







 本文介绍了如何使用Python3爬虫抓取ONE应用的每日一句内容。首先确定URL规律,接着分析页面源代码定位目标元素,最后编写并执行爬虫程序,成功将每日一句保存至本地。
本文介绍了如何使用Python3爬虫抓取ONE应用的每日一句内容。首先确定URL规律,接着分析页面源代码定位目标元素,最后编写并执行爬虫程序,成功将每日一句保存至本地。
前言
ONE是韩寒的一个团队,主要内容是每日一句话、一幅图片、一篇文章、一个问题。我们此次爬虫的目标就是爬取ONE往期所有的每日一句,并保存下来。每日一句的页面如下图所示。
大致可以按照以下的思路进行:
1.由于是所有的往期,所以要先确定每期页面的url的规律
2.查看页面源代码,确定要爬取内容的位置
3.写爬虫程序,爬取内容并保存
1.确定URL规律
下图是我们要爬取的页面中的三个关键部分:URL、期次、每日一句。
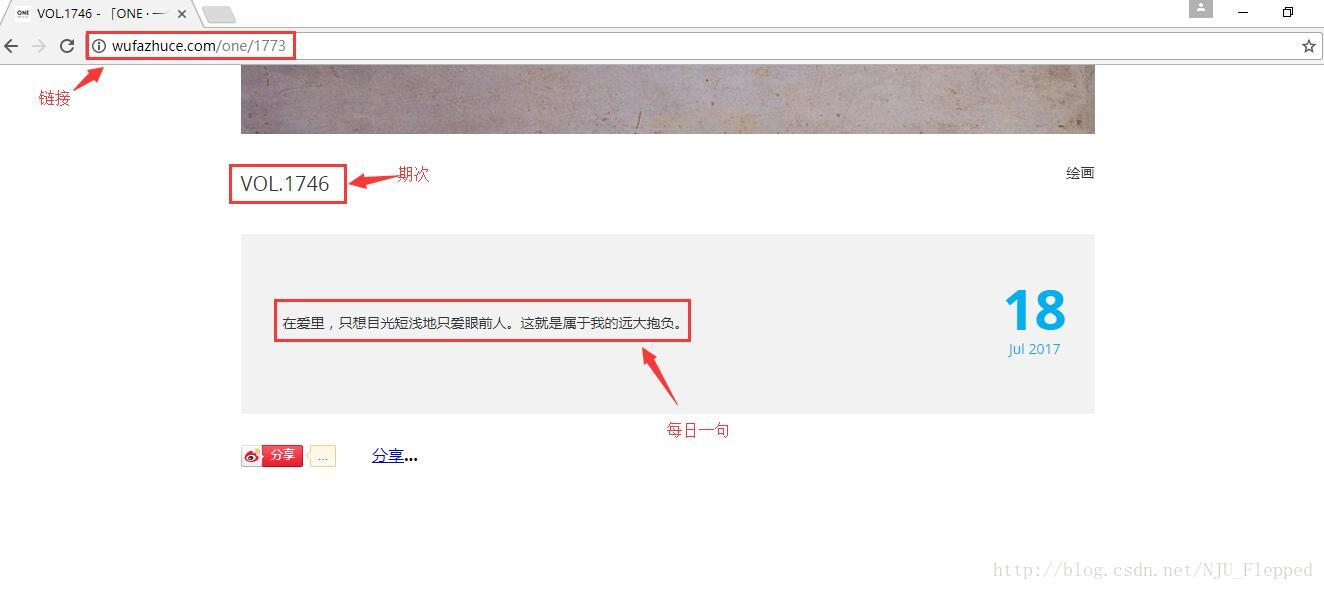
观察URL我们可以看出,每一期的URL公共部分是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









