







文章目录
- K8s 常见问题处理、答疑
- [1] calico一直处于未就绪状态
- [2] 删除dashboard 一直卡在delete
- [3] k8s-dashboard 修改tocken-ttl避免频繁输入tocken
- [4] kubectl 快捷指令
- [5] 解决UTC时间问题
- [6] kubectl命令自动补全
- [7] kubectl exec进入pod
- [8] 使用hostpath解决容器UTC时间问题
- [9] 如何设置sc为default sc?
- [10] pod一直pending是什么原因?
- [11] 查看集群整体状态
- [12] kubelet 无法启动原因
- [13] curl 访问k8s API报错
- [14] pod不能解析同namespace的kubernetes的 svc
- [15] 如何查看所有名称空间的所以容器?
- [16] service nodePort 报错
- [17] keepalived + nginx 搭建的高可用k8s集群 nginx为何没有log?
- [18] 有了service 为什么还需要ingress?
- [20] k8s创建的sc中,外部共享需要手动挂载吗?
- [21] k8s pod has unbound immediate PersistentVolumeClaims
- [22] pod readiness probe端口探测失败原因调查?
- [23] nfs权限问题导致的nginx不能访问问题
- [24] pod中的容器如何以root权限启动
- [25] pod 状态一直是CrashLoopBackOff
- 【26】kube-apiserver日志问题
- 【27】 NFS StorageClassName 有大小限制吗?
- 【28】两个nfs sc引发的bug
- 【29】startupprobe 和 livenessprobe的区别?
- 【30】Error状态的POD如何修复?
- 【31】如何查看某一个namespace下所有的资源?
- 【32】 ingress 的address 是怎么来的?
- 【33】 pod无法调度,describe 发现报错: MinimumReplicasUnavailable
- 【34】deployment 创建之后为何无法创建pod?
K8s 常见问题处理、答疑
[1] calico一直处于未就绪状态
查看未就绪的calico pod 状态
~]#kubectl describe pod calico-node-vjchp -n kube-system
健康检查未通过
Warning Unhealthy 2m6s (x197171 over 22d) kubelet (combined from similar events): Readiness probe failed: 2022-05-19 06:10:31.276 [INFO][598] confd/health.go 180: Number of node(s) with BGP peering established = 0
calico/node is not ready: BIRD is not ready: BGP not established with 10.50.10.22,10.50.10.23
解决1:
ip a 查看k8s集群的ip是哪个网卡
在calico 的containers -> env 中添加如下内容
# Specify interface
- name: IP_AUTODETECTION_METHOD
value: "interface=eth1"
重启calico,问题解决
解决2:
kubectl set env daemonset/calico-node -n kube-system
IP_AUTODETECTION_METHOD=interface=eth1
参考: https://stackoverflow.com/questions/54465963/calico-node-is-not-ready-bird-is-not-ready-bgp-not-established
[2] 删除dashboard 一直卡在delete
问题 : 删除dashboard一直卡在delete,ctrl +c取消之后。执行apply报错。
~]#kubectl delete -f k8s-dashboard.yaml
namespace "kubernetes-dashboard" deleted
serviceaccount "kubernetes-dashboard" deleted
service "kubernetes-dashboard" deleted
secret "kubernetes-dashboard-certs" deleted
secret "kubernetes-dashboard-csrf" deleted
secret "kubernetes-dashboard-key-holder" deleted
configmap "kubernetes-dashboard-settings" deleted
role.rbac.authorization.k8s.io "kubernetes-dashboard" deleted
clusterrole.rbac.authorization.k8s.io "kubernetes-dashboard" deleted
rolebinding.rbac.authorization.k8s.io "kubernetes-dashboard" deleted
clusterrolebinding.rbac.authorization.k8s.io "kubernetes-dashboard" deleted
deployment.apps "kubernetes-dashboard" deleted
service "dashboard-metrics-scraper" deleted
deployment.apps "dashboard-metrics-scraper" deleted
^C
You have mail in /var/spool/mail/root
[root@hadoop100 ~]#
[root@hadoop100 ~]#
[root@hadoop100 ~]#kubectl apply -f k8s-dashboard.yaml
Warning: Detected changes to resource kubernetes-dashboard which is currently being deleted.
namespace/kubernetes-dashboard unchanged
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
Error from server (Forbidden): error when creating "k8s-dashboard.yaml": serviceaccounts "kubernetes-dashboard" is forbidden: unable to create new content in namespace kubernetes-dashboard because it is being terminated
原因: dashboard的ns一直terminating. 因为dashboard 的spec字段有finalizers。目的是为了防止 volumnes 被意外删除。
~]#kubectl get ns
NAME STATUS AGE
kubernetes-dashboard Terminating 24d
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cpnnGfzU-1689141234657)(E:\book\Kubernetes\asset\image-20221125105942262.png)]](https://img-blog.csdnimg.cn/be9c29d1dbc14f748ee9e7ae275eab1e.png)
Kubernetes 中的对象删除并不像表面上看起来那么简单,删除对象涉及一系列过程,例如对象的级联和非级联删除,在删除之前检查以确定是否可以安全删除对象等等。这些都是通过称为 Finalizers(终结器)的 API 对象实现的。
Kubernetes 对象的删除过程
- 发出删除命令后 Kubernetes 会将该对象标记为待删除,但不会真的删除对象,具体做法是将对象的 metadata.deletionTimestamp 字段设置为当前时间戳,这使得对象处于只读状态(除了修改 finalizers 字段)。
- 当 metadata.deletionTimestamp 字段非空时,负责监视该对象的各个控制器会执行对应的 Finalizer 动作,每个 Finalizer 动作完成后,就会从 Finalizers 列表中删除对应的 Finalizer。
- 一旦 Finalizers 列表为空时,就意味着所有 Finalizer 都被执行过了,垃圾收集器会最终删除该对象。
像 ns 这种重要的api-resource 必须要通过Finalizers来约束。
finalizers 不为空,代表是标记删除,如果置位空则直接删除.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a2Ry0A0S-1689141180925)(E:\book\Kubernetes\asset\image-20221125105834250.png)]](https://img-blog.csdnimg.cn/db76cdd51030443f86cd19546819df8f.png)
解决:
– 2022年6月8日18:23:48
在etcd中删除
etcdctl del /registry/namespaces/rook-ceph
另外
1、kubectl get ns ingress-nginx -o json > tmp.json
2、删除spec中的Finalizers字段
3、通过api-server 的restful删除
curl -k -H "Content-Type: application/json" -X PUT --data-binary @tmp.json http://127.0.0.1:8080/api/v1/namespaces/ingress-nginx/finalize
4、ns 被彻底删除
参考: https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/finalizers/
1)运行以下命令以查看处于“Terminating”状态的namespace:
$ kubectl get namespaces
2)选择一个Terminating namespace,并查看namespace 中的finalizer。运行以下命令:
$ kubectl get namespace <terminating-namespace> -o yaml
输出信息如下:
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: "2019-11-20T15:18:06Z"
deletionTimestamp: "2020-01-16T02:50:02Z"
name: <terminating-namespace>
resourceVersion: "3249493"
selfLink: /api/v1/namespaces/knative-eventing
uid: f300ea38-c8c2-4653-b432-b66103e412db
spec:
finalizers:
- kubernetes
status:
3)导出json格式到文件
$ kubectl get namespace <terminating-namespace> -o json >tmp.json
4)编辑tmp.josn,删除finalizers 字段的值
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"creationTimestamp": "2019-11-20T15:18:06Z",
"deletionTimestamp": "2020-01-16T02:50:02Z",
"name": "<terminating-namespace>",
"resourceVersion": "3249493",
"selfLink": "/api/v1/namespaces/knative-eventing",
"uid": "f300ea38-c8c2-4653-b432-b66103e412db"
},
"spec": { #从此行开始删除
"finalizers": []
}, # 删到此行
"status": {
"phase": "Terminating"
}
}
5)开启proxy
$ kubectl proxy
执行该命令后,当前终端会被卡住
6)打开新的一个窗口,执行以下命令
$ curl -k -H "Content-Type: application/json" -X PUT --data-binary @tmp.json http://127.0.0.1:8001/api/v1/namespaces/<terminating-namespace>/finalize
7)确认处于Terminating 状态的namespace已经被删除
[3] k8s-dashboard 修改tocken-ttl避免频繁输入tocken
1、向dashboard的yaml中增加args参数
spec:
containers:
- name: kubernetes-dashboard
image: kubernetesui/dashboard:v2.3.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
- --token-ttl=432000
2、kubectl apply -f .
[4] kubectl 快捷指令
alias kc='kubectl'
alias kgp='kubectl get pods'
alias kgs='kubectl get svc'
[5] 解决UTC时间问题
很多应用镜像时区都是UTC,而不是本机时间(当然,前提是本机时间是对的,云服务器不存在这个问题)
Pod设置挂载本地时间。
volumeMounts:
- name: localtime
mountPath: /etc/localtime
volumes:
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
[6] kubectl命令自动补全
master节点执行
echo "source <(kubectl completion bash)" >> ~/.bash_profile
source ~/.bash_profile
[7] kubectl exec进入pod
命令格式
kubectl exec pod名称 -n 命名空间 -it -c 容器名称 /bin/sh 在容器内部执行命令
[8] 使用hostpath解决容器UTC时间问题
在镜像中心拉去的镜像,时间基本上都是UTC时间,而我们使用的是CST时间。
没有挂载的时候,默认都是UTC时间
apiVersion: v1
kind: Pod
metadata:
name: busy-box-test
namespace: dev
spec:
restartPolicy: OnFailure
containers:
- name: busy-box-test
image: 10.50.10.185/harbortest/busybox:latest
imagePullPolicy: IfNotPresent
command: ["sleep", "60000"]
使用volumemount localtime 变为CST时间
apiVersion: v1
kind: Pod
metadata:
name: busy-box-test
namespace: dev
spec:
restartPolicy: OnFailure
containers:
- name: busy-box-test
image: 10.50.10.185/harbortest/busybox:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: date-config
mountPath: /etc/localtime
command: ["sleep", "60000"]
volumes:
- name: date-config
hostPath:
path: /etc/localtime
[9] 如何设置sc为default sc?
查看sc
[root@k8s-master1 k8s]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-prod nfs-nfs-prod Delete WaitForFirstConsumer false 6d3h
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 3d19h
创建pv的时候需要声明使用的storageClassName。
方法一
kubectl edit sc nfs-prod
在yaml文件中添加metadata.annotation 字段中添加
storageclass.kubernetes.io/is-default-class: "true"
方法二
kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
其中standard为 sc的名字
查看sc
[root@master1 ~]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-prod (default) nfs-nfs-prod Delete WaitForFirstConsumer false 6d19h
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 4d11h
参考文档
https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/change-default-storage-class/
[10] pod一直pending是什么原因?
搭建efk的过程中,创建了一个sts, 第一个pod一直pending。
创建高可用es的yaml文件如下
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es
namespace: logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
nodeSelector:
es: log
initContainers:
- name: increase-vm-max-map
image: 10.50.10.185/harbortest/busybox:latest
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: 10.50.10.185/harbortest/busybox:latest
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
containers:
- name: elasticsearch
image: 10.50.10.185/efk/docker.elastic.co/elasticsearch/elasticsearch:7.6.2
ports:
- name: rest
containerPort: 9200
- name: inter
containerPort: 9300
resources:
limits:
cpu: 1000m
requests:
cpu: 1000m
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: cluster.initial_master_nodes
value: "es-0,es-1,es-2"
- name: discovery.zen.minimum_master_nodes
value: "2"
- name: discovery.seed_hosts
value: "elasticsearch"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
- name: network.host
value: "0.0.0.0"
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 100Gi
describe po的event如下:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
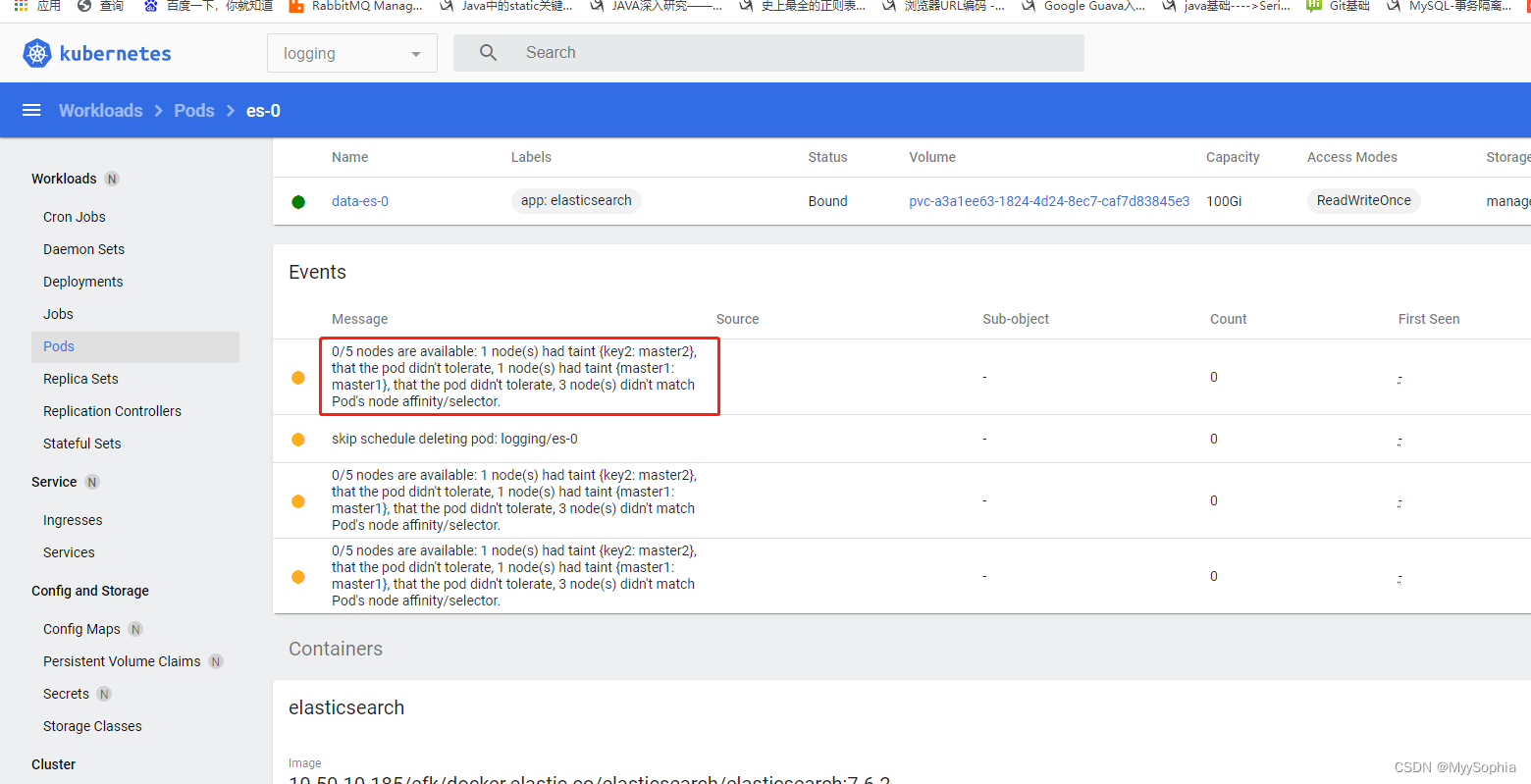
Warning FailedScheduling 56m default-scheduler 0/5 nodes are available: 5 pod has unbound immediate PersistentVolumeClaims.
Warning FailedScheduling 56m default-scheduler 0/5 nodes are available: 1 node(s) had taint {key2: master2}, that the pod didn't tolerate, 1 node(s) had taint {master1: master1}, that the pod didn't tolerate, 3 node(s) didn't match Pod's node affinity/selector.
Warning FailedScheduling 9m8s (x45 over 55m) default-scheduler 0/5 nodes are available: 1 node(s) had taint {key2: master2}, that the pod didn't tolerate, 1 node(s) had taint {master1: master1}, that the pod didn't tolerate, 3 node(s) didn't match Pod's node affinity/selector.
pending的原因是 : pod还没有调度到任何节点上。因为没有适合的节点,因为是我yaml文件中有nodeSelector ,修改这个nodeSelector为自己的机器即可,或者不指定也可以.
其实这个问题,我一开始被误导了,因为都是warning,我一直在找error,k8s的设计哲学中,认为pod pending只是waring而不是error,这正是声明式API的特征,如果是命令式的,那一定是fail,就会有error/fatal。
所以一直怀疑是sts没有挂上pv的问题,但是经过排查pvc和pv的状态都是好着的。
如果理解了k8s的哲学,那么pod的warning event也要分析。
此外借助dashboard上的warning 可以更快定位
[11] 查看集群整体状态
kubectl cluster-info
[root@master3 /etc/kubernetes]# kubectl cluster-info
Kubernetes control plane is running at https://10.50.10.31:6443
CoreDNS is running at https://10.50.10.31:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
查看组件健康状态
[root@master3 /etc/kubernetes]#kubectl get componentstatuses
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
[12] kubelet 无法启动原因
docker和k8s的 cgroupdriver必须一致才能启动.
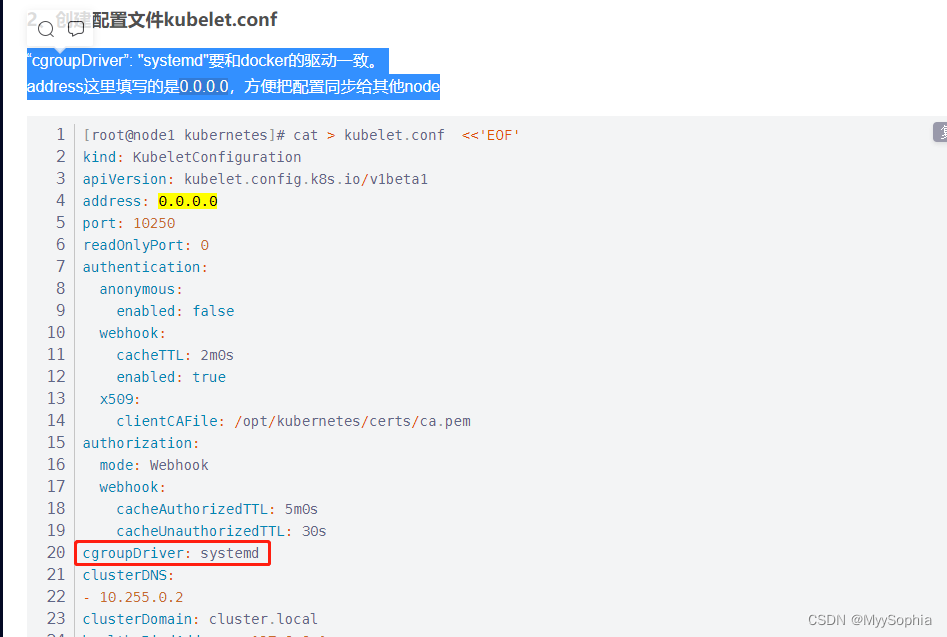
vi /etc/docker/daemon.json
{
"registry-mirrors": ["https://10.50.10.185"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
[13] curl 访问k8s API报错
验证高可用集群时
[root@master1 /etc/kubernetes]#curl -k https://10.50.10.31:6443/version
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "Unauthorized",
"reason": "Unauthorized",
"code": 401
}
解决:
401 权限不足,报错已经说的很明显了。关于k8s的鉴权是一个比较复杂的事情,按照我的理解简答解释一下:
当client 访问k8s 资源时,需要经历 认证、授权、准入控制三个步骤。
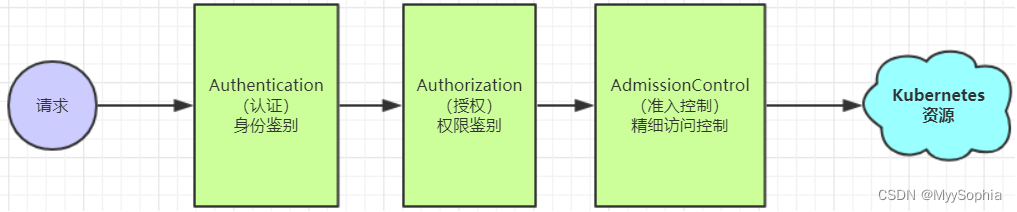
很明显是第一个步骤出了问题。
[root@master1 /etc/kubernetes]#curl --header "Authorization: Bearer $TOKEN" --insecure -X GET $APISERVER/version
{
"major": "1",
"minor": "23",
"gitVersion": "v1.23.8",
"gitCommit": "a12b886b1da059e0190c54d09c5eab5219dd7acf",
"gitTreeState": "clean",
"buildDate": "2022-06-16T05:51:36Z",
"goVersion": "go1.17.11",
"compiler": "gc",
"platform": "linux/amd64"
https://www.cnblogs.com/dudu/p/14485314.html
curl 操作k8s的api
https://www.jianshu.com/p/0a5976ce1ce4
[14] pod不能解析同namespace的kubernetes的 svc
同一个ns,不同pod的是否可以通过svc的域名访问?
[root@master1 /var/log/kubernetes]#kubectl get po
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 0 18m
[root@master1 /var/log/kubernetes]#kubectl get svc kubernetes
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d20h
[root@master1 /var/log/kubernetes]#kubectl exec busybox -n default -- nslookup 10.96.0.1
Server: 10.96.0.2
Address: 10.96.0.2:53
1.0.96.10.in-addr.arpa name = kubernetes.default.svc.cluster.local
[root@master1 /var/log/kubernetes]#
[root@master1 /var/log/kubernetes]#kubectl exec busybox -n default -- nslookup kubernetes
Server: 10.96.0.2
Address: 10.96.0.2:53
** server can't find kubernetes.default.svc.cluster.local: NXDOMAIN
*** Can't find kubernetes.svc.cluster.local: No answer
*** Can't find kubernetes.cluster.local: No answer
*** Can't find kubernetes.default.svc.cluster.local: No answer
*** Can't find kubernetes.svc.cluster.local: No answer
*** Can't find kubernetes.cluster.local: No answer
command terminated with exit code 1
[15] 如何查看所有名称空间的所以容器?
使用 -o jsonpath={..image} 参数,输出结果将格式化为只包含容器镜像名字的形式。该参数将递归地查找 JSON 数据中所有 image 字段,例如:
kubectl get pods --all-namespaces -o jsonpath={..image}
使用工具 tr、sort、uniq 格式化输出结果
- 使用
tr将空格替换为新的行 - 使用
sort对结果排序 - 使用
uniq对镜像使用计数
kubectl get pods --all-namespaces -o jsonpath="{..image}" |\
tr -s '[[:space:]]' '\n' |\
sort |\
uniq -c
用 Pod 中 image 字段的绝对路径来查找容器的镜像名字,可以规避 image 字段重复出现的情况。
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}"
sonpath 的解析如下:
.items[*]:每一个返回值.spec: 获取 spec.containers[*]: 每一个 container.image:获取 image
注意
如果通过名字查找 Pod,例如
kubectl get pod nginx,由于返回结果只有一个 Pod,此时,.items[*]这一部分应该从 jsonpath 中移除。
[16] service nodePort 报错
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: dev
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30008
selector:
app: nginx
[root@master1 /opt/kubernetes/k8s/configmap]#kubectl apply -f nginx-cm-po-svc.yaml
The Service "nginx" is invalid: spec.clusterIPs[0]: Invalid value: "None": may not be set to 'None' for NodePort services
原因是svc重名了。 那个svc是clusterip:none。报错 直接说svc已存在不就好了么 。 K8s的这个报错真的是醉了。 或许是对其设计哲学理解太浅薄了吧
[root@master1 /opt/kubernetes/k8s/configmap]#kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 8d
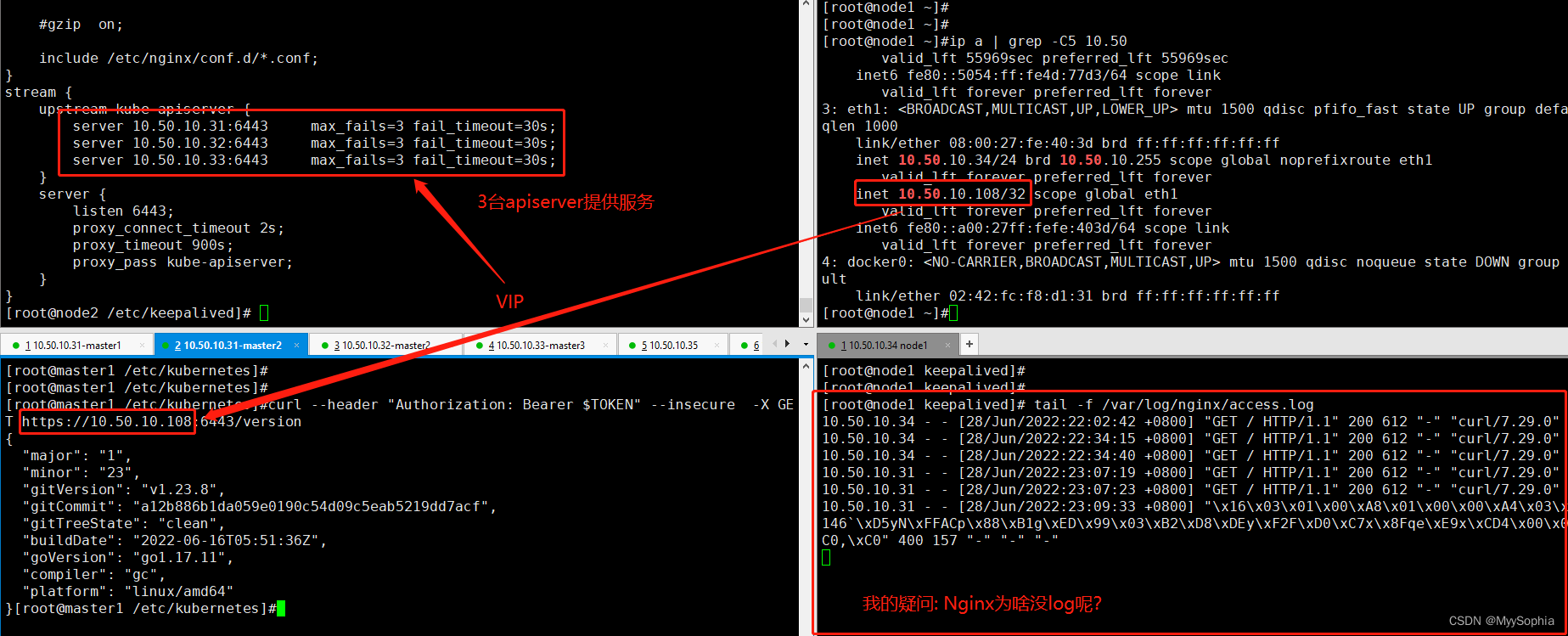
[17] keepalived + nginx 搭建的高可用k8s集群 nginx为何没有log?
这个问题暂时还不知道是什么原因?
[18] 有了service 为什么还需要ingress?
- Service可以使用NodePort暴露集群外访问端口,但是性能低下不安全。 ingress 不用开nodeport,外部无法感知这个服务. ,端口方面很安全.
- 缺少Layer7的统一访问入口(可以理解为网关),可以负载均衡(基于7层的可以拆解包,例如vip用户访问哪些pod,普通用户访问哪些pod。这种负载在svc是无法完成的)、限流等
- Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由 Ingress 资源上定义的规则控制。
- 我们使用Ingress作为整个集群统一的入口,配置Ingress规则转到对应的Service
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B6I7aapk-1689141180935)(E:\book\Kubernetes\k8s从入门到放弃\Kubenetes.assets\image-20220708095616971.png)]](https://img-blog.csdnimg.cn/3a739922eabd417b899ceac1e2f6a1c2.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dRtdpPX4-1689141180935)(E:\book\Kubernetes\K8s 常见问题处理.assets\image-20220708100447957.png)]](https://img-blog.csdnimg.cn/cf4dc6efb9bb40ebafcedcf46eaeaf13.png)
update 2022年10月11日18:10:41
安装zk、kafka、rabbitmq外部访问的方式目前都是svc的nodeport方式。这种方式很不方便特别是对于需要暴露多个端口的rabbitmq来说极为不方便。
如何把ingress 用起来呢?
《kubernetes进阶实战》 16.2.1 说到:
若需要在Kubernetes集群之外访问Elasticsearch服务,建议为Elasticsearch集群启用认证功能之后修改协调器Service的类型为NodePort或LoadBalancer,或者使用Ingress将该服务暴露至Kubernetes集群外部。
Kubernetes on EKS - coredns vs external-dns
Can anyone explain the difference between these two components, please?
In our (undocumented) cluster I can see there is a kube-dns service, a coredns deployment with 2 replicas, and an external-dns deployment with 1 replica.
The kube-dns service has a ClusterIP for traffic into port 53 - and this is the port the coredns pods listen on.
I assume therefore the backend DNS within the cluster is handled via a combination of both the kube-dns service and the coredns pods.
Where does external-dns fit in?
What is the difference between these 3 components?
答案:
Core-DNS is the internal DNS service used by the cluster’s resources. It’s the component which registers pod/service DNS names. This is considered a critical component of Kubernetes.
https://coredns.io/plugins/kubernetes/
External-DNS is an add-on component which allows the deployment of DNS records in external DNS services such as Route53 based on the host field within ingress resources deployed to the cluater.
https://github.com/kubernetes-sigs/external-dns
[20] k8s创建的sc中,外部共享需要手动挂载吗?
k8s 使用nfs sc做动态存储。 pod所在主机需要挂载nfs吗?
答: 不需要,sc 会自动创建pv池。这个过程sc会自己去挂载到指定挂载点
nfs-subdir-external-provisioner是一个自动配置卷程序,它使用现有的和已配置的 NFS 服务器来支持通过持久卷声明动态配置 Kubernetes 持久卷
存储组件 NFS subdir external provisioner 是一个存储资源自动调配器,它可用将现有的 NFS 服务器通过持久卷声明来支持 Kubernetes 持久卷的动态分配。自动新建的文件夹将被命名为 n a m e s p a c e − {namespace}- namespace−{pvcName}-${pvName} ,由三个资源名称拼合而成。

[21] k8s pod has unbound immediate PersistentVolumeClaims
安装nexus,使用nfs sc。
使用managed-nfs-storage就没问题,使用另外一个就有问题。另外一个sc是通过kuboard创建的。

- 这个问题还要继续追踪为何sc不可用…
update 2022年10月11日14:31:55
启动pod报错:
pvc的waring:
waiting for a volume to be created, either by external provisioner "k8s-sigs.io/nfs-subdir-external-provisioner" or manually created by system administrator
pod的warning
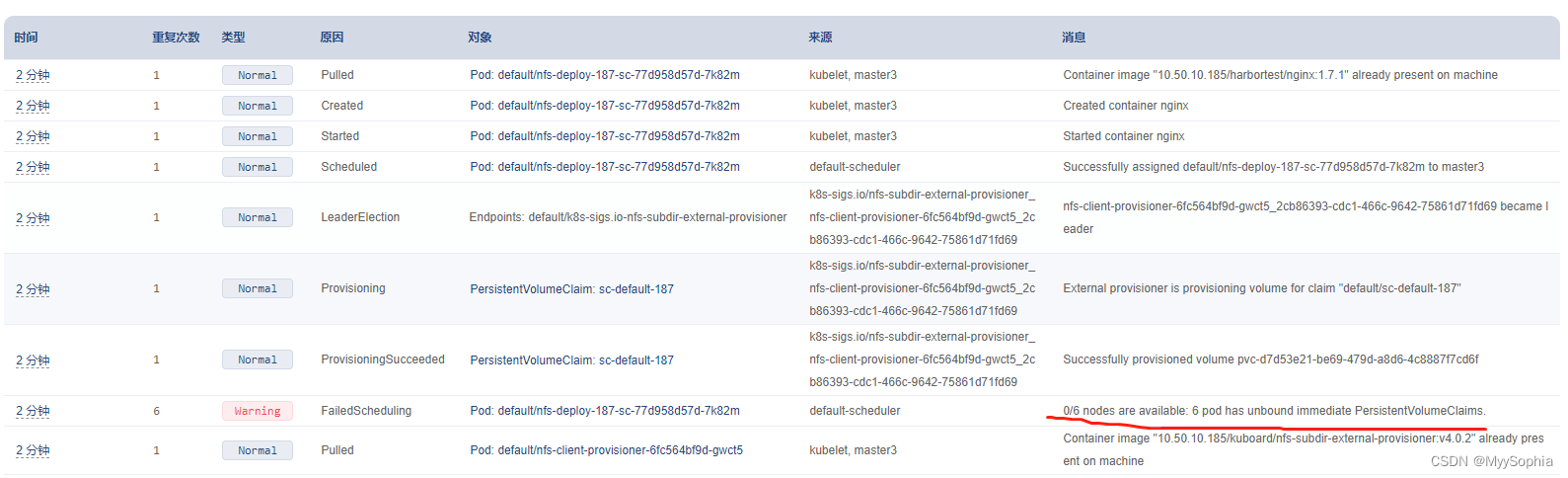
为何sc会无法为pod自动绑定pv呢?检查了一下pvc没有任何问题。
解决: nfs-client-provisioner pod消失导致无法正常为pod绑定存储。手残不小心删掉了,我启动的pod名字和那个太像啦。最好将其部署为deploy且多个副本

nfs-subdir-external-provisioner是一个自动配置卷程序,它使用现有的和已配置的 NFS 服务器来支持通过持久卷声明动态配置 Kubernetes 持久卷
存储组件 NFS subdir external provisioner 是一个存储资源自动调配器,它可用将现有的 NFS 服务器通过持久卷声明来支持 Kubernetes 持久卷的动态分配。自动新建的文件夹将被命名为 n a m e s p a c e − {namespace}- namespace−{pvcName}-${pvName} ,由三个资源名称拼合而成。
参考问题[20]
[22] pod readiness probe端口探测失败原因调查?
问题: 安装nexus仓库时pod 的8081 端口一直访问不通
Readiness probe failed: Get "http://10.244.166.156:8081/": dial tcp 10.244.166.156:8081: connect: connection refused
探测的yaml
readinessProbe:
failureThreshold: 6
httpGet:
path: /
port: 8081
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 10
解决: 这个问题的原因是超过了initialDelaySeconds的时间导致探测失败,适当调大这个参数,或者重启一下就好了。
[23] nfs权限问题导致的nginx不能访问问题
有两个sc,一个是nfs svr称为A sc,另外一个是nas存储称为B sc。
nas存储的sc nginx无法访问,报错是没有权限。
在A sc上创建nginx的index.html可以正常访问
在B sc上创建则无法访问没提示权限不足(“/usr/share/nginx/html/index.html” is forbidden (13: Permission denied))
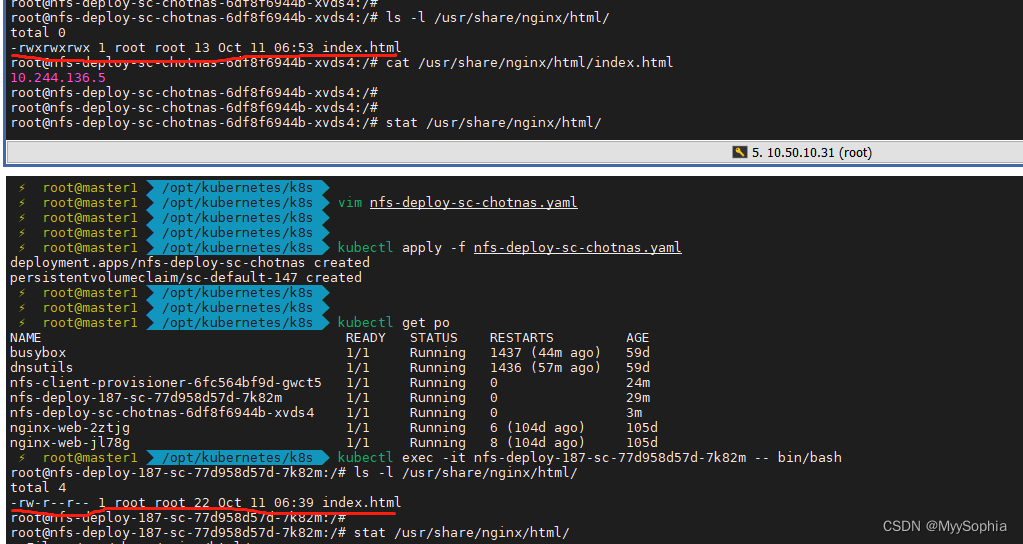
[24] pod中的容器如何以root权限启动
containers:
- name: ...
image: ...
securityContext:
runAsUser: 0
helm chart中是runAsUser。 0代表root
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lBUqbbzR-1689141180938)(E:\book\Kubernetes\asset\image-20221019112323228.png)]](https://img-blog.csdnimg.cn/0cf3064257a94d18bc831e12be7d63a5.png)
[25] pod 状态一直是CrashLoopBackOff
今天启动rabbitmq的时候pod一直启动不起来。状态一直是CrashLoopBackOff ,无从下周。
pod状态流转图,个人感觉这个状态的pod最不好查问题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f38tLGx2-1689141180939)(E:\book\Kubernetes\asset\image-20221019180615002.png)]](https://img-blog.csdnimg.cn/2d181f0049b3406e9d8bdfb6d4181732.png)
CrashLoopBackOff in Kubernetes Pods: Common Causes
The CrashLoopBackOff error can be caused by a variety of issues, including:
- Insufficient resources—lack of resources prevents the container from loading
- Locked file—a file was already locked by another container
- Locked database—the database is being used and locked by other pods
- Failed reference—reference to scripts or binaries that are not present on the container
- Setup error—an issue with the init-container setup in Kubernetes
- Config loading error—a server cannot load the configuration file
- Misconfigurations—a general file system misconfiguration
- Connection issues—DNS or kube-DNS is not able to connect to a third-party service
- Deploying failed services—an attempt to deploy services/applications that have already failed (e.g. due to a lack of access to other services)
https://komodor.com/learn/how-to-fix-crashloopbackoff-kubernetes-error/
【26】kube-apiserver日志问题
api-server的日志已经指向了目录,怎么还会在message中打印log呢
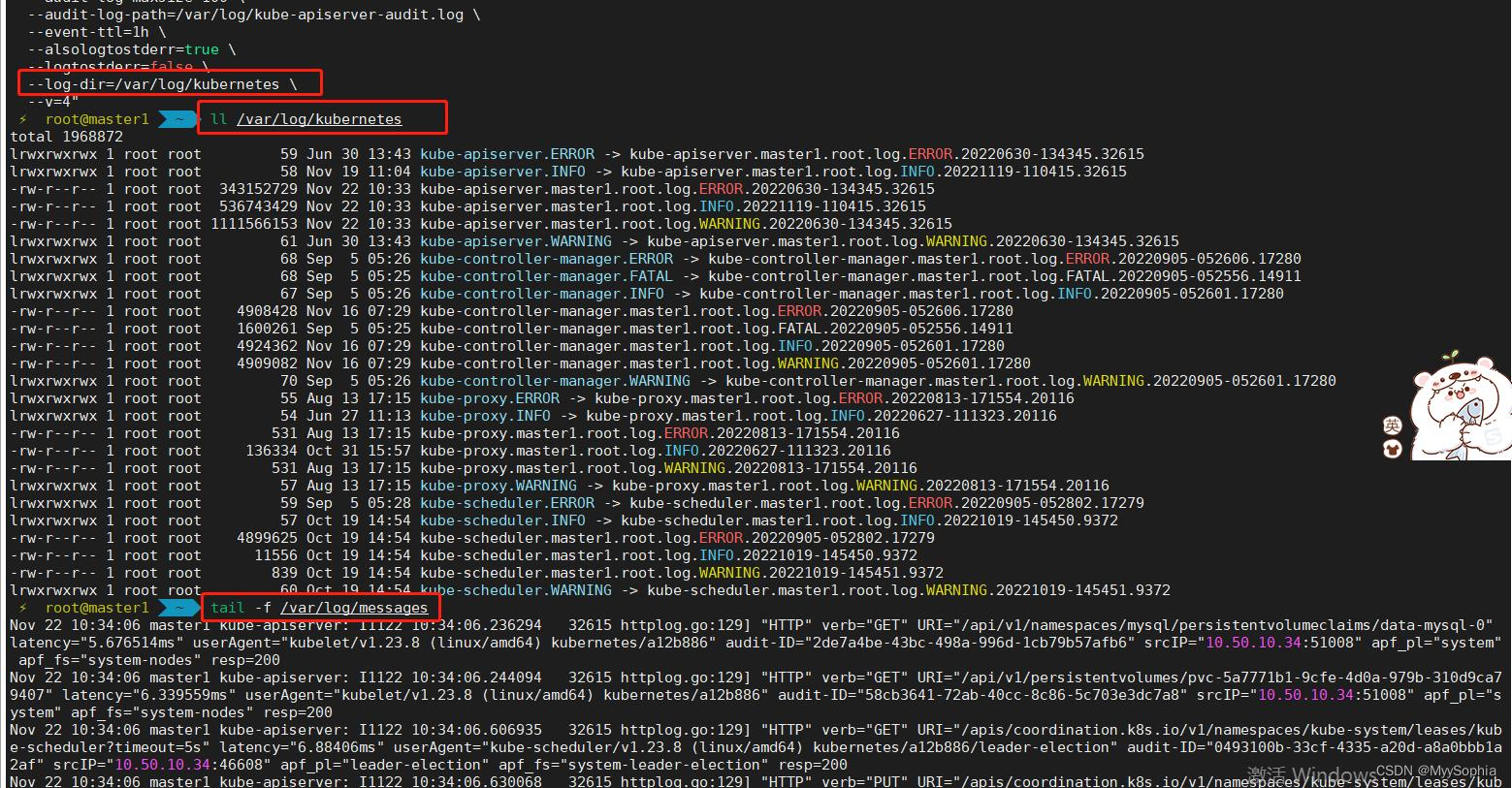
如何解决kube-apiserver日志轮转的问题。
对于这个问题目前的解决方法:
ansible k8s-all -m shell -a "find /var/log/ -maxdepth 1 -name 'messages-*' -type f -mtime +1 -print | xargs -I GG rm -rf GG
1、开发脚本删除/var/log/kubernetes的日志
这里脚本删除的时候需要注意一定不能按照时间一刀切的删除,要保留最近几个日志,因为有的日志可能很久都不更新。
#!/bin/bash
#==============================================================#
# File : clean-k8s-component--log
# Ctime : 2022年8月10日13:12:22
# Mtime : 2022年8月10日13:12:27
# Usage : clean k8s log
# author : ninesun
#==============================================================#
rm -rf >/tmp/no_clean_log.log
for log in `ls -l /var/log/kubernetes | grep lrw |awk '{print $9}'`;do
#no_clean_log=`stat /var/log/kubernetes/${log} | awk 'NR==1'|awk '{print $4}' | tr -d "‘"`
no_clean_log=`readlink /var/log/kubernetes/${log}`
echo ${no_clean_log} >> /tmp/no_clean_log.log
done
no_clean_log_foramt=`sed -r ':a;N;s/\n/|/;ba;' /tmp/no_clean_log.log`
find_list=`find /var/log/kubernetes/ -type f -mtime +1 -print`
echo ${find_list} |tr ' ' '\n'| egrep -v ${no_clean_log_foramt} | xargs -I GG echo "rm -rf GG"|bash
2、日志轮转工具
日志轮转工具 logrotate
/etc/logrotate.d more syslog
/var/log/cron
/var/log/maillog
/var/log/messages
/var/log/secure
/var/log/spooler
{
missingok
rotate 2 # 增加rotate 为2
sharedscripts
postrotate
/bin/kill -HUP `cat /var/run/syslogd.pid 2> /dev/null` 2> /dev/null || true
endscript
}
执行 logrotate -f /etc/logrotate.d/syslog 结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RhqvW7mi-1689141180941)(E:\book\Kubernetes\asset\image-20221122134455728.png)]](https://img-blog.csdnimg.cn/b73d77a4fb11482f8771527c2091d3d7.png)
3、参考
【27】 NFS StorageClassName 有大小限制吗?
2022/10/30 因下游消费者异常 rabbirmq 消息发生大量堆积,直接把nfs server的空间撑爆了。
stroageClass限制的是50GB,怎么会把nfs 撑爆呢?难道这个限制根本限不住?
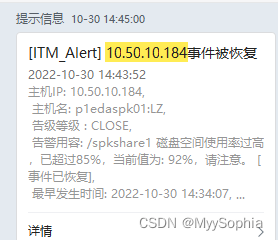
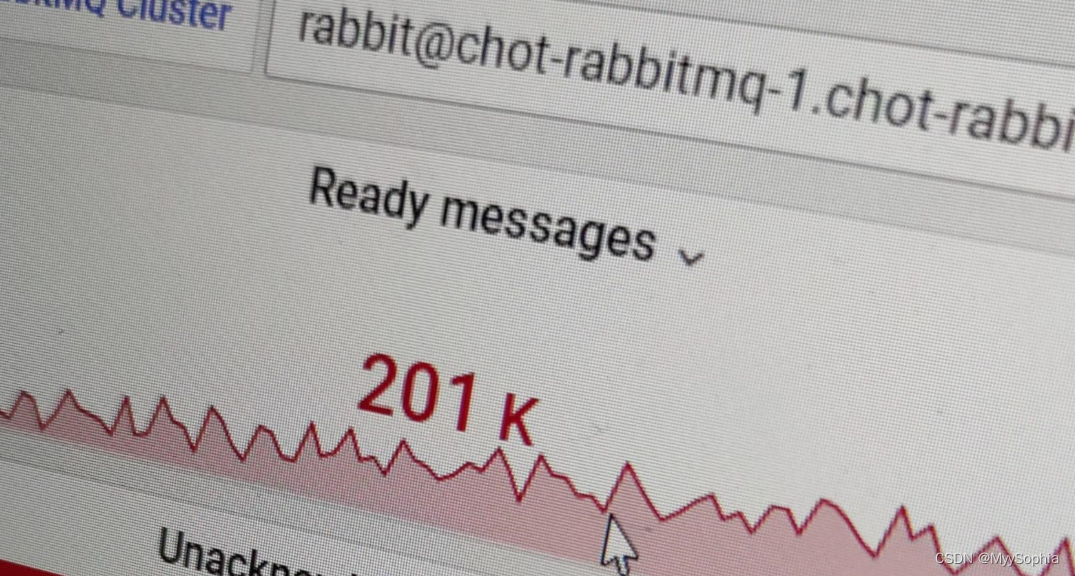
做个实验,nfs 作为sc,其大小限制是否生效?
【28】两个nfs sc引发的bug
集群初建时使用了一个较小的nfs svr作为k8s的后端存储,随着业务数量的增多, 新搭建了一个大的nfs server,共10TB。
在迁移业务时发现了意料之外的bug.
我的操作步骤是这样的:
step1 : 修改旧的 yaml部署文件中的storageclassname
step2: 删除旧的rabbitmq集群 (没有删除pvc.) -> 初步推测问题出在这一步,
step3:启动新的集群(启动新的sc作为后端存储)
问题: 新的nfs 存储上有建立pvc文件夹,但问题是没数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fZdj7K7e-1689141180944)(E:\book\Kubernetes\rabbitmq\assets\image-20221123143143883.png)]](https://img-blog.csdnimg.cn/ef4b9450be294fbab23294550c479f94.png)
这是什么原因呢?
经过调查发现, 两个sc 在 两个NFS svr 都创建了以pvc name 命名的文件夹, 数据还是存储在旧的上面. 新的sc 动态建立的文件夹是空的。 感觉好像如果是多个nfs 时nfs provisioner有bug.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-meaQA4WR-1689141180944)(E:\book\Kubernetes\rabbitmq\assets\image-20221123150535557.png)]](https://img-blog.csdnimg.cn/a16743bae10c4d9cba3b5a49b8739b49.png)
如何解决呢?
将旧的sc 创建的pv 都删掉,nfs上以pvc 创建的文件夹名字也删掉。使用新的sc重新。
怪异的事情发生了,两个po 竟然的pv竟然分散在两个nfs上. (难道是智能高可用)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MRpFOdpk-1689141180945)(E:\book\Kubernetes\rabbitmq\assets\image-20221123154157555.png)]](https://img-blog.csdnimg.cn/20e2007b3b3f4b0aad59029be66a749f.png)
[root@node3 ~]#df -h | grep -E '179|184' | grep -i rabbitmq
10.50.10.179:/k8s-sc2-xfs/data/rabbitmq-data-chot-rabbitmq-1-pvc-eeade764-5a20-42e1-a71c-d3cf7a222224 10T 13G 10T 1% /var/lib/kubelet/pods/e2cc5043-5232-44f7-8ba8-9dc7096ec0df/volumes/kubernetes.io~nfs/pvc-eeade764-5a20-42e1-a71c-d3cf7a222224
[root@node3 ~]#
[root@node3 ~]#
[root@node3 ~]#exit
logout
Connection to node3 closed.
⚡ root@master1 /opt
⚡ root@master1 /opt ssh master3
Last login: Wed Nov 23 15:38:57 2022 from 10.50.10.31
[root@master3 ~]#
[root@master3 ~]#
[root@master3 ~]#df -h | grep -E '179|184' | grep -i rabbitmq
10.50.10.184:/spkshare1/data/rabbitmq-data-chot-rabbitmq-0-pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8 493G 200G 268G 43% /var/lib/kubelet/pods/a1c182c7-5110-4481-b4c0-7166fad57d7a/volumes/kubernetes.io~nfs/pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8
[root@master3 ~]#kubectl get pvc -n rabbitmq
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-chot-rabbitmq-0 Bound pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8 200Gi RWO nfs-storage-179sc 20m
data-chot-rabbitmq-1 Bound pvc-eeade764-5a20-42e1-a71c-d3cf7a222224 200Gi RWO nfs-storage-179sc 20m
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CRLeAnyP-1689141180945)(E:\book\Kubernetes\rabbitmq\assets\image-20221123145703727.png)]](https://img-blog.csdnimg.cn/d9b46e617bf14ca5b52fd6021266b8e9.png)
describe pvc
⚡ root@master1 /opt k describe pvc data-chot-rabbitmq-0 -n rabbitmq
Name: data-chot-rabbitmq-0
Namespace: rabbitmq
StorageClass: nfs-storage-179sc
Status: Bound
Volume: pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8
Labels: app.kubernetes.io/instance=chot-rabbitmq
app.kubernetes.io/name=rabbitmq
Annotations: pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
volume.beta.kubernetes.io/storage-provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
volume.kubernetes.io/storage-provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
Finalizers: [kubernetes.io/pvc-protection]
Capacity: 200Gi
Access Modes: RWO
VolumeMode: Filesystem
Used By: chot-rabbitmq-0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ExternalProvisioning 29m (x2 over 29m) persistentvolume-controller waiting for a volume to be created, either by external provisioner "k8s-sigs.io/nfs-subdir-external-provisioner" or manually created by system administrator
Normal Provisioning 29m k8s-sigs.io/nfs-subdir-external-provisioner_nfs-client-provisioner-6fc564bf9d-gwct5_c033d3db-0c2f-4657-ac4d-506fc1beaf20 External provisioner is provisioning volume for claim "rabbitmq/data-chot-rabbitmq-0"
Normal Provisioning 29m k8s-sigs.io/nfs-subdir-external-provisioner_nfs-client-provisioner-sc179-8447d45564-tfxfd_d4b530f7-d1b2-4cc4-b47f-b1570376917b External provisioner is provisioning volume for claim "rabbitmq/data-chot-rabbitmq-0"
Normal ProvisioningSucceeded 29m k8s-sigs.io/nfs-subdir-external-provisioner_nfs-client-provisioner-6fc564bf9d-gwct5_c033d3db-0c2f-4657-ac4d-506fc1beaf20 Successfully provisioned volume pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8
Normal ProvisioningSucceeded 29m k8s-sigs.io/nfs-subdir-external-provisioner_nfs-client-provisioner-sc179-8447d45564-tfxfd_d4b530f7-d1b2-4cc4-b47f-b1570376917b Successfully provisioned volume pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8
describe pv
# pod1 的pv
⚡ root@master1 /opt k describe pv pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8
Name: pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8
Labels: <none>
Annotations: pv.kubernetes.io/provisioned-by: k8s-sigs.io/nfs-subdir-external-provisioner
Finalizers: [kubernetes.io/pv-protection]
StorageClass: nfs-storage-179sc
Status: Bound
Claim: rabbitmq/data-chot-rabbitmq-0
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 200Gi
Node Affinity: <none>
Message:
Source:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: 10.50.10.184
Path: /spkshare1/data/rabbitmq-data-chot-rabbitmq-0-pvc-ea7912e4-b9bc-4940-b42e-43a667f741c8
ReadOnly: false
Events: <none>
# pod2的pv
⚡ root@master1 /opt k describe pv pvc-eeade764-5a20-42e1-a71c-d3cf7a222224
Name: pvc-eeade764-5a20-42e1-a71c-d3cf7a222224
Labels: <none>
Annotations: pv.kubernetes.io/provisioned-by: k8s-sigs.io/nfs-subdir-external-provisioner
Finalizers: [kubernetes.io/pv-protection]
StorageClass: nfs-storage-179sc
Status: Bound
Claim: rabbitmq/data-chot-rabbitmq-1
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 200Gi
Node Affinity: <none>
Message:
Source:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: 10.50.10.179
Path: /k8s-sc2-xfs/data/rabbitmq-data-chot-rabbitmq-1-pvc-eeade764-5a20-42e1-a71c-d3cf7a222224
ReadOnly: false
nfs provisioner 版本
nfs-subdir-external-provisioner:v4.0.2
如何解决呢?
删除旧的存储类(SC), 只保留一个sc动态创建pv就不会有问题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Niv5zYhv-1689141180946)(E:\book\Kubernetes\rabbitmq\assets\image-20221123165310442.png)]](https://img-blog.csdnimg.cn/1ed7064dc30b4974940d31c7c5d99f7e.png)
【29】startupprobe 和 livenessprobe的区别?
initdelay 是延迟检查,延迟多久呢? 这个时间不好把控。 如果设定很长 在延迟检查之后刚好崩了,这就检查表刅。如果设置较短,会频繁检查失败
多久做一次?每次间隔多少s?
startupprobe 可以每10s检查一下。 只是在启动阶段检查,启动成功后不再使用该probe会使用livebessprobe
【30】Error状态的POD如何修复?
在安装gitlab的时候,pod状态有一个error状态. 这说明pod在启动的时候就发生了异常。
通过describe pod 和log 并没有发现什么问题,一度陷入了迷茫。
一下子就定位到问题了,原因是redis 有密码验证,而gitlab的环境变量未设定该参数。redis是用helm安装的,直接enable=false先禁掉redis auth.
Pod 处于 Error 状态
通常处于 Error 状态说明 Pod 启动过程中发生了错误。常见的原因包括
- 依赖的 ConfigMap、Secret 或者 PV 等不存在
- 请求的资源超过了管理员设置的限制,比如超过了 LimitRange 等
- 违反集群的安全策略,比如违反了 PodSecurityPolicy 等
- 容器无权操作集群内的资源,比如开启 RBAC 后,需要为 ServiceAccount 配置角色绑定
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pgA7TdfR-1689141180946)(E:\book\Kubernetes\K8s 常见问题处理.assets\image-20230202155009312.png)]](https://img-blog.csdnimg.cn/5668af6ca7154db0896d27c3c9b91f6c.png)
【31】如何查看某一个namespace下所有的资源?
# 查看minio ns下所有的资源
# 解析: api-resource是查看所有ns下有什么资源类型,然后通过xargs 管道传给kubectl
kubectl api-resources --verbs=list --namespaced -o name | xargs -n 1 kubectl get --show-kind --ignore-not-found -n minio
【32】 ingress 的address 是怎么来的?
2023年7月13日10:08:58
今天看了一眼目前集群的ingress
Ingress 的 address 是由 Kubernetes 集群中的 Ingress Controller 提供的。Ingress Controller 是一个负责处理 Ingress 资源的组件,它会根据 Ingress 的规则将流量路由到相应的 Service。
当您创建一个 Ingress 资源时,Ingress Controller 会根据您定义的规则和配置来创建相应的负载均衡器,并为其分配一个 IP 地址或域名。这个 IP 地址或域名就是 Ingress 的 address。
Ingress Controller 可以使用不同的方式来为 Ingress 分配 address:
- 外部负载均衡器:这一版是公有云上的K8S集群,例如阿里云的ACK、华为云的CCE、腾讯云的TKE, Kubernetes 集群部署在云服务提供商上,Ingress Controller 可以使用云服务提供商的负载均衡器(收费的)来为 Ingress 分配一个外部 IP 地址。
- NodePort:Ingress Controller 也可以使用 NodePort 服务类型来为 Ingress 分配一个集群中节点的端口。这样,您可以通过集群中任意节点的 IP 地址和该端口来访问 Ingress。(有更精妙的办法不用开nodeport,修改Container使用主机网络,直接在主机上开辟 80,443端口,无需中间解析,速度更快;dnsPolicy策略也需要改为主机网络的。 SVC 使用clusterIP就可以了。)
- Hostname:如果您的 Ingress 规则中定义了域名,Ingress Controller 可以将该域名映射到 Ingress 的 address。
这样,您可以通过该域名来访问 Ingress。
需要注意的是,Ingress 的 address 可能需要一些时间来分配和生效。
这个IP是hostIP 还是svc IP 呢?
A集群是SVC IP
[07-13 09:47:07] root@master1:~
$ k get ingress -A
NAMESPACE NAME CLASS HOSTS ADDRESS PORTS AGE
chaos-mesh chaos-dashboard nginx chot-chaos-dashboard.prod.com 10.96.204.41 80 43d
default cafe-ingress nginx cafe.example.com 10.96.204.41 80, 443 160d
default ingress-myapp <none> ingress.test.com 10.96.204.41 80 160d
dev chot-ingress <none> qmsrpt.cecchot.com 80 369d
dev ingress-http <none> nginx.test.com,tomcat.test.com 80 369d
example cloud-eureka <none> cloud-eureka.example.cluster-name.domain.com 80 376d
example web-example <none> web-example.example.demo.kuboard.cn 80 376d
gitlab gitlab <none> chot-gitlab.prod.com 10.96.204.41 80 79d
kuboard kuboard-grafana nginx kuboard-grafana.com 10.96.204.41 80 100d
minio chot-minio nginx chot-minio-web.prod.com 10.96.204.41 80 124d
minio chot-minio-api nginx chot-minio-api.prod.com 10.96.204.41 80 124d
prometheus chot-prometheus-grafana <none> chot-grafana.prod.com 10.96.204.41 80 124d
prometheus chot-prometheus-kube-prome-prometheus nginx chot-prometheus.prod.com 10.96.204.41 80 124d
B集群的ADDRESS 怎么是nodeIP 呢?而且还是两个呢?
k get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-demo-app <none> app.demo.com 10.50.10.22,10.50.10.23 80 65d
ping-new ing-internal hello 80 16h
解决为什么是两个的问题?
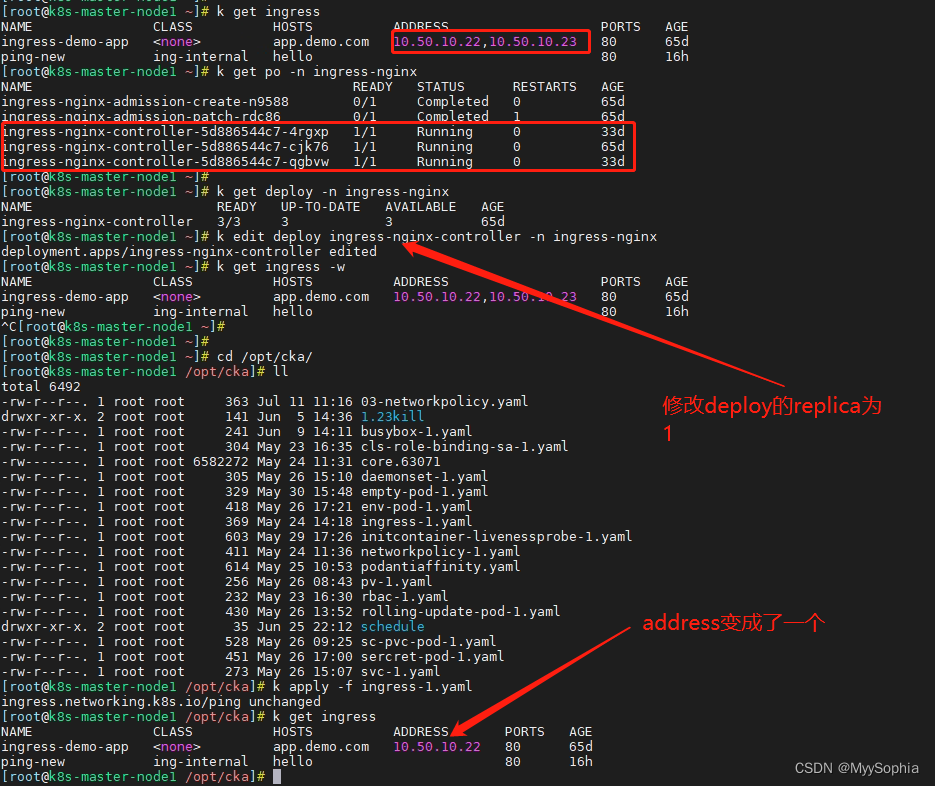
为什么A集群和B集群的IP 类型不一样呢?是哪个参数控制的呢?
A集群的ingress address: SVCIP
B集群的ingress address: nodeIP
刚开始以为A集群的ingress-nginx-controller svc是clusterIP,B集群是NodePort。
然而并不是,A、B两个集群都是nodePort。
A集群ingress-nginx-controller 镜像版本
image: ingress/k8s.gcr.io/ingress-nginx/controller:v1.2.1
B集群ingress-nginx-controller 镜像版本
image: ingress/k8s.gcr.io/ingress-nginx/controller:v1.3.1
[07-13 09:47:10] root@master1:~
$ k get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.96.204.41 <none> 80:32100/TCP,443:32101/TCP 369d
ingress-nginx-controller-admission ClusterIP 10.96.115.62 <none> 443/TCP 369d
# k get svc -ningress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.96.4.41 <none> 80:37157/TCP,443:35931/TCP 65d
ingress-nginx-controller-admission ClusterIP 10.96.4.180 <none> 443/TCP 65d
【33】 pod无法调度,describe 发现报错: MinimumReplicasUnavailable
这个是在一个测试集群中,创建了一个deployment
kubectl create deployment my-dep --image=10.50.10.185/harbortest/nginx:1.7.1 --replicas=3
发现无法创建po,describe deploy后发现如下报错
Type Status Reason
---- ------ ------
Available False MinimumReplicasUnavailable
ReplicaFailure True FailedCreate
Progressing False ProgressDeadlineExceeded
MinimumReplicasUnavailable -> 无法启动 Pod 的最小副本数。这通常是由于资源不足或其他问题导致的. 该集群正在压测,具体看这里三面第一题。
实际上该集群是资源利用率较低并不是资源不足。
ProgressDeadlineExceeded -> Pod 的启动时间超过了指定的时间限制
【34】deployment 创建之后为何无法创建pod?
2023年12月11日10:34:12
背景是进行集群恢复,A集群导出yaml,apply到B集群。
其中几个deploy apply成功,但是pod一直没创建。
- describe deploy
Volumes:
energy-storage-web-nova:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: energy-storage-web-nova
Optional: false
Conditions:
Type Status Reason
Available False MinimumReplicasUnavailable
ReplicaFailure True FailedCreate
Progressing False ProgressDeadlineExceeded
OldReplicaSets:
NewReplicaSet: energy-storage-web-nova-6c97f7cc55 (0/1 replicas created)
Events:
- 到这里不知道咋排查了?没有看到很明显的问题
这时候其实应该另辟蹊径,看看replicaset的状态。 deploy controller 控制replicaset ,replicaset 控制 pod。
看describe replicaset
Events:
Type Reason Age From Message
Warning FailedCreate 8m13s (x311 over 2d19h) replicaset-controller Error creating: pods “energy-storage-web-nova-6c97f7cc55-” is forbidden: error looking up service account ems-plus-demo/energy-storage-web-nova: serviceaccount “energy-storage-web-nova” not found
- 也可以查看ns级别的的event
k get event --namespace ems-plus-demo
LAST SEEN TYPE REASON OBJECT MESSAGE
9m1s Warning FailedCreate replicaset/energy-storage-web-nova-6c97f7cc55 Error creating: pods “energy-storage-web-nova-6c97f7cc55-” is forbidden: error looking up service account ems-plus-demo/energy-storage-web-nova: serviceaccount “energy-storage-web-nova” not found
解决:
这个服务迁移的时候漏掉了sa,迁移的资源类型是自己定义的,迁移前应该先了解应用都包含哪些负载















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











