







https://github.com/claire360/Dify-Learing
文章目录
儿童故事绘本文生视频语音合成版
本工作流主要是实现儿童故事绘本文本分镜提示词,通过分镜提示词生成图片,然后把后端图片和语音合成一个动画视频功能
代码解析
models/const.py
该文件定义了一些常量和枚举类型,用于统一管理故事类型、图片风格、支持的语言等信息。
from enum import Enum
class StoryType(str, Enum):
custom = "custom" # 自定义故事
bedtime = "bedtime" # 睡前故事
fairy_tale = "fairy_tale" # 童话故事
adventure = "adventure" # 冒险故事
science = "science" # 科普故事
moral = "moral" # 寓言故事
class ImageStyle(str, Enum):
realistic = "realistic" # 写实风格
cartoon = "cartoon" # 卡通风格
watercolor = "watercolor" # 水彩风格
oil_painting = "oil_painting" # 油画风格
class Language(str, Enum):
CHINESE_CN = "zh-CN" # 中文(简体)
CHINESE_TW = "zh-TW" # 中文(繁体)
ENGLISH_US = "en-US" # 英语(美国)
JAPANESE = "ja-JP" # 日语
KOREAN = "ko-KR" # 韩语
# 语言名称映射
LANGUAGE_NAMES = {
Language.CHINESE_CN: "中文(简体)",
Language.CHINESE_TW: "中文(繁体)",
Language.ENGLISH_US: "English",
Language.JAPANESE: "日本語",
Language.KOREAN: "한국어"
}
schemas
llm.py
from pydantic import BaseModel, Field
from typing import List, Dict, Any
from models.const import Language
from typing import Optional
# 故事生成的设置
class StoryGenerationRequest(BaseModel):
resolution: Optional[str] = Field(default="1024*1024", description="分辨率")
text_llm_provider: Optional[str] = Field(default=None, description="Text LLM provider")
text_llm_model: Optional[str] = Field(default=None, description="Text LLM model")
image_llm_provider: Optional[str] = Field(default=None, description="Image LLM provider")
image_llm_model: Optional[str] = Field(default=None, description="Image LLM model")
segments: int = Field(..., ge=1, le=10, description="Number of story segments to generate")
story_prompt: str = Field(..., min_length=1, max_length=4000, description="Theme or topic of the story")
language: Language = Field(default=Language.CHINESE_CN, description="Story language")
# 故事分镜
class StorySegment(BaseModel):
text: str = Field(..., description="Story text")
image_prompt: str = Field(..., description="Image generation prompt")
url: str = Field(None, description="Generated image URL")
# 故事生成请求
class StoryGenerationResponse(BaseModel):
segments: List[StorySegment] = Field(..., description="Generated story segments")
# 图像生成请求模型类
class ImageGenerationRequest(BaseModel):
prompt: str = Field(..., min_length=1, max_length=4000, description="Description of the image to generate")
image_llm_provider: Optional[str] = Field(default=None, description="Image LLM provider")
image_llm_model: Optional[str] = Field(default=None, description="Image LLM model")
resolution: Optional[str] = Field(default="1024*1024", description="Image resolution")
# 图像生成响应模型类
class ImageGenerationResponse(BaseModel):
image_url: str = Field(..., description="Generated image URL")
video.py
video.py: 定义了与视频生成相关的数据结构
enum
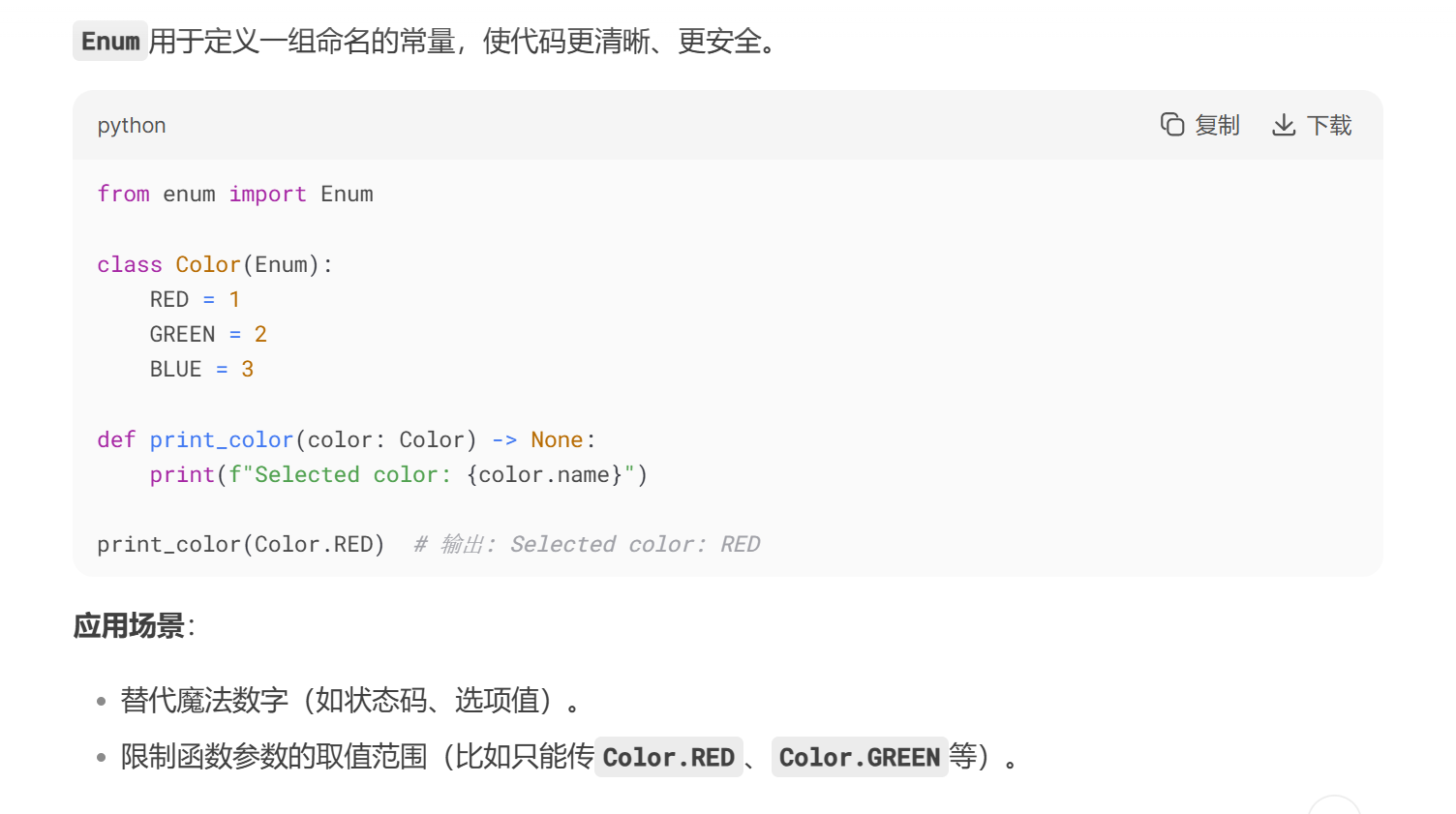
from enum import Enum:从 enum 模块导入 Enum 类,用于定义枚举类型。枚举类型可以将一组相关的常量组织在一起,提高代码的可读性和可维护性。
typing
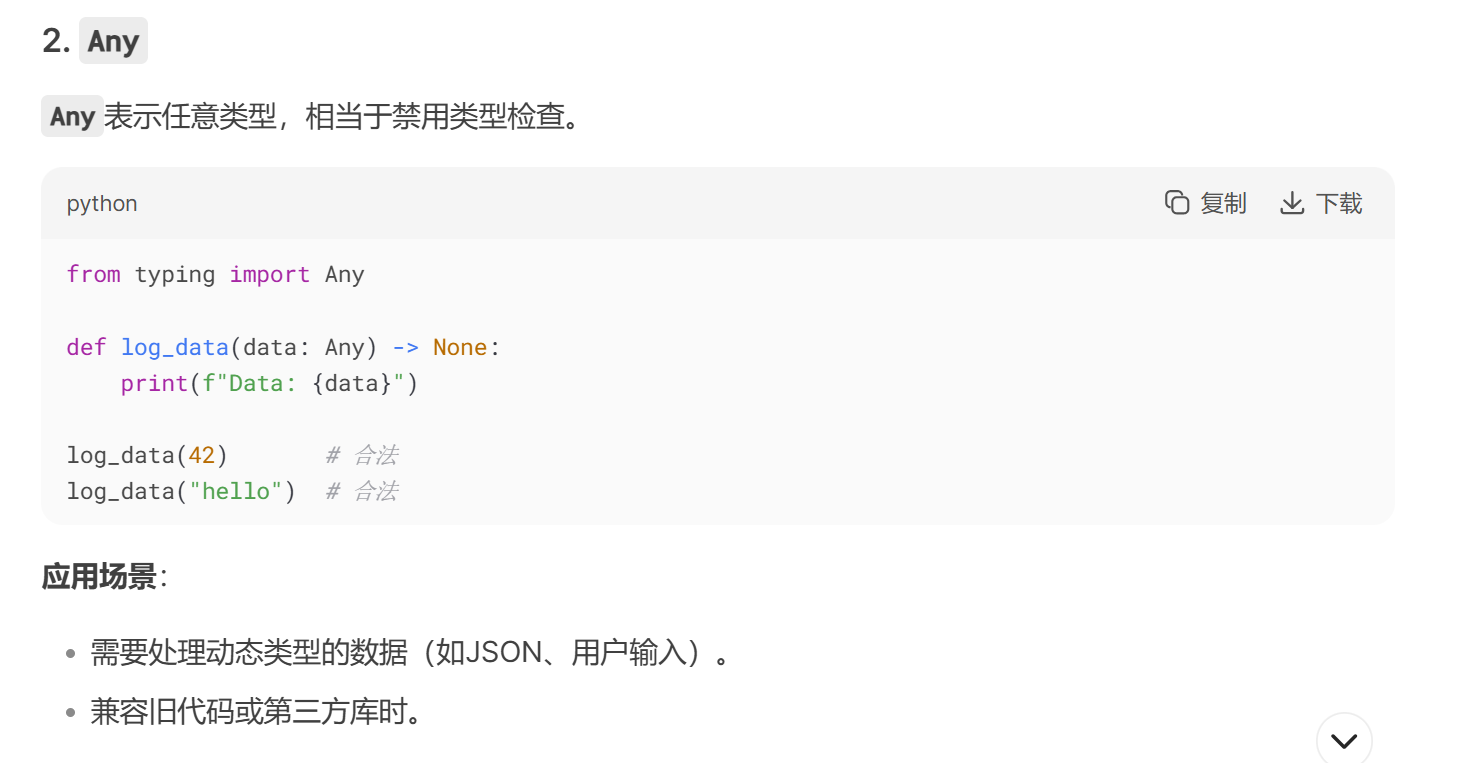
from typing import Any, List, Optional, Union, Dict:从 typing 模块导入类型注解相关的类。Any 表示任意类型,List 用于表示列表类型,Optional 表示该类型可以是指定类型或者 None,Union 用于表示联合类型,Dict 用于表示字典类型。
pydantic
https://zhuanlan.zhihu.com/p/387492501

忽略特定警告
# 忽略 Pydantic 的特定警告
warnings.filterwarnings(
"ignore",
category=UserWarning,
message="Field name.*shadows an attribute in parent.*",
)
定义枚举类型
class VideoConcatMode(str, Enum):
random = "random"
sequential = "sequential"
class VideoAspect(str, Enum):
landscape = "16:9"
portrait = "9:16"
square = "1:1"
def to_resolution(self):
if self == VideoAspect.landscape.value:
return 1920, 1080
elif self == VideoAspect.portrait.value:
return 1080, 1920
elif self == VideoAspect.square.value:
return 1080, 1080
return 1080, 1920
class VideoAspect(str, Enum):定义一个名为 VideoAspect 的枚举类,继承自 str 和 Enum,表示视频的纵横比。
landscape = "16:9"、portrait = "9:16" 和 square = "1:1":定义枚举的三个值,分别表示横向(16:9)、纵向(9:16)和方形(1:1)的纵横比。
def to_resolution(self):定义一个实例方法 to_resolution,用于根据枚举值返回对应的视频分辨率。根据不同的纵横比返回不同的分辨率,默认返回纵向的分辨率(1080, 1920)。
api
video.py: 定义了与视频生成相关的 API 路由,通过 FastAPI 框架提供对外服务。
读取配置文件
这部分代码是导入所需的模块和函数:
fastapi 相关导入:
APIRouter:用于创建 API 路由的类。
HTTPException:用于在 API 中抛出 HTTP 异常。
Query:用于处理查询参数。
Header:用于获取 HTTP 请求头。
Depends:用于依赖注入。
loguru.logger:用于日志记录的工具。
services.video 模块中的函数:generate_video、create_video_with_scenes 和 generate_voice,这些函数可能用于视频生成、场景创建和语音生成。
schemas.video 模块中的类:VideoGenerateRequest、VideoGenerateResponse 和 StoryScene,用于定义请求和响应的数据结构。
os 模块:提供了与操作系统进行交互的功能。
json 模块:用于处理 JSON 数据。
utils.utils 模块中的 extract_id 函数,可能用于提取 ID。
configparser 模块:用于读取配置文件。
router = APIRouter()
创建一个 APIRouter 实例,用于定义和组织 API 路由。
有什么用呢?
router = APIRouter() 是 FastAPI 中用于组织和管理路由(API 端点)的核心工具,它的作用类似于 Flask 中的 Blueprint 或 Django 中的 urls.py。通过 APIRouter(),你可以将大型项目的 API 拆分为多个模块化组件,提升代码的可维护性和可扩展性。
@router.post("/story/generatestory")
async def generate_video_endpoint(
request: VideoGenerateRequest,
auth_token: str = Depends(verify_auth_token)
):
"""生成视频"""
try:
video_file = await generate_video(request)
video_url = video_file
print("video_url::::"+video_url)
return VideoGenerateResponse(
success=True,
data={"video_url": video_url}
)
except Exception as e:
logger.error(f"Failed to generate video: {str(e)}")
return VideoGenerateResponse(
success=False,
message=str(e)
)
使用 @router.post 装饰器定义一个 POST 请求的 API 路由,路径为 /story/generatestory。
定义一个异步函数 generate_video_endpoint,用于处理视频生成请求。
函数接受两个参数:
request:类型为 VideoGenerateRequest,表示视频生成请求的数据。
auth_token:通过依赖注入调用 verify_auth_token 函数进行令牌验证。
尝试调用 generate_video 函数生成视频文件,并将其赋值给 video_file。
将 video_file 赋值给 video_url。
打印视频 URL。
如果视频生成成功,返回一个 VideoGenerateResponse 对象,包含 success 为 True 和视频 URL。
如果发生异常,记录错误日志并返回一个 VideoGenerateResponse 对象,包含 success 为 False 和错误消息。
这个auth valid_tokens 是在哪得到的,填的是什么呢?
这个auth valid_tokens 是在哪得到的,填的是什么呢?
[auth] 部分的 valid_tokens 是自定义的有效令牌列表,用于 API 鉴权。你可以手动生成令牌或从第三方服务获取令牌,并将其添加到列表中。客户端在调用 API 时需要在请求头中提供有效的令牌,服务端会对其进行验证。
teststoryvideo.py
该文件提供了一个测试客户端 StoryVideoClient,用于测试视频生成功能。

storymain.py
该文件是项目的入口文件,使用 FastAPI 框架启动一个 Web 服务,并挂载视频生成相关的路由。
整体流程
整体流程
用户通过 StoryVideoClient 发起视频生成请求,传入故事提示、分段数、语言等参数。
StoryVideoClient 向服务端发送 HTTP 请求,请求地址为 /story/generatestory。
服务端接收到请求后,根据测试模式的不同进行处理:
测试模式:从 story.json 文件中读取数据。
非测试模式:调用 LLMService 生成故事场景和配图,下载图片并保存故事数据到 story.json 文件。
最后,调用 create_video_with_scenes 函数生成视频。
.ttc

zh-CN-XiaoxiaoNeural
文字转语音的包

提示
文字和图片的返回形式都已经定义好了
async def _get_story_prompt(self, story_prompt: str = None, language: Language = Language.CHINESE_CN, segments: int = 3) -> str:
"""生成故事提示词
Args:
story_prompt (str, optional): 故事提示. Defaults to None.
segments (int, optional): 故事分段数. Defaults to 3.
Returns:
str: 完整的提示词
"""
languageValue = LANGUAGE_NAMES[language]
if story_prompt:
base_prompt = f"讲一个故事,主题是:{story_prompt}"
return f"""
{base_prompt}. The story needs to be divided into {segments} scenes, and each scene must include descriptive text and an image prompt.
Please return the result in the following JSON format, where the key `list` contains an array of objects:
**Expected JSON format**:
{{
"list": [
{{
"text": "Descriptive text for the scene",
"image_prompt": "Detailed image generation prompt, described in English"
}},
{{
"text": "Another scene description text",
"image_prompt": "Another detailed image generation prompt in English"
}}
]
}}
**Requirements**:
1. The root object must contain a key named `list`, and its value must be an array of scene objects.
2. Each object in the `list` array must include:
- `text`: A descriptive text for the scene, written in {languageValue}.
- `image_prompt`: A detailed prompt for generating an image, written in English.
3. Ensure the JSON format matches the above example exactly. Avoid extra fields or incorrect key names like `cimage_prompt` or `inage_prompt`.
**Important**:
- If there is only one scene, the array under `list` should contain a single object.
- The output must be a valid JSON object. Do not include explanations, comments, or additional content outside the JSON.
Example output:
{{
"list": [
{{
"text": "Scene description text",
"image_prompt": "Detailed image generation prompt in English"
}}
]
}}
"""
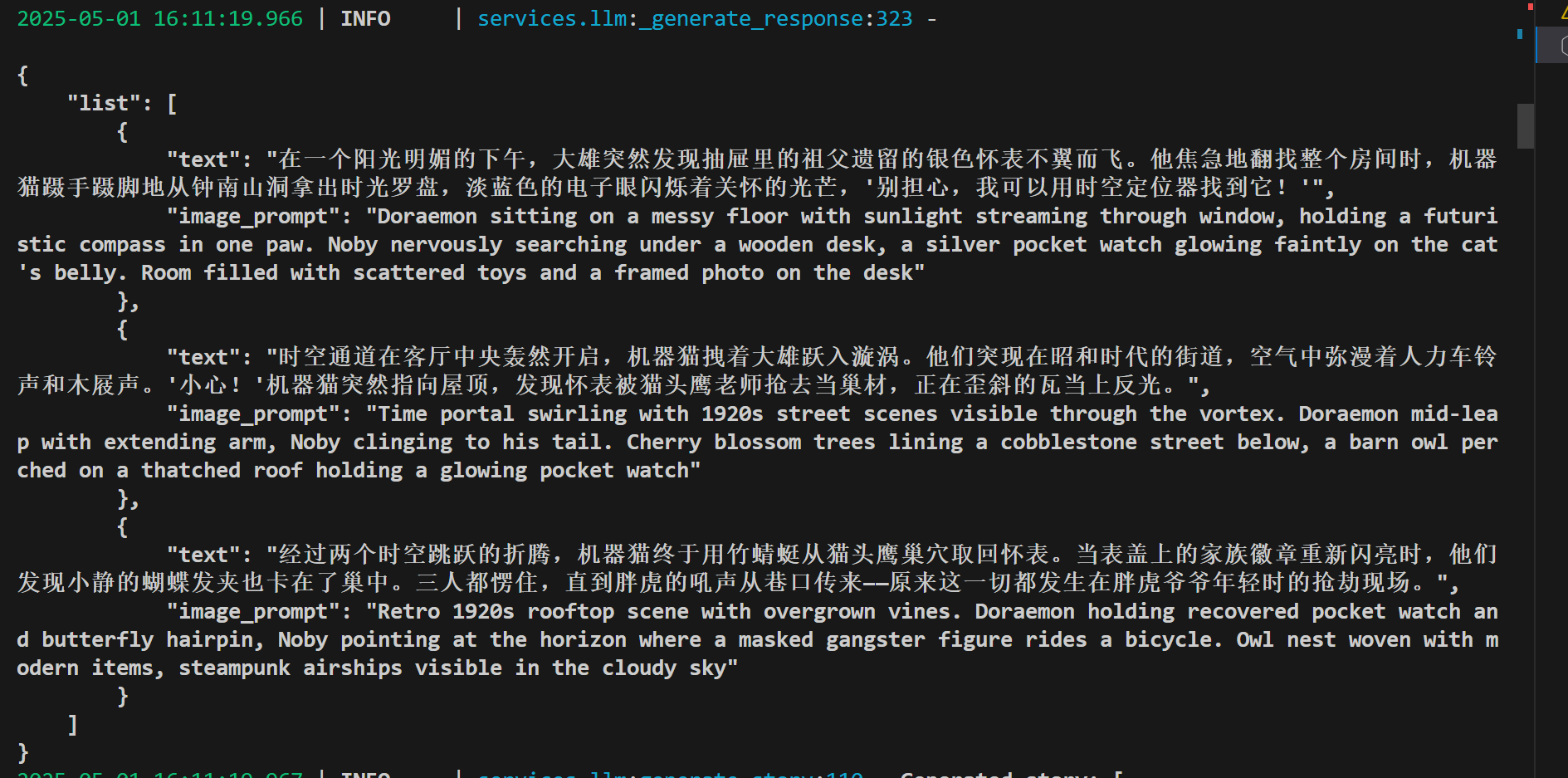
生成故事情节和每个情节对应的图片描述(英文)
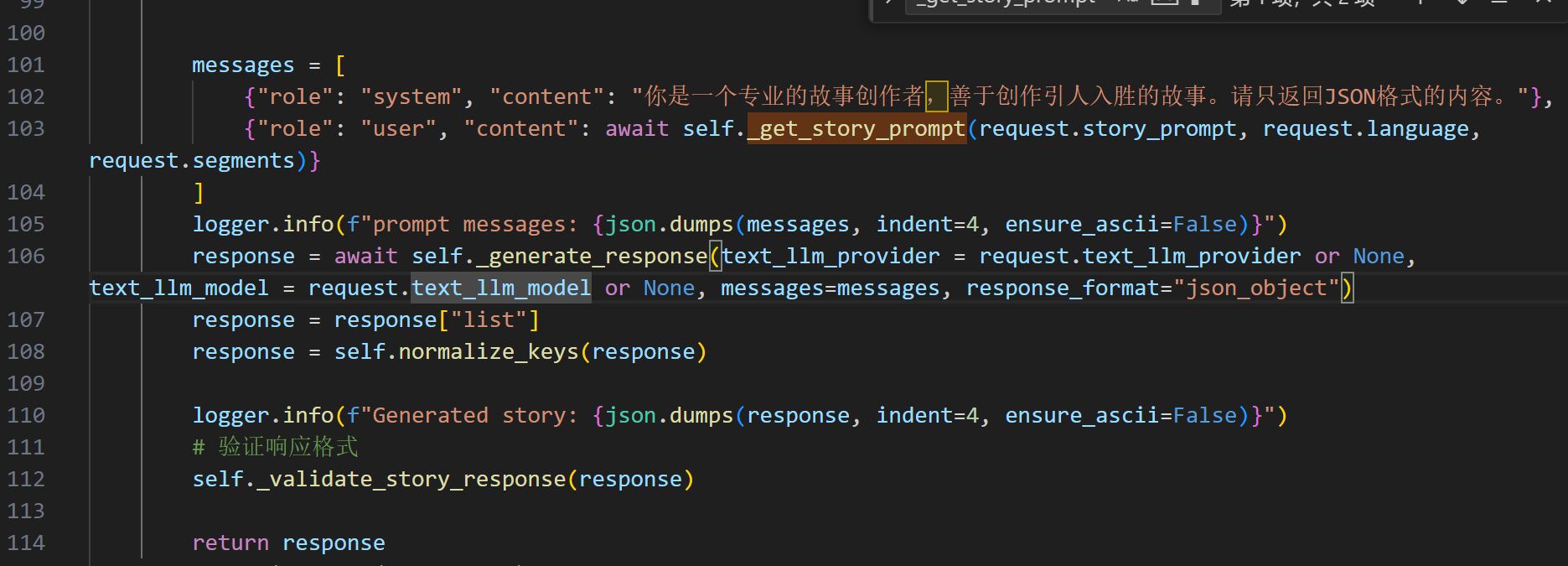
开始生成每个视频的场景
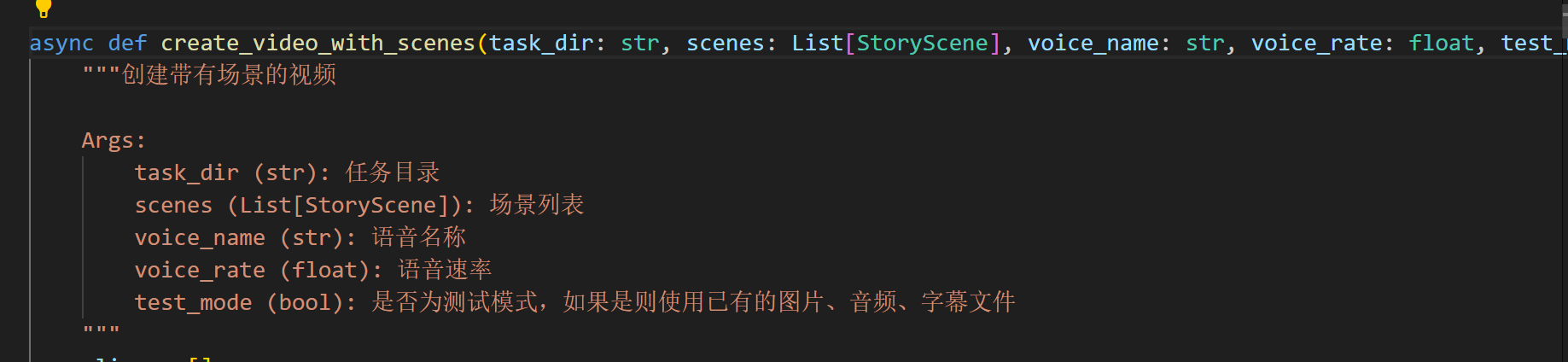
.srt是什么文件
.srt 是一种常见的 字幕文件格式(SubRip Subtitle),主要用于存储视频的文本字幕信息。它的特点是纯文本、结构简单,被广泛用于视频播放器、剪辑软件和流媒体平台。
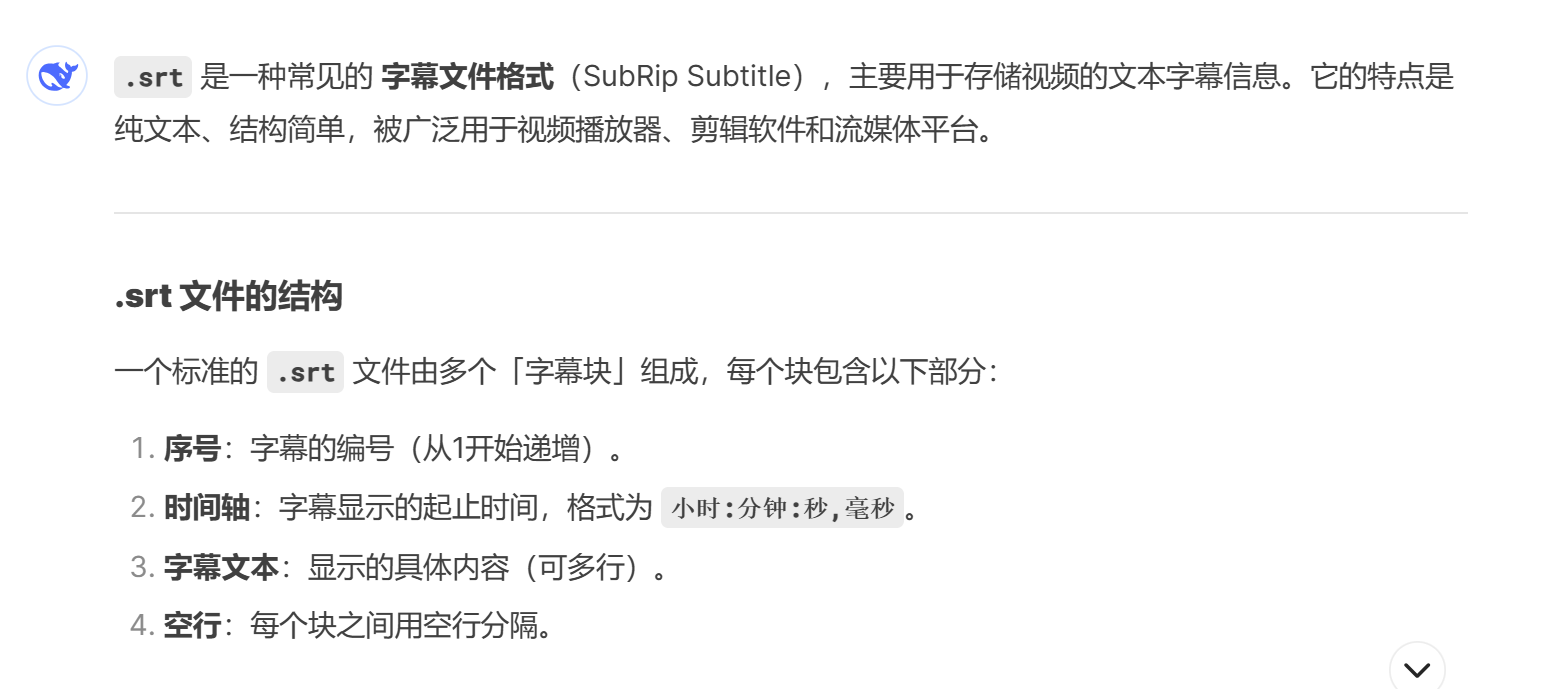
合成了所有的片段
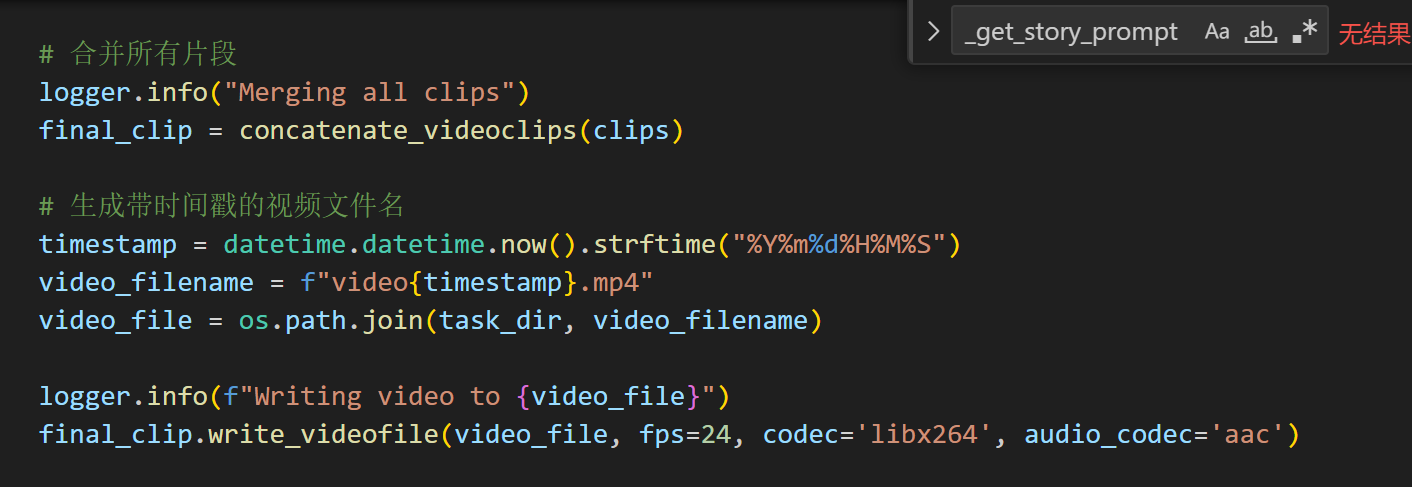
返回了生成视频的地址-我没有上传到腾讯COS,因为又要注册,感觉可能还要花钱,我觉得没这个必要。
生成视频
保存图片
开始配置进行debug吧
问题1:ini是什么东西+如何传入代码里面的
config.ini
.ini 文件是一种常见的 配置文件格式(扩展名为 .ini),用于存储程序的配置参数(如数据库连接、路径设置等)。它的结构简单、易读,通常由 节(Section)、键(Key) 和 值(Value) 组成。Python 中可以通过标准库 configparser 或第三方库(如 pydantic)来解析和传入配置。

import configparser
# 读取配置文件中的API密钥
config = configparser.ConfigParser()
这是什么意思

我还好奇为什么要用腾讯的COS,这里没有出现调用[common]的地方
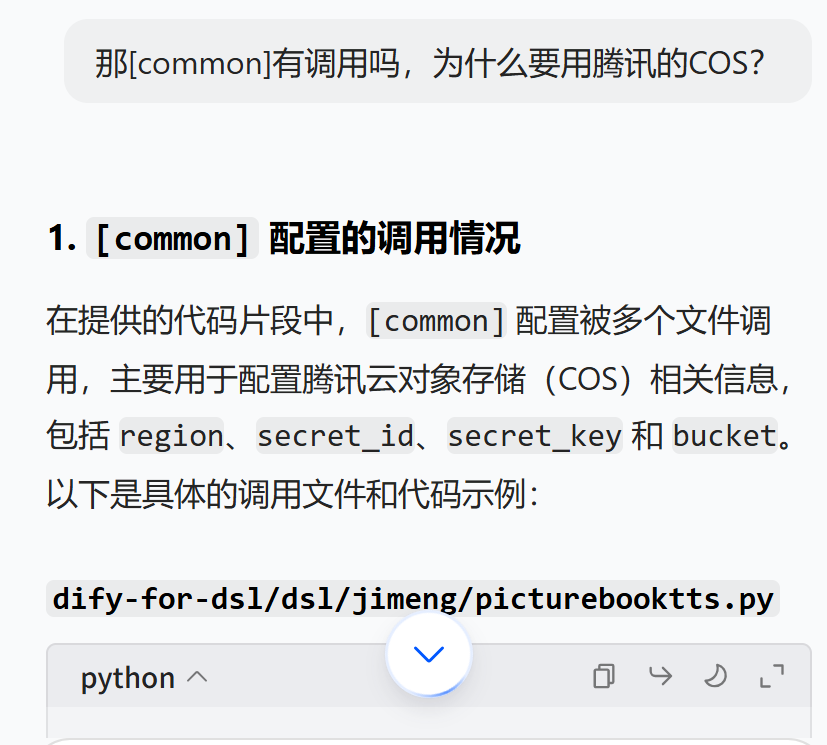
2. 使用腾讯云 COS 的原因
使用腾讯云对象存储(COS)可能有以下几个原因:
2.1 高可靠性和可用性
腾讯云 COS 提供了高可靠性的数据存储服务,采用了分布式存储架构和多副本机制,确保数据的安全性和可靠性。即使在硬件故障或自然灾害等情况下,也能保证数据的可用性。
2.2 弹性扩展
COS 支持弹性扩展,用户可以根据实际需求动态调整存储空间的大小,无需担心存储空间不足的问题。这对于处理大量数据或数据量波动较大的应用场景非常有用。
2.3 高性能
腾讯云 COS 具有高性能的数据读写能力,能够快速响应应用程序的请求。通过优化存储架构和网络性能,COS 可以提供低延迟、高吞吐量的数据访问服务,满足应用程序对数据读写速度的要求。
2.4 安全性
COS 提供了多种安全机制,包括访问控制、数据加密、防盗链等,确保数据的安全性和隐私性。用户可以根据自己的需求设置不同的安全策略,保护数据不被非法访问和篡改。
2.5 成本效益
相比自建存储系统,使用腾讯云 COS 可以降低企业的 IT 成本。用户无需购买和维护硬件设备,只需根据实际使用量支付费用,降低了前期投资和运营成本。
2.6 集成方便
腾讯云 COS 提供了丰富的 SDK 和 API,方便开发者将其集成到自己的应用程序中。同时,COS 还与腾讯云的其他服务(如云服务器、云函数等)紧密集成,为开发者提供了一站式的解决方案。
综上所述,使用腾讯云 COS 可以为应用程序提供高可靠性、高性能、安全性和成本效益的存储服务,同时方便开发者进行集成和管理。
我不太想用,我也不知道为什么要用,就是为了传入到云上面去吗?
说明 common 配置下面4个值是腾讯COS 相关配置,主要目的生成的视频上传腾讯COS 上方便后面浏览和显示视频。
在【api/video.py】也有是调用config.ini
得到了视频的本地的地址,就可以直接返回给前端,进行下载不就可以了吗
搞不了,一直返回不出来,有问题!!!
结果

网络端口号是怎么看啊
dify中写的是ip地址,而不是这个本地的地址


















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











