







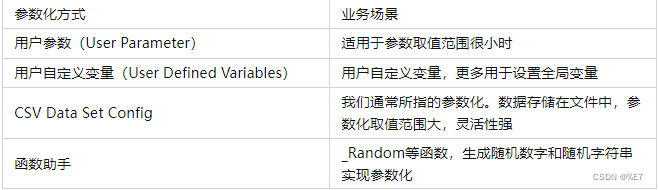
我们在做接口自动化测试时,通常把输入数据用参数来替代,然后在脚本执行时,根据需要选取不同的参数值作为输入值。
下面介绍 jmeter 提供的4种参数化方式:
01
用户参数
1.添加用户参数
右击(如测试计划、线程组、http请求等)> 添加 > 前置处理器 > 用户参数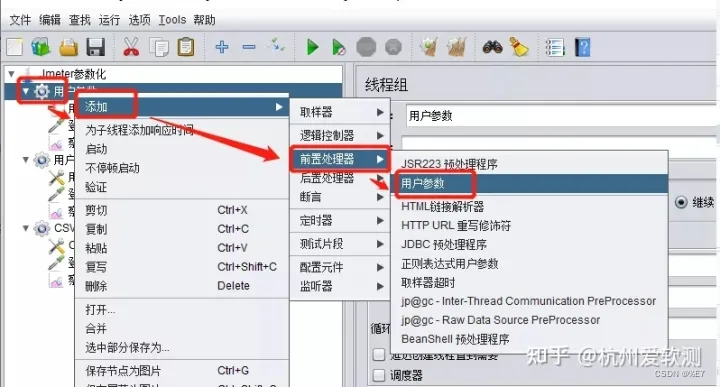
2.设置参数
通过【添加变量】添加 account 和password两个变量: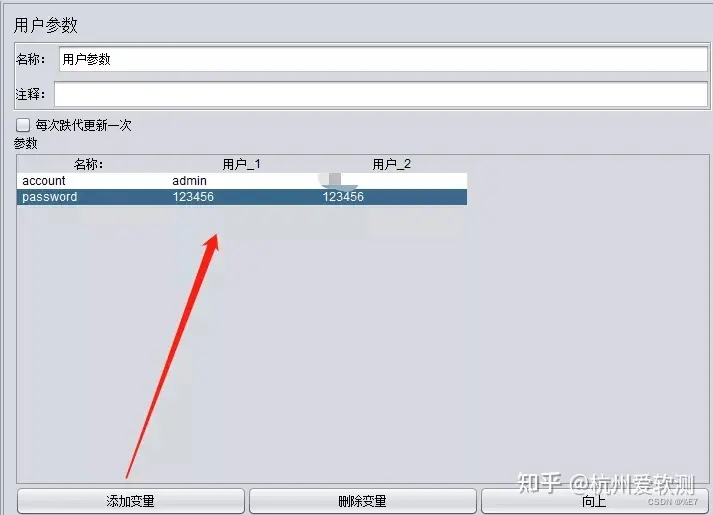
3.参数引用
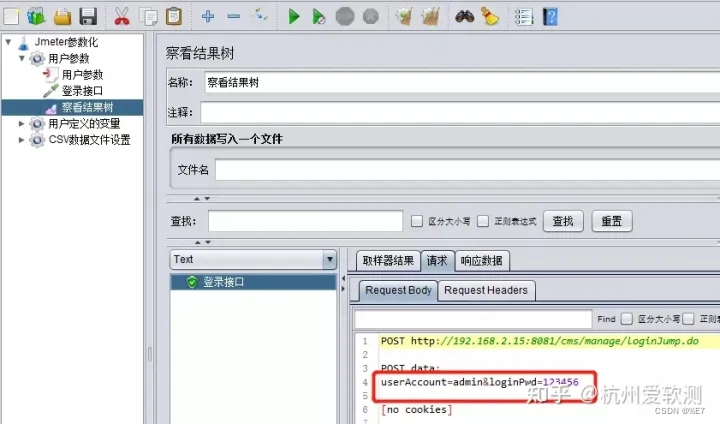
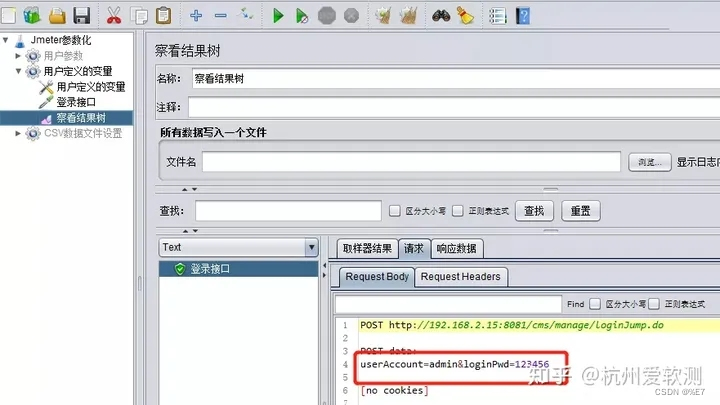
在接口请求参数中通过**${变量名}**的方式来引用变量: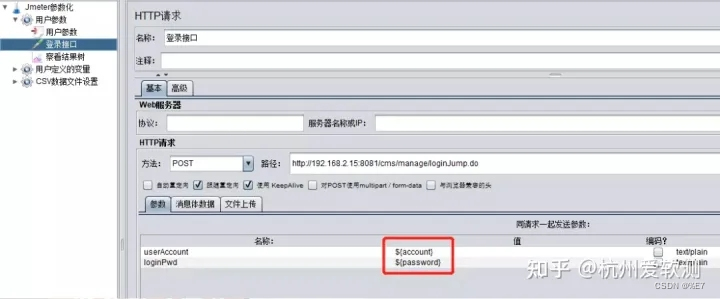
由于在【用户参数】中添加了两组数据,而线程组中的线程数只设置了1个,那么执行登录接口的时候取的值为第一组数据(admin/123456)。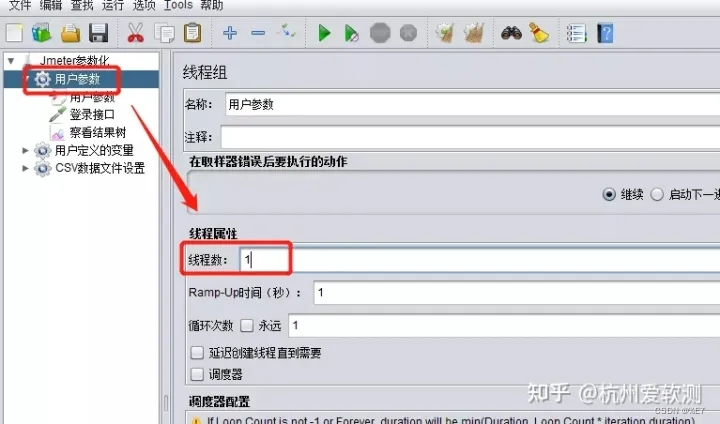
总结:
这种参数化方式较简单,但数据范围有限,适用场景也少。
02
用户自定义变量
1.添加用户定义的变量
右击(如测试计划、线程组、http请求等)> 添加 > 配置元件 > 用户定义的变量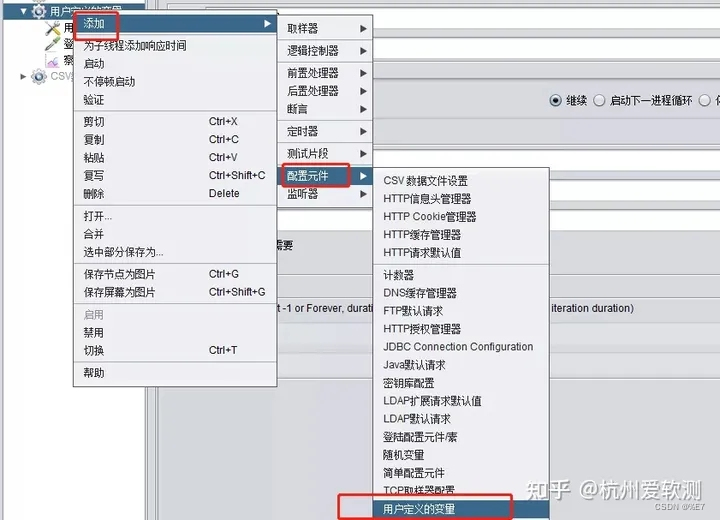
2.添加变量
点击页面下方的【添加】按钮,变量列表中会新增一行,名称一栏中填写变量名,值一栏中填写对应的值,描述一栏可以填写描述(非必填)。
3.引用变量
在登录接口请求参数中通过**${变量名}**的方式来引用变量。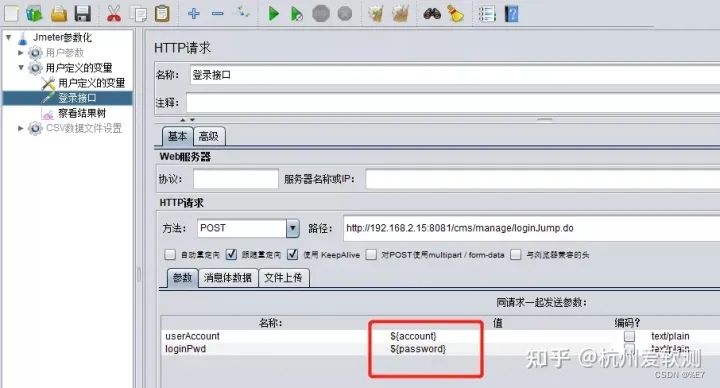
总结:
【用户定义的变量】一般并非用来做HTTP请求参数化,而是用来定义全局变量,比如参数化文件路径、host、url等。
如果创建在“线程组”上,则在线程组内生效,创建在“测试计划”上,则对所有线程组生效。
03
CVS 数据文件设置
1.添加CSV数据文件设置
右击(如测试计划、线程组、http请求等)> 添加 > 配置元件 > CSV数据文件设置
2.CSV页面参数介绍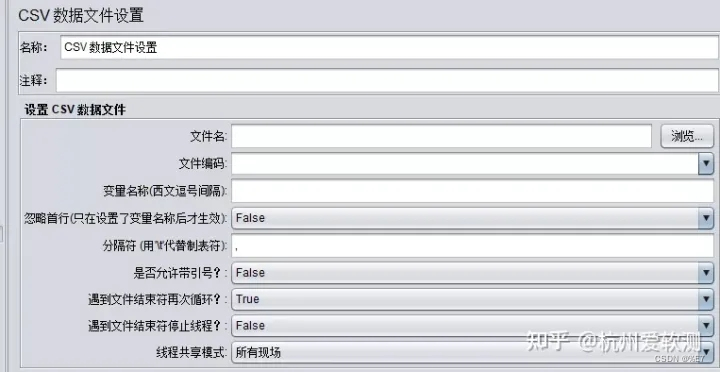
各项参数详解:
| 参数 | 描述 | 是否必填 |
| 名称 | 脚本中显示的这个元件的描述性名称 | 是 |
| 文件名 | 待读取文件的名称。可以写入绝对路径,也可以写入相对路径(相对于bin目录),如果直接写文件名,则该文件要放在bin目录中。对于分布式测试,主机和远程机中相应目录下应该有相同的CSV文件 | 是 |
| 文件编码 | 文件读取时的编码格式,不填则使用操作系统的编码格式 | 否 |
| 变量名称 | 多个变量名之间必须用分隔符分开,如果该项为空,则文件首行会被读取并解析为列表 | 否 |
| 忽略首行 | csv文件中没有表头,则选择false | 是 |
| 分隔符 | 将一行数据分隔成多个变量,默认为逗号,也可以使用“\t”。如果一行数据分隔后的值比用户自定义中的变量少,这些变量将保留以前的值。 | 是 |
| 是否允许变量使用双引号? | 允许的话,变量将可以括在双引号内,并且这些变量名可以包含分隔符 | 否 |
| 遇到文件结束符是否再次循环? | 默认为 true | 是 |
| 遇到文件结束符是否停止线程? | 默认为 true | 是 |
| 线程共享模式 | 1、All threads(默认):一个线程组内,各个线程(用户)唯一顺序取值;2、current thread:一个线程组内,各个线程(用户)各自顺序取值;3、Current thread group:线程组各自独立,但每个线程组内各个线程(用户)唯一顺序取值; | 是 |
2.参数化文件
将account文件放置到bin目录下,在【设置CSV数据文件】中导入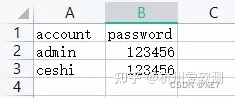
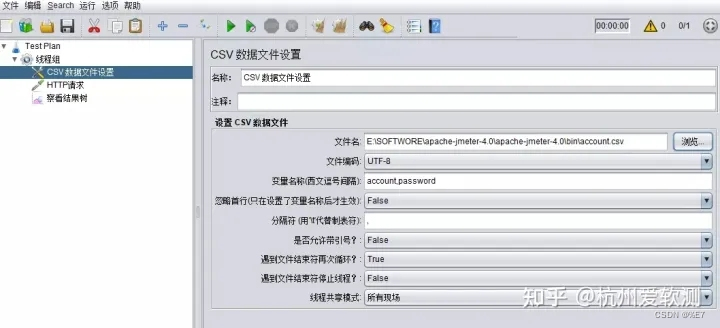
- 文件名:点击“浏览”,在bin目录下选择文件路径
- 变量名称:两列数据分别为 account 和 password 两个变量
- 分隔符:以逗号分开
3.引用变量
在接口请求参数中通过**${变量名}**的方式来引用变量。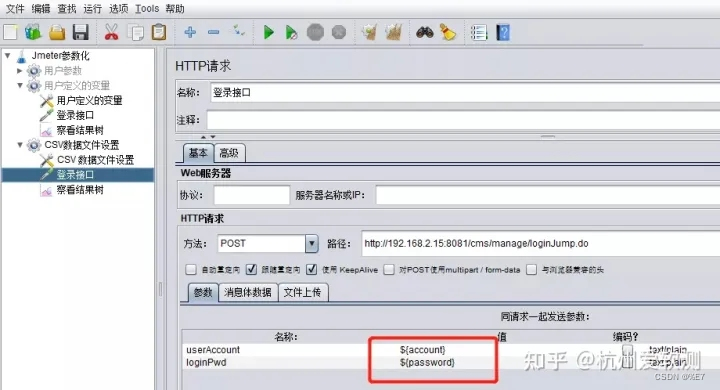
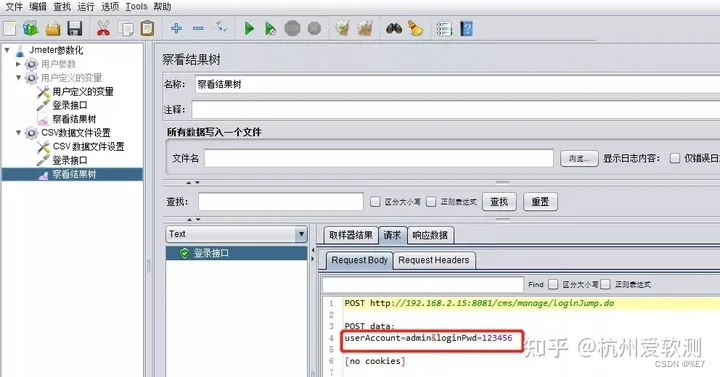
总结:
【CSV数据文件设置】是常用的数据参数化方式,它能够读取文件中的数据并生成变量,被JMeter脚本引用。
04
函数助手
1.创建random函数
选项 > 函数助手对话框 > 选择一个功能 > _Random:
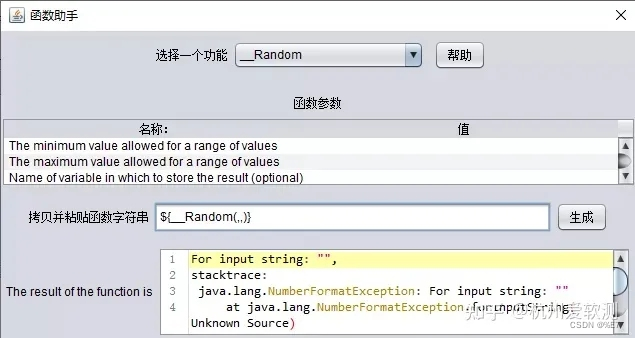
2.设置random随机数
设置数据区间范围,点击【生成】按钮,生成一个随机表达式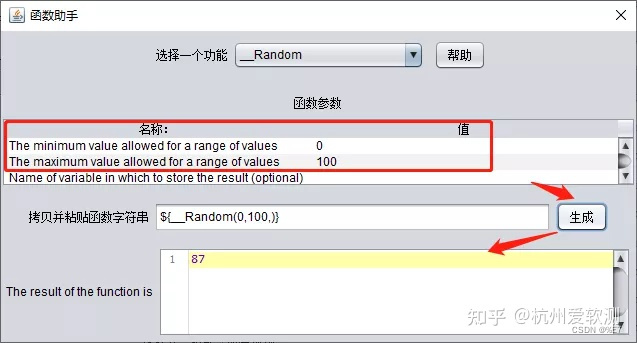
3.引用参数
使用上一步生成的表达式替换参数化的变量值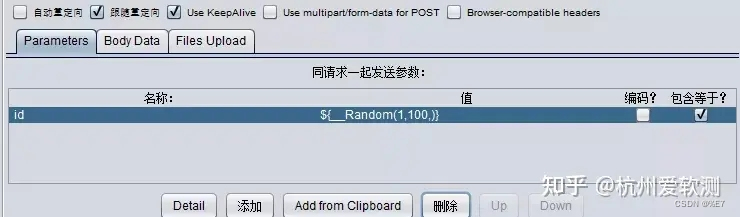
总结:
当参数为随机数时,可使用函数助手生成所需数据,当所需字段数据长度较长且不能重复时,通常将时间函数与计数器结合,拼接为合适长度的有效数据.
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!


















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









