







《Federated Meta-Learning with Fast Convergence and Efficient Communication》论文阅读
1 Introduction
基于初始化的元学习算法,如MAML(Model-Agnostic Meta-Learning),以对新任务的快速适应和良好泛化而闻名,这使得它特别适合于联邦设置,其中分散的训练数据是非iid和高度个性化的。受此启发,我们提出了一个联邦元学习框架,它与先前的联邦学习工作有很大的不同。我们的工作是元学习方法和联邦学习的桥梁。在元学习中,参数化算法(或元学习者)通过元训练过程从大量任务中缓慢学习,其中算法在每个任务中快速训练一个特定的模型。一个任务通常由支持集和查询集组成,它们彼此不相交。在支持集上训练特定任务的模型,然后在查询集上进行测试,测试结果用于更新算法。相比之下,在联邦元学习中,算法在服务器上维护,并分发给客户端进行模型训练。在每一集元训练中,一批抽样的客户端接收算法的参数并进行模型训练。然后将查询集上的测试结果上传到服务器以进行算法更新。我们框架的工作流程如图1所示。

联邦元学习与联邦学习的比较。联邦元学习框架看似与联邦学习相似,只不过服务器与客户端之间传输的信息是算法(参数)而非全局模型。不过,我们注意到,元学习在概念上不同于分布式模型训练,联盟元学习中的共享算法比联盟学习中的共享模型能以更灵活的方式应用。例如,在图像分类中,n 个类别的图像可能会非均匀地分布在客户端,每个客户端最多拥有 k 个类别( k ≪ n k \ll n k≪n)。联邦学习需要训练一个大型的 n-ways分类器来利用所有客户端的数据,而 k-ways 分类器每次只需对一个客户端进行预测即可。大型模型会增加通信和计算成本。可以只向客户发送模型的一部分,以更新相关参数,但这需要事先了解客户的私人数据,以决定发送的部分。另一方面,在元学习中,算法可以训练包含不同类别的任务。例如,MAML算法(将在 3 部分详细介绍)可以通过对 k-ways 任务进行元训练,为 k-ways 分类器提供初始化,而无需考虑具体类别。因此,在联邦元学习框架中,我们可以使用 MAML 对 k-ways 分类器进行元训练。
Contributions. 我们重点关注联邦设置的算法设计方面,并为此提出了一个新框架和大量实验结果。我们的贡献有三方面。
- 首先,我们表明元学习是联邦设置的自然选择,并提出了一种名为 FedMeta 的新型联邦元学习框架,它将元学习算法与联邦学习结合在一起。该框架允许以更灵活的方式共享参数化算法,同时保护客户端隐私,不向服务器收集数据。我们将基于梯度的元学习算法 MAML 和 Meta-SGD 整合到该框架中,以作说明。
- 其次,我们在 LEAF 数据集上进行了实验,比较了 FedMeta 框架与基线 FedAvg 在准确性、计算成本和通信成本方面的运行示例。结果表明,FedMeta 以更少或相当的系统开销实现了更高的准确率。
- 第三,我们将 FedMeta 应用于一项工业推荐任务,在这项任务中,每个客户都有高度个性化的记录,实验结果表明,元学习算法比联邦或stand-alone recommendation方法在推荐任务中实现了更高的准确率。
2 Related Work
**基于初始化的元学习。**元学习的目标是在一系列任务中学习一个模型,使其只需少量样本就能解决新任务。作为元学习的一个有前途的方向,基于初始化的方法最近通过 "学习微调 "证明了其有效性。在各种方法中,有些方法侧重于学习优化器,如基于 LSTM 的元学习器 [19] 和带有外部存储器的元网络 [15]。另一种方法旨在学习良好的模型初始化,从而使模型在少量梯度下降后,在样本有限的新任务中发挥最大性能。上述所有研究都只探讨了任务具有统一形式的情况(e.g., 5-way 5-shot for image classification)。在这项工作中,我们通过研究真实世界联邦数据集上的元学习算法来填补这一空白。我们关注的重点是模型初始化方法,这些算法与模型和任务无关,可以开箱即用,因为联邦环境中的任务和模型各不相同。据我们所知,我们提出的框架是第一个从元学习角度探索联邦环境的框架。
**联邦学习。**我们提出的联邦元学习框架将每个客户端视为一个任务。我们的目标不是训练一个能接收所有任务的全局模型,而是训练一个能快速适应新任务的初始化模型。元学习算法背后的直觉是提取和传播先前任务的内部可转移表征。因此,元学习算法可以防止过度拟合,并提高对新任务的泛化能力,这显示了元学习算法在处理统计问题方面的潜力。
3 Federated Meta-Learning
在本节中,我们将详细阐述所提出的联邦元学习框架。我们首先讨论元学习方法,并介绍 MAML 和 Meta-SGD 算法。然后,我们将介绍如何在联邦环境中实现元学习算法。
3.1 The Meta-Learning Approach
元学习的目标是对 $Algorithm ~ \mathcal{A} $ 【function of function】进行元训练,以便针对新任务快速训练模型(如深度神经网络)。一般来说,算法 A φ \mathcal{A}_{\varphi} Aφ 是参数化的,其参数 φ \varphi φ 在元训练过程中通过任务集合进行更新。元训练中的任务 T T T 由一个支持集 D S T = ( x i ; y i ) i = 1 ∣ D S T ∣ D^T_S = {(x_i ; y_i)}_{i=1}^{|D_S^T|} DST=(xi;yi)i=1∣DST∣ 和一个查询集 D Q T = ( x i ′ ; y i ′ ) i = 1 ∣ D Q T ∣ D^T_Q = {(x_i' ; y_i')}_{i=1}^{|D_Q^T|} DQT=(xi′;yi′)i=1∣DQT∣ 组成,两者都包含标注数据点。 $Algorithm ~ \mathcal{A} $ 在支持集 D S T D^T_S DST 上训练模型 f f f【分类器】,并输出参数 θ T θ_T θT,我们称之为内部更新。然后在查询集 D Q T D^T_ Q DQT 上对模型 f θ T f_{\theta_T} fθT 进行评估,并计算一定的测试损失 L D Q T ( θ T ) L_{D^T_Q} (θ_T ) LDQT(θT) 以反映 A φ \mathcal{A_\varphi} Aφ 的训练能力。最后,对 A φ \mathcal{A_\varphi} Aφ 进行更新,使测试损失最小化,我们称之为外部更新。请注意,支持集和查询集是不相交的以最大限度地提高 A φ \mathcal{A_\varphi} Aφ 的泛化能力。元训练以episodic的方式进行,在每个episodic中,从元训练集上的任务分布 T \mathcal{T} T 中抽取一个batch的 task。因此,算法 A φ \mathcal{A_\varphi} Aφ 的优化目标如下:
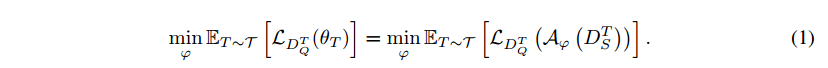
MAML 算法是一种具有代表性的基于梯度的元学习方法,它通过梯度更新步骤来训练模型。**MAML 的 $Algorithm ~ \mathcal{A} $ 只是用来为模型提供初始化。**对于每个任务 T,算法都会维护
φ
=
θ
\varphi=\theta
φ=θ ,作为模型
f
f
f 参数的初始值。然后在支持集
D
S
T
D^T_S
DST 上训练
f
θ
f_θ
fθ,并使用一个(或多个)梯度下降步骤将
θ
θ
θ 更新为
θ
T
θ_T
θT,训练损失为 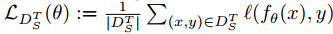 ,其中
l
l
l 为损失函数,例如用于图像分类任务的交叉熵。最后在查询集
D
Q
T
D^T_ Q
DQT 上测试
f
θ
T
f_{θ_T}
fθT,并计算测试损失
,其中
l
l
l 为损失函数,例如用于图像分类任务的交叉熵。最后在查询集
D
Q
T
D^T_ Q
DQT 上测试
f
θ
T
f_{θ_T}
fθT,并计算测试损失 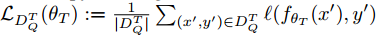 。公式 (1) 中的优化目标具体化如下:
。公式 (1) 中的优化目标具体化如下:
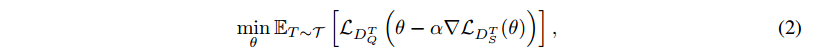
其中 α 是内部梯度更新的学习率。
Meta-SGD在MAML的基础上更进一步,同时学习初始化 θ θ θ 和内部学习率 α α α。请注意,测试损失 L D Q T ( θ T ) \mathcal{L}_{D^T_Q}(\theta_T) LDQT(θT) 可以视为 θ θ θ 和 α α α 的函数,两者都可以通过在 L D Q T ( θ T ) \mathcal{L}_{D^T_Q}(\theta_T) LDQT(θT) 上采用梯度,使用 SGD 在外循环中进行更新。此外,学习率 α α α 是与 θ θ θ 具有相同维度的向量,使得 α α α 对应于 θ θ θ 坐标。
Meta-SGD的优化目标可以写为
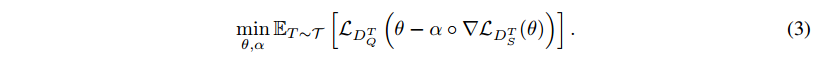
latex
3.2 The Federated Meta-Learning Framework
在联邦学习(federated learning)的环境下,训练数据分布在一组客户端中,目的是在不向服务器收集数据的情况下协同训练一个模型。模型在客户端上分布和训练,服务器通过平均从客户端收集的更新模型来维护共享模型。在许多实际应用中,例如为手机用户提供推荐时,该模型反过来又被用于对同一组客户进行预测。
我们将元学习纳入联邦学习框架。我们的目标是利用分布在客户端的数据协同元训练算法。以 MAML 为例,我们的目标是使用所有客户的数据共同训练模型的初始化。回想一下,MAML 包含两层优化:内部循环使用维护的初始化来训练特定于任务的模型【f】,外循环使用任务的测试损失【 L D Q T ( θ T ) \mathcal{L}_{D^T_Q}(\theta_T) LDQT(θT) 】更新初始化。在联邦设置中,每个客户端 u u u 从服务器检索初始化 θ θ θ,使用设备上的数据支持集 D S u D^u_S DSu 训练模型,并向服务器发送单独查询集 D Q u D^u_Q DQu 上的测试损失 L D Q u ( θ ) L_{D^u_Q} (θ) LDQu(θ)。服务器会维护初始化,并通过收集一小批客户的测试损失来更新初始化【a mini batch of clients】。
在此过程中传输的信息包括模型参数初始化(从服务器到客户端)和测试损失(从客户端到服务器),服务器无需收集数据。对于 Meta-SGD,向量 α α α 也作为算法参数的一部分进行传输,并用于内循环模型训练。

A l g o r i t h m 1 Algorithm 1 Algorithm1 展示了带有 MAML 和 Meta-SGD 的联邦元学习框架 FedMeta,其中 通信轮数 对应元学习术语中的 episode。算法在 AlgorithmUpdate 程序中进行维护。在每一轮更新中,服务器都会在一组抽样客户端上调用 ModelTrainingMAML 或 ModelTrainingMeta-SGD,以收集测试损失。在元训练后,要在客户端 u u u 上部署模型,需要使用 u u u 的训练集更新初始化 θ θ θ,并使用获得的 θ u θ_u θu 进行预测。
4 Experiments
在本节中,我们评估 FedMeta 在不同任务、模型和现实世界联邦数据集上的实证性能。首先,我们在 LEAF 数据集上进行实验,并表明与传统的联邦学习方法相比,FedMeta 可以提供更快的收敛、更高的准确性和更低的系统开销。其次,我们在更现实的场景(工业推荐任务)中评估FedMeta,并证明FedMeta可以使算法和模型保持在更小的规模,同时保持更高的容量。
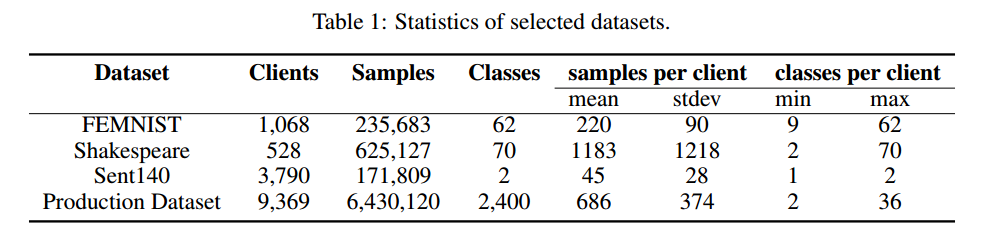
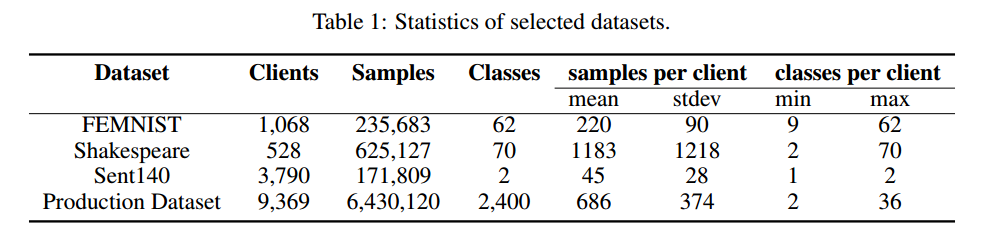
所选数据集的统计数据总结于表1中。
4.1 Evaluation Scheme
在所有实验中,我们随机选择 80% 的客户端作为训练客户端,10% 的客户端作为验证客户端,其余的作为测试客户端,因为我们认为泛化到新客户端的能力是联邦学习的一个重要属性。对于每个客户端,本地数据分为支持集和查询集。我们改变了用作每个客户端支持集的数据比例 p p p,以研究FedMeta在有限数据情况下如何有效地适应新用户。我们在本节的其余部分中用“ p p p Support”表示此设置。
对于传统的联邦学习,我们考虑联邦平均算法(FedAvg),它是一种基于平均局部随机梯度下降(SGD)更新的启发式优化方法,并且已被证明在非凸设置中效果良好。为了公平比较,我们还实现了 FedAvg 的元学习版本,用 FedAvg(Meta) 表示。与直观的FedAvg不同,FedAvg(Meta)在测试之前使用测试客户端的支持集对从服务器接收到的模型初始化进行微调,这体现了元学习的本质——“学习微调”。在训练过程中,FedAvg 和 FedAvg(Meta) 都使用训练客户端上的所有数据。
对于联邦元学习,我们包括三种面向优化的算法:MAML、MAML 的一阶近似(用 FOMAML 表示)和 Meta-SGD,所有这些都是模型无关的方法,可以在我们的 FedMeta 框架中很容易实现。 FOMAML 是 MAML 的简化版本,其中省略了二阶导数,据称其性能与 MAML 相似,同时计算成本提高了约 33% 。所以我们在比较系统开销时还额外考虑了FOMAML。附录中提供了有关实施的更多详细信息。
4.2 LEAF Dataset
我们首先探索 LEAF,它是联邦设置的基准。 LEAF 由三个数据集组成:(1)用于 62 类图像分类的 FEMNIST,它是流行的 MNIST 数据集的更复杂版本。数据根据数字/字符的编写者进行分区。 (2)莎士比亚用于下一个角色预测,它是根据威廉·莎士比亚全集构建的。每部剧中的每个说话角色都被视为不同的客户。 (3) Sentiment140,用于二元情感分类,它是通过根据推文中呈现的表情符号对推文进行注释而自动生成的。每个 Twitter 用户都被视为客户。我们对 FEMNIST 使用 CNN 模型,对莎士比亚使用stacked character-level LSTM 模型,对 Sent140 使用 LSTM 分类器。我们过滤了少于 k 条记录的不活跃客户端,对于 FEMNIST、Shakespeare 和 Sent140 分别设置为 10、20、25。附录中提供了有关数据集和我们采用的模型的完整详细信息。
**准确性和收敛性比较。**我们研究了 FedAvg 和 FedMeta 框架在 LEAF 数据集上的性能。考虑到边缘设备上的计算能力有限,我们将所有方法的局部epoch设置为 1。
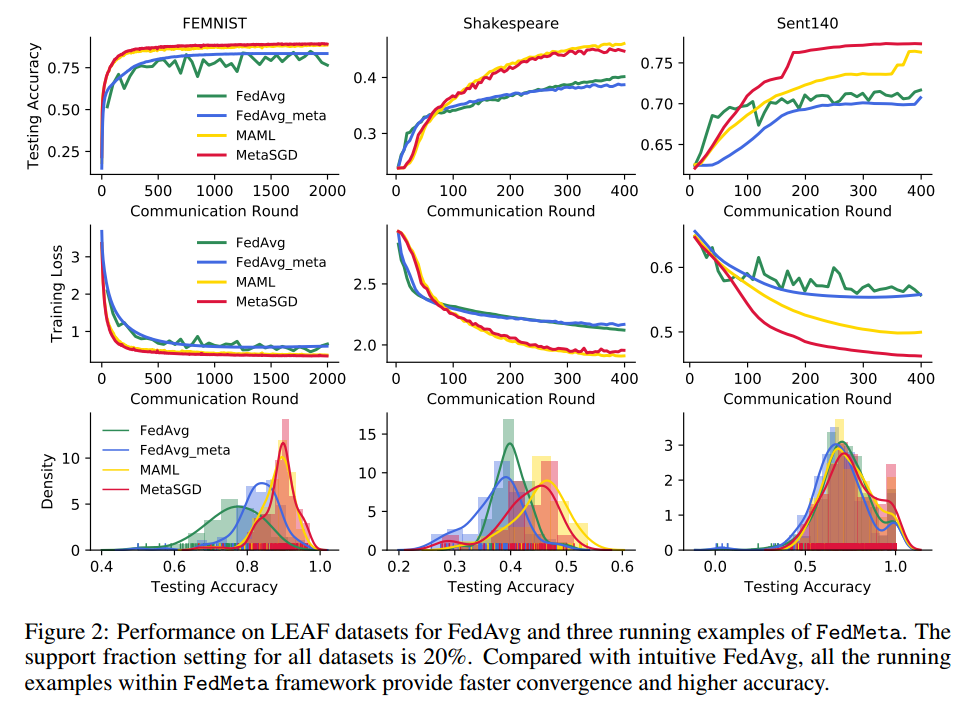
如图 2 所示,FedMeta 框架内的所有方法都以更快、更稳定的收敛速度实现了最终精度的提高。我们可以看到,MAML 和 Meta-SGD 在 FEMNIST 和 Shakespeare 上具有相似的收敛速度和最终精度,而 Meta-SGD 在 Sent140 上的表现明显优于 MAML。
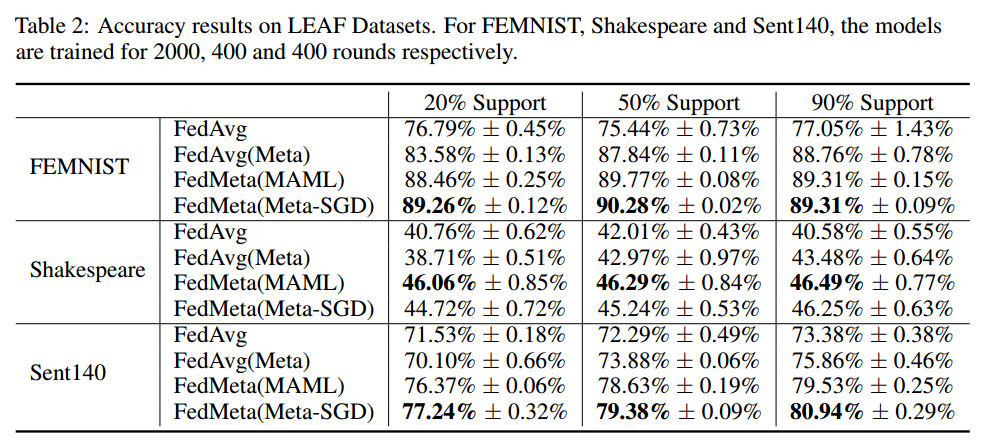
表2显示了四种方法经过几轮通信后的最终准确率。首先,比较不同的方法,我们注意到 FedAvg 的表现明显比 FedMeta 差,尤其是在图像分类任务上。相比之下,MAML和Meta-SGD在不同情况下获得了最高的准确率,最终准确率提高了3.23%-14.84%。我们还观察到,在大多数情况下,与 FedAvg 相比,FedAvg(Meta) 具有更高的准确性。然而,莎士比亚和 Sent140 支持率为 20%是两个特殊案例。出乎意料的是,FedAvg(Meta) 导致准确性略有下降。这可能是因为模型在少量数据的微调后与全局最优值偏差过大。【???】其次,当我们增加支持集 p p p 时,FedAvg(Meta) 和 FedMeta 的准确性几乎在所有情况下都会上升。然而,FedAvg(Meta)的增长率大于FedMeta。例如,在莎士比亚上,当 p p p 从 20% 变化到 90% 时,FedAvg(Meta) 的准确率提高了 4.77%,而 MAML 的准确率仅提高了 0.43%。这表明FedMeta框架具有更好的泛化能力,可以有效地适应数据有限的新客户端。
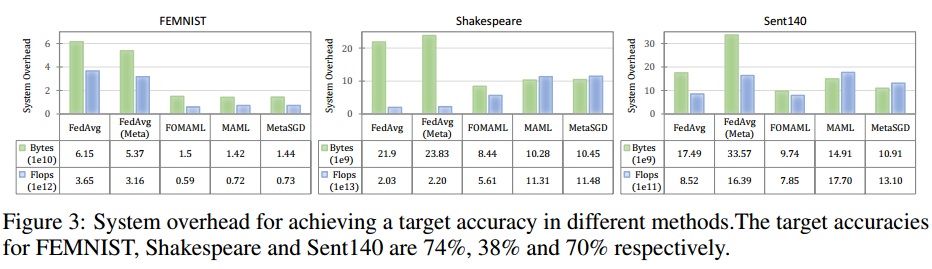
系统开销。我们根据所有设备上的 FLOPS 总数以及上传到服务器和从服务器下载的字节总数来描述系统预算。图 3 显示了不同方法实现目标测试集精度所需的系统开销。比较通信成本,我们观察到 FedMeta 在所有情况下都将所需的通信成本降低了 2.82-4.33 倍。在计算成本方面,由于显着的快速收敛,FOMAML 为 FEMNIST 和 Sent140 提供了最低的成本。对于莎士比亚,FedAvg 实现了最低成本,大约比 MAML 和 Meta-SGD 低 5 倍。这是因为元学习方法在反向传播元梯度时使用二阶导数会产生大量的计算费用。比较 MAML 和 FOMAML,正如预期的那样,FOMAML 降低了所有数据集的计算成本。//对于两种语言建模任务,FOMAML 相比 MAML 降低了通信成本。但对于图像分类任务,FOMAML 增加了通信成本,这表明 FOMAML 中后向传递的丢弃对卷积网络的影响比 LSTM 更大。一般来说,在实际应用中我们可以灵活选择不同的方法来权衡通信和计算成本。
**公平性比较。**继最近的工作之后,我们通过比较多次运行的平均最终准确度分布来研究 FedAvg 和 FedMeta 框架的公平性。在图 2 的最后一行中,我们展示了不同方法的核密度估计。对于 FEMNIST,我们观察到 MAML 和 Meta-SGD 不仅可以带来更高的平均精度,而且还可以实现更集中的精度分布和更低的方差。对于莎士比亚,虽然 FedMeta 导致方差更高,但平均准确度也更高。对于 Sent140,所有方法的最高峰值周围的准确度分布几乎相同。然而,我们看到 MAML 和 Meta-SGD 带来了更多准确率约为 100% 的客户。总体而言,FedMeta 鼓励在图像分类任务中跨设备进行更公平的准确度分布。而对于语言建模任务,FedMeta 保持相当的公平性或牺牲公平性以获得更高的平均准确性。
核密度图是什么?
核密度图本质上是根据有限的数据样本,运用核密度函数,对整体数据的密度进行估计;即已知有限的数据样本和一个核函数,输出整体数据的概率密度,并通过图形展示出结果
核密度图可以将数据分布可视化为一个平滑的概率密度曲线,使我们能够直观地了解数据的分布特征。
4.3 Real Industrial Recommendation Task
为了证明我们的 FedMeta 框架在具有客户端数据自然分区的实际应用程序中的有效性,我们还在来自工业推荐任务的大型生产数据集上评估了 FedMeta。我们的目标是根据每位客户过去的记录向其推荐前 k 项移动服务。如表 1 所示,该数据集中有 2400 个不同的服务、9,369 个客户端和约 640 万条使用记录。此外,每个客户有100至5000多条记录和2至36项服务。
**设置。**我们将此推荐任务视为分类问题,并考虑三种设置:META、MIXED 和 SELF。后两者被视为baseline,因为我们希望包含一些经典的独立推荐算法以进行公平比较。 (1) META 设置对应于联邦元学习方法,我们采用 40 类分类器而不是 MIXED 设置中采用的 2420 类分类器。元学习允许训练小型本地模型,正如在Introduction中将联邦元学习与联邦学习进行比较时所解释的那样。该分类器考虑了两种架构:逻辑回归和神经网络,分别用 LR 和 NN 表示。 (2) MIXED 类型代表联邦学习方法,其中首先在训练客户端上训练统一的 2420 类分类器,然后使用相应的支持集对每个测试客户端进行微调。对于分类器,我们考虑一个具有 64 个神经元的隐藏层的神经网络,其中输出层由 2420 个神经元组成。我们用 NN-unified 表示它。我们避免使用深度神经网络,因为我们专注于研究元学习算法可以为训练推荐模型带来的优势,而不是寻找最佳模型。此外,在实践中,模型将在计算资源有限的用户设备上进行训练,其中简单的模型更可取。 (3) SELF 设置代表独立方法,其中使用本地数据为每个客户端训练不同的模型。我们选择以下方法进行分类:最常用的(MFU)、最近使用的(MRU)、朴素贝叶斯(NB)以及META设置中采用的两种架构(LR和NN)。有关输入特征向量构造和实现的完整详细信息可以在附录中找到。
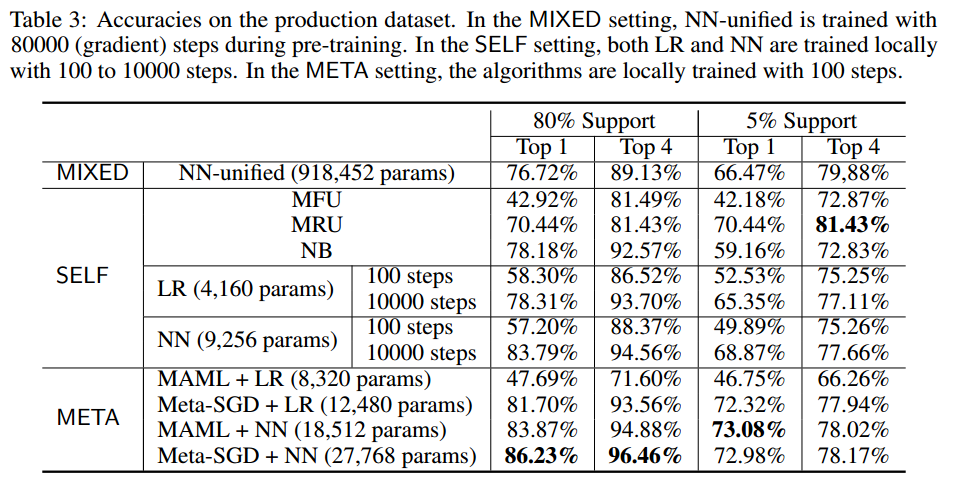
**准确度比较。**从表3中,我们观察到以下情况:(1)比较META设置中的元学习算法,在其他模块和设置相同的情况下,Meta-SGD优于MAML,NN优于LR。最简单的 MAML + LR 组合表现最差,这意味着算法或模型都应该具有一定的复杂性才能保证 FedMeta 框架的性能。 (2) 比较 MIXED、SELF 和 META,元学习方法 MAML + NN 和 Meta-SGD + NN 通常优于所有基线,尽管这两种方法都只用 100 个梯度步骤进行训练。另一个有趣的观察结果是,在“5% 支持”的情况下,MRU 具有最高的 Top 4 准确率。这可能是因为用户在短时间内使用少量服务,并且MRU不受低支持率的影响。然而,随着支持集的扩展(实践中经常出现这种情况),元学习方法的表现将优于 MRU。
**收敛性比较。**我们进一步研究 META 和 SELF 设置的收敛性能。与使用(非参数)优化方法从头开始训练的模型相比,用元学习方法训练的模型实现了更快的收敛,这意味着个性化模型的训练受益于良好的初始化。完整的实验结果可以在附录中找到。
5 Conclusion and Future Work
在这项工作中,我们证明元学习是处理联邦学习中统计和系统挑战的自然选择,并提出了一种新颖的联邦元学习框架 FedMeta。
我们对一系列联邦数据集的实证评估表明,FedMeta 框架在准确性、收敛速度和通信成本方面取得了显着改进。
我们进一步验证了 FedMeta 在工业推荐场景中的有效性,其中 FedMeta 的性能优于独立模型和联邦学习方法训练的统一模型。
未来,我们将探索以下方向:(1)我们想从模型攻击的角度研究FedMeta框架在保护用户隐私方面是否具有额外的优势[26,24,25,22],如共享的全局模型当前的联邦学习方法仍然隐式地包含所有用户的隐私,而在 FedMeta 中,元学习器是共享的。 (2)我们将在线部署我们的FedMeta框架用于APP推荐,以评估其在线性能,涉及大量工程工作尚未完成。
A Experimental Details
A.1 数据集和模型
**FEMNIST:**我们在 FEMNIST 上研究了 62 类图像分类任务,这是流行的 MNIST 数据集的更复杂版本[9]。数据根据数字/字符的编写者进行分区。我们考虑一个具有两个 5x5 卷积层(第一个有 32 个通道,第二个有 64 个通道,每个通道后面有 2 × 2 最大池化)的 CNN,一个具有 2048 个单元和 ReLU 激活的全连接层,以及一个最终层Softmax输出层。 CNN模型的输入是展平的28×28图像,输出是0到61之间的数字。
**Shakespeare:**我们研究Shakespeare的下一个字符预测任务,该任务基于威廉·莎士比亚全集[21]。在数据集中,每部剧中的每个说话角色都被视为不同的客户端。该语言建模任务可以建模为 53 类分类问题。我们使用包含 256 个隐藏单元和 8D 嵌入层的两层 LSTM 分类器。嵌入层以 80 个字符的序列作为输入,输出是 0 到 52 之间的类标签
**Sent140:**我们在 Sent140 上研究了一个 2 类情感分类任务,该任务是通过根据推文中呈现的表情符号对推文进行注释来自动生成的。我们使用具有 100 个隐藏单元和预训练的 300D GloVe 嵌入的两层 LSTM 分类器 [18]。输入是 25 个单词的序列,其中每个单词随后通过查找 GloVe 嵌入到 300 维空间中。最后一个密集连接层的输出是 0 或 1 的类标签。
**生产数据集:**我们研究生产数据集上的工业推荐任务。有 2400 个不同的服务和 9369 个客户端,其中每个客户端有 100 到 5000 多个记录和 2 到 36 个服务。在每个使用记录中,标签是用户已经使用过的服务,特征包含服务特征(例如服务ID等)、用户特征(例如最后使用的服务等)和上下文特征(例如电池)级别、时间等)。我们使用三种模型架构进行实验:NN-unified、NN 和 LR。这些模型的详细信息在实验部分提供。
A.2 实现细节
**Libraries:**我们在 TensorFlow [1] 中使用 MAML、FOMAML 和 MetaSGD 实现 FedAvg、FedAvg(Meta)、FedMeta,这允许在元学习期间通过梯度更新进行自动微分。我们使用 Adam [7] 作为所有方法的局部优化器。
**Evaluation:**有两种常见的方法来定义联合设置中的测试准确性,即针对所有数据点的准确性和针对所有设备的准确性。在本工作中,我们选择前者。至于采样方案,我们在每轮通信中对客户端进行统一采样,并在服务器上更新算法时对本地模型进行平均,其权重与本地数据点的数量成正比。为了公平比较,所有方法的客户端划分和支持/查询集的划分保持相同。
**超参数:**对于每个 LEAF 数据集,我们调整每轮的活跃客户端数量。对于 FEMNIST、Shakepseare 和 Sent140,活跃客户数量分别为 4、50 和 60。我们还对学习率进行了网格搜索,表 4 中提供了最好的学习率。【我们会过滤记录数少于 k 的非活动客户端,FEMNIST、Shakespeare 和 Sent140 分别设置为 10、20、25。】
A.3 LEAF 上的附加实验
如图4和图5所示,我们提供了支持率为50%和90%时的收敛曲线。我们注意到,当我们增加支持率时,FedAvg(Meta) 和 FedMeta 之间的差距正在缩小。一个例子是,当支持率为 90% 时,FedAvg(Meta) 和 FedMeta 的收敛曲线几乎重合。这与之前的行业经验一致,即元学习方法在低数据情况下确实比在中数据或大数据情况下具有更大的优势。
A.4 工业任务的附加实验
补充:Meta Learning
Base-hongyi Lee
数据集
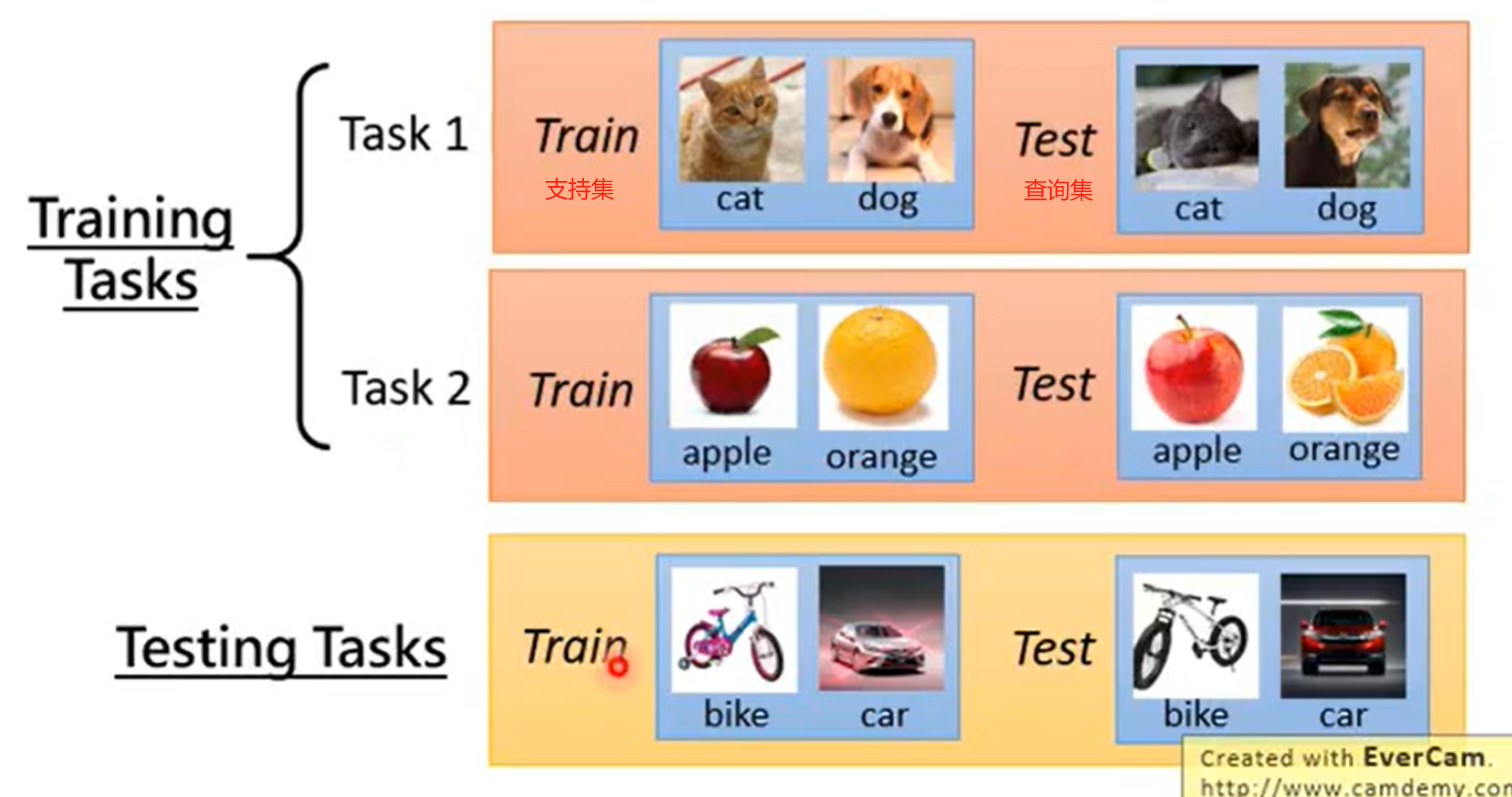
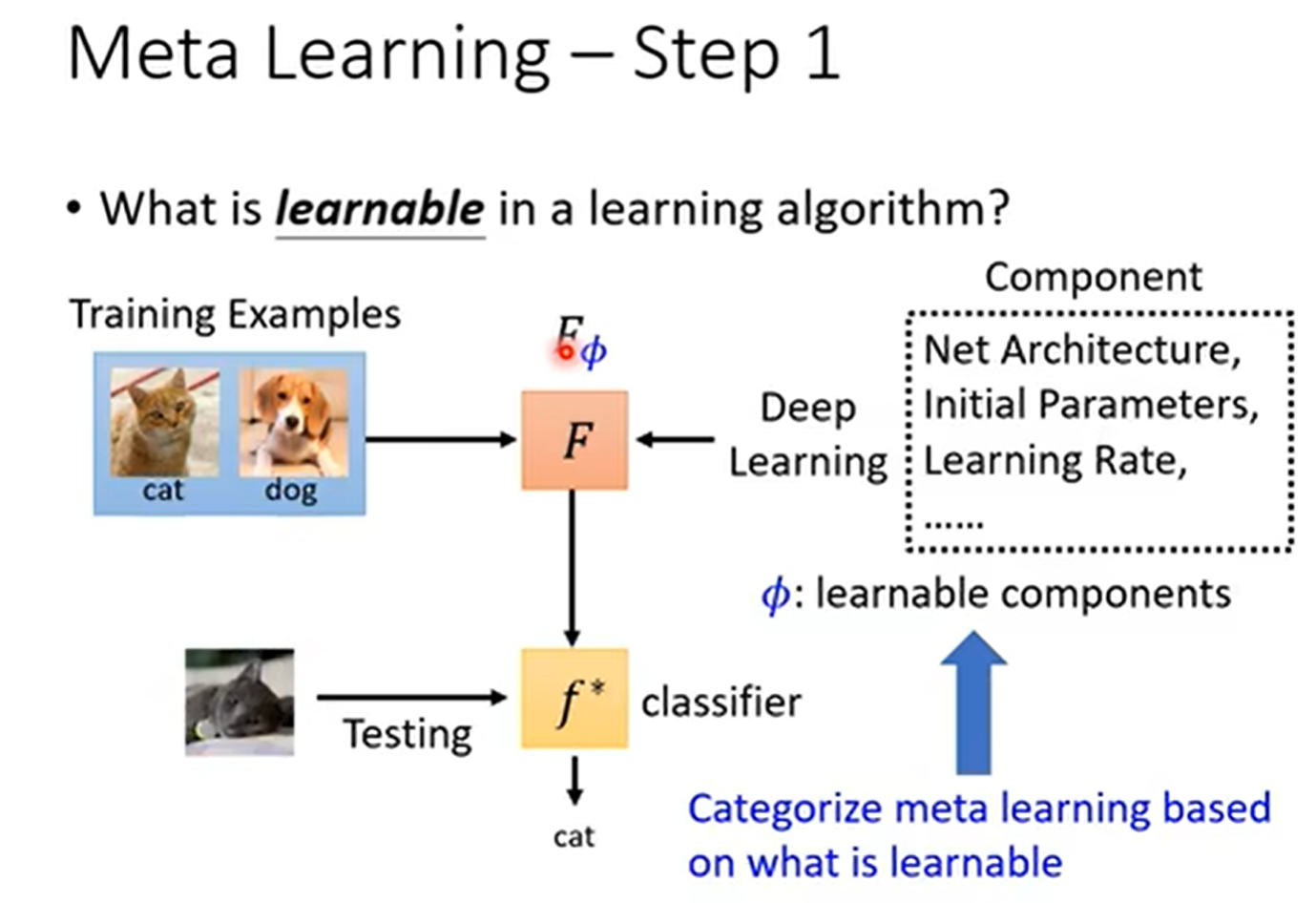
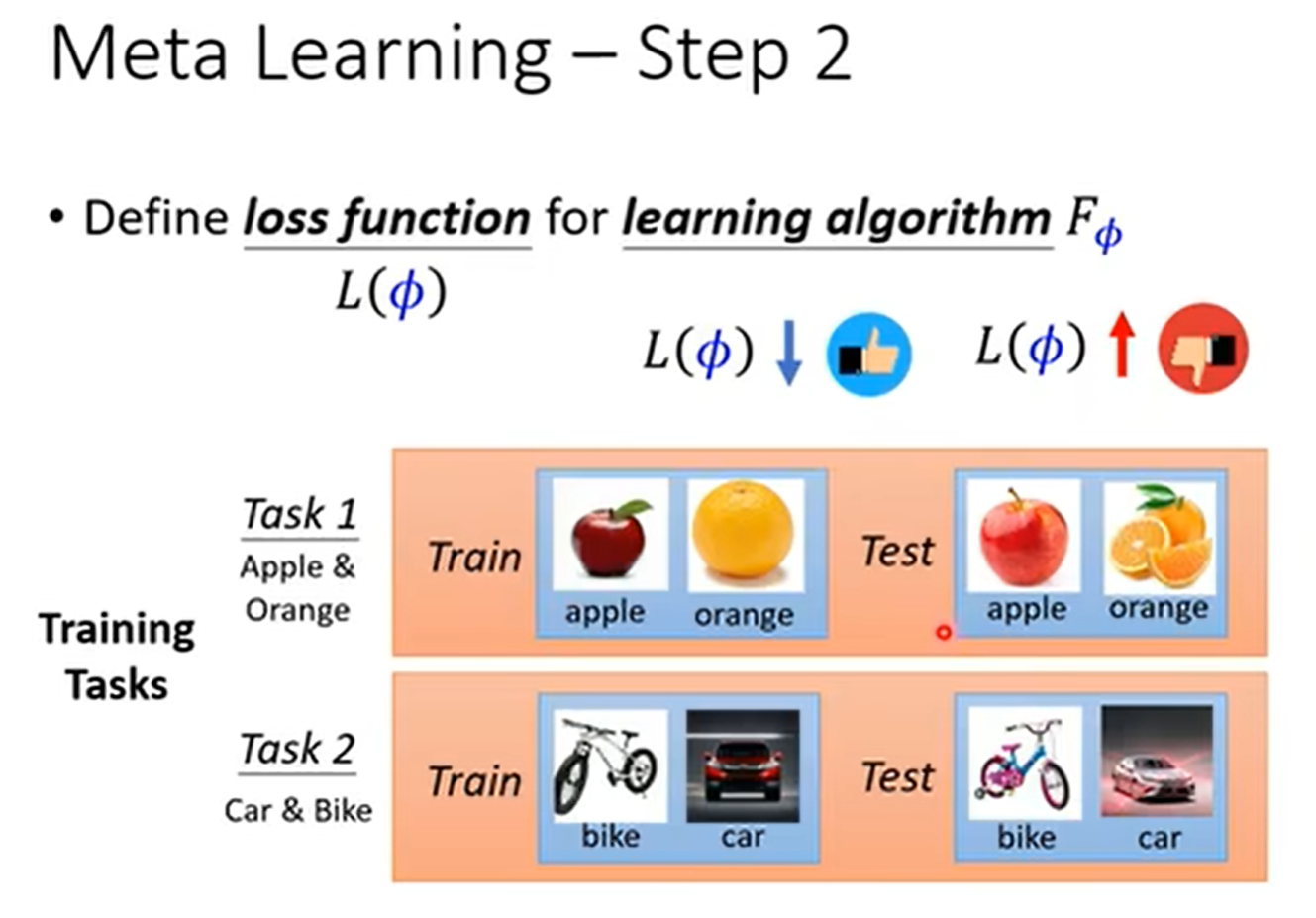
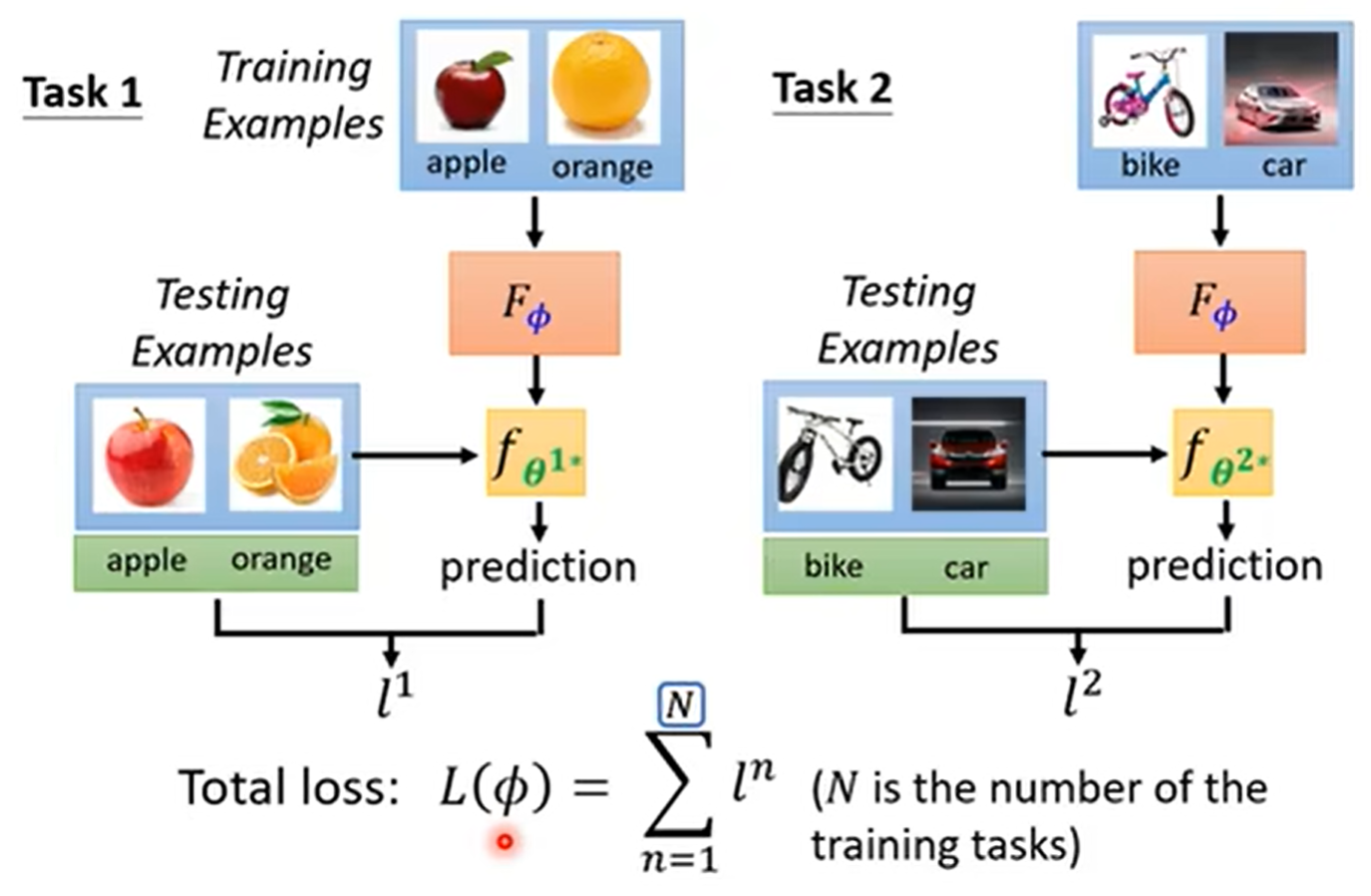


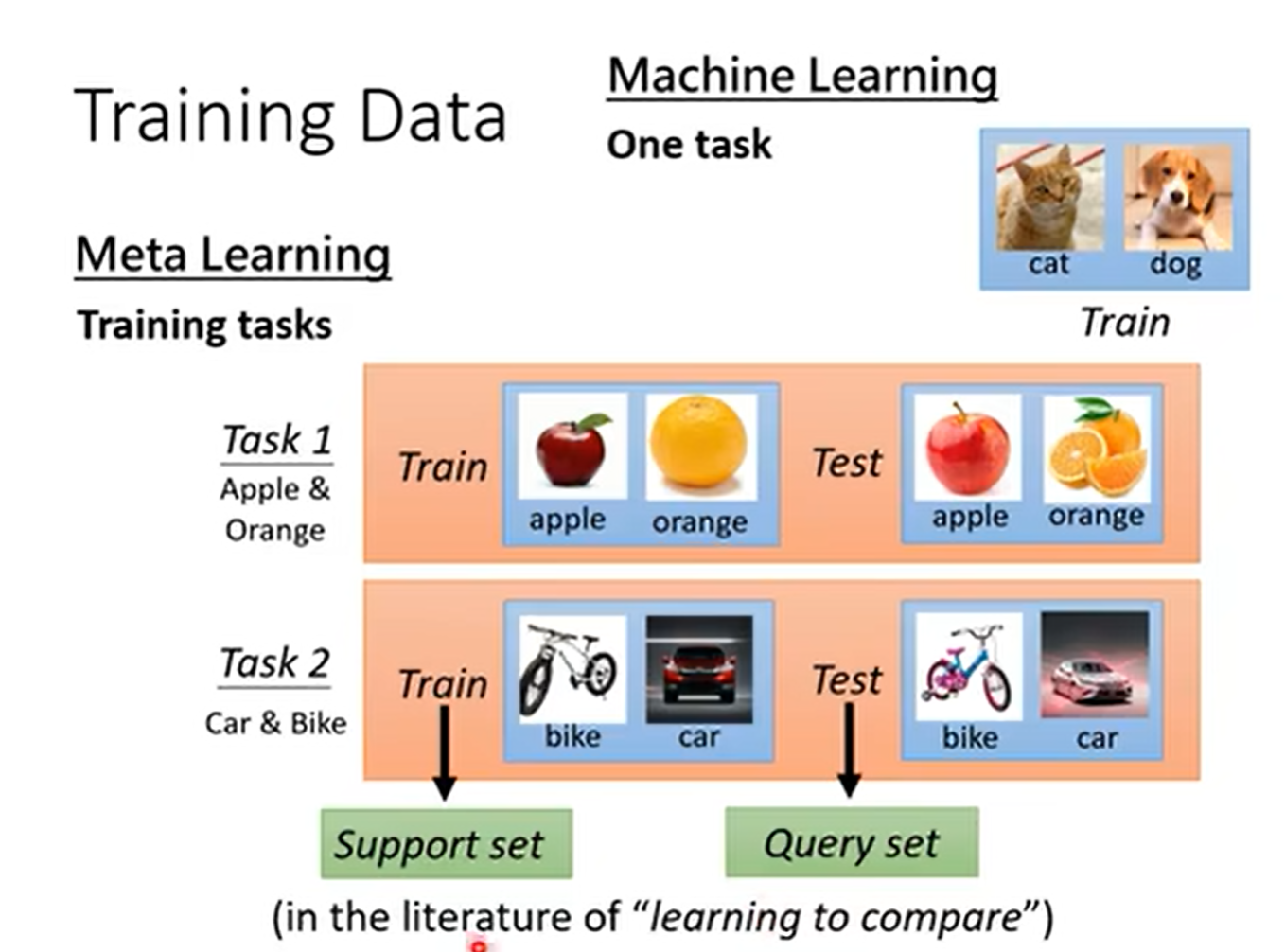
meta learning可以学什么?
MAML学的是初始化参数,使其接近收敛
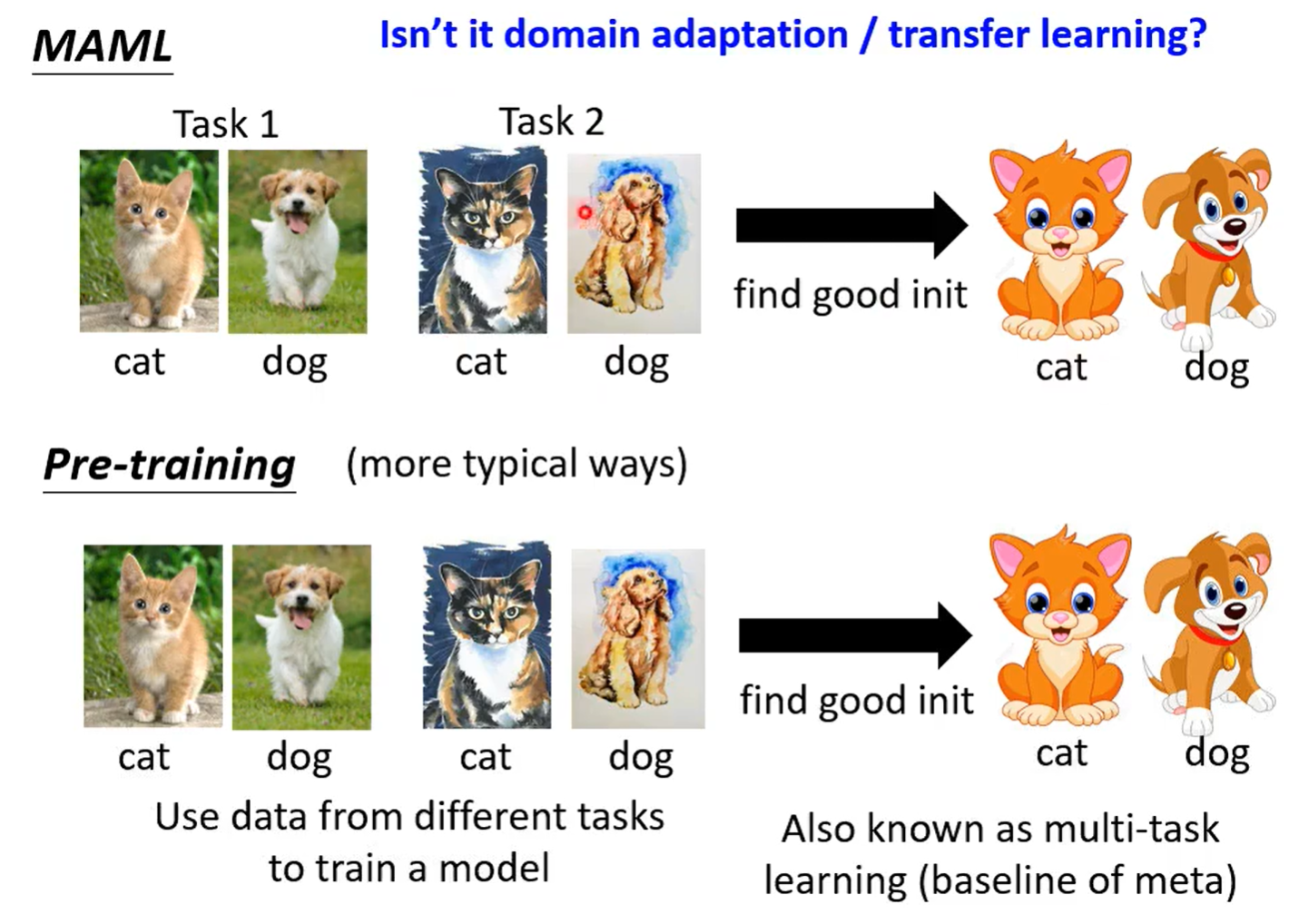
还可以学Optimizer、Network Architecture、Data Augmentation、Sample Reweighting

使 L L L 可以微分:
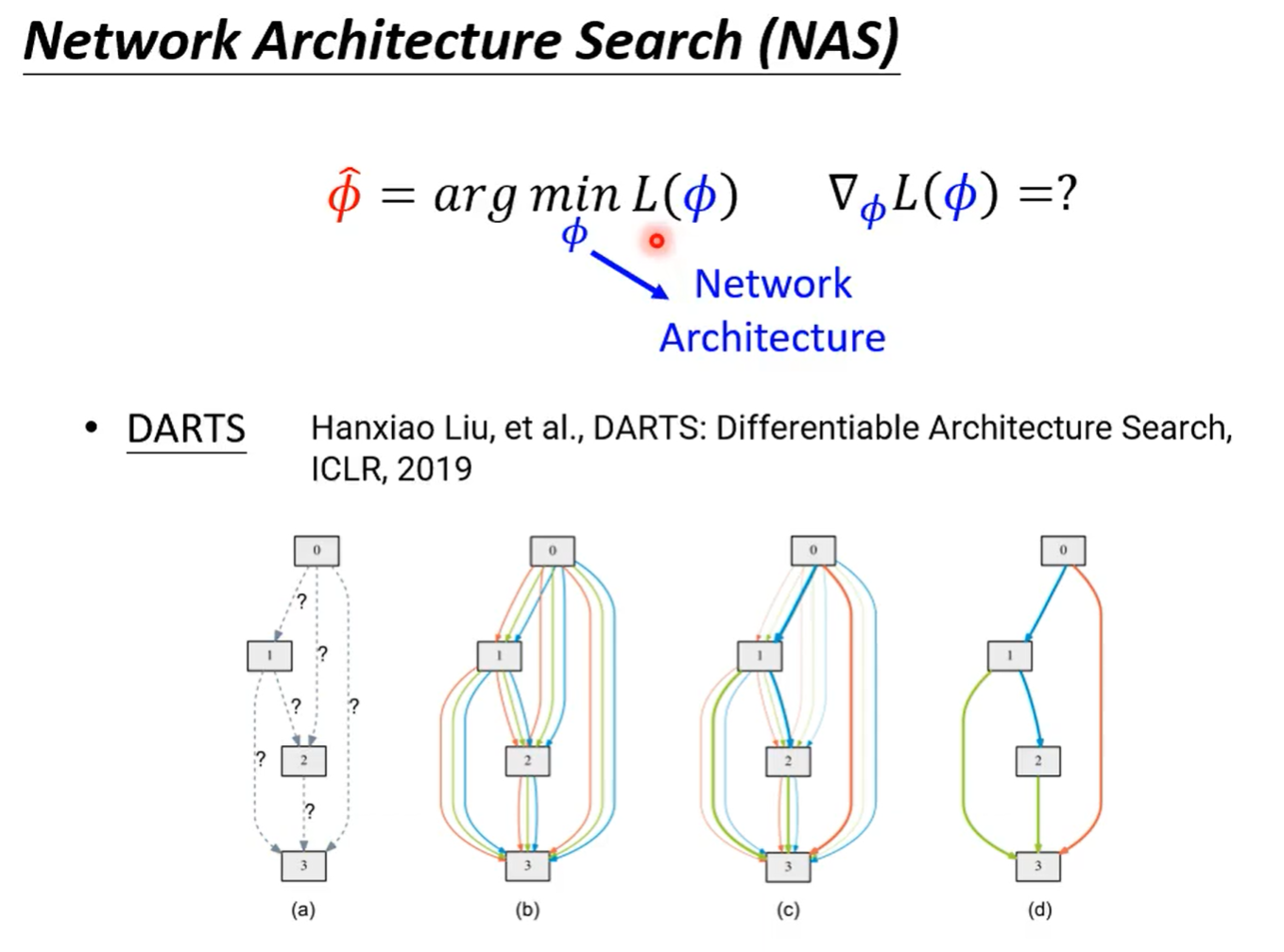
不同任务有不同模型,期待机器可以从过去的经验中学习技巧使得在未来训练一个新模型时可以更快更好
Application-hongyi Lee

MAML

1623*20
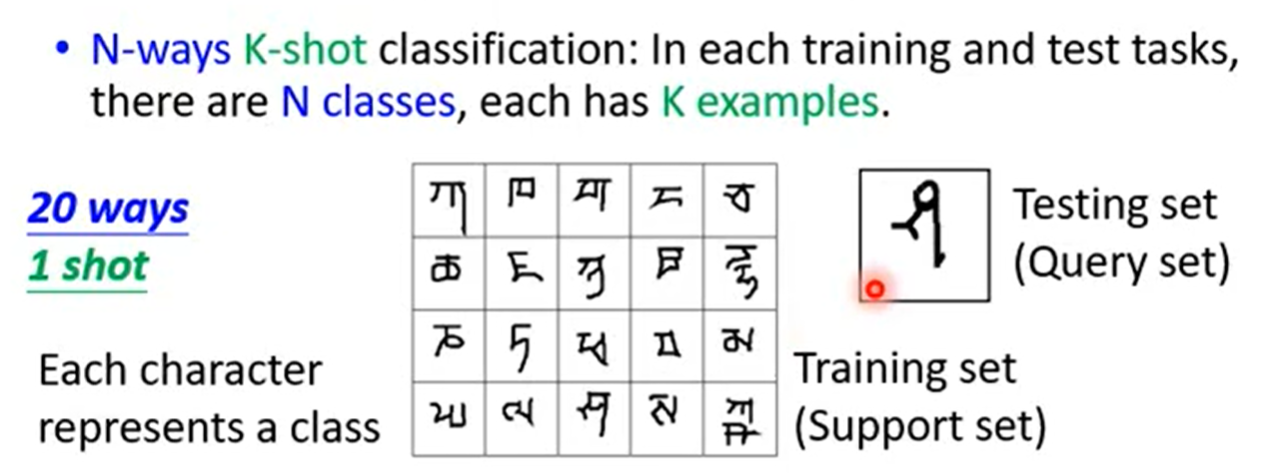
https://zhuanlan.zhihu.com/p/181709693
注:【****】内容为个人理解

流程解析:
Step 1: 随机初始化一个权重
Step 2: 一个while循环,对应的是训练中的epochs(Step 3-10)
Step 3: 采样一个batch的task(假设为4个任务)
Step 4: for循环,用于遍历所有task(Step 5-8)
Step 5: 从support set中取出一批task图片和标签
Step 6-7: 对这一张图片进行前向传播,计算梯度后用 l r α lr_α lrα反向传播,更新 θ ′ θ' θ′这个权重
Step 8: 从query set中取出所有task进行前向传播,但不更新模型
Step 10: 将所有用 $θ’ $计算出来的损失求和,计算梯度后用 l r β lr_\beta lrβ进行梯度下降,更新 θ θ θ 的权重
原文链接:https://blog.csdn.net/weixin_42392454/article/details/109891791
补充:Python抽象基类及abc模块
抽象基类(Abstract Base Class,简称ABC)是一种在面向对象编程中用于定义一组共享特征和行为的类的概念。抽象基类并不用于创建对象,而是用于定义其他类的通用接口和方法。
抽象基类通常包含抽象方法(Abstract Method),这些方法只包含方法签名但没有具体的实现。其他类可以继承这些抽象基类,并在继承过程中实现抽象方法,从而强制这些子类提供特定的行为。这有助于确保子类具备特定的功能和接口,同时也提供了一种规范化的方式来组织和设计代码。
Python 中的抽象基类是通过 abc 模块实现的,通过继承 ABC 类以及使用 @abstractmethod 装饰器来定义抽象方法。以下是一个简单的示例:
from abc import ABC, abstractmethod
class Shape(ABC): # 抽象基类
@abstractmethod
def area(self):
pass
class Circle(Shape):
def __init__(self, radius):
self.radius = radius
def area(self):
return 3.14 * self.radius * self.radius
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
def area(self):
return self.width * self.height
# 无法实例化抽象基类,下面的代码会引发TypeError
# shape = Shape()
circle = Circle(5)
print("圆的面积:", circle.area())
rectangle = Rectangle(4, 6)
print("矩形的面积:", rectangle.area())
在上述示例中,Shape 是抽象基类,定义了一个抽象方法 area,要求任何继承自 Shape 的子类都必须实现 area 方法。Circle 和 Rectangle 分别是 Shape 的子类,它们实现了 area 方法以提供特定形状的面积计算。通过这种方式,我们确保了所有的形状类都有一个共同的接口(area 方法),并可以以一致的方式使用。
import abc
class meta(abc.ABC):
def __init__(self):
self.func()
def func(self):
print("meta function")
class son(meta):
def __init__(self):
super(son, self).__init__()
def func(self):
print("son function")
obj = son()
son function
基类 meta 的构造函数中的 func 方法被调用,但由于子类 son 重写了 func 方法,因此实际上会调用子类 son 中的 func 方法。
所以,最终会打印出 "son function"。
补充:Python&Pytorch
class meta():
def __init__(self):
print(1)
dict = {'a': 1, 'b': 2}
print(dict.get('c', meta))
<class '__main__.meta'>
print(dict()=={})
True
def model_structure(model):
blank = ' '
print('-' * 90)
print('|' + ' ' * 11 + 'weight name' + ' ' * 10 + '|' \
+ ' ' * 15 + 'weight shape' + ' ' * 15 + '|' \
+ ' ' * 3 + 'number' + ' ' * 3 + '|')
print('-' * 90)
num_para = 0
type_size = 1 # 如果是浮点数就是4
for index, (key, w_variable) in enumerate(model.named_parameters()):
if len(key) <= 30:
key = key + (30 - len(key)) * blank
shape = str(w_variable.shape)
if len(shape) <= 40:
shape = shape + (40 - len(shape)) * blank
each_para = 1
for k in w_variable.shape:
each_para *= k
num_para += each_para
str_num = str(each_para)
if len(str_num) <= 10:
str_num = str_num + (10 - len(str_num)) * blank
print('| {} | {} | {} |'.format(key, shape, str_num))
print('-' * 90)
print('The total number of parameters: ' + str(num_para))
print('The parameters of Model {}: {:4f}M'.format(model._get_name(), num_para * type_size / 1000 / 1000))
print('-' * 90)
model_structure(net)
------------------------------------------------------------------------------------------
| weight name | weight shape | number |
------------------------------------------------------------------------------------------
| conv1.weight | torch.Size([32, 1, 5, 5]) | 800 |
| conv1.bias | torch.Size([32]) | 32 |
| conv2.weight | torch.Size([64, 32, 5, 5]) | 51200 |
| conv2.bias | torch.Size([64]) | 64 |
| fc1.weight | torch.Size([62, 1024]) | 63488 |
| fc1.bias | torch.Size([62]) | 62 |
------------------------------------------------------------------------------------------
The total number of parameters: 115646
The parameters of Model Model: 0.115646M
------------------------------------------------------------------------------------------
import torch
a = [
[1, 2, 3],
[2, 3, 4]
]
a = torch.tensor(a)
print(a.size())
print(a.size(0))
print(a.size(1))
torch.Size([2, 3])
2
3
torch.autograd.grad()
x=torch.rand(2,2,requires_grad=True)
print(x)
y=torch.pow(x,2)
print(y)
z=torch.sum(y)
print(z)
dzdy=torch.autograd.grad(z,y,retain_graph=True)[0]
dzdx=torch.autograd.grad(y,x,grad_outputs=dzdy)[0]
print(dzdx)
# x.grad = None
Implement

What are x and y stand for?
3
---
**torch.autograd.grad()**
```python
x=torch.rand(2,2,requires_grad=True)
print(x)
y=torch.pow(x,2)
print(y)
z=torch.sum(y)
print(z)
dzdy=torch.autograd.grad(z,y,retain_graph=True)[0]
dzdx=torch.autograd.grad(y,x,grad_outputs=dzdy)[0]
print(dzdx)
# x.grad = None
Implement

What are x and y stand for?
?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









