







 本文探讨了Transformer模型中多头注意力机制的可解释性,提出了自注意力归因算法,用于解释Transformer内部信息交互。研究显示,attention score并不能直接反映重要性,而attribution score能更好地体现注意力依赖对模型预测的影响。此外,通过构建attribution tree,作者可视化了Transformer的信息流动,增强了模型的可解释性,并展示了如何利用这一方法进行注意力头的裁剪和对BERT的非目标攻击。
本文探讨了Transformer模型中多头注意力机制的可解释性,提出了自注意力归因算法,用于解释Transformer内部信息交互。研究显示,attention score并不能直接反映重要性,而attribution score能更好地体现注意力依赖对模型预测的影响。此外,通过构建attribution tree,作者可视化了Transformer的信息流动,增强了模型的可解释性,并展示了如何利用这一方法进行注意力头的裁剪和对BERT的非目标攻击。
©原创作者 | FLPPED
论文:
Self-Attention Attribution: Interpreting Information Interactions Inside Transformer (2021 AAAI论文亚军)
地址:
https://arxiv.org/pdf/2004.11207.pdf
01 研究背景
随着transformer模型的提出与不断发展,NLP领域迎来了近乎大一统的时代,绝大多数预训练方法例如BERT等都将transformer结构作为模型的框架基础,在NLP许多领域的SOTA框架中也常常能看到它的身影。
而transformer的成功很大程度上得益于多头注意力机制,这一机制可对输入的上下文信息进行编码,并且使得模型学习到不同输入token之间的依赖关系。
在多头注意力的可解释性研究方面,有些学者侧重于对注意力权重的分析,重点讨论权重大的特征,有些将模型决策的关注点放在输入的token上,还有部分学者认为注意力机制的分布是无法直接解释的。
相比于过去的研究,本文提出了一种自注意力机制的归因算法,可对transformer内部的信息交互进行可解释性的说明。
通过该方法,模型可识别较重要的注意力head,将其他不重要的head进行有效裁剪。还可通过构建归因树(attribution tree)将不同层之间的信息交互进行直观的可视化表示。
最后,文章还以bert作为扩展的实例应用,通过对归因结果分析构建的Adversarial trigger对Bert发动攻击,使得bert的预测能力显著下降。
02 Transformer简介
首先让我们来重新回顾一下Transformer结构。一般Transformer的结构是由encoder和decoder两部分组成,两者各包含N=6的layer,每个layer由两个sub-layer组成,分别为多头自注意力和全连接网络,具体如图1所示。
Transformer模型的成功很大程度上得益于多头注意力机制。假定每个layer的attention heads数量为h,第h个attention head可用下式(1),(2),(3)表示
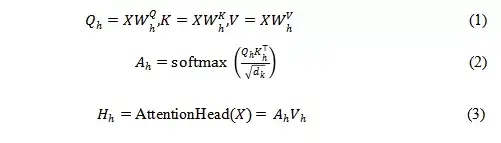
那么每一层多头注意力可表示为:
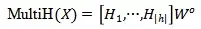
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











