







2.1 内置序列的类型
-
按照存储内容分类
1). 容器序列
可以存放不同类型的序列,本质上它们存储的都是类型的引用,如list,tuple,colections.deque
2). 扁平序列
这类序列只能存储一种数据类型,本质上是一段连续的内存空间,如str,bytes,array.array等 -
按照能否被修改分类
1). 可变序列
list,bytearray,array.array
2). 不可变序列
tuple,str,bytes
2.2 列表推倒和生成表达式
2.2.1 生成一个列表
生成列表可以通过以下两种方式,一种用循环一种用列表生成式,通常列表生成式的可读性更强。
symbols = 'ABC'
# 循环
codes = []
for symbol in symbols:
codes.append(symbol)
print(codes)
# 生成式
codes = [ord(symbol) for symbol in symbols]
print(codes)
通常在循环体只有一句话时我们采用列表生成式
ord函数为求得一个字符的unicode编码
2.2.2 利用内置的filter和map来生成表达式
symbols = 'ABCαβγ'
beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
beyond_ascii = list(filter(lambda c: c < 127, map(ord, symbols)))
这里的
filter用法参见:runoob:filter()
map用法参见:runoob:map()
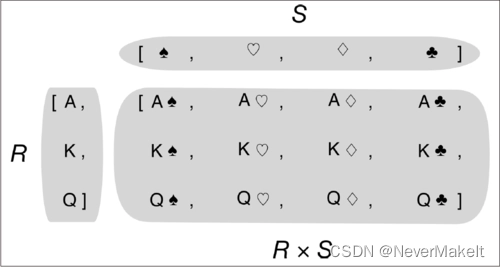
2.2.3 笛卡尔积
笛卡尔积在构造笛卡尔坐标系时非常常用,下图是笛卡尔积的定义
cartesian_coordinates = [(x, y) for x in range(10)
for y in range(10)]
print(cartesian_coordinates)
2.2.4 生成器表达式
生成器表达式就是将列表生成式的方括号换成圆括号,但生成器是一个一个产出元素,而不是想列表生成式一样先产出一个列表,在把列表当作值传递出去。后者更加节省内存
利用生成器输出笛卡尔坐标
2.3 元组
元组虽然属于不可变列表,但是他的功能不仅仅局限于不可变列表,它还可以被当作没有字段名的记录。
2.3.1 元组和记录
下面是元祖作为记录的常见用法
lax_coordinates = (33.945, -118.408056)
city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014)
traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')]
for passport in sorted(traveler_ids):
print('%s/%s' % passport)
for country, _ in traveler_ids:
print(country)
2.3.2 元组拆包
拆包就是将元祖中的记录给各个变量,特殊的用法是可以用*args 来获取不确定数量的参数
a, b, *rest = range(5)
a, *rest, b = range(5)
2.3.3 嵌套拆包
接受表达式的元祖也同样可以是嵌套式的,例如
a, b, (c, d) = 1, 2, (3, 4)
只要模式匹配就能解包
2.3.4 具名元组
作为记录功能的元组有个缺陷,那就是无法记录元组的字段名。因此,具名元组应韵而生。具名元祖通常可以相当于一个没有方法的类。
Card = collections.namedtuple('Card', ['rank', 'suit'])
具名元祖的第一个参数是相当于是类名,rank,suit相当于是类的两个属性。出现在本书开头的例程充分体现了具名元组的功能
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split() # 不用手敲字符串列表
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, item):
return self._cards[item]
2.3.5 元组作为不可变序列
注意作为不可变序列不能插入,添加,修改,但是可以拼接使用+,同时也可以使用reversed函数,虽然元组没有__reversed__ 方法
2.4 切片
2.4.1 对对象进行切片
s[a:b:c] 表示对s在a和b之间以c为间隔取值,可以省略a,b,c但是不能省略:
s = 'bicycle'
# 1. 指定下标3可以利用切片将序列分为两个部分
left_s, right_s = s[:3], s[3:]
# 2. 提取最后一个元素
s_back = s[-1]
# 3. 实现序列反转
s_reversed = s[::-1]
2.4.2 对切片命名
invoice = """
0.....6.................................40........50...55....
1909 Pimoroni PiBrella $17.50 3 $52.50
1489 6mm Tactile Switch x20 $4.95 2 $9.90
1510 Panavise Jr. -PV-201 $28.00 1 $28.00
1601 PiTFT Mini Kit 320x240 $34.95 1 $34.95
"""
SKU = slice(0, 6)
DESCRIPTION = slice(6, 40)
UNIT_PRICE = slice(40, 52)
QUANTITY = slice(52, 55)
ITEM_TOTAL = slice(55, None)
line_items = invoice.split('\n')[2:]
for item in line_items:
print(item[UNIT_PRICE], item[DESCRIPTION])
这种对切片字段的命名方式,十分清晰能很大提高程序的可读性
2.4.3 多维切片
对数组多个维度进行切片常用,分开,例如对一个二维数组a的第三行至第四行,第三列至第六列进行切片a[3:5, 3:7]。特殊的针对更高维的数组进行切片,例如四维数组b[1:3, :,:,:],可以省略写为b[1:3, ...]
2.4.4 对切片赋值
切片不仅可以获取数值,还能够通过操作切片修改序列
l = list(range(10))
l[2:5] = [20, 30]
# 0,1,20,30,5,6,7,8,9
del l[5:7]
# 0,1,20,30,5,8,9
l[3::2]=[11, 22]
# 0,1,20,11,5,22,9
l[2:5]=[100] # 这里100必须用方括号括起来不然报错
# 0,1,100,22,9
2.5对序列使用+ *
+可以拼接两个序列,调用内置方法__add__
*可以重复一个序列,调用内置方法__mul__
*+都是在原有序列的基础上构建出的一个全新的序列,而不修改原有的操作对象
需要额外注意的是,如果你想用*来初始化一个由列表组成的列表[[]]*3,这样写是不行的,因为里层的序列是一个引用,这样复制的三个列表实际上共用了一个列表的内存空间
例如:
board = [['_'] * 3 for i in range(3)]
# 这种初始化嵌套列表的方式是正确的
# 它相当于以下操作
board = []
for i in range(3):
row = ['_'] * 3
board.append(row)
以下方式则是错误的
weird_board = [['_'] * 3] * 3
# 它相当于是以下操作
row = ['_'] * 3
board = []
for i in range(3):
board.append(row)














 2216
2216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









