







《FedMD: Heterogenous Federated Learning via Model Distillation》 论文阅读
NeurIPS 2019
文章目录
1 Introduction
在这项工作中,我们关注的是不同类型的异质性:本地模型的差异。在最初的联合框架中,所有用户都必须就集中模式的特定架构达成一致。当参与者是数百万台低容量设备(如手机)时,这是一个合理的假设。在这项工作中,我们将探索联合框架的扩展,这在面向企业的环境中是现实的,在这种环境中,每个参与者都有能力和愿望设计自己的模型。如果每个参与者都有不同的模型,而这些模型对其他人来说都是黑箱,那么如何进行联合学习呢?这就是我们要回答的核心问题。
这个问题与联合学习的非 i.i.d. 挑战密切相关,因为解决统计异质性的一个自然方法就是为每个用户建立个性化模型。事实上,现有的框架会产生截然不同的模型。例如,[10] 为多任务学习提供了一个框架,前提是问题是凸的。基于贝叶斯(Bayesian)[11]、元学习(meta-learning)[12]和迁移学习(transfer learning)[14]等框架的方法也能在非 i.i.d. 数据上实现良好的性能,同时允许一定量的模型定制。然而,据我们所知,所有现有框架都要求对局部模型的设计进行集中控制。完全模型独立性虽然与非 i.i.d. 问题相关,但其本身也是一个重要的新研究方向。
完全模型异构的关键在于通信。特别是,必须有一种转换协议,使深度网络能够在不共享数据或模型架构的情况下理解他人的知识。这个问题涉及深度学习的基本问题,如可解释性和新兴通信协议。原则上,机器应该能够学习适应任何特定用例的最佳通信协议。【??】作为朝这个方向迈出的第一步,我们采用了一种基于知识蒸馏的更透明框架来解决这个问题。
迁移学习是解决私有数据稀缺问题的另一个主要框架。在这项工作中,我们的私有数据集可能小到每类只有几个样本。因此,除了联合学习之外,利用大型公共数据集进行迁移学习也势在必行。我们通过两种方式利用迁移学习的力量。首先,在加入合作之前,每个模型都要先在公共数据上进行充分训练,然后再在自己的私有数据上进行训练。其次,更重要的是,黑盒模型根据它们在公共数据集样本上输出的类得分进行交流。这是通过知识蒸馏(knowledge distillation)实现的,它能够以一种与模型无关的方式传输所学信息。
Contributions: 这项工作的主要贡献在于 FedMD,它是一个新的联合学习框架,能让参与者独立设计自己的模型。我们的中央服务器不控制这些模型的架构,只需要有限的黑盒访问。我们认为该框架的关键要素是在参与者之间转换知识的通信模块。我们利用迁移学习和知识提炼的力量实现了这样一个通信协议。我们使用 FEMNIST 数据集和 CIFAR10/CIFAR100 数据集的子集测试了这一框架。我们发现,与没有协作的情况相比,使用该框架的本地模型性能有了明显提高。
2 Method
联合学习过程中有 m 个参与者。每个参与者都拥有一个非常小的标注数据集
D
k
:
=
{
(
x
i
k
;
y
i
k
)
}
i
=
1
N
k
D_k := \{(x ^k _i ; y_i^k)\}_{i=1}^{N_k}
Dk:={(xik;yik)}i=1Nk ,这个数据集可能来自同一个分布,也可能不是。此外,还有一个每个人都能访问的大型公共数据集
D
0
:
=
{
(
x
i
0
;
y
i
0
)
}
i
=
1
N
0
D_0 := \{(x ^0 _i ; y^0 _i )\}_{i=1}^{N_0}
D0:={(xi0;yi0)}i=1N0 。每个参与者独立设计自己的模型
f
k
f_k
fk 来执行分类任务。模型
f
k
f_k
fk 可以有不同的架构。此外,参与者之间无需共享超参数。我们的目标是建立一个协作框架,通过本地可访问的数据
D
0
D_0
D0 和
D
k
D_k
Dk,提高
f
k
f_k
fk 的性能,从而超越个人的努力。
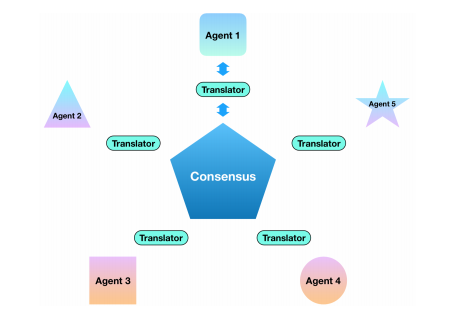
异构联合学习的通用框架。每个代理都拥有一个私有数据集和一个独特设计的模型。为了在不泄露数据的情况下进行交流与合作,代理需要将其学习到的知识转化为标准格式。中央服务器收集这些知识,并计算出分布在整个网络上的共识。在这项工作中,翻译器是通过知识蒸馏实现的。

Transfer learning: 在参与方开始合作阶段之前,其模型必须首先经历整个迁移学习过程。它将在公共数据集上进行全面训练,然后再在自己的私人数据上进行训练。因此,未来的任何改进都要与这一基线进行比较。
Communicate: 我们将公共数据集
D
0
D_0
D0 作为模型间Communicate的基础,并通过知识蒸馏来实现。每个学习者
f
k
fk
fk 通过共享在公共数据集
D
0
D_0
D0 上计算的类得分
f
k
~
(
x
i
0
)
\tilde{f_k}(x^0_i)
fk~(xi0) 来表达其知识。中央服务器收集这些类得分(没有转化为概率),并计算出一个平均值
f
~
(
x
i
0
)
\tilde{f}(x^0_i)
f~(xi0)。然后,每一方都对
f
k
f_k
fk 进行训练,以接近 consensus
f
~
(
x
i
0
)
\tilde{f}(x^0_i)
f~(xi0)。这样,一个参与者的知识就能被其他参与者了解,而无需明确共享其私有数据或模型架构。使用整个大型公共数据集会造成很大的通信负担。实际上,服务器可以在每一轮随机选择一个小得多的子集
d
j
⊂
D
0
d_j ⊂ D_0
dj⊂D0 作为通信的基础。这样,成本就可以得到控制,不会随着参与模型的复杂性而增加。
f ~ \tilde{f} f~
latex: \tilde{f}
我们将对 Algorithm 1 的实现过程中的重要细节进行说明:
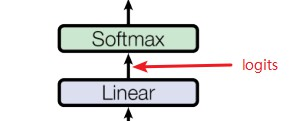
- 在Communication阶段,模型进行通信并对齐根据公共数据计算的 logits,而不应用 softmax 激活层。我们还可以使用具有特定温度的 softmax 分数 [Distilling the knowledge in a neural network],并且我们预计这种区别不会产生很大的影响。
- 在Communication阶段,我们不使用整个公共数据集,而是使用一个大小为 5000 的子集,在每一轮随机选择。这在不影响性能的情况下加快了进程。
- Digest 和 Revisit 阶段的轮数和批量大小控制着学习过程的稳定性。一个模型的测试性能可能会出现短暂的倒退,但在接下来的几轮测试中很快就会恢复。这个问题可以通过在 Revisit 阶段选择较少的历元数和在 Digest 阶段选择较大的批量来解决。
- 原则上,可以使用加权平均
f
(
x
i
0
)
=
∑
k
c
k
f
k
(
x
i
0
)
f(x^0_i ) = \sum_k c_k f_k(x^0_i )
f(xi0)=∑kckfk(xi0) 计算consensus。在这项工作中,我们几乎总是选择权重
c
k
c_k
ck 等于
1
/
N
p
a
r
t
i
e
s
1/N_{parties}
1/Nparties 。一个例外是在
CIFAR案例中,我们略微抑制了两个较弱模型(0 和 9)的贡献。当我们的模型或数据差异极大时,这些权重可能会变得更加重要。
logits就是最终的全连接层的输出。
softmax之前的值
3 Results
我们在两种不同的环境中测试了这一框架。
在第一种环境中,公共数据是 MNIST,私人数据是 FEMNIST 的一个子集。我们考虑了 i.i.d. 的情况,即每个私人数据集都是从 FEMNIST 中随机抽取的,也考虑了非 i.i.d. 的情况,即每个参与者在训练时只得到一个作者写的字母,但在测试时却被要求对所有作者的字母进行分类。
在第二个环境中,公共数据集是 CIFAR10,私有数据集是 CIFAR100 的子集,CIFAR100 有 100 个子类,属于 20 个超类,例如熊、豹、狮、虎和狼属于大型食肉动物。在 i.i.d. 的情况下,每个参与者的任务是将测试图像归入正确的子类。非 i.i.d.情况更具挑战性:在训练期间,每个参与者都有来自每个超类的一个子类的数据;在测试时,参与者需要将通用测试数据归入正确的超类。例如,在训练期间只见过狼的参与者要把狮子正确地归类为大型食肉动物。因此,它必须依靠其他参与者提供的信息
CIFAR-100中的100个类被分成20个超类。每个图像都带有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类)
超类 类别 大型食肉动物 熊,豹,狮子,老虎,狼
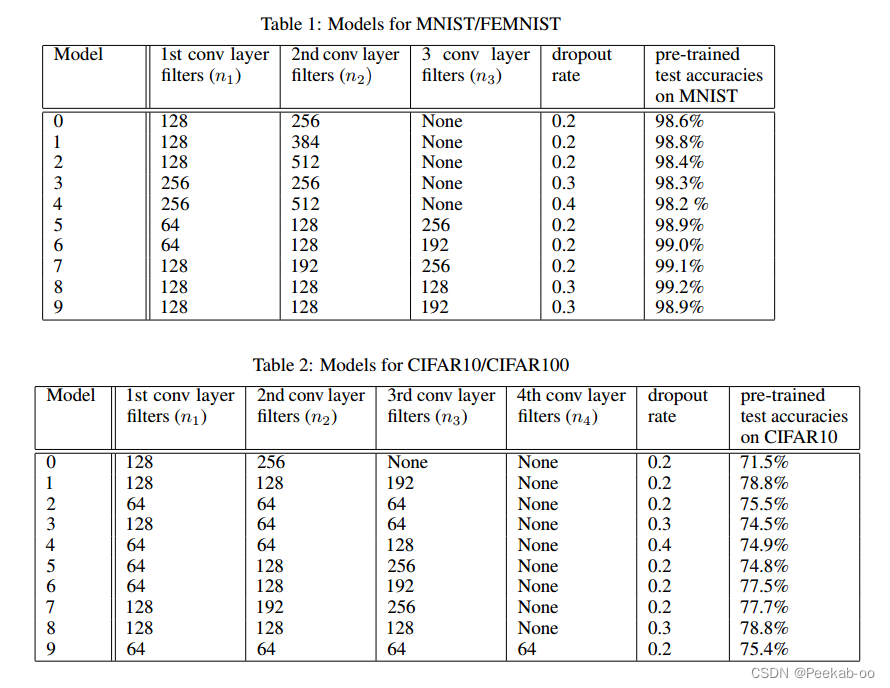
在每个环境中,10 名参与者设计出独特的卷积网络,这些网络的通道数和层数各不相同,详见表 1 和表 2。这些模型在 MNIST 和 CIFAR10 上的测试准确率分别为 99% 和 76%。其次,每个参与者在自己的小型私有数据集上训练自己的模型。完成这些步骤后,它们将进入协作训练阶段,在此期间,模型将获得全面而快速的改进,并迅速超越迁移学习的基线。我们使用Adam优化器,初始学习率为 0.001;在每一轮协作训练中,我们随机选择一个大小为 5000 的子集
d
j
⊂
D
0
d_j ⊂ D_0
dj⊂D0 作为Communication的基础。
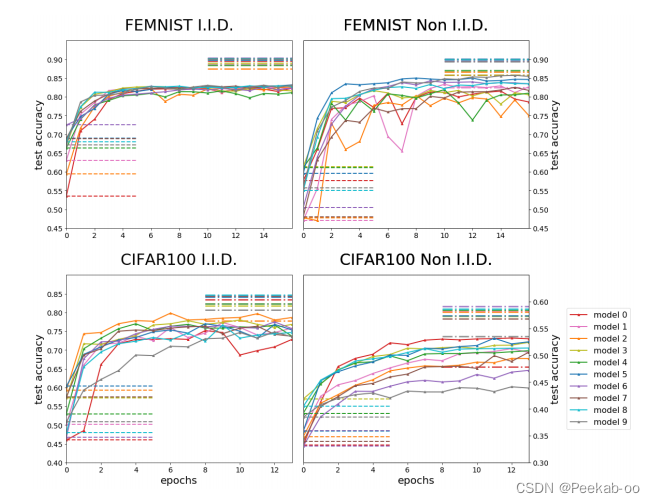
FedMD 提高了参与模型的测试准确率,超过了它们的基线。**虚线(左侧)表示模型在使用公共数据集和自己的小型私有数据集进行完全迁移学习后的测试准确率。**这条基线是我们的起点,与相应学习曲线的起点重合。虚线(右侧)表示如果所有参与者的私人数据集解密并提供给小组中的每个参与者,模型的预期性能。
我们讨论了我们结果的几个有趣的方面。
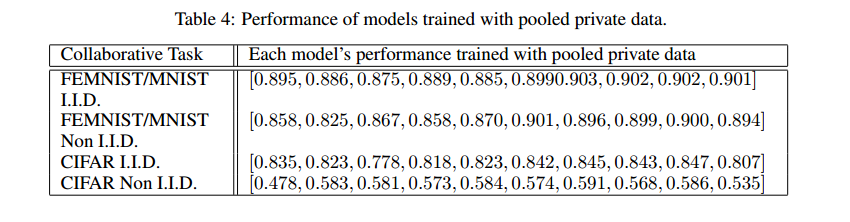
- 我们用一个模型在汇集所有参与者的私人数据并直接提供给全组的情况下所能达到的测试准确率来衡量我们的结果。请参阅表 4。通常我们的框架会将所有参与者的性能提升到仅比集合数据性能低几个百分点的水平。
- 在个别情况下,用我们的框架训练出来的模型一直优于用集合私有数据训练出来的同一模型。特别是
CIFAR非i.i.d.分布中的模型 0。此外,该模型的性能在大多数情况下都名列前茅。该模型具有最简单的架构,通常落后于更复杂的同类模型。了解这一成功背后的机制并利用它来改进我们的框架是很有趣的。 - 我们的框架可以包含模型异质性的极端情况。我们尝试了几种性能低得多的模型,例如两层全连接网络。如果它们对consensus的贡献与先进模型具有相同的权重,那么它们往往会阻碍群体的准确性。如果我们用较低的权重抑制它们的贡献,我们的框架会更好地工作。
4 Discussion and conclusion
在这项工作中,我们提出了 FedMD,这是一个能让独立设计的模型进行联合学习的框架。我们的框架以知识提炼为基础,并在各种任务和数据集上进行了测试。今后,我们将探索更复杂的通信模块,如特征转换和新兴通信协议,以进一步提高我们框架的性能。我们的框架还可应用于涉及 NLP 和强化学习的任务。我们将把框架扩展到异构的极端情况,包括数据量、模型能力和本地任务差异很大的情况。我们相信,异构联合学习将成为未来深度学习广泛应用于商业领域的重要工具。
5 复现
https://github.com/wanglikuan/fedmd_pytorch/tree/main/fedmd_simple/src

pre_train_result
[0.50146484375, 0.57890625, 0.62138671875, 0.65546875, 0.67978515625, 0.6955078125, 0.69541015625, 0.69111328125, 0.71416015625, 0.70986328125]
init_result
[0.28508772034394114, 0.44682017596144424, 0.3854166677123622, 0.4292763157894737, 0.32401315789473684, 0.41228070227723373, 0.39254386017197057, 0.3103070180667074, 0.31853070227723373, 0.3338815789473684]
pooled_train_result
[0.7779605263157895, 0.7845394736842105, 0.7417763157894737, 0.7461622827931454, 0.7445175459510401, 0.818530703845777, 0.8097587729755201, 0.818530703845777, 0.8146929835018358, 0.8174342105263158]
col_performance
[0.2719298248228274, 0.4331140361334148, 0.34375, 0.41337719402815165, 0.320175439119339, 0.4029605263157895, 0.3739035098176253, 0.30372807069828633, 0.29769736842105265, 0.3316885970140758]
效果很差😭















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









