleDateFormat FORMAT_DAY_MINUTES = new SimpleDateFormat(TIME_FORMAT_DAY_MINUTES);
/**
* 获取两个日期之间的键
*
* @param d1 日期1
* @param d2 日期2
* @return 键列表
*/
public static List<String> parse(Date d1, Date d2) {
List<String> list = new ArrayList<>();
if (d1.compareTo(d2) == 0) {
return list;
}
long delta = d2.getTime() - d1.getTime();
if (delta == 0) {
return list;
}
if (delta < DateUtils.MILLIS_PER_HOUR) { // 若时间差小于 1 小时
int minutesDiff = (int) (delta / DateUtils.MILLIS_PER_MINUTE);
Date date1Increment = d1;
while (d2.compareTo(date1Increment) > 0 && minutesDiff > 0) {
list.add(FORMAT_DAY_MINUTES.format(date1Increment));
date1Increment = DateUtils.addMinutes(date1Increment, 1);
}
} else if (delta < DateUtils.MILLIS_PER_DAY) { // 若时间差小于 1 天
Date dateLastPortionHour = DateUtils.truncate(d2, Calendar.HOUR_OF_DAY);
list.addAll(parse(dateLastPortionHour, d2));
long delta2 = dateLastPortionHour.getTime() - d1.getTime();
int hoursDiff = (int) (delta2 / DateUtils.MILLIS_PER_HOUR);
Date date1Increment = DateUtils.addHours(dateLastPortionHour, -1 * hoursDiff);
while (dateLastPortionHour.compareTo(date1Increment) > 0 && hoursDiff > 0) {
list.add(FORMAT_DAY_HOURS.format(date1Increment));
date1Increment = DateUtils.addHours(date1Increment, 1);
}
list.addAll(parse(d1, DateUtils.addHours(dateLastPortionHour, -1 * hoursDiff)));
} else {
Date dateLastPortionDay = DateUtils.truncate(d2, Calendar.DAY_OF_MONTH);
list.addAll(parse(dateLastPortionDay, d2));
long delta2 = dateLastPortionDay.getTime() - d1.getTime();
int daysDiff = (int) (delta2 / DateUtils.MILLIS_PER_DAY); // 若时间差小于 1 个月
Date date1Increment = DateUtils.addDays(dateLastPortionDay, -1 * daysDiff);
while (dateLastPortionDay.compareTo(date1Increment) > 0 && daysDiff > 0) {
list.add(FORMAT_MONTH_DAY.format(date1Increment));
date1Increment = DateUtils.addDays(date1Increment, 1);
}
list.addAll(parse(d1, DateUtils.addDays(dateLastPortionDay, -1 * daysDiff)));
}
return list;
}
/**
* 获取从 date 往前推 minutes 分钟的键列表
*
* @param date 特定日期
* @param minutes 分钟数
* @return 键列表
*/
public static List<String> getLastMinutes(Date date, int minutes) {
return parse(DateUtils.addMinutes(date, -1 * minutes), date);
}
/**
* 获取从 date 往前推 hours 个小时的键列表
*
* @param date 特定日期
* @param hours 小时数
* @return 键列表
*/
public static List<String> getLastHours(Date date, int hours) {
return parse(DateUtils.addHours(date, -1 * hours), date);
}
/**
* 获取从 date 开始往前推 days 天的键列表
*
* @param date 特定日期
* @param days 天数
* @return 键列表
*/
public static List<String> getLastDays(Date date, int days) {
return parse(DateUtils.addDays(date, -1 * days), date);
}
/**
* 为keys列表添加前缀
*
* @param keys 键列表
* @param prefix 前缀符号
* @return 添加了前缀的键列表
*/
public static List<String> addPrefix(List<String> keys, String prefix) {
return keys.stream().map(key -> prefix + key).collect(Collectors.toList());
}
}
有了这样生成 key 的方法,我们便可以很轻松地在实际场景中应用 Redis 的 HyperLoglog 进行数据统计,比如,要统计从此刻开始往前推一小时、一天、一周的 UV。
import redis.clients.jedis.Jedis;
import java.util.Date;
import java.util.List;
public class UVCounter {
private Jedis client = new Jedis();
private static final String PREFIX = "USER:LOGIN:";
public UVCounter() {
}
/**
* 获取周 UV
*
* @return UV数
*/
public long getWeeklyUV() {
List<String> suffixKeys = HLLUtils.getLastDays(new Date(), 7);
List<String> keys = HLLUtils.addPrefix(suffixKeys, PREFIX);
return client.pfcount(keys.toArray(new String[0]));
}
/**
* 获取日 UV
*
* @return UV 数
*/
public long getDailyUV() {
List<String> suffixKeys = HLLUtils.getLastHours(new Date(), 24);
List<String> keys = HLLUtils.addPrefix(suffixKeys, PREFIX);
return client.pfcount(keys.toArray(new String[0]));
}
/**
* 获取小时UV
*
* @return UV数
*/
public long getHourlyUV() {
List<String> suffixKeys = HLLUtils.getLastHours(new Date(), 1);
List<String> keys = HLLUtils.addPrefix(suffixKeys, PREFIX);
return client.pfcount(keys.toArray(new String[0]));
}
}
HyperLogLog 的实现原理可以看看这篇:《如何用 Redis HyperLogLog 统计日活月活》- 码农沉思录。
二、布隆过滤器
来看这样一个业务场景,在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。
布隆过滤器 (Bloom Filter) 就可以用来解决这种 去重 问题。它在起到去重的同时,在空间上还能节省 90% 以上,只是稍微有那么点不精确,也就是有一定的误判概率。
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置合理,它的精确度可以控制得相对足够精确,只会有小小的误判概率。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。 打个比方,当它说不认识你时,一定就是不认识;当它说见过你时,可能根本就没见过面🤭,不过因为你的脸跟它认识的人中某脸比较相似 (某些熟脸的系数组合),所以误判以前见过你。
套在上面的使用场景中,布隆过滤器能准确过滤掉那些没有看过的新内容,它也会过滤掉极小一部分 (误判),但是绝大多数新内容它都能准确识别。这样就可以完全保证推荐给用户的内容都是无重复的(就是说 它说不存在的,那一定是不存在的)。
1、Redis 中的布隆过滤器
Redis 官方提供的 布隆过滤器 到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
(1)使用
Docker 容器安装 Redis
下面我们来体验一下 Redis 4.0 的布隆过滤器,为了省去繁琐安装过程,我们直接用 Docker 。这就需要先用 Docker 容器来安装 Redis:
(1)拉取官方的最新版本的镜像:
docker pull redis
这个还蛮费时的,中途遇到报错:
 这是因为 虚拟机中系统时间不同步,需要进行时间同步。执行
这是因为 虚拟机中系统时间不同步,需要进行时间同步。执行 ntpdate time.windows.com。(要先使用 su - 切换到管理员身份哟~)

(2)查看本地镜像,使用以下命令来查看是否已安装了 Redis:
$ docker images

(3)运行 redis 容器
docker run --name myredis -d -p6379:6379 redis
其中,-p 6379:6379 表示 映射容器服务的 6379 端口到 宿主机的 6379 端口。外部可以直接通过宿主机ip:6379 访问到 Redis 的服务。
(4)查看容器的运行信息:
docker ps

可以看到,名为 “myredis”。
(5)使用 Redis 服务:
docker exec -it myredis /bin/bash

接下来用 Docker 安装布隆过滤器:
dbq 安了两天还是没成功 😭,我放弃咯。如果安装成功的话,就可以使用基本指令 bf.add 添加元素 和 bf.exists 查询元素是否存在,如果要一次查询多个元素是否存在,可以用 bf.mexists 指令。如果不设置任何参数,使用的就是默认参数的布隆过滤器,在第一次 add 的时候自动创建,如果在 add 前使用 bf.reserve 指令显式创建,就可以自定义参数。bf.reserve 有三个参数,分别是 key,error_rate 【错误率,默认是 0.01】和 initial_size 【预计放入的元素数量,默认是 100】。错误率越低,需要的空间越大。当实际数量大于预计放入的元素数量时,误判率会上升。所以需要提前设置一个较大的数值 ,避免超出导致误判率升高(当然太大又会浪费存储空间,所以要设置适当)。看看使用的简单例子吧:
127.0.0.1:6379>bf.add jia user1
(integer) 1
127.0.0.1:6379>bf.add jia user2
(integer) 1
127.0.0.1:6379>bf.add jia user3
(integer) 1
127.0.0.1:6379>bf.exists jia user1
(integer) 1
127.0.0.1:6379>bf.exists jia user2
(integer) 1
127.0.0.1:6379>bf.exists jia user3
(integer) 1
127.0.0.1:6379>bf.exists jia user4
(integer) 0
127.0.0.1:6379>bf.madd jia user4 user5 user6
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379>bf.mexists jia user4 user5 user6 user7
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0
可以看到,这个简单的例子里是没有误判的。
google 的 guava 包中也有对 Bloom Filter 的实现。
(2)原理
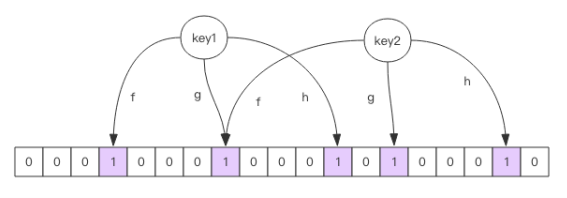
每个 布隆过滤器 对应到 Redis 的数据结构里面就是一个 大型的位数组 和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash ,算得一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看 位数组中 这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。正是由于这个 hash 冲突,所以会有误报率。 如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。不过具体的概率计算公式比较复杂,不建议细看。有个公式可以了解一下:

如果想让误报率最小,求导就可以了。
使用时不要让实际元素远大于初始化大小,当实际元素开始超出初始化大小时,应该对布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add 进 去 (这就要求我们在其它的存储器中记录所有的历史元素)。因为 error_rate 不会因为数量超出就急剧增加,这就给我们重建过滤器提供了较为宽松的时间。
现在已经有很多现成的网站支持 计算空间占用 的功能了,输入参数,就可以进行计算。
(3)Java 实现布隆过滤器
业务场景是有很多的垃圾网站,现在给网站,去判断是否在垃圾网站集里,换言之,对 URL 进行去重,比如爬虫,已经爬过的网页就可以不用爬了 。
import java.util.BitSet;
public class MyBloomFilter {
// 2<<25 表示 32 亿个比特位
private static final int DEFAULT_SIZE = 2 << 25 ;
private static final int[] seeds = new int [] {3,5,7,11,13,19,23,37};
// 存储在 BitSet 中
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap,int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0 ;
int len = value.length();
for (int i = 0 ; i < len; i++ ) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
public static void main(String[] args){
// 可疑网站
String value = "www.愚公要移山.com" ;
MyBloomFilter filter = new MyBloomFilter();
// 加入之前判断一下
System.out.println(filter.contains(value));
filter.add(value);
// 加入之后判断一下
System.out.println(filter.contains(value));
}
// 构造函数
public MyBloomFilter() {
for (int i = 0;i<seeds.length;i++) {
func[i]=new SimpleHash(DEFAULT_SIZE,seeds[i]);
}
}
// 添加网站
public void add(String value){
for (SimpleHash f : func) {
bits.set(f.hash(value), true );
}
}
// 判断可疑网站是否存在
public boolean contains(String value){
if (value == null ) {
return false ;
}
boolean ret = true ;
for (SimpleHash f : func) {
// 核心是 与操作
ret = ret && bits.get(f.hash(value));
if(!ret) return ret;
}
return ret;
}
}
这里说 2 << 25 表示 32 亿个比特位 只是意思意思😊 。
BitSet 类 ,就是 “位图”,实现了一个按需增长的位向量,每一个元素都有一个 boolean 值。比如 set(int bitIndex, boolean value) 方法,将索引处元素在 bitSet 中设定为 true 或者 false, 默认情况下,set 中所有位的初始值都是 false。 此后可以通过 get(int bitIndex) 方法检测结果。真正存放信息的是个 long 数组,long 类型的话是 64 位,也就是说借用了 long 的形式,实际是用二进制来按顺序表示一个正数是否存在。
这样的话,如果 URL 很多,使用布隆过滤器可以大幅降低去重存储消耗,只不过因为误判率,可能会错过少量页面。
邮箱系统的垃圾邮件过滤功能也普遍用到了布隆过滤器(应该有个垃圾邮件目录,判断为不存在其中的一定不存在,但是判断为存在其中的不一定存在),这样就会导致某些正常的邮件被放进了垃圾邮件目录中,不过概率很低。
三、限流
限流算法 在分布式领域 是一个经常被提起的话题,当系统的处理能力有限时,如何阻止计划外的请求继续对系统施压,这是一个需要重视的问题。除了控制流量,限流还有一个应用目的是用于控制用户行为,避免垃圾请求。比如在社区,用户的发帖、回复、点赞等行为都要严格受控,一般要严格限定 某行为 在规定时间内 允许的次数,超过了次数那就是非法行为。对非法行为,业务必须规定适当的惩处策略。
1、简单限流
现在,比如说,一分钟内 只允许 最多回复 5 个帖子,这个限流需求里存在一个滑动时间窗口,可以想到 zset 的数据结构,因为它有 score 值,可以通过 score 实现时间窗口,而 zset 的 value 只需要保证唯一性就好,如果使用 uuid 比较浪费空间,就用毫秒时间戳吧。
用 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个 key 被保存下来,同一个用户同一个行为用一个 zset 记录。为了节省内存,只需要保存时间窗口内的行为记录,而且如果用户是冷用户,滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间,通过统计滑动窗口内的行为数量 和 阈值 5 进行比较,就可以得出当前的行为是否被允许。
💎 代码:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.Response;
// 简单限流
/* 用 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个 key 被保存下来,
同一个用户同一个行为用一个 zset 记录。
为了节省内存,只需要保存时间窗口内的行为记录,
而且如果用户是冷用户,滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间,
通过统计滑动窗口内的行为数量 和 阈值 5 进行比较,就可以得出当前的行为是否被允许。*/
public class SimpleRateLimiter {
private Jedis jedis;
public SimpleRateLimiter(Jedis jedis) {
this.jedis = jedis;
}
/**
*
* @param userId 用户ID
* @param actionKey 行为
* @param period
* @param maxCount 阈值:5
* @return
*/
public boolean isActionAllowed(String userId, String actionKey, int period, int maxCount) {
String key = String.format("hist:%s:%s", userId, actionKey);
// 当前时间
long nowTs = System.currentTimeMillis();
Pipeline pipe = jedis.pipelined();
pipe.multi();
// 记录行为,value 和 score 都是使用毫秒时间戳
pipe.zadd(key, nowTs, "" + nowTs);
// 移除时间窗口之前的行为记录,这样剩下的都是时间窗口内的
pipe.zremrangeByScore(key, 0, nowTs - period * 1000);
// 获取窗口内的行为数量
Response<Long> count = pipe.zcard(key);
// 设置过期时间为时间窗口长度宽限 1s,避免冷用户持续占用内存
pipe.expire(key, period + 1);
// 批量执行
pipe.exec();
pipe.close();
// 比较数量是否超标
return count.get() <= maxCount;
}
public static void main(String[] args) {
Jedis jedis = new Jedis();
SimpleRateLimiter limiter = new SimpleRateLimiter(jedis);
for(int i=0; i<20 ;i++) {
System.out.println(limiter.isActionAllowed("jia", "reply", 60, 5));
}
}
}
运行结果:

可以看到,代码中用到了 jedis.pipelined() ,pipeline 管道,我们在操作大量数据时,Redis 的吞吐量性能可能较低,此时我们可以通过 pipeline 进行批量操作。这个功能在 Redis 的命令中并没有,但 jedis 是支持的,在实际应用中还是比较常用的。它提供了命令的批量提交,当我们有 批量查询 或者 写入操作 时,比如 单个命令的“往返时间”是1ms,那么 10 个命令就会消耗 10ms,如果我们使用 pipeline 批量操作后可以一次性提交 10 个命令,redis的响应时间将会大大减小。吞吐量也自然提高,可以控制网络开销。
这段代码的整体思路是 每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。zset 集合中只有 score 值非常重要,value 值没有特别的意义,只需要保证它是唯一的就可以了。因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升 Redis 存取效率。但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间,所以它适用的场景也有限。
2、高级限流算法:漏斗限流

漏洞的容量是有限的,如果将漏嘴堵住,然后一直往里面灌水,它就会变满,直至再也装不进去。如果将漏嘴放开,水就会往下流,流走一部分之后,就又可以继续往里面灌水。如果漏嘴流水的速率大于灌水的速率,那么漏斗永远都装不满。如果漏嘴流水速率小于灌水的速率,那么一旦漏斗满了,灌水就需要暂停并等待漏斗腾空。所以,漏斗的剩余空间就代表着当前行为可以持续进行的数量,漏嘴的流水速率代表着系统允许该行为的最大频率。下面我们使用代码来描述单机漏斗算法。
import java.util.HashMap;
import java.util.Map;
public class FunnelRateLimiter {
static class Funnel {
// 漏斗容量
int capacity;
// 漏嘴流水速率
float leakingRate;
// 漏斗剩余空间
int leftQuota;
// 上一次漏水时间
long leakingTs;
public Funnel(int capacity, float leakingRate) {
this.capacity = capacity;
this.leakingRate = leakingRate;
this.leftQuota = capacity;
this.leakingTs = System.currentTimeMillis();
}
// 在 watering 方法中被调用
void makeSpace() {
long nowTs = System.currentTimeMillis();
// 距离上一次漏水时间过去了多久
long deltaTs = nowTs - leakingTs;
// 腾出了空间
int deltaQuota = (int) (deltaTs * leakingRate);
// 间隔时间太长,整数数字过大溢出
if (deltaQuota < 0) {
this.leftQuota = capacity;
this.leakingTs = nowTs;
return;
}
// 腾出空间太小,最小单位是 1
if (deltaQuota < 1) {
return;
}
// 增加剩余空间
this.leftQuota += deltaQuota;
this.leakingTs = nowTs;
// 剩余空间不能大于容量
if (this.leftQuota > this.capacity) {
this.leftQuota = this.capacity;
}
}
// 灌水
boolean watering(int quota) {
// 每次灌水前都会被调用以触发漏水,给漏斗腾出空间来
makeSpace();
// 判断剩余空间是否足够
if (this.leftQuota >= quota) {
this.leftQuota -= quota;
return true;
}
return false;
}
}
private Map<String, Funnel> funnels = new HashMap<>();
// 行为是否被允许
public boolean isActionAllowed(String userId, String actionKey, int capacity, float leakingRate) {
String key = String.format("%s:%s", userId, actionKey);
Funnel funnel = funnels.get(key);
if (funnel == null) {
funnel = new Funnel(capacity, leakingRate);
funnels.put(key, funnel);
}
// 需要 1 个 quota
return funnel.watering(1);
}
}
Funnel 对象的 makeSpace() 方法是漏斗算法的核心,其在每次灌水前都会被调用以触发漏水,给漏斗腾出空间来。能腾出多少空间取决于过去了多久以及流水的速率。Funnel 对象占据的空间大小不再和行为的频率成正比,它的空间占用是一个常量。
问题来了,分布式的漏斗算法该如何实现?能不能使用 Redis 的基础数据结构来搞定?
我们观察 Funnel 对象的几个字段,我们发现可以将 Funnel 对象的内容按字段存储到一个哈希结构中,灌水的时候 将哈希结构的字段取出来 进行逻辑运算后,再将新值回填到哈希结构中 就完成了一次行为频度的检测。
但是有个问题,我们无法保证整个过程的原子性。从 hash 结构中取值,然后在内存里运算,再回填到 hash 结构,这三个过程无法原子化,意味着需要进行适当的加锁控制。而一旦加锁,就意味着会有加锁失败,加锁失败就需要选择重试或者放弃。
如果重试的话,就会导致性能下降。如果放弃的话,就会影响用户体验。同时,代码的复杂度也跟着升高很多。
这真是个艰难的选择,我们该如何解决这个问题呢?用 Redis-Cell 吧,Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块只有 1 条指令 cl.throttle :
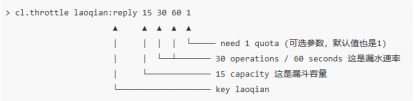
上面这个指令的意思是允许「用户老钱回复行为」的频率为每 60s 最多 30 次(漏水速率),漏斗的初始容量为 15,也就是说一开始可以连续回复 15 个帖子,然后才开始受漏水速率的影响。我们看到这个指令中漏水速率变成了 2 个参数,替代了之前的单个浮点数。用两个参数相除的结果来表达漏水速率相对单个浮点数要更加直观一些。

在执行限流指令时,如果被拒绝了,就需要丢弃或重试。cl.throttle 指令考虑的非常周到,连重试时间都帮你算好了,直接取返回结果数组的第四个值进行 sleep 即可,如果不想阻塞线程,也可以异步定时任务来重试。
参考文章:
《巧用 Redis Hyperloglog,轻松统计 UV 数据》-程序员乔戈里















 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









