







目录
一:中间件定义
1.为什么使用消息中间件
如有一个电商交易的场景,用户下单之后调用库存系统减库存,然后调用物流系统进行发货,如果刚开始交易,库存,物流都是属于一个系统,那么他们之间就是接口调用。但是随着系统的发展,各个模块业务越来越庞大、业务逻辑越来越复杂,这个时候就必然要做服务化和业务拆分。这个时候就需要考虑这些系统之间是如何交互的。首先想到的就是RPC(Remote Procedure Call),但是随着系统的发展,可能一笔交易后序需要调用几十个接口位于不同系统的接口,比如短信服务、邮件服务等等,这个时候就需要消息中间件来解决问题了。
消息中间件最突出的特点就是提供数据传输的可靠性和高效性,主要解决分布式的系统数据传输需求。
2.消息中间件的作用
(1):应用解耦
耦合:当实现某个功能的时候,直接接入当前接口
解耦:利用消息队列,将相应的消息发送到消息队列。允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。如果接口出现问题,将不会影响到当前的功能
(2):异步调用
允许用户把一个消息放入队列,但不立即处理,在需要的时候再去处理它们。同步变异步
(3)流量削峰
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。如:高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力。
3.消息中间件的术语
(1)Broker:消息服务器,提供核心服务
(2)Producer:消息生产者
(3)Consumer:消息消费者
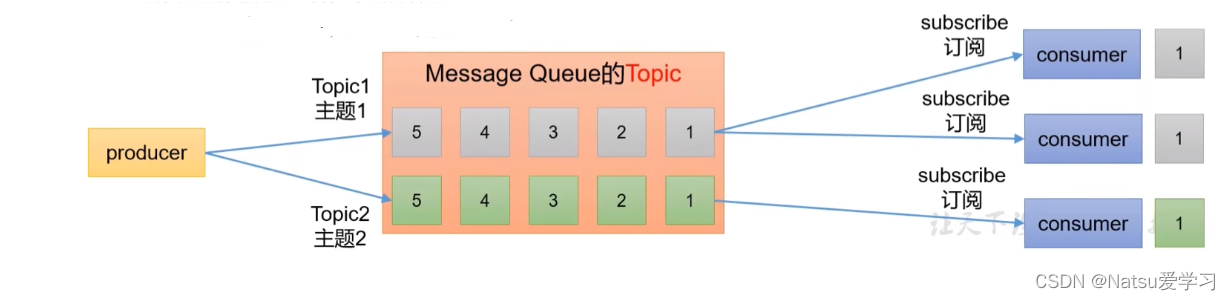
(4)Topic:主题,发布订阅模式下的消息统一汇集地
(5)Queue:队列,P2P模式下的消息队列
4.消息中间件工作模式
发布/订阅模式:
二:kafka定义及架构
1.kafka定义
Kafka是一个分布式流处理平台,也可以被用作分布式消息队列。Kafka具有高吞吐量和分布式发布订阅消息系统的特点,可以处理网站中所有动作流数据。
流处理是一种重要的大数据处理手段,其主要特点是其处理的数据是源源不断且实时到来的。分布式流处理是一种面向动态数据的细粒度处理模式,基于分布式内存,对不断产生的动态数据进行处理。其对数据处理的快速,高效,低延迟等特性,在大数据处理中发挥越来越重要的作用。
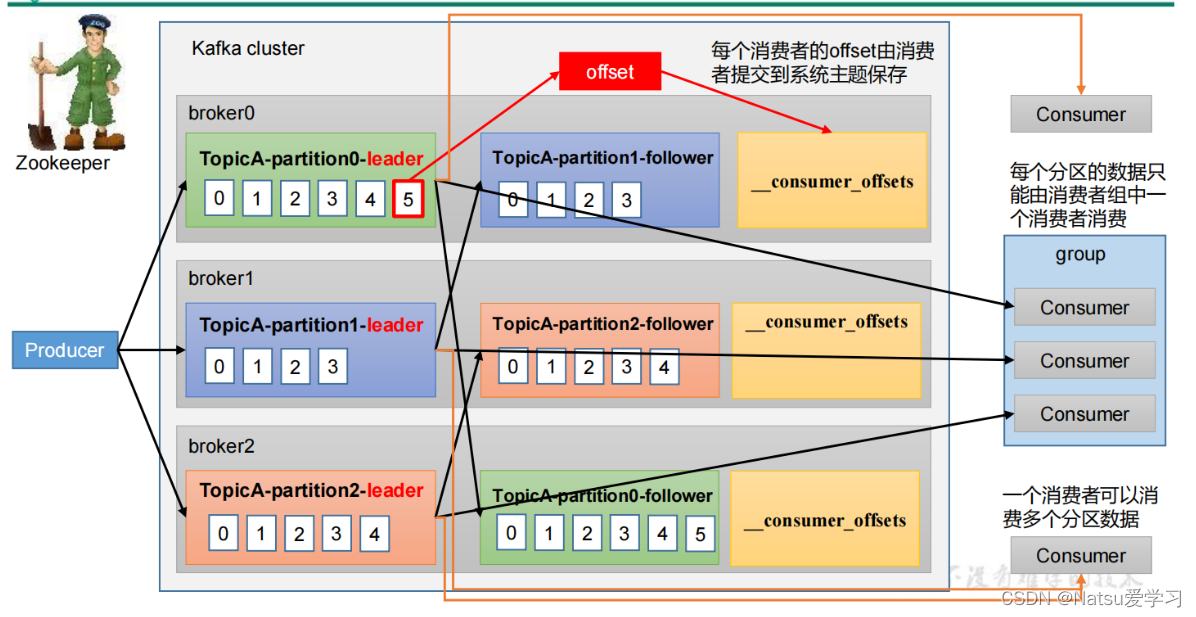
2.kafka架构
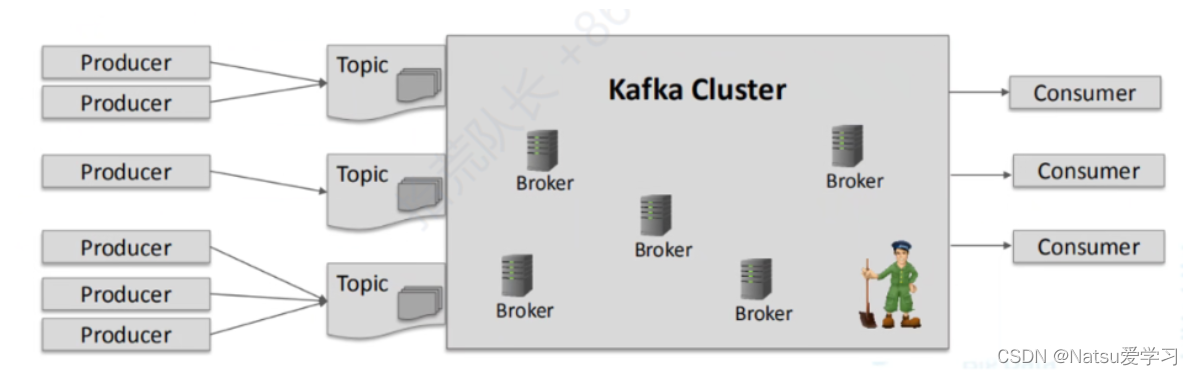
1)生产者:负责将数据写入到Kafka集群中的主题中
2)消费者:负责从主题中读取数据进行处理
3)topic(主题):是消息的逻辑容器,可以将相似的消息归类到同一个主题中。它用于实现数据的发布、订阅和消费。在Kafka中,数据被分割成多个小块,这些小块被称为Kafka Topic。Kafka集群由多个节点组成,每个节点都可以在Topic之间传递数据。
4)partition(分区):是主题的逻辑划分,用于实现数据的并行处理和负载均衡。
5)broker(代理):在Kafka集群中负责存储和处理数据的服务器节点。每个broker可以被分配一个唯一的broker id,并且通过设置监听端口来进行数据交互。Kafka broker与Zookeeper之间通过数据交互来维护集群的元数据信息。
3.kafka topic
1)Topic
(1)主题是已发布消息的类别名称
(2)发布和订阅数据必须指定主题
(3)主题副本数量不大于Brokers个数
2)Partition
(1)一个主题包含多个分区,默认按Key Hash分区
(2)每个Partition对应一个文件夹<>-<partition_id>
(3)每个Partition被视为一个有序的日志文件
(4)Replication策略是基于Partition,而不是Topic
(5)每个Partition都有一个leader,0或多个follower
3)Kafka Message
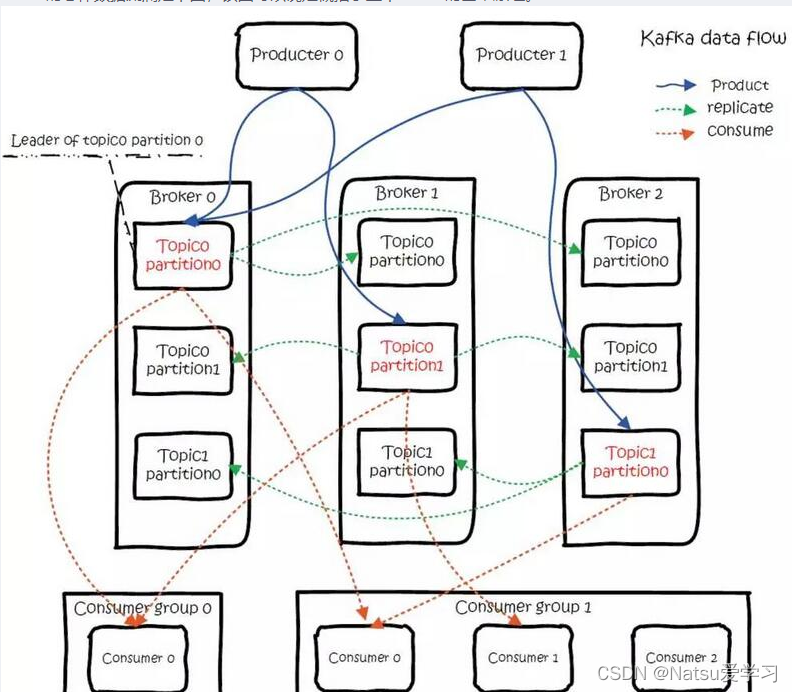
4.kafka数据流
(1)副本同步(ISR)
ISR(In-Sync Replicas)是与leader副本保持同步的副本集合。ISR的界定方式在Kafka 0.9版本前后是不同的。在Kafka 0.9版本之前,ISR的界定是基于副本的最后一个已确认的偏移量(Last Confirmed Offset,简称LEO)。只有当ISR中的所有副本都更新了对应的LEO后,leader副本才会向右移动HW值,表示写入成功。换句话说,只有ISR中的副本都与leader副本保持同步,才能保证数据的一致性和可靠性。
(2)容灾
是指在Kafka集群中,为了避免因单点故障而导致整个集群不可用,采取一系列措施保障集群的高可用性和数据的可靠性。其机制主要包括副本复制,ISR机制,多数据中心复制,消费者偏移量提交,监控和警报,来提高集群的可用性,保证数据的可靠性,实现故障自动切换及提升系统的稳定性。
(3)高并发
(4)负载均衡
5.Producer
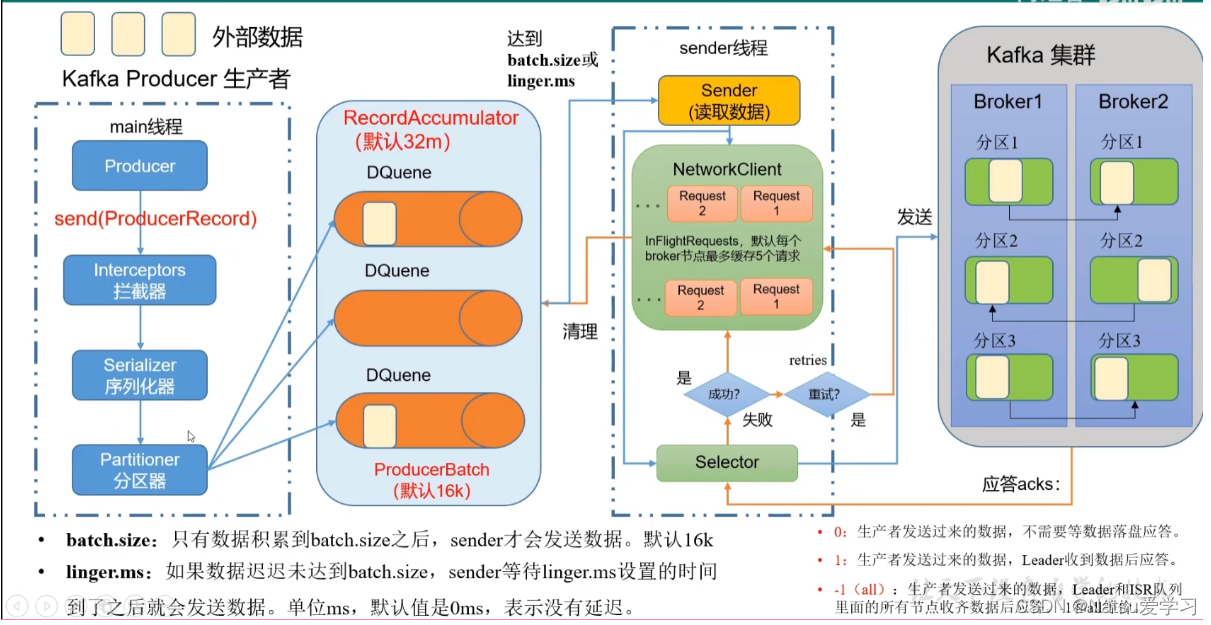
1)java构造producer
构建producer步骤:
(1)构造一个properties,然后指定bootstrap.server,key.serializer,value.serializer,acks.config。service代表,localhost:9092。key.serializer和value.serializer是指对应的key和value字符串的属性,acks.config是指ack的值
(2)使用构造好的properties构造KafkaProducer对象
(3)构造ProducerRecord对象,属性为对应的topic和填入的内容
(4)KafkaProducer对象的send发送
(5)关闭KafkaProducer对象
(1)控制台输入的方式调用
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.Scanner;
public class MyProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.10.129:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // 指定字符串类型
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class); //Value字符串类型
properties.put(ProducerConfig.ACKS_CONFIG,"-1"); //应答机制
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
Scanner scanner = new Scanner(System.in);
while(true){
System.out.println("请输入内容: ");
String msg = scanner.nextLine();
if(msg.equals("tt")){
break;
}
ProducerRecord<String, String> record = new ProducerRecord<>("bigdata", msg);
producer.send(record);
}
producer.close();
}
}(2)多线程生产
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class MyProducer3 {
public static void main(String[] args) {
final Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.10.137:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // 指定字符串类型
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class); //Value字符串类型
properties.put(ProducerConfig.ACKS_CONFIG,"-1"); //应答机制
properties.put(ProducerConfig.RETRIES_CONFIG,"3"); //重试次数
properties.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG,"1000"); //重试时间
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,102400); //批量大小,默认16kb
properties.put(ProducerConfig.SEND_BUFFER_CONFIG,102400);//每次发送大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,67108864);//缓存大小,默认32M
ExecutorService executorService = Executors.newCachedThreadPool(); //创建线程的缓存池
for(int i=0 ; i<10 ; i++){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
String threadName = Thread.currentThread().getName();
for(int j=0;j<1000000;j++){
ProducerRecord<String, String> record =
new ProducerRecord<>("bigdata001", threadName + " " + j);
producer.send(record);
}
}
});
executorService.execute(thread);
}executorService.shutdown();
while(true){
try {
Thread.sleep(10000); // 设置Thread的sleep时间,供所有子线程加载完数据
} catch (InterruptedException e) {
e.printStackTrace();
}
if(executorService.isTerminated()){
System.out.println("game over");
break;
}
}
}
}2)ACK机制
ACK机制指的是消息发送确认机制,它影响kafka集群的吞吐量和消息的可靠性.分别为1(默认),0,-1
ACK=1时,Producer会等待Leader接收到消息并返回确认响应,这可以提供较高的可靠性
ACK=0时,Producer不会等待任何确认响应,这能够提供最高的吞吐量,但可能会导致消息的丢失
ACK=-1时,Producer会等待Leader和所有的Replica都接收到消息并返回确认响应,这提供了最高的可靠性,但会降低吞吐量
3)HW和LEO
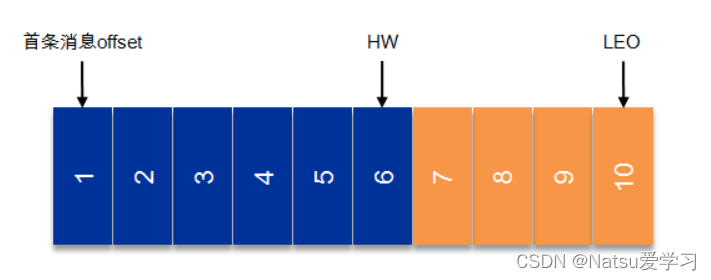
LEO:表示每个partition的log最后一条Message的位置
HW:取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置
6. Consumer
1)java构造consumer
(1)单线程构造
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class MyConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.10.129:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
/*
* 设置是否自动提交,获取数据的状态 false:手动提交;true:自动提交
* */
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); //多久自动提交一次
/*
* 设置消费者组
* */
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"groupa1");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Collections.singleton("kb23_2"));
while(true){
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String,String> recored:
records) {
System.out.println(" topic: "+recored.topic()+" partition: "+recored.partition()+" 偏移量: "+recored.offset()+
" value: "+recored.value()+" 时间戳: "+recored.timestamp());
}
// 手动提交;如果设置成自动提交,则不需要下面一行
kafkaConsumer.commitAsync();
}
}
}(2)多线程构造
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class MyConsumer2 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.10.129:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
//properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); //多久自动提交一次
/*
* 设置消费者组
* */
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"threadgroup1");
for(int i=0;i<=2;i++){
new Thread(new Runnable() {
@Override
public void run() {
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Collections.singleton("kb23_2"));
while(true){
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println(Thread.currentThread().getName()+
" topic: "+record.topic()+
" partition: "+record.partition()+
" 偏移量: "+record.offset()+
" value: "+record.value()+
" 时间戳: "+record.timestamp());
}
// 手动提交
// kafkaConsumer.commitAsync(); //此处需要手动提交,不设置手动提交是为了下面seek调取数据
}
}
}).start();
}
}
}
(3)seek调取对应的偏移量内容
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class MyConsumer3 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.10.129:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"groupxx");
for(int i=0;i<=2;i++){
new Thread(new Runnable() {
@Override
public void run() {
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Collections.singleton("xxww"));
while(true){
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println(Thread.currentThread().getName()+
" topic: "+record.topic()+
" partition: "+record.partition()+
" 偏移量: "+record.offset()+
" value: "+record.value()+
" 时间戳: "+record.timestamp());
}
}
}
}).start();
}
}
}2)消费模式
earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 latest : 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的数据 none : 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,抛出异常
















 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









