










副本概念
副本是 OceanBase 数据库存储引擎中的概念,同一份数据在不同节点的拷贝称为副本,这里的数据是一个用户层面的概念。
在 OceanBase 数据库层面,我们指数据分区,每个数据分区根据租户的 Locality 属性冗余有多份,从而提供良好的水平扩展性和更高级别的容灾能力。
数据分区是指根据一定的建表规则,把一个表或者索引分解成多个更小的、更容易管理的部分。每个数据分区都是一个独立的对象,具有自己的名称和可选的存储特性。
说明
OceanBase 数据库以多副本架构著称,基于 Paxos 协议的多副本架构是高可用能力的基础。多副本中的“副本”本质是同一份数据在不同节点的拷贝,而数据在 OceanBase 数据库中有多种层面的承载容器,例如数据分区、日志流、Unit、租户等。一般情况下我们提及的“副本”往往是指“数据分区副本”。但需要注意的是,不同语境下的“副本”可能对应着不同的数据库实体。
副本的作用
副本提高了 OceanBase 数据库的可用性和容错性,副本可以被分配在不同的地理位置,以应对网络故障或数据中心故障。
OceanBase 数据库通过分区复制、日志同步等方式将数据复制到多个副本以防止数据丢失,确保 OceanBase 数据库在少数派副本故障的情况下依然能够提供无损的数据库服务。
副本的类型
OceanBase 数据库的存储引擎采用分层 LSM-Tree 结构,数据分为两部分:基线数据和增量数据。
基线数据是持久到磁盘上的数据,一旦生成就不会再修改,称之为 SSTable。
增量数据存在于内存,用户写入都是先写到增量数据,称之为 MemTable,通过 RedoLog 来保证事务性(也称为 CommitLog,简称 CLog)。
这些数据冗余有多份(例如,同城三中心部署架构为 3 个,三地五中心部署架构为 5 个),分布于多个节点上。事务提交时利用 Paxos 协议在多个节点间同步 RedoLog 达成多数派提交,从而维护副本间数据的一致性。
OceanBase 数据库当前版本支持的副本类型如下:
-
全功能型副本
全功能型副本也称为普通副本,其名称为 FULL,简称 F,拥有 RedoLog、MemTable 和 SSTable 等全部完整的数据和功能。
全功能副本有角色的概念,即数据分区有角色的概念,分别是 Leader 和 Follower。Leader 主要对外提供写服务和强一致读服务,也可以提供弱一致读服务。Follower 对外提供弱一致读服务,在 Leader 故障的情况下还可以快速切换为 Leader 对外提供服务。
有关全功能型副本的更多介绍,参见 全功能型副本。
-
只读型副本
只读型副本的名称为 READONLY,简称 R,区别于全功能副本,只读副本提供读的能力,不提供写的能力,只能作为日志流的 Follower 副本,不参与选举及日志的投票,不能当选为日志流的 Leader 副本。
有关只读型副本的更多介绍,参见 只读型副本。
-
列存副本
列存副本的名称为 COLUMNSTORE,简称 C。列存副本是指在同一个日志流上用户表的基线数据都以列存模式存储,这里的用户表包括复制表,但不包括索引表、内部表以及系统表等。例如,用户在 F 副本上创建了一个行存表,则在 C 副本所在的机器上,该表将会以列存形式存储。与只读副本 R 类似,列存副本不参与选举和日志投票,拥有完整的 SSTable、clog 和 MemTable。
有关列存副本的更多介绍,参见 列存副本。
日志流介绍
日志流概念
日志流是由 OceanBase 数据库自动创建和管理的实体,它代表了一批数据的集合,包括若干数据分区,及对其进行事务操作的日志和事务管理结构。RedoLog 是基于 Paxos 协议实现的日志模块,实现了多副本间日志同步,保证副本间数据的一致性,实现了数据的高可用。TxCtxMgr 是事务管理结构,日志流内所有数据分区的修改可以在日志流内部完成原子提交,事务跨多个日志流时使用 OceanBase 优化的两阶段提交协议完成事务的原子提交,日志流是分布式事务的参与者。
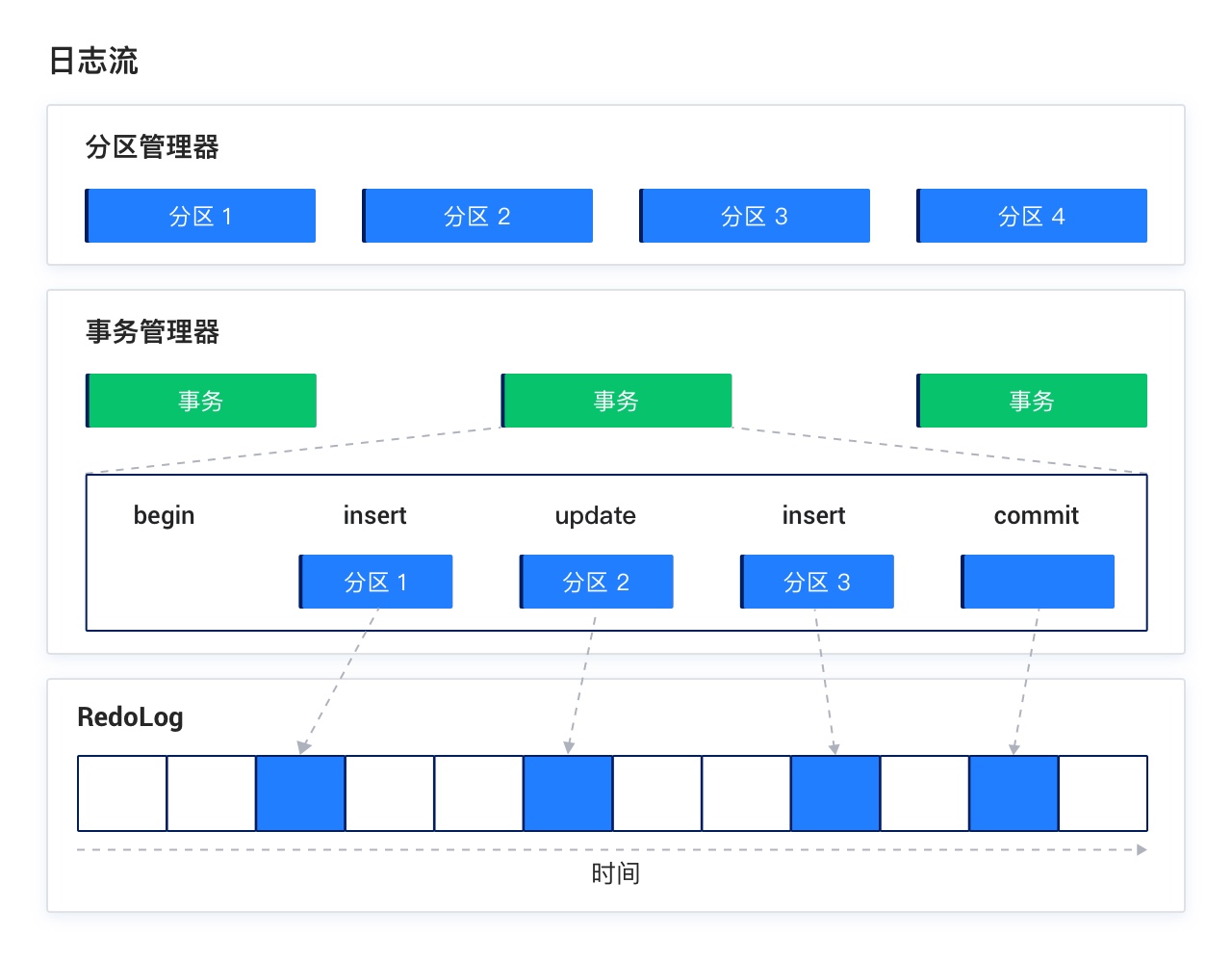
日志流是 OceanBase 数据库 V4.0 新引入的概念,OceanBase 数据库 V4.0 相比于 OceanBase 数据库 V3.x 最大的改变就是改变了事务提交的基本单位,从而在资源、性能、功能三个方面带来了很大价值。
-
在 OceanBase 数据库 V3.x 中,OceanBase 数据库以分区为单位进行事务提交,分区内的修改由分区内 WAL 保证修改的原子性,每个分区作为两阶段提交的参与者,事务提交的基本单位是分区。
-
在 OceanBase 数据库 V4.x 中,OceanBase 数据库以日志流为单位进行事务提交,日志流内的修改由日志流内 WAL 保证修改的原子性,每个日志流作为两阶段提交的参与者,事务提交的基本单位是日志流。
广播日志流
从 V4.2.0 版本开始,OceanBase 数据库又新引入了广播日志流的概念。当某个租户的第一个复制表被创建时,同时系统会创建一个特殊的日志流,称为广播日志流。之后新建的复制表都会创建到这个广播日志流上。广播日志流与普通日志流的不同之处在于,广播日志流会自动地在租户内的每个 OBServer 节点上均部署一个副本,保证在理想情况下复制表可以在任意一个 OBServer 节点上提供强一致性读。
一般来说,参与一致性协议投票的副本过多,就会导致达成多数派需要的时间越长。在一个租户内的 OBServer 节点较多时,自然不可能让所有的 OBServer 上的副本都参与投票。因此,广播日志流就会在不需要参与投票的 OBServer 上会部署 R 副本(READONLY 副本,只读型副本),在需要参与投票的 OBServer 节点上部署常规的 F 副本(FULL 副本,即全功能型副本)。
广播日志流与普通日志流对副本的差异如下:
-
对于普通日志流来说,每个 Zone 仅能有一个副本,且该副本类型需要与 Locality 中指定的副本类型匹配。
-
对于广播日志流来说,每个 Zone 内,除了 Locality 中描述的该 zone 的副本类型外,在该 Zone 内其余有该租户 Unit 资源的机器上还会各放置一个只读型副本。对 Locality 中没有指定副本类型的 Zone 不放置任何副本。
广播日志流的使用限制如下:
-
sys租户、所有Meta租户均没有广播日志流,不支持复制表创建。 -
每个用户租户最多只能有一个广播日志流。
-
不支持广播日志流和普通日志流之间的属性转换。
-
不支持手动删除广播日志流,当前仅支持广播日志流随着租户的删除而删除。
查看日志流的基本信息
通过 DBA_OB_LS 视图可以查看本租户所有日志流的基本信息,包括状态、日志进度等。例如:
-
查看普通日志流信息
系统租户和用户租户均可以查看本租户对应的日志流的基本信息。例如以下示例在系统租户中执行,所示为系统租户仅有的一个 1 号日志流。
SELECT * FROM oceanbase.DBA_OB_LS limit 10;结果如下。
+-------+--------+----------------------------------------+---------------+-------------+------------+----------+----------+--------------+-----------+ | LS_ID | STATUS | PRIMARY_ZONE | UNIT_GROUP_ID | LS_GROUP_ID | CREATE_SCN | DROP_SCN | SYNC_SCN | READABLE_SCN | FLAG | +-------+--------+----------------------------------------+---------------+-------------+------------+----------+----------+--------------+-----------+ | 1 | NORMAL | sa128_obv4_2;sa128_obv4_1,sa128_obv4_3 | 0 | 0 | NULL | NULL | NULL | NULL | | +-------+--------+----------------------------------------+---------------+-------------+------------+----------+----------+--------------+-----------+ 1 row in set -
查看广播日志流信息
仅用户租户可以查看广播日志流信息,系统租户没有广播日志流。以下示例为在用户租户上执行,所示为用户租户的广播日志流信息,复制表就创建在该日志流上。
SELECT * FROM oceanbase.DBA_OB_LS WHERE flag LIKE "%DUPLICATE%";结果如下。
+-------+--------+--------------+---------------+-------------+---------------------+----------+---------------------+---------------------+-----------+ | LS_ID | STATUS | PRIMARY_ZONE | UNIT_GROUP_ID | LS_GROUP_ID | CREATE_SCN | DROP_SCN | SYNC_SCN | READABLE_SCN | FLAG | +-------+--------+--------------+---------------+-------------+---------------------+----------+---------------------+---------------------+-----------+ | 1003 | NORMAL | z1;z2 | 0 | 0 | 1683267390195713284 | NULL | 1683337744205408139 | 1683337744205408139 | DUPLICATE | +-------+--------+--------------+---------------+-------------+---------------------+----------+---------------------+---------------------+-----------+
查看日志流的位置信息和角色信息
日志流具有位置信息,记录了其分布于哪些节点,可以通过 oceanbase.DBA_OB_LS_LOCATIONS 视图的 MEMBER_LIST 字段和 LEARNER_LIST 字段分别查看全功能型副本和只读型副本的分布情况。数据分区不再独立拥有位置信息,而是由其归属于的日志流位置决定。日志流支持在不同节点之间迁移和复制,以达到性能均衡和容灾的目的。
日志流具有角色信息,记录其是 LEADER 还是 FOLLOWER,可以通过 oceanbase.DBA_OB_LS_LOCATIONS 视图的 ROLE 字段查看。数据分区不再独立拥有角色信息,而是由其归属于的日志流角色决定。日志流角色通过选举协议产生。
关于视图 oceanbase.DBA_OB_LS_LOCATIONS的详细介绍,参见 DBA_OB_LS_LOCATIONS。
查看数据分区到日志流的映射
通过 DBA_OB_TABLE_LOCATIONS 视图可以查看本租户数据分区到日志流的映射,其中每个数据分区的每个副本都是一条记录,记录了该数据分区的基本信息,及其所归属的日志流信息。
为满足对 TP 增强混合负载(准实时决策分析)场景的支持,OceanBase 数据库提供了对列存副本(COLUMNSTORE,以下简称 C 副本)的支持。用户可以将 C 副本部署在独立的 Zone 上。在 C 副本上,所有的用户表(包括复制表、不包括索引表、内部表、系统表)均为列存格式存储。OLAP 业务通过独立的 proxy 入口访问 C 副本,并以弱读方式执行决策分析类业务。
注意事项
在使用 C 副本时,需要注意以下事项:
-
从 V4.3.5 BP1 版本开始,支持部署多个 C 副本,建议最多部署 3 个 C 副本。
-
C 副本与 F 或 R 副本之间不支持相互转换。
-
由于访问 C 副本需要部署独立的 ODP,建议对存在 C 副本的 Zone 上只部署 C 副本。同时,部署 ODP 时,要求其版本必须为 ODP V4.3.2 及以上版本。
-
F/R 副本上的查询不允许转发到 C 副本。反之,C 副本上的用户表查询也不允许转发到 F/R 副本,否则会报错。
-
部署了 C 副本的集群,在执行 DDL 操作时,会对 CPU、内存、磁盘以及 IO 等资源的使用产生影响。
-
C 副本的合并比 F/R 副本的合并慢。如果 C 副本未合并完成,将无法发起新一轮的租户级合并。手动触发合并前,建议通过查看 CDB_OB_ZONE_MAJOR_COMPACTION 或 DBA_OB_ZONE_MAJOR_COMPACTION 视图来确认上一轮所有副本是否都已完成合并。
有关查看合并情况的详细操作,参见 查看合并信息。
-
物理恢复不支持恢复 C 副本,指定租户的 Locality 时,如果指定了 C 副本,恢复操作将会执行失败。
-
如果主库未部署 C 副本,备库也不建议部署 C 副本。
部署 C 副本并配置 ODP
以下内容主要介绍如何在 OceanBase 集群中部署并配置 ODP,以访问 C 副本。
步骤一:部署 C 副本
要在集群中部署 C 副本,只需要在租户的 Locality 中指定 C 副本即可。主要有以下两种场景:
-
创建租户时指定 C 副本
-
通过修改租户的 Locality 来增加 C 副本
创建租户时指定 C 副本
假设当前有一个已部署好的集群,且集群的部署模式为 2F1A(两副本+ 1 个仲裁服务)。集群中的 3 个 Zone 分别为 zone1、zone2、zone3,仲裁服务部署在 zone3 上。需要在该集群上创建一个含有 C 副本的租户,步骤如下:
-
找到一台能够与当前集群网络互通的机器,并在该机器上部署 ODP。
为防止资源争抢,建议 ODP 单独部署在一台机器上。部署 ODP 时,要求其版本必须为 ODP V4.3.2 及以上版本。有关部署 ODP 的详细操作,参见 部署 ODP。
-
为租户创建资源单元
unit1。obclient [oceanbase]> CREATE RESOURCE UNIT unit1, MAX_CPU=5, MIN_CPU=5, MEMORY_SIZE= '32G', MAX_IOPS=10000, MIN_IOPS=5000, LOG_DISK_SIZE=5301023539200; -
为租户创建资源池
pool1,指定资源单元为unit1。obclient [oceanbase]> CREATE RESOURCE POOL pool1 UNIT='unit1', UNIT_NUM = 1, ZONE_LIST = ('zone1','zone2','zone3'); -
创建一个租户
tenant_c,指定其 Locality 为F@zone1,F@zone2,C@zone3。obclient [oceanbase]> CREATE TENANT tenant_c LOCALITY = 'F@zone1,F@zone2,C@zone3', primary_zone='zone1;zone2,zone3', RESOURCE_POOL_LIST=('pool1') SET ob_tcp_invited_nodes = '%';本示例中,创建的租户默认为 MySQL 兼容模式租户,如果需要创建 Oracle 兼容模式租户,需要通过系统变量 ob_compatibility_mode 显式指定
ob_compatibility_mode='oracle'。
通过修改租户的 Locality 来增加 C 副本
假设当前集群中有一个名为 tenant_c 的租户,其 Locality 为 F@zone1,F@zone2,F@zone3,租户的资源池为 pool1,其 ZONE_LIST 范围为 'zone1','zone2','zone3'。现在需要为租户增加 C 副本,可以增加一个 Zone4,然后修改租户的 Locality 为 F@zone1,F@zone2,F@zone3,C@zone4,步骤如下:
-
在集群中添加新的 Zone
zone4。添加 Zone 的详细操作,参见 添加 Zone。 -
向
zone4内增加节点。添加节点的详细操作,参见 添加节点。 -
找到一台能够与当前集群网络互通的机器,并在该机器上部署 ODP。
为防止资源争抢,建议 ODP 单独部署在一台机器上。部署 ODP 时,要求其版本必须为 ODP V4.3.2 及以上版本。有关部署 ODP 的详细操作,参见 部署 ODP。
-
创建资源单元
unit2。obclient [oceanbase]> CREATE RESOURCE UNIT unit2, MAX_CPU=5, MIN_CPU=5, MEMORY_SIZE= '32G', MAX_IOPS=10000, MIN_IOPS=5000, LOG_DISK_SIZE=5301023539200; -
创建资源池
pool2,指定资源单元为unit2。obclient [oceanbase]> CREATE RESOURCE POOL pool2 UNIT = 'unit2', UNIT_NUM = 1, ZONE_LIST = ('zone4'); -
为租户增加资源池
pool2。obclient [oceanbase]> ALTER TENANT tenant_c RESOURCE_POOL_LIST = ('pool1','pool2'); -
修改租户的 Locality 为
F@zone1,F@zone2,F@zone3,C@zone4。obclient [oceanbase]> ALTER TENANT tenant_c LOCALITY = 'F@zone1,F@zone2,F@zone3,C@zone4';
步骤二:配置路由转发策略及弱读请求
部署 C 副本后,需要配置路由转发策略及弱读请求,以保证 OLAP 请求可以自动转为弱读请求并转发到相应的 C 副本上。
-
使用
root@proxysys用户登录到用于访问 C 副本的 ODP。连接示例如下:
[admin@obtest ~]$ obclient -uroot@proxysys -h10.10.10.1 -P2883 -p -
执行以下语句,配置路由转发策略及弱读请求。
支持以下两种配置项组合,选择任意一种进行设置即可。
-
第一种
-
配置 SQL 请求为只读类型。
obclient> ALTER PROXYCONFIG SET obproxy_read_only = 0; -
配置 SQL 请求为弱一致性读。
obclient> ALTER PROXYCONFIG SET obproxy_read_consistency = 1; -
配置弱读情况下,ODP 所有请求仅路由到 C 副本所在的 Zone,同时生成 C 副本的查询计划。
例如, C 副本所在的 Zone 为
zone4。obclient> ALTER PROXYCONFIG SET proxy_primary_zone_name='zone4';obclient> ALTER PROXYCONFIG SET init_sql='set @@ob_route_policy = COLUMN_STORE_ONLY';
-
-
第二种
-
配置 SQL 请求为只读类型。
obclient> ALTER PROXYCONFIG SET obproxy_read_only = 0; -
配置 SQL 请求为弱一致性读。
obclient> ALTER PROXYCONFIG SET obproxy_read_consistency = 1; -
配置弱读情况下,所有请求仅路由到 C 副本,同时生成 C 副本的查询计划。
obclient> ALTER PROXYCONFIG SET route_target_replica_type = 'ColumnStore';obclient> ALTER PROXYCONFIG SET init_sql='set @@ob_route_policy = COLUMN_STORE_ONLY'; -
配置弱读情况下,所有请求仅选择从副本,当从副本都不可用时,断开和客户端的连接。
obclient> ALTER PROXYCONFIG SET proxy_route_policy='TARGET_REPLICA_TYPE_FOLLOWER_ONLY';
-
-
-
修改成功后,通过以下语句,确认修改结果。
obclient> SHOW PROXYCONFIG ALL LIKE 'obproxy_read_only';obclient> SHOW PROXYCONFIG ALL LIKE 'obproxy_read_consistency';obclient> SHOW PROXYCONFIG ALL LIKE 'proxy_primary_zone_name';obclient> SHOW PROXYCONFIG ALL LIKE 'init_sql';obclient> SHOW PROXYCONFIG ALL LIKE 'route_target_replica_type';obclient> SHOW PROXYCONFIG ALL LIKE 'proxy_route_policy';
配置成功后,对于 OLAP 业务,用户可以通过该独立的 ODP 将查询请求定向到 C 副本,利用列存批量处理的优势加速查询,且不影响原有的 OLTP 业务。
C 副本上暂为行存的几种场景
在 OceanBase 数据库中,如果一张表在被创建时为行存表,则系统会在 C 副本上创建对应的纯列存表;如果一张表在被创建时为列存表,则在 C 副本上的存储方式将与 F 副本保持一致。故,对于 C 副本而言,仅负责将 F 副本上行存的用户表的用户分区转换为列存存储,且该描述仅表示 “最终” 状态为列存。在 C 副本上,并非任意时刻分区均表现为列存形式,在以下场景中, C 副本上的用户表分区会暂时为行存,需要系统自发调度行转列任务,将最新的基线数据转换为列存。
| 场景 | 描述 |
|---|---|
| 补副本(增加副本) | 以修改 Locality 使得 F@z1, F@z2 变更为 F@z1, F@z2, C@z3 为例:
|
| 日志流 Rebuild | 当触发 C 副本上日志流的 Rebuid 时,系统将会从源端拉取相应的基线到 C 副本。若基线数据为行存,则暂时为行存,待后台调度行转列任务后再转为列存。 |
| 补副本与 Offline DDL 并发场景 | 当 C 副本在日志流成员列表中时,若执行 Offline DDL,系统将会直接在 C 副本上构建列存基线。然而,当补副本与 Offline DDL 并发时,C 副本对执行 DDL 任务的日志流 Leader 不可见,此时系统在 C 副本上将会先构建出行存的基线,待后台调度行转列任务后再转为列存。 |
| 全量旁路导入 | 全量旁路导入当前仅支持先向 C 副本上导入行存,待后台调度行转列任务后转为列存。 |
| 表级恢复 | 由于当前列存表暂不支持表级恢复,因此 C 副本上的表级恢复仅支持先恢复为行存,待后台调度行转列任务后再转为列存。 |
上述场景下,在进行行存转列存的过程中,尽管当前优化器生成的是列存查询计划,但实际执行的仍然是对行存基线的查询。用户可以通过视图 CDB_OB_CS_REPLICA_STATS(系统租户)和 DBA_OB_CS_REPLICA_STATS(用户租户)来查询 C 副本的可用信息及行转列的进度,待行转列任务完全结束后,再进行 C 副本上的查询。
sys 租户下,查询所有租户 C 副本日志流中 Tablet 行转列进度的示例如下:
obclient[oceanbase]> SELECT * FROM oceanbase.CDB_OB_CS_REPLICA_STATS;
查询结果如下:
+-----------+----------------+----------+-------+------------------+----------------------+-----------------------+---------------------------+-----------+
| TENANT_ID | SVR_IP | SVR_PORT | LS_ID | TOTAL_TABLET_CNT | AVAILABLE_TABLET_CNT | TOTAL_MACRO_BLOCK_CNT | AVAILABLE_MACRO_BLOCK_CNT | AVAILABLE |
+-----------+----------------+----------+-------+------------------+----------------------+-----------------------+---------------------------+-----------+
| 1004 | xx.xxx.xxx.212 | 63000 | 1001 | 1019 | 1019 | 10706 | 10706 | TRUE |
| 1006 | xx.xxx.xxx.212 | 63000 | 1001 | 133 | 133 | 875 | 875 | TRUE |
+-----------+----------------+----------+-------+------------------+----------------------+-----------------------+---------------------------+-----------+
2 rows in set
从第一行查询结果可知,租户 ID 为 1004 的租户,其 C 副本所在的服务器为 xx.xxx.xxx.212,端口号为 63000; C 副本日志流的 ID 为 1001;当前需要转换为列存的分区总数为 1019,可用的分区总数为 1019;当前总的基线宏块数为 10706,可用的基线宏块数为 10706。用户可以通过 AVAILABLE_TABLET_CNT / TOTAL_TABLET_CNT 或者 AVAILABLE_MACRO_BLOCK_CNT /TOTAL_MACRO_BLOCK_CNT 来大致估算行转列的进度。仅当日志流上的所有 Tablet 均可用时,该日志流才完全可用。
在 OceanBase 数据库中,Leader 承担事务中的读写请求,因此每个分区 Leader 的分布决定了流量在每个节点上的分布。
流量介绍
数据库系统在应用架构中承担了数据存储和查询的功能,应用的读写请求称为数据库流量。数据库流量分为写流量、强一致读流量和弱一致读流量,写流量和强一致读流量由 OceanBase 数据库的 Leader 副本提供服务,弱一致读流量由 Leader 副本和 Follower 副本提供服务。ODP 提供了数据库流量的路由选择能力,ODP 实现了一个简单的 SQL Parser 模块,解析出 SQL 中的库名、表名及 hint,从而根据业务 SQL、路由规则、及 OBServer 节点的状态,选择最合适的一个 OBServer 节点转发请求。
Primary Zone 介绍
流量分布通过 Primary Zone 来描述,Primary Zone 描述了 Leader 副本的偏好位置,而 Leader 副本承载了业务的强一致读写流量,即 Primary Zone 决定了 OceanBase 数据库的流量分布。假设某张表 t1 的 primary_zone="Zone1",则 RootService 会尽量将 t1 表的 Leader 调度到 Zone1 上来。
说明
副本描述的对象是数据,而 Primary Zone 描述的对象是承载数据的容器,从而该容器下的数据继承容器的 Primary Zone 属性所描述的 Leader 偏好位置。OceanBase 数据库当前版本仅支持租户级别的 Primary Zone,而 OceanBase 数据库 V3.x 还支持表级、DB级、Table Group 级别配置 Primary Zone。
Primary Zone 实际上是一个 Zone 的列表,列表中包含多个 Zone。该列表用如下方式为 Zone 配置优先级:
当 Primary Zone 列表包含多个 Zone 时,用 ';' 分隔的具有从高到低的优先级;用 ',' 分隔的具有相同优先级,表示流量打散在多个 Zone 上,这几个 Zone 同时提供服务。
例如:'hz1,hz2;sh1,sh2;sz1' 表示 hz1 和 hz2 具有相同的优先级,并且优先级高于 sh1/sh2 和 sz1;sh1 和 sh2 具有相同优先级,并且优先级高于 sz1。
OceanBase 数据库当前版本仅支持租户级别的 Primary Zone,不再支持表级、DB 级、Table Group 级配置 Primary Zone。如果创建租户时未指定 primary_zone,默认填写为 RANDOM,表示各个 Zone 优先级相同。
租户的 Primary Zone 属性可以通过系统租户下 oceanbase.DBA_OB_TENANTS 视图的 PRIMARY_ZONE 字段查看。示例如下:
obclient> SELECT * FROM oceanbase.DBA_OB_TENANTS limit 10;
+-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+
| TENANT_ID | TENANT_NAME | TENANT_TYPE | CREATE_TIME | MODIFY_TIME | PRIMARY_ZONE | LOCALITY | PREVIOUS_LOCALITY | COMPATIBILITY_MODE | STATUS | IN_RECYCLEBIN | LOCKED | TENANT_ROLE | SWITCHOVER_STATUS | SWITCHOVER_EPOCH | SYNC_SCN | REPLAYABLE_SCN | READABLE_SCN | RECOVERY_UNTIL_SCN | LOG_MODE | ARBITRATION_SERVICE_STATUS |
+-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+
| 1 | sys | SYS | 2023-05-17 18:10:19.940353 | 2023-05-17 18:10:19.940353 | RANDOM | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
| 1001 | META$1002 | META | 2023-05-17 18:15:21.455549 | 2023-05-17 18:15:36.639479 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
| 1002 | mysql001 | USER | 2023-05-17 18:15:21.461276 | 2023-05-17 18:15:36.669988 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | 1684398681521302749 | 1684398681521302749 | 1684398681345969089 | 4611686018427387903 | NOARCHIVELOG | DISABLED |
| 1003 | META$1004 | META | 2023-05-17 18:18:19.927859 | 2023-05-17 18:18:36.443233 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
| 1004 | oracle001 | USER | 2023-05-17 18:18:19.928914 | 2023-05-17 18:18:36.471606 | zone1 | FULL{1}@zone1 | NULL | ORACLE | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | 1684398681335427475 | 1684398681335427475 | 1684398681144712832 | 4611686018427387903 | NOARCHIVELOG | DISABLED |
| 1005 | META$1006 | META | 2023-05-18 15:48:57.441320 | 2023-05-18 15:49:12.820051 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
| 1006 | mq_t1 | USER | 2023-05-18 15:48:57.447657 | 2023-05-18 15:49:12.857944 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | 1684398680916392609 | 1684398680916392609 | 1684398680742451346 | 4611686018427387903 | NOARCHIVELOG | DISABLED |
+-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+
7 rows in set
Region 属性
在 OceanBase 数据库中,Zone 有一个 Region 属性(DBA_OB_ZONES 视图的 REGION 字段),表示该 Zone 所处的地区,每个 Zone 仅能配置一个 Region,但一个 Region 内可包含多个 Zone。Primary Zone 的设置隐含的包含了 Leader 偏好的 Region 位置。具体指用户设置 Primary Zone 时包含两层语义:
-
被指定的 Primary Zone 为 Leader 的偏好 Zone 的 Region。
-
被指定 Primary Zone 所在的 Region 为 Leader 偏好的 Region。
具体地,Leader 会被优先调度到最高优先级的 Zone 上去,如果最高优先级的 Zone 上的副本不能成为 Leader,会优先选择同一个 Region 内的其他 Zone 作为 Leader 的位置,从而保证业务访问 OceanBase 数据库尽量不跨城。
Primary Zone 改写
用户设置的 Primary Zone 会由 OceanBase 数据库基于各个 Zone 所在的 Region 进行改写,改写规则如下:
-
将用户设置的 Primary Zone 中的所有 Zone 对应的 Region 列出。例如:
primary_zone为hz1,hz2;sh1,sh2;sz1对应的primary_region的列表为hz,hz;sh,sh;sz。 -
将
primary_region中重复的 Region 去掉,去掉规则为保留第一个出现的 Region,其他 Region 后续重复的 Region 移除,例如hz1,hz2;sh1,sh2;sz1,其primary_region转化为列表hz;sh;sz。 -
依据
primary_region中各 Region 的优先级,对primary_zone进行补充,补充规则如下:将 Primary Zone 中各 Region 对应的 Zone 都取出,重新排列,高优先级 Region 内 Zone 比低优先级 Region 内 Zone 的优先级高,同一 Region 内 Zone 的优先级高低参考原始 Primary Zone 中的优先级。
例如:假设共有 9 个 Zone,sh1、sh2、sh3 三个 Zone 在 Region SH,hz1、hz2、hz3 三个 Zone 在 Region HZ,sz1、sz2、sz3 三个 Zone 在 Region SZ。
-
用户设置的
primary_zone为'sh1;hz1;hz2;sz1';按照改写规则 1 得到 primary_region 为'SH;HZ;HZ;SZ'。按照改写规则 2 得到primary_region为'SH;HZ;SZ'。按规则 3 得到改写后primary_zone为'sh1;sh2,sh3;hz1;hz2;hz3;sz1;sz2,sz3'。解释如下:
三个 Region 的优先级为
SH>HZ>SZ。RegionSH中的 Zone 的优先级高于 RegionHZ和 RegionSZ中 Zone 的优先级。RegionHZ中的 Zone 的优先级高于 RegionSZ中 Zone 的优先级。各 Region 内每个 Zone 的优先级为:在 RegionSH中sh1>sh2=sh3,在 RegionHZ中hz1>hz2>hz3,在 RegionSZ中sz1>sz2=sz3。因此最终得到新的 Primary Zone 为'sh1;sh2,sh3;hz1;hz2;hz3;sz1;sz2,sz3'。Leader 会优先分布在sh1上,当sh1发生故障时,Leader 会依照上面的 Primary Zone 优先级依次分布在sh2和sh3。 -
用户设置的
primary_zone为'sh1,sh2;hz1;hz2;sz1';按照改写规则 1 得到primary_region为'SH,SH;HZ;HZ;SZ'。按照改写规则 2 得到primary_region为'SH;HZ;SZ'。按规则 3 得到改写后primary_zone为'sh1,sh2;sh3;hz1;hz2;hz3;sz1;sz2,sz3'。解释如下:
三个 Region 的优先级为
SH>HZ>SZ。RegionSH中的 Zone 的优先级高于 RegionHZ和 RegionSZ中 Zone 的优先级。RegionHZ中的 Zone 的优先级高于 RegionSZ中 Zone 的优先级。各 Region 内每个 Zone的优先级为:在 RegionSH中sh1=sh2>sh3,在 RegionHZ中hz1>hz2>hz3,在 RegionSZ中sz1>sz2=sz3。因此最终得到新的 Primary Zone 为'sh1,sh2;sh3;hz1;hz2;hz3;sz1;sz2,sz3'。Leader 会优先平均分布在sh1和sh2上,当sh1和sh2发生故障时,Leader 会依照上面 Primary Zone 优先级依次分布在sh3。 -
用户设置的
primary_zone为'sh1,hz1;hz2;sz1';按照改写规则 1 得到primary_region为'SH,HZ;HZ;SZ'。按照改写规则 2 得到primary_region为'SH,HZ;SZ'。按规则 3 得到改写后primary_zone为'sh1,hz1;hz2;sh2,sh3,hz3;sz1;sz2,sz3'。解释如下:
三个 Region 的优先级为
SH=HZ>SZ。RegionSH和 RegionHZ中的 Zone 的优先级高于 RegionSZ中 Zone 的优先级。sh1=hz1>hz2>sh2=sh3=hz3>sz1>sz2=sz3。因此最终得到新的 Primary Zone 为'sh1,hz1;hz2;sh2,sh3,hz3;sz1;sz2,sz3'。Leader 会优先平均分布在sh1和hz1上,当sh1和hz1发生故障时,Leader 会依照上面 Primary Zone 优先级依次分布在hz2。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









