






“你看见的每一个伟大的模型,都由小小的积木构成。”
在前几篇文章中,我们分别手撕了 TokenEmbedding、PositionEmbedding、Attention 的核心计算细节。从今天开始,我们将走进 Transformer 编码器部分的主干 —— Encoder 模块,来看它是如何“积木式”地组合出一个强大特征抽取器的。
Encoder 是 Transformer 架构中最重要的组成部分之一,尤其在 NLP 任务如文本分类、机器翻译、语言建模等中,它承担了 “理解输入语义、捕捉上下文依赖” 的关键角色。
本篇我们将:
-
手动实现 Encoder 模块及其内部子结构
-
逐步分析每一层的功能、作用及输入输出
-
辅以测试代码、可视化、注意力矩阵等方法,帮助你彻底吃透 Encoder 的工作机制
1. Encoder 模块整体结构
2. Encoder Layer 内部拆解
2.1 Multi-Head Attention
2.2 Scaled Dot-Product Attention
2.3 LayerNorm 与残差连接
2.4 FeedForward 前馈网络
3. 总结与后续篇章预告
💡 阅读建议:本篇适合已有一定 PyTorch 编程经验,并具备 Transformer 基本原理认知的同学阅读。配合调试和可视化效果,效果更佳!
一、开篇
在手撕系列的前三章节中(手撕Transfomer系列(01/02/03)https://blog.csdn.net/Nathan0921/article/details/147083625?spm=1001.2014.3001.5501),我们已经对数据的处理给出了清晰的解析和代码结构,那么从第3篇开始i,我们尝试着把Transformer打碎、揉开,解构内部构成,以及如何协同完成工作,并于联系起来。根据Attention Is All You Need文章中的结构图,我们正处在这个部分:
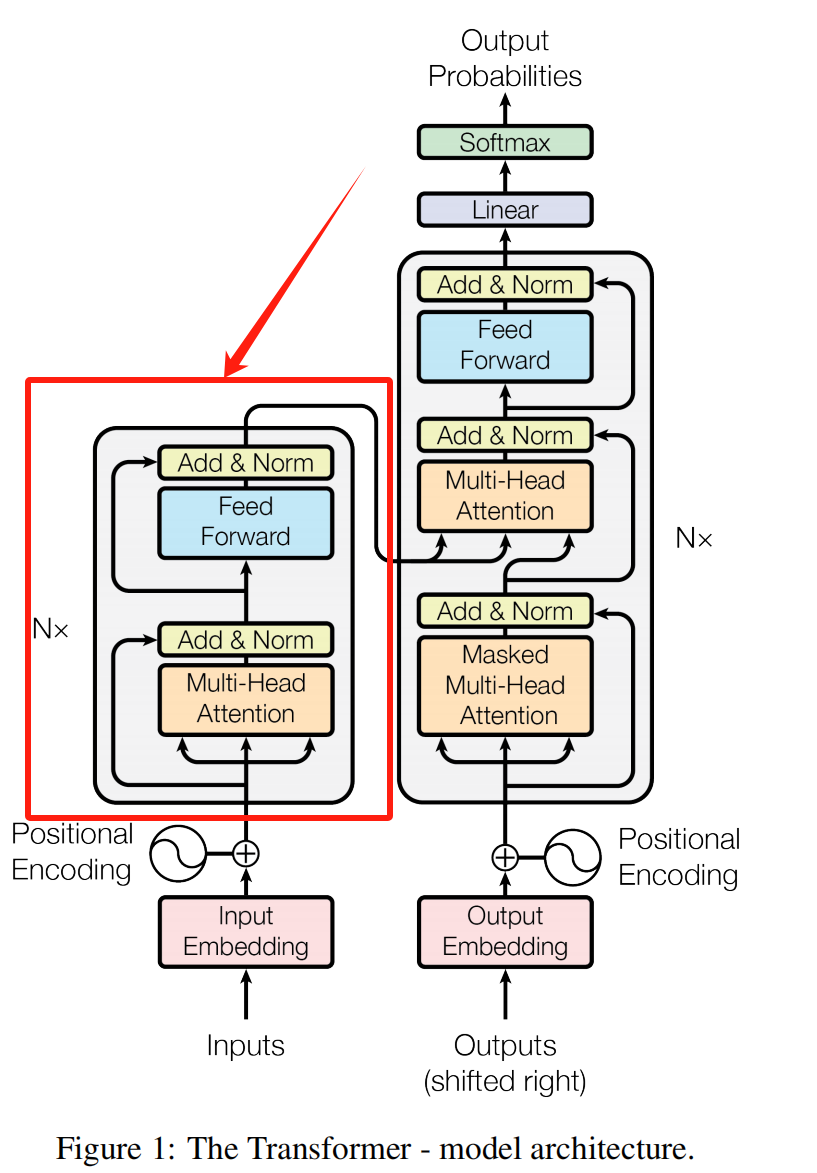
二、整体Encoder的代码解构
💥 Scaled Dot-Product Attention
📌 什么是 Scaled Dot-Product Attention?
在 Transformer 中,“Attention” 的本质就是一种信息加权聚合机制,即:
给定一个 Query(查询)向量,我们从一堆 Key(键)向量中计算其相关性,然后使用这些相关性权重去加权组合对应的 Value(值)向量。
这就是我们所说的:
“注意力机制 = 相似度打分 + 权重加权”
而 Scaled Dot-Product Attention(缩放点积注意力) 是这一机制的具体数学实现方式。

🧪 PyTorch 实现代码
"""
Scaled Dot-Product Attention单头注意力机制
要点如下:
1. 计算注意力权重矩阵:QK^T/sqrt(d_k)
2. 计算softmax:softmax(QK^T/sqrt(d_k))
3. 计算注意力输出:softmax(QK^T/sqrt(d_k))V
#数据输入输出:
输入:Q、K、V的shape应该是(batch_size, num_heads, seq_len, d_model_i)
.....
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self,q, k, v, mask=None, e=1e-12):
"""
input_shape is 4 dimension tensor
batc_size, head, length, d_tensor
"""
# 这里的输入就已经出来了 [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot production attention Query with Key^T to compute similarity
k_t = k.transpose(2, 3)
score = (q @ k_t) / math.sqrt(d_tensor) # (batch_size, head, length, length)
# 2. apply mask if needed
if mask is not None:
if mask.size(1) == 1:
mask = mask.expand(-1, head, -1, -1)
score = score.masked_fill(mask == 0, -1e9)
# 3. apply softmax to get attention weights
score = self.softmax(score)
# 4. multiply with value to get output
output = score @ v
# output shape is (batch_size, head, length, d_tensor)
return output, score # output shape is (batch_size, head, length, d_tensor), score shape is (batch_size, head, length, length)
if __name__ == '__main__':
print("🧠 Scaled Dot-Product Attention Demo")
batch_size = 2
heads = 4
seq_len = 5
d_k = d_v = 8
Q = torch.rand(batch_size, heads, seq_len, d_k)
K = torch.rand(batch_size, heads, seq_len, d_k)
V = torch.rand(batch_size, heads, seq_len, d_v)
print(Q)
mask = torch.ones(batch_size, 1, 1, seq_len)
print(mask)
attn = ScaledDotProductAttention()
output, score = attn(Q, K, V, mask)
# output, score = attn(Q, K, V)
print(output)
print(score)
print("output shape: ", output.shape)
print("score shape: ", score.shape)
# 可视化第一个样本第一头的注意力权重
import matplotlib.pyplot as plt
import seaborn as sns
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
sns.heatmap(score[0, 0].detach().numpy(), cmap='viridis', annot=True)
plt.title("Attention Weights (Head 1, Sample 1)")
plt.xlabel("Key Position")
plt.ylabel("Query Position")
plt.show()
# 整个处理过程总结:
# 1.需要注意的是,输入的Q、K、V都是4维的张量,形状为(batch_size, head, length, d_tensor)
# 2.在计算注意力分数时,使用了点积的方式,并且进行了缩放处理
# 3.如果有mask,则将mask为0的位置的分数设置为一个很小的值(-100000)
# 4.最后通过softmax函数计算注意力权重,并与值V进行矩阵乘法得到最终的输出 🔍 输入输出的形状说明
-
输入
q,k,v:维度是[batch_size, heads, seq_len, d_k] -
输出
output:同样形状[batch_size, heads, seq_len, d_k] -
输出
attention_weights:形状为[batch_size, heads, seq_len, seq_len]
注意:attention_weights 是每一个 Query 与所有 Key 的相似度,构成了“注意力矩阵”。
最终输出的结果是这样的:
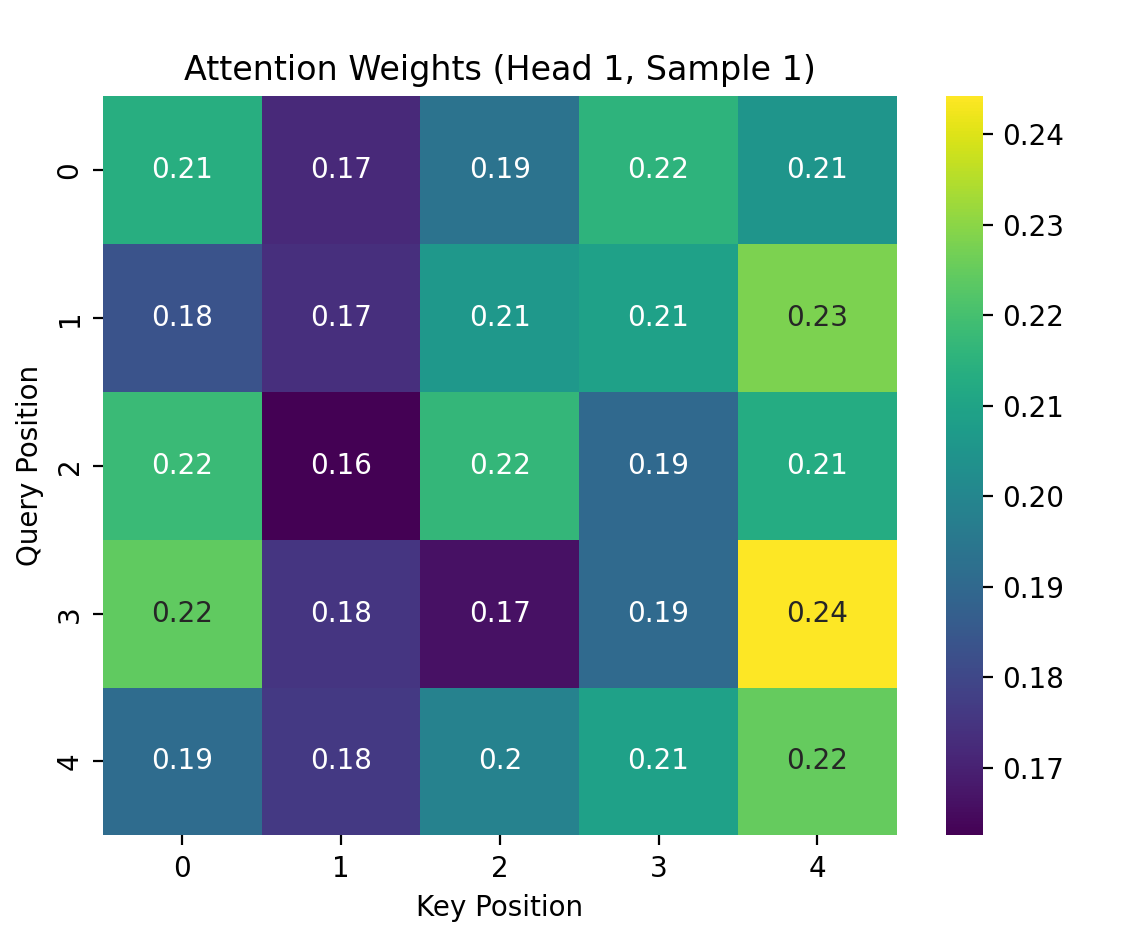
❓为什么要除以 √d_k?
为了避免在维度较高时点积结果过大,导致 softmax 输出极端偏向(梯度消失),所以进行缩放操作,保持分布稳定。
✅ 小结
| 组件 | 功能 |
|---|---|
| 点积计算 | 捕捉 Query 与 Key 的相关性 |
| 缩放 √d_k | 保证稳定梯度和数值分布 |
| Softmax | 将打分转化为概率分布(权重) |
| 加权求和 | 根据权重聚合 Value 向量,得到最终输出 |
🔗 接下来,我们将在上层模块 Multi-Head Attention 中复用这个机制,并将多个头的结果拼接,进一步增强模型的表达能力。
🚀 Multi-Head Attention(多头注意力机制)
🎯 核心理念:为什么要多头?
在上一节我们了解了 Scaled Dot-Product Attention 的工作机制,但问题来了:
如果我们只用一个头(Single Attention),是不是太单一了?我们可能只能看到一种维度下的注意关系,缺乏多角度的感知。
于是,Transformer 提出了一种非常聪明的机制:
🧠 多头注意力(Multi-Head Attention)= 多个子空间并行感知
-
将输入的 Q、K、V 各自线性映射到多个子空间
-
在每个子空间上分别执行一次 attention(并行)
-
最后将所有注意力头的输出拼接在一起,再线性变换回来
这样做的好处:
-
不同的头学到了不同的“注意力视角”
-
模型整体更加鲁棒、表达力更强!
Input (Q, K, V)
│
├─ Linear → Split → [head_1] ┐
├─ Linear → Split → [head_2] │ → Scaled Dot-Product Attention
├─ Linear → Split → [head_3] │
└─ Linear → Split → [head_h] ┘
↓
Concatenate all heads
↓
Linear projection
↓
Output
🔧 PyTorch 实现
"""
Multi-head attention layer多头注意力机制要点:
1. 通过线性变换将输入的Q、K、V映射到多个头上
2. 对每个头分别计算注意力分数
3. 将所有头的输出拼接在一起,并通过线性变换得到最终的输出
4. 可以使用掩码来屏蔽掉不需要关注的部分
"""
import sys
import os
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
import torch
import torch.nn as nn
from models.layers.Scale_dot_product_attention import ScaledDotProductAttention
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.d_model = d_model
self.attention = ScaledDotProductAttention()
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_concat = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2. split into n_head
q, k, v = self.split_heads(q), self.split_heads(k), self.split_heads(v)
# 3. apply scale dot product to compute attention
out, attention = self.attention(q, k, v, mask=mask)
# 4. concat heads
out = self.concat_heads(out)
# 5. apply final linear transformation
out = self.w_concat(out)
return out
def split_heads(self, tensor):
# tensor shape is (bathch_size, length, d_model)
# split into n_head
# tensor shape is (batch_size, n_head, length, d_model/n_head)
batch_size, length, d_model = tensor.size()
d_tensor = d_model // self.n_head
tensor = tensor.view(batch_size, length, self.n_head, d_tensor).transpose(1, 2)
# tensor.shape is (batch_size, n_head, length, d_tensor)
return tensor
def concat_heads(self, tensor):
# tensor.shape is (batch_size, n_head, length, d_tensor)
# concat heads
# tensor shape is (batch_size, length, d_model)
batch_size, n_head, length, d_tensor = tensor.size()
d_model = n_head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, d_model)
# tensor.shape is (batch_size, length, d_model)
# 这里给清楚它的操作过程:
# 1. tensor.transpose(1, 2)的操作是将tensor的第1维和第2维交换位置 对应的张量情况是:
# tensor.shape is (batch_size, length, n_head, d_tensor)
# tensor.transpose(1, 2).contiguous()操作是将tensor的内存布局变为连续的
return tensor
if __name__ == '__main__':
print("🧠 Multi-head Attention Demo")
batch_size = 2
heads = 8
seq_len = 5
d_model = 512
Q = torch.rand(batch_size, seq_len, d_model)
K = torch.rand(batch_size, seq_len, d_model)
V = torch.rand(batch_size, seq_len, d_model)
# print(Q)
multi_head_attention = MultiHeadAttention(d_model, heads)
out = multi_head_attention(Q, K, V)
print(out) # (batch_size, seq_len, d_model)
# Multi-head attention layer多头注意力机制要点:
# 1. 通过线性变换将输入的Q、K、V映射到多个头上
# 2. 对每个头分别计算注意力分数
# 3. 将所有头的输出拼接在一起,并通过线性变换得到最终的输出
# 4. split_heads函数将输入的Q、K、V分成多个头
# 5. concat_heads函数将多个头的输出拼接在一起
# 代码练习题:请补全以下代码:将输入的 [batch, seq_len, d_model]
# 通过线性映射和 reshape,转换成 [batch, heads, seq_len, d_k]。
def transform_heads(x, num_heads, d_k):
batch_size, seq_len, d_model = x.size()
x = x.view(batch_size, seq_len, num_heads, d_k)
x_transformed = x.transpose(1, 2)
return x_transformed
# 代码练习题:写出一个 MultiHeadAttention 的 forward 输入输出接口定义,说明各参数含义(非代码)
# 1. def forward(self, q, k, v, mask=None):
# - q: 输入的查询向量,形状为 (batch_size, seq_len, d_model)
# - k: 输入的键向量,形状为 (batch_size, seq_len, d_model)
# - v: 输入的值向量,形状为 (batch_size, seq_len, d_model)
# - mask: 可选的掩码,形状为 (batch_size, 1, seq_len, seq_len),用于屏蔽掉不需要关注的部分
# - 返回值:输出的注意力向量,形状为 (batch_size, seq_len, d_model)
# - 返回值:注意力权重,形状为 (batch_size, n_head, seq_len, seq_len)📐 形状转换小贴士
| 阶段 | Shape |
|---|---|
| 输入 Q/K/V | [batch_size, seq_len, d_model] |
| Linear 映射后 reshape | [batch_size, n_heads, seq_len, d_k] |
| 注意力输出 context | [batch_size, n_heads, seq_len, d_k] |
| 拼接后还原 | [batch_size, seq_len, d_model] |
📊 可视化(和上一节一样)
如果你打印 attn_weights[0, 0],可以看到第一个样本、第一个头的注意力矩阵,非常直观!
🧠 小结
| 步骤 | 说明 |
|---|---|
| Linear 映射 | 将输入映射到多个头子空间 |
| 并行注意力 | 在每个头上独立执行 scaled dot-product attention |
| 拼接 heads | 汇总不同头的信息 |
| 残差连接 + LayerNorm | 保持梯度流通和数值稳定 |
✅ 你学到了什么?
-
为什么要多头? —— 多角度表达注意力信息
-
如何实现? —— 拆头 → 独立计算 → 拼接 → 输出
-
实战重点? —— reshape 的理解 + LayerNorm 的位置
🧱 Position-wise Feed Forward Network(前馈全连接网络)
🎯 为什么还要加一层 FFN?
前面 Multi-Head Attention 已经完成了“全局信息交互”,也就是让每个 token 能“看到”序列中其他位置的内容。
但注意力模块本质上是加权平均,它缺乏对特征进行非线性变换和表达提升的能力。所以我们需要:
💡 在每个位置上,单独做一次全连接 + 激活函数的特征加工,这就是 FFN 的工作。
🧠 核心思想
这个模块对序列中每个位置的表示,单独、独立地送入一个两层的全连接网络进行处理。
-
所以叫它 Position-wise(按位置独立)
-
每个 token 表示向量都走一遍全连接 → ReLU → Dropout → Linear
📐 网络结构
输入: [batch_size, seq_len, d_model]
↓
Linear(d_model → hidden_dim)
↓
ReLU
↓
Dropout
↓
Linear(hidden_dim → d_model)
↓
输出: [batch_size, seq_len, d_model]
一般 hidden_dim 设置为 2048(比原始维度大),起到升维压缩的作用,提升表达能力。
🔧 PyTorch 实现
from torch import nn
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, hidden_dim, dropout=0.1):
super(PositionWiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden_dim)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(hidden_dim, d_model)
self.relu = nn.ReLU()
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
if __name__ == "__main__":
import torch
x = torch.randn(32, 10, 512) # (batch_size, seq_len, d_model)
ff = PositionWiseFeedForward(d_model=512, hidden_dim=2048)
output = ff(x)
print(output.shape) # (32, 10, 512)🔧 为什么加 LayerNorm 和残差连接?
-
残差连接(+ residual):避免梯度消失,使网络更易训练
-
LayerNorm:归一化每个 token 的特征维度,保持数值稳定
这一点和 Multi-Head Attention 一样:Transformer 的所有子模块都有 LayerNorm 和残差连接机制,保证训练深层网络不会出现梯度爆炸或梯度消失。
🧠 小结
| 模块 | 功能 |
|---|---|
| Linear + ReLU + Linear | 非线性表达、升维压缩 |
| Dropout | 防止过拟合 |
| LayerNorm | 保持数值稳定 |
| Residual | 保留原始信息、促进训练 |
✅ 你现在应该清楚:
-
FFN 是对每个位置单独做非线性变换
-
主要用于增强特征的表达能力
-
本质是两层 MLP,加上残差 & LayerNorm
🧩 Encoder Layer(编码器层)
🎯 为什么要有 Encoder Layer?
到目前为止,我们已经了解了:
-
多头注意力:能提取序列中不同位置之间的依赖关系
-
前馈网络(FFN):对每个位置的向量做非线性变换,增强表达能力
但是这两个功能模块并不是独立存在的,而是被打包在一起构成了:
💡 Transformer 的基本构建单元:Encoder Layer
🏗️ 结构图
一个标准的 Encoder Layer 包含两个核心子模块,每个模块后面都跟着残差连接和 LayerNorm:
Input
│
├──► Multi-Head Attention
│ + Residual
│ + LayerNorm
↓
├──► Position-wise Feed Forward
│ + Residual
│ + LayerNorm
↓
Output
🔧 PyTorch 实现
"""
Encoder_Layer 单层encoderd的封装:
1. 由多头自注意力机制和前馈神经网络组成
2. 采用残差连接和LayerNorm
3. 前馈神经网络由两个线性变换和一个ReLU激活函数组成
4. 多头自注意力机制由多个头组成,每个头都有自己的线性变换和缩放点积注意力计算
5. 多头自注意力机制的输出经过线性变换和dropout
"""
import torch
import torch.nn as nn
import sys
import os
# 添加项目根目录到 sys.path
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
from models.layers.multi_head_attention import MultiHeadAttention
from models.layers.position_wise_feed_forward import PositionWiseFeedForward
from models.layers.Layer_norm import LayerNorm
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, ffn_hidden, dropout):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model, n_heads)
self.norm1 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.ffn = PositionWiseFeedForward(d_model, ffn_hidden, dropout)
self.norm2 = LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, s_mask):
# 1. compute self-attention
# print("encoder layer x:", x.shape)
_x = x
x = self.attention(q=x, k=x, v=x, mask=s_mask)
# 2. add & norm
x = self.dropout1(x)
x = self.norm1(x + _x)
# 3. position-wise feed forward
_x = x
x = self.ffn(x)
# 4. add & norm
x = self.dropout2(x)
x = self.norm2(x + _x)
return x
if __name__ == "__main__":
print("Encoder Layer Test")
batch_size = 32
seq_len = 10
n_heads = 8
d_model = 512
ffn_hidden = 2048
dropout = 0.1
encoder_layer = EncoderLayer(d_model, n_heads, ffn_hidden, dropout)
x = torch.randn(batch_size, seq_len, d_model) # (batch_size, seq_len, d_model)
s_mask = torch.ones(batch_size, 1, 1, seq_len)
s_mask = s_mask.expand(batch_size, n_heads, seq_len, seq_len)
output = encoder_layer(x, s_mask)
print(output.shape) # (32, 10, 512)
print("Encoder Layer Test Passed")
📎 编码器层的工作流程
-
Multi-Head Attention:让序列中的每个位置关注其他位置
-
残差连接 + LayerNorm:稳定训练,保留输入信息
-
FeedForward 网络:对每个位置的表示做非线性增强
-
再次残差 + LayerNorm
每个 Encoder Layer 可以看作是“一轮自我理解”,让 token 更加理解自身与全局上下文的关系。
🧠 为什么能堆叠多层?
因为每一层都在逐步提升表示:
-
第一层:学习低级依赖
-
第二层:抽象出更高阶语义
-
第三层:全局整合上下文特征
-
…
这也解释了为什么原始 Transformer 模型中的 n_layers=6(甚至 GPT 用几十层):每层都是语义提升!
✅ 小结
| 模块 | 作用 |
|---|---|
| Multi-Head Attention | 建立 token 之间的联系 |
| Position-wise FFN | 非线性增强每个 token 的表示 |
| 残差连接 + LayerNorm | 保持稳定 & 信息不丢失 |
✅ 一个 EncoderLayer 是 Transformer 中最核心的构建模块,它由两大核心子模块组成:Multi-Head Attention + FeedForward,每个都加上 LayerNorm 和残差连接。
这也解释了为什么原始 Transformer 模型中的 n_layers=6(甚至 GPT 用几十层):每层都是语义提升!
🧱 构建完整的 Transformer Encoder(多层堆叠)
📦 1. 什么是 Encoder?
Encoder 的整体结构,其实就是这样一句话的实现:
Embedding + N 层 EncoderLayer 堆叠
输入 → TokenEmbedding + PositionalEncoding
↓
EncoderLayer × N
↓
最终输出
这个结构的意义是:
-
利用 Embedding 将离散 token 编码为稠密向量;
-
通过多层自注意力和前馈网络,逐层抽象、融合上下文语义。
⚙️ 2. 编码器整体 PyTorch 实现
import torch
import torch.nn as nn
import sys
import os
# 添加项目根目录到 sys.path
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
from models.blocks.encoder_layer import EncoderLayer
from models.embedding.transform_embedding import TransformEmbedding
class Encoder(nn.Module):
def __init__(self, enc_voc_size, max_len, d_model, ffn_hidden, n_heads, n_layers, drop_prob, device):
super(Encoder, self).__init__()
# vocab_size: int, d_model: int, max_len: int, drop_prob, device
self.emb = TransformEmbedding(vocab_size=enc_voc_size,
d_model=d_model,
max_len=max_len,
drop_prob=drop_prob,
device=device)
self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,
n_heads=n_heads,
ffn_hidden=ffn_hidden,
dropout=drop_prob)
for _ in range(n_layers)])
def forward(self, x, s_mask):
# print("encoder x:", x.shape)
x = self.emb(x)
# print("encoder emb x:", x.shape)
for layer in self.layers:
x = layer(x, s_mask)
return x
if __name__ == "__main__":
print("Encoder Test")
batch_size = 32
seq_len = 10
n_heads = 8
d_model = 512
ffn_hidden = 2048
dropout = 0.1
enc_voc_size = 10000
max_len = 1000
n_layers = 6
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
encoder = Encoder(enc_voc_size=enc_voc_size,
max_len=max_len,
d_model=d_model,
ffn_hidden=ffn_hidden,
n_heads=n_heads,
n_layers=n_layers,
drop_prob=dropout,
device=device).to(device)
x = torch.randint(0, enc_voc_size, (batch_size, seq_len)).to(device)
s_mask = torch.ones((batch_size, 1, 1, seq_len))
s_mask = s_mask.expand(batch_size, n_heads, seq_len, seq_len).to(device)
output = encoder(x, s_mask)
print("Encoder output shape:", output.shape) # 应该是 (batch_size, seq_len, d_model)
print("Encoder output:", output)🔍 总结回顾:掰开揉碎的 Transformer Encoder
| 模块 | 内容 |
|---|---|
| 🔢 TokenEmbedding | 把词转换成向量表示 |
| 🌍 PositionalEncoding | 注入顺序信息 |
| 🔄 Scaled Dot-Product Attention | 衡量 token 之间的注意力关系 |
| 🌐 Multi-Head Attention | 多个头并行关注不同语义空间 |
| 🧠 Positionwise FeedForward | 非线性增强每个位置的表达 |
| ♻️ 残差 + LayerNorm | 保持训练稳定、避免退化 |
| 🧱 EncoderLayer | 核心构件单元 |
| 🧱 ×N 层 EncoderLayer | 组成完整的 Encoder 模块 |
📘 小结
Transformer 的编码器部分,是深度学习中最清晰、最模块化的架构之一。
我们通过自定义手写,逐层理解了注意力机制、前馈网络、归一化与残差等机制的核心原理。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









