







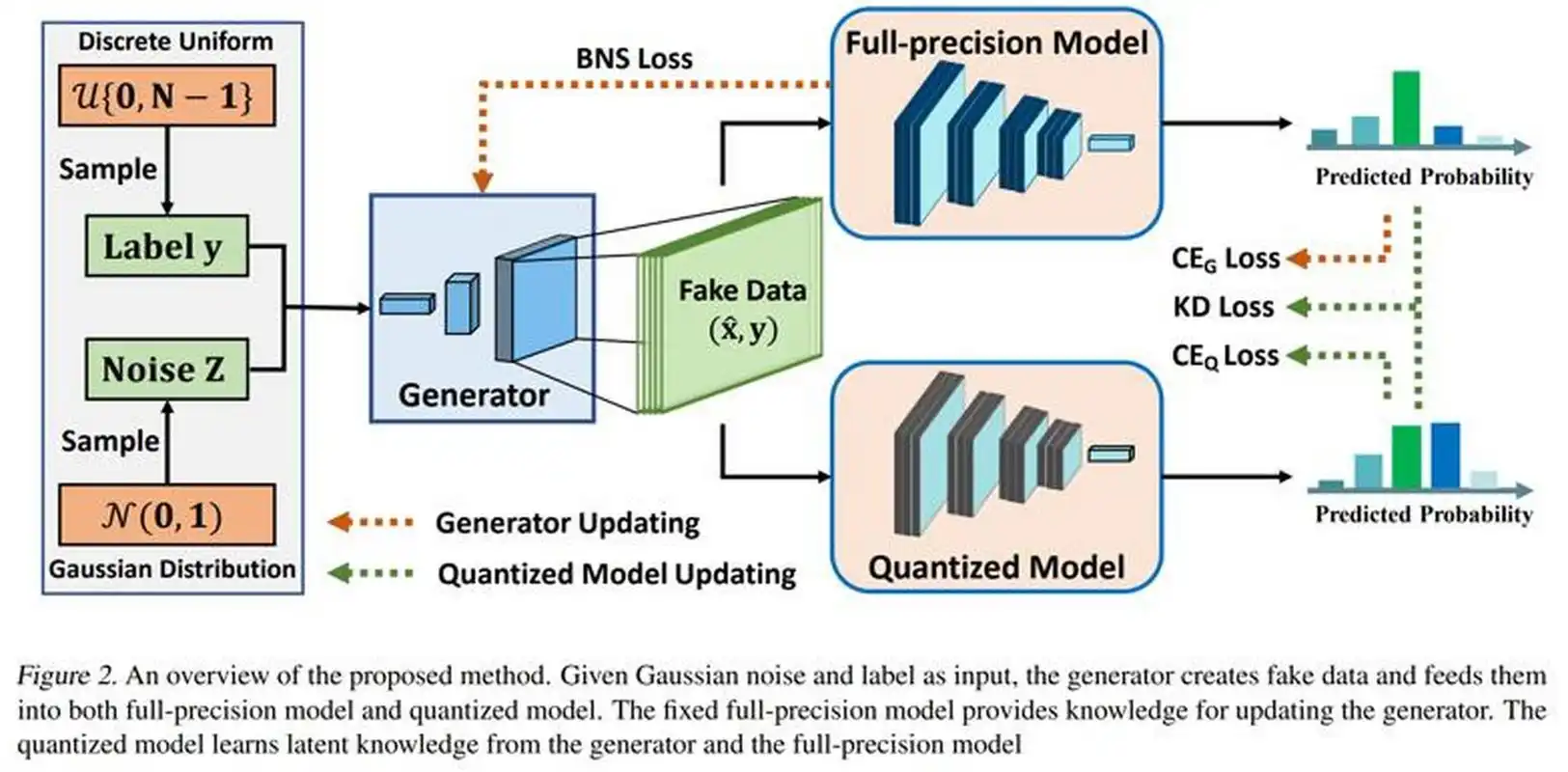
GANs(Generative Adversarial Networks)即生成对抗网络,是一种深度学习模型,由伊恩·古德费洛(Ian Goodfellow)等人在2014年提出。GANs在人工智能领域具有重要地位,尤其在生成任务中表现出色:
一、GANs的基本结构与原理
-
结构组成:
- 生成器(Generator):负责生成数据,通过学习真实数据的分布,生成尽可能接近真实数据的假数据。
- 判别器(Discriminator):负责判断输入的数据是真实的还是生成的,输出一个概率值表示数据为真实的概率。
-
工作原理:
- 生成器和判别器通过对抗训练的方式共同优化。生成器试图生成更逼真的数据以欺骗判别器,而判别器则努力提高自己的判别能力以区分真实数据和生成数据。
- 这个过程可以看作是一个零和博弈,生成器和判别器在训练过程中相互竞争、相互提高。
二、GANs的训练过程
- 初始化:生成器和判别器的参数随机初始化。
- 交替训练:
- 固定生成器,训练判别器:使用真实数据和生成器生成的假数据训练判别器,提高其判别能力。
- 固定判别器,训练生成器:使用判别器的反馈(如损失函数)来更新生成器的参数,使其生成更逼真的数据。
- 迭代优化:重复上述步骤,直到生成器和判别器达到某种平衡状态,即生成器生成的数据能够很好地欺骗判别器,而判别器也能以较高的准确率区分真实数据和生成数据。
三、GANs的应用领域
- 图像生成:GANs可以生成高质量的图像,如人脸、风景、艺术品等。这在艺术创作、设计、广告等领域具有广泛应用。
- 图像修复与超分辨率:GANs可以用于修复损坏的图像或提高图像的分辨率,使图像更加清晰和逼真。
- 风格迁移:GANs可以将一种图像的风格迁移到另一种图像上,实现图像风格的转换。
- 数据增强:GANs可以生成与真实数据相似的新数据,用于扩充数据集,提高模型的泛化能力。
- 文本生成:虽然GANs在文本生成方面的应用相对较少,但也有一些研究尝试使用GANs生成高质量的文本内容。
四、GANs的优势与挑战
-
优势:
- 生成高质量数据:GANs能够生成与真实数据非常接近的假数据,具有很高的逼真度。
- 无需显式建模:GANs通过对抗训练的方式隐式地学习数据的分布,无需显式地建模数据的概率分布。
- 应用广泛:GANs在图像、音频、视频等多个领域都有广泛的应用前景。
-
挑战:
- 训练不稳定:GANs的训练过程容易出现不稳定现象,如模式崩溃(生成器只生成有限种类的样本)和梯度消失等问题。
- 评估困难:由于GANs生成的数据是新颖的,没有直接的评估标准来衡量生成数据的质量。
- 计算资源需求大:GANs的训练需要大量的计算资源和时间,对硬件要求较高。
五、GANs的未来发展
随着深度学习技术的不断发展,GANs也在不断改进和优化。未来,GANs有望在以下几个方面取得更大的突破:
- 提高训练稳定性:通过改进训练算法、优化网络结构等方式提高GANs的训练稳定性。
- 拓展应用领域:将GANs应用于更多领域,如医疗、金融、教育等,推动这些领域的智能化发展。
- 与其他技术融合:将GANs与其他深度学习技术(如强化学习、自监督学习等)相结合,发挥各自的优势,实现更强大的功能。
提高GANs(生成对抗网络)的训练稳定性是深度学习领域的一个重要课题。
一、改进网络架构
- 使用更深的网络:增加生成器和判别器的网络深度,可以提高模型的表达能力,但也要注意避免过拟合。
- 引入残差块:在生成器和判别器中引入残差块(Residual Blocks),有助于缓解梯度消失问题,促进信息的有效传递。
- 归一化技术:使用批归一化(Batch Normalization)或层归一化(Layer Normalization)等技术,可以加速训练过程,提高模型的稳定性。
二、优化训练策略
- 标签平滑:在判别器的训练目标中,将真实样本的标签从1稍微降低(如0.7-0.9),将假样本的标签从0稍微提高(如0.1-0.3),可以避免判别器过于自信,从而缓解训练不稳定的问题。
- 特征匹配:通过让生成器匹配判别器中间层的特征,而不是仅仅匹配输出层的概率分布,可以提供更稳定的训练信号。
- 历史平均:在更新生成器时,使用判别器历史参数的平均值,而不是最新的参数,可以减少训练过程中的振荡。
- 小批量判别:让判别器评估一个小批量中所有样本的集合,而不是单个样本,可以防止判别器对单个样本过拟合,提高训练的稳定性。
三、调整损失函数
- Wasserstein距离:使用Wasserstein距离(又称Earth-Mover距离)代替传统的JS散度或KL散度作为损失函数,可以解决梯度消失问题,提供更稳定的训练过程。Wasserstein GAN(WGAN)及其改进版本(如WGAN-GP)在这方面表现出色。
- 梯度惩罚:在WGAN的基础上,添加梯度惩罚项(如WGAN-GP中的梯度范数惩罚),可以确保判别器的Lipschitz连续性,进一步提高训练的稳定性。
四、增加训练数据多样性
- 数据增强:对训练数据进行增强处理,如旋转、缩放、裁剪等,可以增加数据的多样性,提高模型的泛化能力。
- 使用更大的数据集:更多的训练数据可以提供更丰富的信息,有助于模型学习到更稳定的数据分布。
五、调整超参数
- 学习率:选择合适的学习率对于GANs的训练至关重要。过大的学习率可能导致模型无法收敛,而过小的学习率则可能导致训练速度过慢。
- 优化器:尝试不同的优化器(如Adam、RMSProp等),并调整其超参数(如beta1、beta2等),以找到最适合当前任务的优化策略。
六、监控和调试
- 可视化训练过程:通过可视化生成器和判别器的损失函数、生成的样本质量等指标,可以及时发现训练过程中的问题,并采取相应的措施进行调整。
- 调试技巧:当训练不稳定时,可以尝试简化模型、减少层数或参数数量,以降低训练难度;或者先训练一个较简单的模型,再逐渐增加复杂度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









