







单例进程(锁文件操作)
- 所谓的单例进程,就是当前系统只能同时运行一个程序
- 比如某些服务程序,数据处理程序
- 这样的文件又称之为锁文件,相当于发现这个文件存在,说明这个锁文件锁定的资源肯定被占用着
- 而发现没有这个锁文件,说明锁定的资源目前没有程序使用
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>
#define LOCK_FILE "/tmp/temp/my.lock"
/*
* 所谓的单例进程,就是当前系统只能同时运行一个程序
* 比如某些服务程序,数据处理程序
* 这样的文件又称之为锁文件,相当于发现这个文件存在,说明这个锁文件锁定的资源肯定被占用着
* 而发现没有这个锁文件,说明锁定的资源目前没有程序使用
* */
int check_lock(const char *lock_file) {
int fd;
fd = open(lock_file, O_CREAT | O_EXCL | O_RDWR, 0666);
if (fd == -1) {
// 如果出的错误不是文件存在出错那?
perror("open");
return 0;
}
// 需要关闭这个文件不?
close(fd);
return 1;
}
void release_lock(const char *lock_file) {
// 删除文件
unlink(lock_file);
}
int main() {
int i;
if (!check_lock(LOCK_FILE)) {
printf("the process already running,ready exit...!\n");
return -1;
}
for (i = 0; i < 10; i++) {
printf("the process running %d ...!\n", i);
sleep(1);
}
release_lock(LOCK_FILE);
return 0;
}
但是如何让程序运行2次呢?Clion的设置如下:
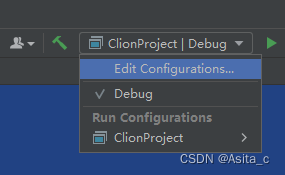
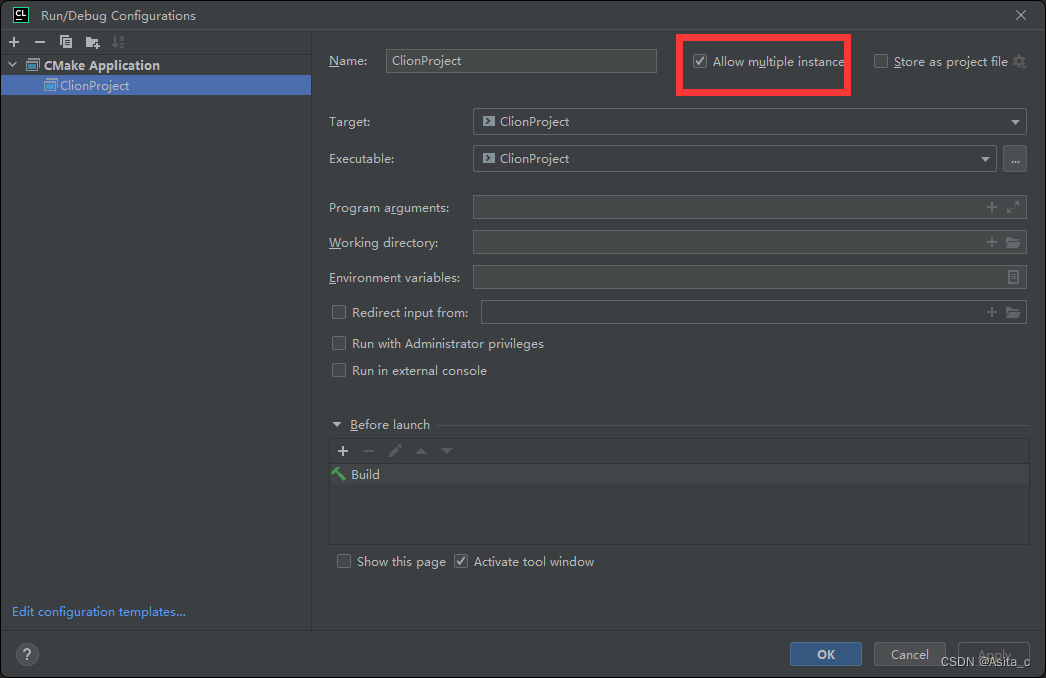
运行2次:
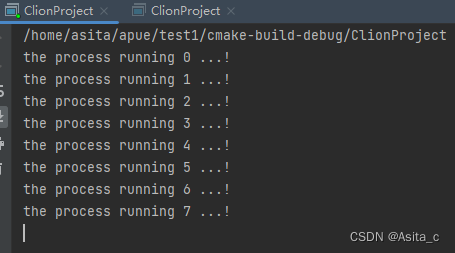
可以看到第一个进程运行结果:
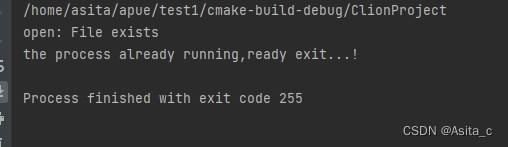
第二个进程运行结果:
然后再第一个进行运行完之后,再运行第3个进程:
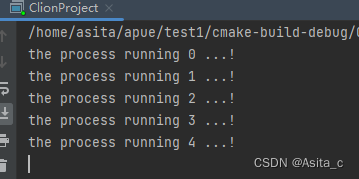
又可以成功运行了,这就实现对临界资源的互斥访问,这里是用文件存在的方式来作为操作系统中的锁,这个锁有很多实现方式,还可以用全局变量来实现
系统出错反馈
- Linux系统提供了一个全局整型错误代号errno变量,只需要包含errno.h即可
- 每一个系统调用反馈的错误,内核都定义了一个整型数字来代表具体的错误
- 可以通过strerror将错误号对应的错误描述返回回来
- 相比perror来说,通过errno更灵活,而且可以将错误码返回
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
/*
* Linux系统提供了一个全局整型错误代号errno变量,只需要包含errno.h即可
* 每一个系统调用反馈的错误,内核都定义了一个整型数字来代表具体的错误
* 可以通过strerror将错误号对应的错误描述返回回来
*
* 相比perror来说,通过errno更灵活,而且可以将错误码返回
* */
int main()
{
int fd;
// 当前可执行目录下没有abc.txt文件,人为制造一个错误
fd = open("abc.txt", O_RDWR, 0666);
if (fd == -1) {
printf("the error number is %d\n", errno);
printf("the error info is %s\n", strerror(errno));
return errno;
}
printf("success!\n");
close(fd);
// success的错误码是0
return 0;
}
不同错误是在Linux中以不同的数值定义了,所有大于0的数全是失败。
写文件操作
- write写入方式是将数据写入目标文件,注意是数据,包含字符串和其他二进制内容
- 所以write的关键三要素是:
- 目标文件描述符、写入目标文件的内容首地址、写入目标文件的内容大小(字节)
- write返回的是成功写入目标文件的内容大小(字节),-1代表出错
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#include <string.h>
#define NEW_FILE_NAME "/tmp/temp/tmp_new.txt"
/*
* write写入方式是将数据写入目标文件,注意是数据,包含字符串和其他二进制内容
* 所以write的关键三要素是:
* 目标文件描述符、写入目标文件的内容首地址、写入目标文件的内容大小(字节)
* write返回的是成功写入目标文件的内容大小(字节),-1代表出错
* */
int write_lesson1(const char *filename) {
int fd;
int ret;
unsigned int data1 = 0x63646566;
char buf[10] = "abc";
fd = open(filename, O_CREAT | O_TRUNC | O_RDWR, 0666);
if (fd == -1) {
perror("open");
return -1;
}
// 写入整型空间内容
ret = write(fd, &data1, sizeof(data1));
if (ret == -1){
perror("write");
return -1;
}
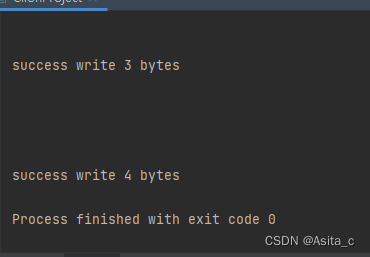
printf("success write %d bytes\n", ret);
getchar();
// 写入字符串空间
ret = write(fd, buf, strlen(buf));
if (ret == -1){
perror("write");
return -1;
}
printf("success write %d bytes\n", ret);
getchar();
// 写入任意空间
data1 = 3113787376;
ret = write(fd, &data1, sizeof(data1));
if (ret == -1) {
perror("write");
return -1;
}
printf("success write %d bytes\n", ret);
}
/*
* 对于回车和换行,实际是2个控制字符\r\n
* \r : 0x0d \n : 0x0a
* */
int write_lesson2(const char *filename) {
int fd;
char a = '\n';
int ret;
fd = open(filename, O_CREAT | O_TRUNC | O_RDWR, 0666);
if (fd == -1) {
perror("open");
return -1;
}
ret = write(fd, "abc", 3);
if (ret == -1){
perror("write");
return -1;
}
write(fd, &a, 1);
write(fd, "123", 3);
close(fd);
}
int main()
{
write_lesson1(NEW_FILE_NAME);
return 0;
}


此时写入了4个字节
用od命令查看二进制的存储形式

用vim 查看

写入的数字变成了字母
敲回车,让程序继续运行:
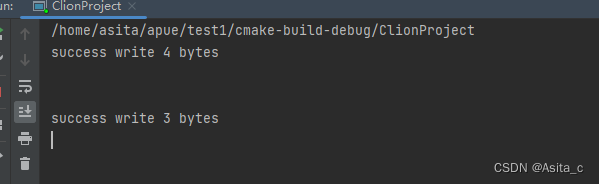
ps:sizeof跟strlen的区别:
strlen 测量的是字符的实际长度,以’\0’ 结束(不包含’\0’ )。而sizeof 测量的是字符的分配大小,如果未分配大小,则遇到’\0’ 结束(包含’\0’ ,也就是strlen测量的长度加1),如果已经分配内存大小,返回的就是分配的内存大小。
我们知道字符串是以 ‘\0’ 为结束标志的,所以char str1[ ] = “hello” 等效于char str2[ ] = {‘h’ , ‘e’ , ‘l’ , ‘l’ , ‘o’ , ‘\0’} 。strlen函数求的是字符串的实际长度,它求得方法是从开始到遇到第一个’\0’,如果你只定义没有给它赋初值,这个结果是不定的,它会从首地址一直找下去,直到遇到’\0’停止。而如果不在字符数组初始化的时候加上\0,那么strlen 得到的值就不是正确的数值,打印出来的结果也不是想要的结果。因此我们要避免这种情况,在初始化的时候要记得加上 \0,或者一次性赋初值。
strlen的结果要在运行的时候才能计算出来,是用来计算字符串的长度,不是类型占内存的大小。而大部分编译程序在编译的时候就把sizeof计算过了是类型或是变量的长度。
sizeof可以用类型做参数,strlen只能用char*做参数,且必须是以’‘\0’'结尾的。

abc对应的ascii码就是616263
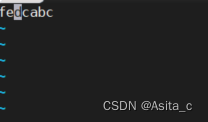
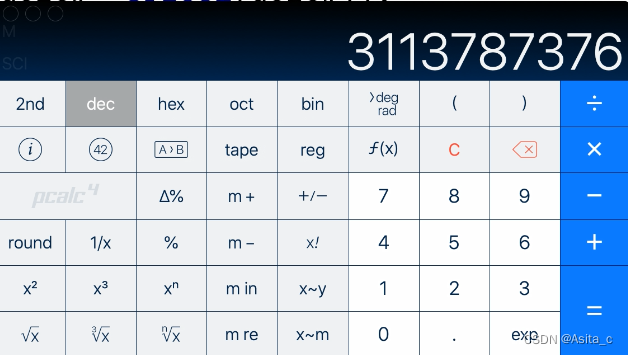
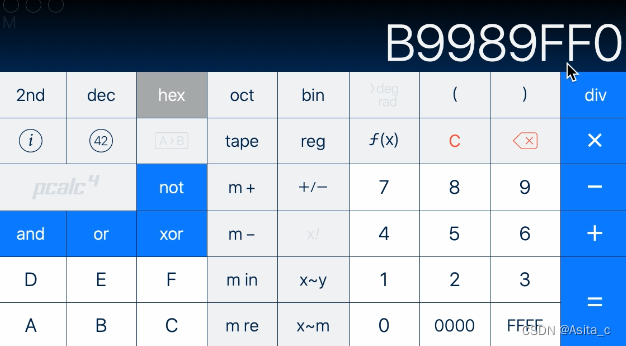
再次回车
用二进制的方式查看

可以看到,这里写进去的不是数字的字符,而且把数字写进去了
但是用vim打开:
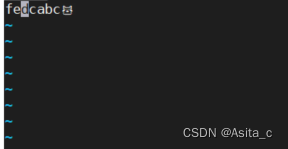
变成表情包了
这是因为这个数值对应了一个码表上的一个符号,便是这个表情包
读文件操作
- read是从目标文件的驱动层中将数据转移到用户应用空间的一种方法
- 从调用者的角度来看,我不清楚驱动层有多少数据,所以调用者应该把最大能读取的空间交给内核
- 然后通过返回值的信息进行下一步的处理



读文件操作实验
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#define NEW_FILE_NAME "/tmp/temp/tmp_new.txt"
/*
* read是从目标文件的驱动层中将数据转移到用户应用空间的一种方法
* 从调用者的角度来看,我不清楚驱动层有多少数据,所以调用者应该把最大能读取的空间交给 内核
* 然后通过返回值的信息进行下一步的处理
*
* */
int read_lesson1(const char *filename) {
int fd;
char buf[1024];
int ret;
fd = open(filename, O_RDONLY);
if (fd == -1) {
perror("open");
return -1;
}
printf("open file success!\n");
ret = read(fd, buf, sizeof(buf));
if (ret < 0) {
perror("read");
return -1;
} else if (ret == 0) {
printf("read end of file");
return 0;
}
printf("the read content is :%s\n", buf);
return 0;
}
/*
* read需要循环读取,直到遇到文件结束标志
* */
int read_lesson2(const char *filename) {
int fd;
char buf[1024];
int ret;
int pos;
fd = open(filename, O_RDONLY);
if (fd == -1) {
perror("open");
return -1;
}
printf("open file success!\n");
pos = 0;
ret = read(fd, buf+pos, 3);
while (ret) {
pos += ret;
ret = read(fd, buf+pos, 3);
}
printf("the read total is %d\n", pos);
buf[pos] = 0;
printf("the content is %s\n", buf);
return 0;
}
int main() {
read_lesson1(NEW_FILE_NAME);
}
执行read_lesson1:

执行read_lesson2:
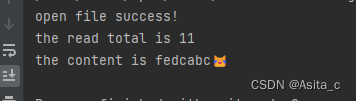
可以看到,第一种方法是直接以buf的大小来进行读取,这样的做有几个弊端:
- 它只能处理小于或等于1024字节的文件,如果文件大于1024字节,那么就会丢失部分数据,这可能导致文件内容的错误或不完整。
- 它没有给缓冲区添加字符串结束符0,如果文件中没有换行符或其他空白字符,那么打印出来的内容可能会有乱码或垃圾数据,这可能影响文件内容的可读性或正确性。(这就是为什么第一个函数运行结果有乱码)
- 它没有记录当前读取的位置,只是简单地打印出了缓冲区的内容,如果需要对文件内容进行进一步的处理或分析,那么就需要重新读取文件或使用其他变量来存储当前读取的位置,这可能增加程序的复杂度或开销。
第二种方式的好处:
- read_lesson2使用了一个循环,每次从文件中读取3个字节(这个可以自己设置具体多少)的数据,直到读到文件末尾或出错为止。这样可以处理任意大小的文件,而不需要担心缓冲区溢出的风险。而read_lesson1只调用了一次read函数,一次性从文件中读取1024个字节的数据,如果文件大于1024字节,那么就会丢失部分数据;如果文件小于1024字节,那么就会浪费部分空间。
- read_lesson2在每次读取后,将当前读取的位置pos加上实际读取的字节数ret,这样可以记录下当前读取到了哪里,方便后续的处理。而read_lesson1没有记录当前读取的位置,只是简单地打印出了缓冲区的内容
- read_lesson2在最后给缓冲区添加了一个字符串结束符0,这样可以保证缓冲区中存储的是一个合法的字符串,方便后续的操作。而read_lesson1没有给缓冲区添加字符串结束符,如果文件中没有换行符或其他空白字符,那么打印出来的内容可能会有乱码或垃圾数据。
文件拷贝案例
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
int copy_file(const char *dest_file, const char *src_file) {
int dest_fd;
int src_fd;
char buf[1024];
int ret, size_ret;
int total = 0;
dest_fd = open(dest_file, O_CREAT | O_TRUNC | O_WRONLY, 0666);
if (dest_fd == -1) {
perror("open dest file:");
return -1;
}
src_fd = open(src_file, O_RDONLY);
if (src_fd == -1) {
perror("open src file:");
return -1;
}
ret = read(src_fd, buf, sizeof(buf));
while (ret) {
if (ret == -1) {
perror("read src file:");
return -1;
}
size_ret = write(dest_fd, buf, ret);
total += size_ret;
ret = read(src_fd, buf, sizeof(buf));
}
printf("copy %d bytes success!\n", total);
close(src_fd);
close(dest_fd);
return 0;
}
int main() {
char *src = "/bin/vdir";
char *dest = "/tmp/temp/vvdir";
if (copy_file(dest, src)) {
printf("copy failed!\n");
return -1;
}
printf("copy success!\n");
return 0;
}



拷贝成功!
lseek
文件光标
(文件描述符,偏移量,参照物)

文件偏移操作实验
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#define NEW_FILE_NAME "/tmp/temp/tmp_new.txt"
/*
* lseek将对应的文件描述指向的驱动空间进行坐标移动
* 移动参考点:SEEK_SET: 文件开头 SEEK_END: 文件结尾 SEEK_CUR: 文件当前位置
* */
int read_file(const char *filename) {
int fd;
char buf;
fd = open(filename, O_RDONLY);
if (fd == -1) {
perror("open");
return -1;
}
lseek(fd, 1, SEEK_SET);
read(fd, &buf, 1);
printf("the read buf is %x\n",buf);
close(fd);
return 0;
}
int read_file2(const char *filename, int size) {
int fd;
fd = open(filename, O_WRONLY);
if (fd == -1) {
perror("open");
return -1;
}
lseek(fd, size -1, SEEK_END);
write(fd, "123", 3);
close(fd);
}
int main() {
read_file(NEW_FILE_NAME);
}
实验结果:


65刚好是光标从最开始偏移一位后的结果
执行empty_file()函数:
int main() {
read_file2(NEW_FILE_NAME,1);
}
从文件末尾开始写入:


空洞文件
空洞文件的概念:
“在UNIX文件操作中,文件位移量可以大于文件的当前长度,在这种情况下,对该文件的下一次写将延长该文件,并在文件中构成一个空洞,这一点是允许的。位于文件中但没有写过的字节都被设为 0。” --摘自“百度百科
具体解释:
lseek()系统调用可以修改文件的当前读写位置偏移量,此函数不但可以改变位置偏移量,并且还允许文件偏移量超出文件长度,这是什么意思呢?譬如有一个 test_file,该文件的大小是 4K(也就是 4096 个字节),如果通过 lseek 系统调用将该文件的读写偏移量移动到偏移文件头部 6000 个字节处,大家想一想会怎样?
接下来使用 write()函数对文件进行写入操作,也就是说此时将是从偏移文件头部 6000 个字节处开始写入数据,也就意味着 4096~6000 字节之间出现了一个空洞,因为这部分空间并没有写入任何数据,所以形成了空洞,这部分区域就被称为文件空洞,那么相应的该文件也被称为空洞文件。文件空洞部分实际上并不会占用任何物理空间,直到在某个时刻对空洞部分进行写入数据时才会为它分配对应的空间,但是空洞文件形成时,逻辑上该文件的大小是包含了空洞部分的大小的。
空洞文件的作用:
例如:迅雷下载文件时,在未下载完成时,就已经占据了全部文件大小的空间,这时候就是空洞文件。下载的时候如果没有空洞文件,多线程下载时文件就都只能从一个地方写入,这就不是多线程了,如果有了空洞文件,可以从不同的地址写入,就完成了多线程的优势任务。
一般大文件才这样操作。
空洞文件的创建
例子:创建一个约64M的空洞文件:
int empty_file(const char *filename, unsigned int size) {
int fd;
fd = open(filename, O_CREAT | O_TRUNC |O_WRONLY,0666);
if (fd == -1) {
perror("open");
return -1;
}
//使用size-1而不是size是为了保证文件实际大小和指定大小一致,并且避免超出文件范围
lseek(fd, size -1, SEEK_SET);
//这里写入的空串实际上就是“/0”
write(fd, "", 1);
close(fd);
}
int main() {
empty_file(NEW_FILE_NAME,1);
}

















 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











