







图的存储
- 邻接矩阵
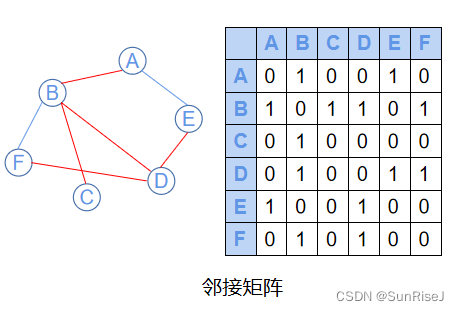
G[a][b] = 1表示从a到b有一条边,其中值也可以定义为边的权值
使用场景:当点的数量级比较小:为n,而边的数量级达到了n^2时,该图被称为稠密图,这时的存储形式应当使用邻接矩阵。
Dijkstra算法普通版:用于稠密图表示的邻接矩阵,来求单源最短路(从一个点到其他任意点的最短距离)。
算法思想:基于贪心,每次寻找当前能够到达的最短路径的点,再用该点去更新到达其他未找到最短路径的点。接下来再次循环,寻找当前能够到达的最短路径的点……由于每次都找到的是当前所到达的最短路径,因此到达每个点的距离均是最短的。
算法步骤:
- 初始化距离,1号点距离为0,其他点的距离为 +∞。
- 遍历所有点,寻找能够到达最近距离的点,加入已找到路径的集合。
- 用找到的点去更新剩余点的距离,2-3循环n次,即找到n个点的路径
算法代码:
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for(int i=0;i<n;i++)
{
int t = -1;
for(int j=1; j<=n; j++)
{
if(!st[j] && (t==-1 || dist[t]>dist[j]))
{
t = j;
}
}
st[t] = true;
for(int j=1; j<=n; j++)
{
dist[j] = min(dist[j],dist[t] + g[t][j]);
}
}
if(dist[n] == 0x3f3f3f3f) return -1;
else return dist[n];
}
- 邻接表
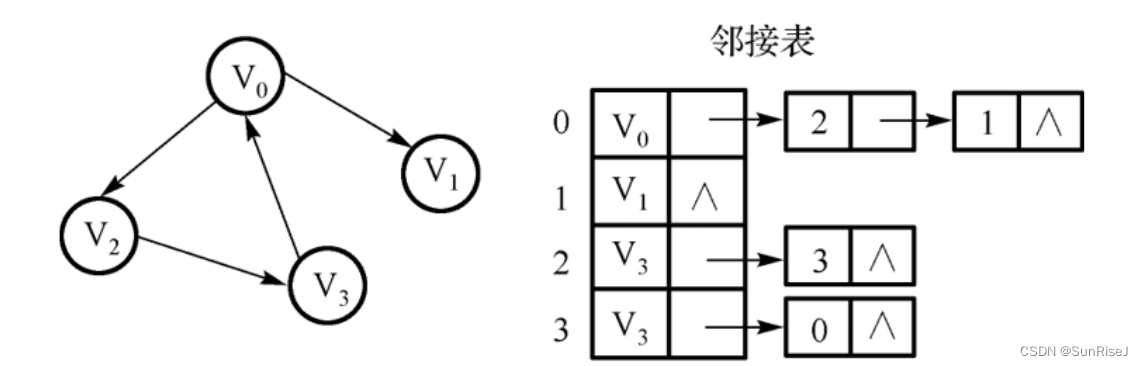
定义:为每一个点开一个单链表,存储的是这个点可以到达的点有哪些。
注意:在定义数据结构的时候,对于无向图,使用数组模拟邻接表。如果N:点的个数,则M:边的个数最大要为2N,因此开的数组长度,边要为点的二倍。
使用场景:用来存放稀疏图,即点数和边数的数量级基本一致。
邻接表在BFS和DFS中的应用:
在宽度遍历和深度遍历方法遍历图时,通常情况下是每个点只需要遍历一次,因此需要使用状态数组st[N]来存储是否该点已经遍历过了。
图的遍历和搜索的对比:图的遍历和之前讲过的搜索中,使用的算法思想是一致的,区别在于图的遍历是一次性的,不需要进行现场的恢复,而搜索中,由于需要记录下每次达到条件的状态,从而判断是否该状态需要进行输出或返回,因此需要进行现场的恢复,来保证每次的状态不受之前搜索到的状态的影响。
Dijkstra算法堆优化版:
优化原理:由于在简单版中是用于稠密图的邻接矩阵,在寻找当前最短距离的点时,是遍历所有点的dist来寻找的。但该步骤求的是最短边,因此可以使用一个heap来维护当前未加入集合的点,与已在集合中点,所共同参与边的最小值。Heap.top即最小值。由于我们获取最短边时,还需要获取该点是什么,因此用pair<int, int>作为堆元素的数据结构。第一个int为distance,用于排序,第二个Int作为点的序号。
算法步骤:
- 初始化距离,1号点距离为0,其他点的距离为 +∞。构建堆,将1号点加入堆中。
- 当heap不空时,取堆顶元素,即距离最小值。
- 判断是否已经在集合中,若在continue,若不在,加入集合
- 用该点来更新该点链条所到达点的距离。从2继续循环,直到heap空。
算法代码:
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;
heap.push({0,1});
while(heap.size())
{
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if(st[ver]) continue;
st[ver] = true;
for(int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if(dist[j] > distance + w[i])
{
dist[j] = distance + w[i];
heap.push({dist[j], j});
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









