







一、前言
继上一篇“基于Akshare与Streamlit的股票财务分析实战教程——以贵州茅台(sh600519)为例”https://blog.csdn.net/NAN_YU_LOVE/article/details/146504014?spm=1001.2014.3001.5501。
现在是测试二:从 akshare 获取贵州茅台近五年的市盈率,市净率以及市销率三个估值每日数据,并以五年,三年,一年为周期,计算每个周期的平均值,最大值和最小值,以及周期内最高的 10%和最低的10%数值的平均值,通过 streamlit 在网页展示。
二、相关知识点
-
股票估值指标
-
市盈率(PE):市值 / 净利润,反映投资者对公司盈利能力的预期。
-
市净率(PB):市值 / 净资产,衡量公司资产与股价的关系。
-
市销率(PS):市值 / 营业收入,评估公司收入与股价的合理性。
-
-
数据获取与处理
-
Akshare:中国金融数据接口库,支持股票、基金等数据获取。
-
Pandas:数据处理与分析库,用于合并、清洗和计算数据。
-
-
统计分析
-
时间周期计算:通过
pd.DateOffset实现年、月、日的时间偏移。 -
百分位数计算:使用
nlargest和nsmallest获取最高 / 最低 10% 数据。
-
-
可视化与交互
-
Streamlit:快速构建 Web 应用,支持数据展示与动态交互。
-
三、代码分步解析
步骤 1:导入库
import akshare as ak
import streamlit as st
import pandas as pd
import numpy as np
from datetime import datetime-
akshare:获取股票数据。 -
streamlit:构建 Web 界面。 -
pandas和numpy:数据处理与计算。 -
datetime:处理日期时间。
步骤 2:获取数据
stock = "600519"
end_date = datetime.now()
start_date = end_date - pd.DateOffset(years=5)
def fetch_data(indicator):
df = ak.stock_a_indicator_lg(symbol=stock)
df['trade_date'] = pd.to_datetime(df['trade_date'])
df = df[(df['trade_date'] >= start_date) & (df['trade_date'] <= end_date)]
return df[['trade_date', indicator]]-
逻辑:定义函数
fetch_data获取指定指标(PE/PB/PS)的近 5 年数据。 -
关键点:
-
ak.stock_a_indicator_lg:获取股票估值数据。 -
pd.DateOffset(years=5):计算 5 年前的日期。 -
过滤数据范围,仅保留近 5 年记录。
-
步骤 3:合并数据并清洗
df_pe = fetch_data("pe")
df_pb = fetch_data("pb")
df_ps = fetch_data("ps")
df = pd.merge(df_pe, df_pb, on='trade_date', how='outer')
df = pd.merge(df, df_ps, on='trade_date', how='outer')
df = df.sort_values('trade_date').ffill().dropna()
df = df.rename(columns={'trade_date':'日期','pe':'市盈率','pb':'市净率','ps':'市销率'})-
逻辑:
-
分别获取 PE、PB、PS 数据。
-
通过
pd.merge合并三张表。 -
ffill()填充缺失值,dropna()删除无效行。 -
重命名列名以提高可读性。
-
步骤 4:计算统计指标
def calculate_stats(data, indicator):
stats = {}
stats['平均值'] = data[indicator].mean()
stats['最大值'] = data[indicator].max()
stats['最小值'] = data[indicator].min()
n = len(data)
k_high = max(1, int(np.ceil(n * 0.1)))
k_low = max(1, int(np.ceil(n * 0.1)))
stats['高10%平均值'] = data.nlargest(k_high, indicator)[indicator].mean()
stats['低10%平均值'] = data.nsmallest(k_low, indicator)[indicator].mean()
return stats-
逻辑:
-
计算平均值、最大值、最小值。
-
使用
nlargest和nsmallest获取最高 / 最低 10% 数据的平均值。 -
np.ceil(n * 0.1)确保至少取 1 条数据(当数据量较小时)。
-
步骤 5:定义时间周期
latest_date = df['日期'].max()
periods = {
'五年': latest_date - pd.DateOffset(years=5),
'三年': latest_date - pd.DateOffset(years=3),
'一年': latest_date - pd.DateOffset(years=1),
}-
逻辑:根据当前日期计算五年、三年、一年前的截止日期。
步骤 6:遍历计算结果
results = {}
for indicator in ['市盈率', '市净率', '市销率']:
results[indicator] = {}
for period_name, cutoff_date in periods.items():
period_data = df[df['日期'] >= cutoff_date]
if not period_data.empty:
results[indicator][period_name] = calculate_stats(period_data, indicator)-
逻辑:
-
遍历每个指标(PE/PB/PS)。
-
对每个指标计算不同周期(五年 / 三年 / 一年)的统计值。
-
结果存储在嵌套字典
results中。
-
步骤 7:Streamlit 展示结果
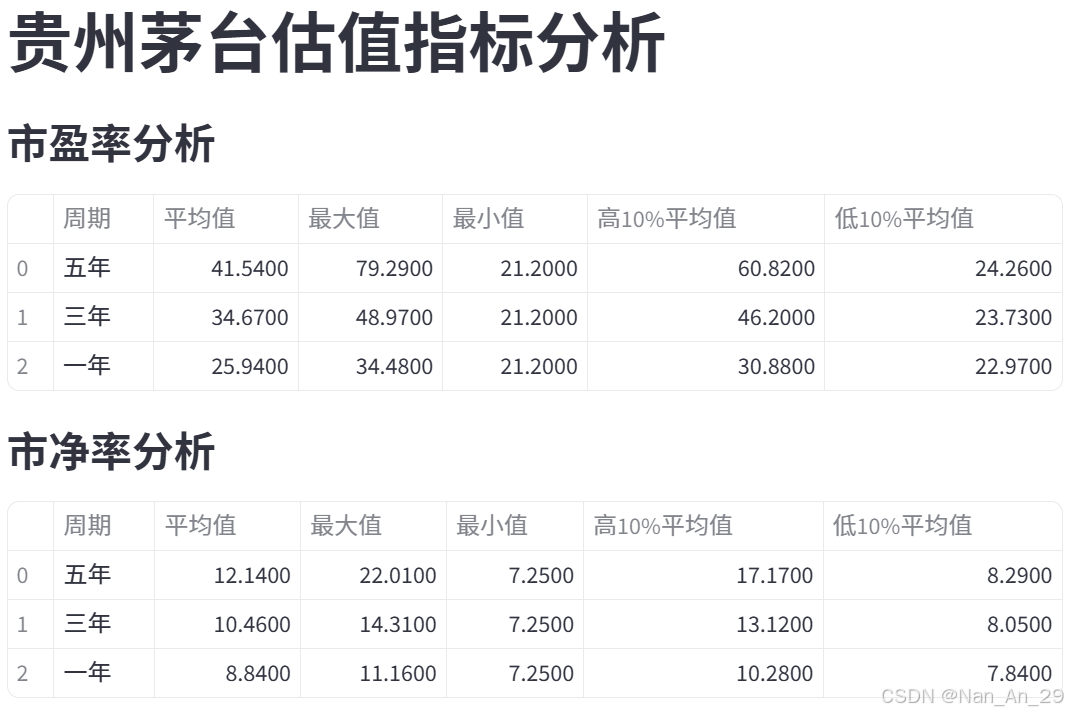
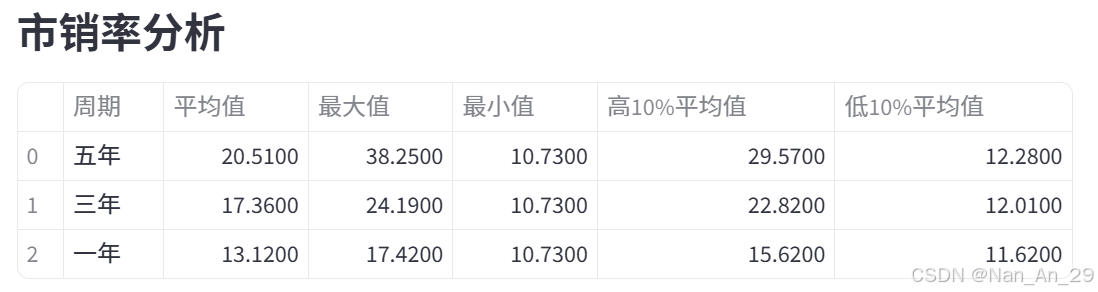
st.title("贵州茅台估值指标分析")
for indicator in ['市盈率', '市净率', '市销率']:
st.subheader(f"{indicator}分析")
data = []
for period in ['五年', '三年', '一年']:
if period not in results[indicator]:
continue
stats = results[indicator][period]
row = {
'周期': period,
'平均值': round(stats['平均值'], 2),
'最大值': round(stats['最大值'], 2),
'最小值': round(stats['最小值'], 2),
'高10%平均值': round(stats['高10%平均值'], 2),
'低10%平均值': round(stats['低10%平均值'], 2),
}
data.append(row)
if data:
df_display = pd.DataFrame(data)
st.table(df_display)
else:
st.write("无可用数据")-
逻辑:
-
使用
st.title和st.subheader定义页面标题。 -
通过循环将统计结果整理为 DataFrame,并使用
st.table展示。 -
结果保留两位小数,提升可读性。
-
四、结果示例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









