







一般的分类模型建立的步骤,分为两种:
积极学习法 (决策树归纳):先根据训练集构造出分类模型,根据分类模型对测试集分类。
消极学习法 (基于实例的学习法):推迟建模, 当给定训练元组时,简单地存储训练数据 (或稍加处理) ,一直等到给定一个测试元组。
消极学习法在提供训练元组时只做少量工作,而在分类或预测时做更多的工作。KNN就是一种简单的消极学习分类方法,它开始并不建立模型,而只是对于给定的训练实例点和输入实例点,基于给定的邻居度量方式以及结合经验选取合适的k值,计算并且查找出给定输入实例点的k个最近邻训练实例点,然后基于某种给定的策略,利用这k个训练实例点的类来预测输入实例点的类别。
特例: 当K=1时,即为最近邻算法(Nearest Neighbor)
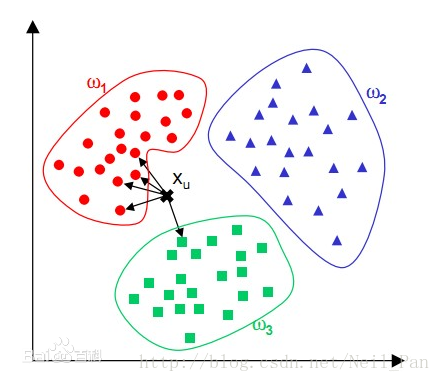
基本原理:
(1)计算新样本与训练样本对象之间得距离度量值;
(2)找出与训练样本中距离最近得K个训练样本;
(3)根据投票法则,找到K个训练样本中占据数量最多得某一类别,并将该类别赋值给新样本,完成分类
适用性:KNN分类时,只与最相邻得K个训练样本得类别有关,不是靠判别类域的方法来确定所属类别,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
常见问题
1、k值设定为多大?
k太小,分类结果易受噪声点影响;k太大,近邻中又可能包含太多的其它类别的点。(对距离加权,可以降低k值设定的影响)
k值通常是采用交叉检验来确定(以k=1为基准)
经验规则:k一般低于训练样本数的平方根
2、类别如何判定最合适?
投票法没有考虑近邻的距离的远近,距离更近的近邻也许更应该决定最终的分类,所以加权投票法更恰当一些。
3、如何选择合适的距离衡量?
高维度对距离衡量的影响:众所周知当变量数越多,欧式距离的区分能力就越差。
变量值域对距离的影响:值域越大的变量常常会在距离计算中占据主导作用,因此应先对变量进行标准化。
4、训练样本是否要一视同仁?
在训练集中,有些样本可能是更值得依赖的。
可以给不同的样本施加不同的权重,加强依赖样本的权重,降低不可信赖样本的影响。
5、性能问题?
kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。
已经有一些方法提高计算的效率,例如压缩训练样本量等。
6、能否大幅减少训练样本量,同时又保持分类精度?
浓缩技术(condensing)
编辑技术(editing)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









