







一、插入类排序
直接插入排序
- 思想:
- 将一个序列看成左右两个部分,左边表示已经排好序,右边表示待排序。
- 然后,将右边待排序中的数逐个插入到左边排好序部分的适当位置,直到所有数字都被插入到左边有序部分。
- 步骤:
- 1、该数组的第一个元素被认为已经排好序
- 2、从下一个元素(新元素)开始,在已经排序的元素序列中从后向前扫描
- 3、如果这个已排序元素大于新元素,将这个元素后移
- 4、重复3,直到找到已排序的元素小于或者等于新元素的位置
- 5、将新元素插入到该位置后
- 6、重复2~5
- 时间复杂度:
- 最坏:O(n²),最好:O(n),平均复杂度:O(n²)
- 空间复杂度:
- O(1)
void InsertSort(int R[],int n)
{
int i,j,tmp;
//右边,从第一个数字开始
for(i=1,i<n,++i)
{
tmp = R[i]; //将待插入关键字暂存与temp中
j = i-1;
//和左边从右到左比较,如果R[j]>tmp,将它向后移
//直到找到小于自己的数,将自己放到这个数的后边
while(j>=0 && tmp<R[j])
{
R[j+1] = R[j];
--j;
}
R[j+1] = tmp;//找到插入位置
}
}
希尔排序
-
思想:
- 又叫缩小增量排序,本质还是插入排序,只不过将待排序序列按照某种规则分成了几个子序列,分别对几个子序列直接插入排序。
-
步骤:
- 1、选择一个增量序列 t1,t2,t3…tn,该序列递减且最后一个tn=1
- 2、对序列进行 n 趟排序
- 3、每趟排序,根据对应增量,将待排序数组分割成若干子序列
- 4、对每个子序列进行直接插入排序
- 5、最后一个增量为1,其实就是对整个数组进行一次直接插入排序
-
时间复杂度:
- 最坏:O(nlog2n),最好:O(nlog2n),平均复杂度:O(nlog2n)
-
空间复杂度:
- O(1)
int main() {
int len ;
scanf("%d", &len);
int* nums = (int*)malloc(sizeof(int) * len);
for (int i = 0; i < len; i++) {
scanf("%d", &nums[i]);
}
int gap = len / 2;
while (gap > 0) { //每完成一次while循环,代表完成了一次分组后的插入排序
for (int i = 0; i <= gap; i++) {
for (int j = i+gap; j < len; j += gap) { //对间隔为gap的数组成员进行插入排序
if (nums[j] < nums[j - gap]) {
int t = nums[j];
nums[j] = nums[j - gap];
nums[j - gap] =t;
}
}
}
gap /= 2;
}
for (int i = 0; i < len; i++) {
printf("%d\n", nums[i]);
}
return 0;
}
二、交换类排序
冒泡排序
-
思想:
- 它是通过一系列的“交换”动作完成的
-
步骤:
- 1、比较相邻的元素
- 2、如果第一个比第二个大,就交换它们两个,否则不交换
- 3、如果第二个比第三个大,就交换它们两个,否则不交换…
- 4、一直按照上边的方式交换,最终最大的关键字将被移动到最后,一趟冒泡排序完成
- 5、针对所有的元素重复以上的步骤,除了最后一个
-
时间复杂度:
- 最坏:O(n²),最好:O(n),平均复杂度:O(n²)
-
空间复杂度:
- O(1)
void BubbleSort(int R[], int n){
int i,j,flag;
int temp;
for(i = n-1;i >=1;--i){
flag = 0;
for(j = 1;j <= i;++j){
if(R[j-1] > R[j]){
temp = R[j];
R[j] = R[j-1];
R[j-1] = temp;
flag = 1;
}
if(flag == 0)
return;
}
}
}
快速排序
- 思想:
- 快速排序也是“交换”类的排序,它通过多次划分操作实现排序。
- 步骤:
-
1、每一趟选择当前所有子序列中的一个关键字作为枢轴
-
2、将子序列中比枢轴小的移到枢轴前边,比枢轴大的移到枢轴后边
-
3、以上述规则划分完毕后会得到新的一组更短的子序列
-
4、继续以上述规则划分子序列
-
注意:快速排序中对每一个子序列的一次划分算作一趟排序,每一趟结束之后有一个关键字到达最终位置
-
- 时间复杂度:
- 最坏:O(n²) ,待排序列接近有序;最好:O(nlog2n),待排序列接近无序,平均复杂度:O(nlog2n)
- 空间复杂度:
- O(log2n)
void QuickSort(int R[],int low,int high)
{
int tmp;
int i=low,j=high;
if(low<high)
{
temp=R[low];
//小于temp的关键字放在左边,大于temp的关键字放在右边
while(i<j)
{
while(j>i&&R[j]>=temp) --j;
if(i<j)
{
R[i]=R[j];
++i;
}
while(i<j&&R[i]<temp) ++i;
if(i<j)
{
R[j]=R[i];
--j;
}
}
R[i]=temp;
QuickSort(R,low,i-1);
QuickSort(R,i+1,high);
}
}
三、选择类排序
简单选择排序
-
思想:
- 简单选择排序主要的动作就是 选择。
-
步骤:
- 1、从头至尾顺序扫描序列,找出最小的一个关键字
- 2、和第一个关键字交换
- 3、从剩下的关键字中继续这种选择和交换
- 4、最终使序列有序
-
时间复杂度:
- O(n²)
-
空间复杂度:
- O(1)
void SelectSort(int R[],int n)
{
int i,j,k;
int temp;
for(i=0;i<n;++i)
{
k=i;
//从无序序列中挑出一个最下的关键字
for(j=i+1;j<n;++j)
if(R[k]>R[j])
k=j;
//交换
temp = R[i];
R[i] = R[k];
R[k] = temp;
}
}
堆排序
- 思想:
- 堆是一种数据结构,可以把堆看成一棵完全二叉树,这棵完全二叉树满足:任何一个非叶结点的值都不大于(或不小于)其左右孩子结点的值。若父亲大孩子小,则这样的堆叫作大顶堆;若父亲小孩子大,则这样的堆叫作小顶堆。
- 代表堆的这棵完全二叉树的根结点的值是最大(或最小)的,因此将一个无序序列调整为一个堆,就可以找出这个序列的最大(或最小)值,然后将找出的这个值交换到序列的最后(或最前),这样,有序序列关键字增加1个,无序序列中关键字少1个,对新的无序序列重复这样的操作,就实现了排序。
举个例子,原始序列为: 49 38 65 97 76 13 27 49
-
1、下边为原始序列对应的完全二叉树,第一步先将这个树调整为一个大顶堆
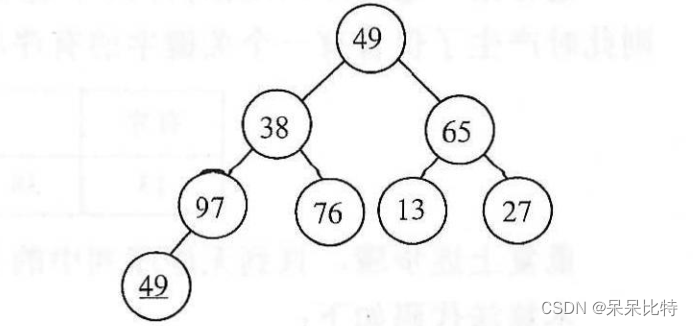
- 在上边的完全二叉树中,76、13、27、
49是叶子节点,满足堆的定义。 - 调整97,97 >
49,不需要调整 - 调整65,65>13,65>27,不需要调整
- 调整38,38小于他的两个子节点,和子节点中较大的一个交换,38和97交换。交换后38还小于子节点
49,继续交换。 - 调整49,49小于两个子节点,和较大的97交换,交换后49还小于76,继续与76交换。
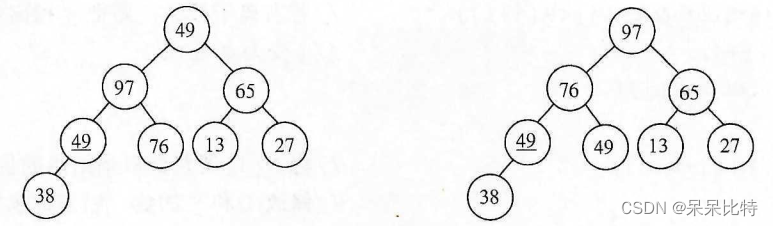
- 在上边的完全二叉树中,76、13、27、
-
2、排序
- 第一步:根据上边调整好的大顶堆,先将97和38交换,第一趟堆排序完成,97到达最终位置。
- 第二步:将除堆顶97外的其他结点重新调整为大顶堆,再将堆顶和最后一个结点交换,第二趟排序完成。
- 重复第二步,知道树中只剩一个结点,排序完成。
步骤总结:
-
1)从无序序列所确定的完全二叉树的最后一个非叶子结点开始,从右至左,从下至上,对每个结点
进行调整,最终将得到一个大顶堆。 -
对结点的调整方法:将当前结点(假设为a)的值与其孩子结点进行比较,如果存在大于a值的孩
子结点,则从中选出最大的一个与a交换。当a来到下一层的时候重复上述过程,直到a的孩子结点值
都小于a的值为止。 -
2)将当前无序序列中的第一个关键字,反映在树中是根结点(假设为)与无序序列中最后一个关
键字交换(假设为b)。进入有序序列,到达最终位置。无序序列中关键字减少1个,有序序列中关键
字增加1个。此时只有结点b可能不满足堆的定义,对其进行调整。 -
3)重复第2步,直到无序序列中的关键字剩下1个时排序结束。
-
时间复杂度:
- O(nlog2n)
-
空间复杂度:
- O(1)
void Sift(intR[],int low,int high)//这里关键字的存储设定为从数组下标1开始
{
int i=low,j=2*i; //R[j]是R[i]的左孩子结点
int temp=R[i];
while(j<=high)
{
if(j<high&&R[j]<R[j+1]) //若右孩子较大,则把j指向右孩子
++j; //行变为2*i+1
if (temp<R[j])
{
R[i]=R[j];//将R[5]调整到双亲结点的位置上
i=j;//修改1和j的值,以便继续向下调整
j=2*i;
}
else
break; //调整结束
}
R[i]=temp; //被调整结点的值放入最终位置
}
/*堆排序函数*/
void heapsort(int R[],int n)
{
int i;
int temp;
for(i=n/2;i>=1;--1) //建立初始堆
Sift (R,i,n);
for(i=n;i>=2;--1) //进行n-1次循环,完成堆排序
{
/*以下3句换出了根结点中的关键字,将其放入最终位置*/
temp=R[1];
R[1]=R[i]:
R[i]=temp;
Sift(R,1,i-1); //在减少了1个关键字的无序序列中进行调整
}
}
四、二路归并排序
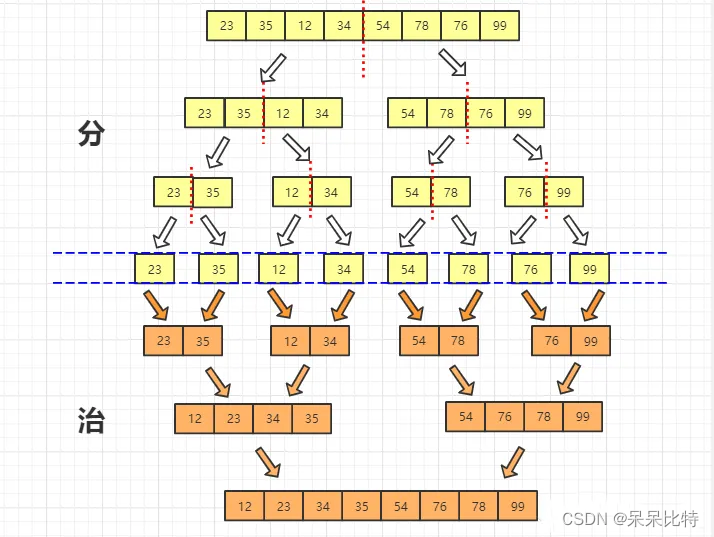
-
思想:
- 归并排序可以看作一个分而治之的过程。
-
步骤:
- 1、将原始序列看成只含有一个关键字的子序列,显然这些子序列都是有序的。
- 2、两两归并,形成若干有序二元组。
- 3、再将这个序列看成若干二元组子序列。
- 4、继续两两归并,形成若干四元组。
- 5、知道将整个子序列合并成一个序列。
-
时间复杂度:
- 最坏,最好,平均复杂度:O(nlog2n)
-
空间复杂度:
- O(n)
//int A[size],B[size]
void mergeSort(int A[],int low,int high)
{
if(low<high)
{
int mid = (low+high)/2;
mergeSort(A,low,mid); //前部分
mergeSort(A,mid+1,high); //后部分
merge(A,low,mid,high); //合并
}
}
void merge(int A[],int low,int mid,int high){
//B里暂存A的数据
for(int k = low ; k < high + 1 ; k++){
B[k] = A[k];
}
int i = low , j = mid + 1 , k = low;
while(i < mid + 1 && j < high + 1) {
//A的元素暂存在B里,因为不能再A上原地操作,会打乱数据
//这也是为什么二路归并排序(合并排序)空间复杂度是O(n)的原因
//我们这里把值小的放在前面,最后排序结果就是从小到大
if(B[i] > B[j]){
A[k++] = B[j++];
}else{
A[k++] = B[i++];
}
}
//循环结束后,会有一个没有遍历结束的数组段。
while(i < mid + 1)
A[k++] = B[i++];
while(j < high + 1)
A[k++] = B[j++];
}
五、基数类排序
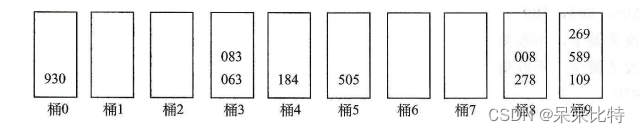
- 思想:
- 将待排序的元素拆分为k个关键字,其中k为最大值的位数,从低位开始进行稳定排序。
- 适合的场景是序列中的关键字很多,但组成关键字的取值范围较小。
- 步骤:(278、109、063、930、589、184、505、269、008、083)
-
1、每一个元素的每一位都是 0~9 数字,所以准备10个桶
-
2、进行第一趟分配,按照最后一位
-
3、按桶 0~9顺序收集,从桶下边出:930 063 083 184 505 278 008 109 589 269
-
4、进行第二趟分配,按照中间位
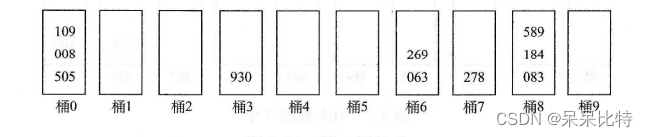
-
5、收集:505 008 109 930 063 269 278 083 184 589
-
6、进行第三趟分配,按照最高位

-
7、收集:008 063 083 109 184 269 278 505 589 930,最终整个序列有序。
-
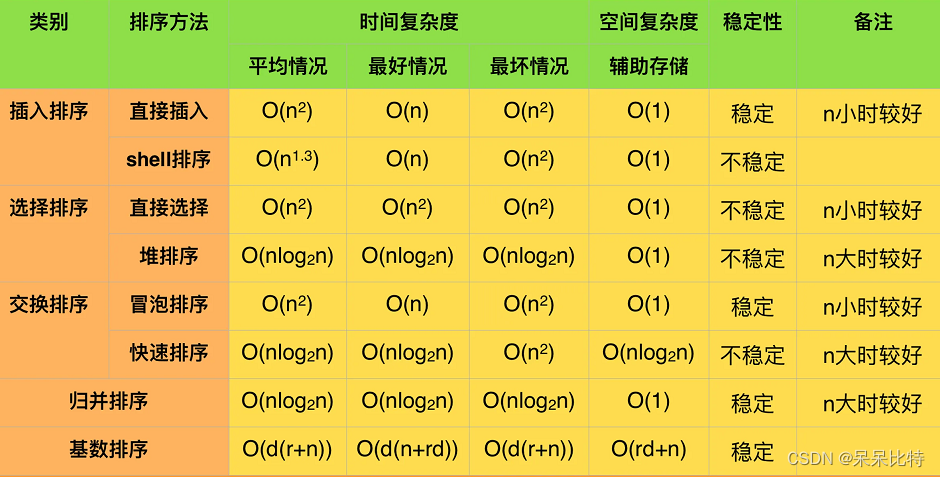
各种排序算法比较总结

















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











