







最近朋友问到我关于List<Map>中根据map的一个属性去重的问题,刚刚写了一个例子,给大家分享一下,应该还有更好的办法,如果有好的建议或问题,可以留言告诉我。
现在已有优化解点击 点击打开链接
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class Test2 {
public static void main(String[] args) {
List<Map<String, Object>> list = new ArrayList<Map<String, Object>>();
Map map1 = new HashMap();
map1.put("ppdz", "12341");
map1.put("name", "啦啦1");
Map map2 = new HashMap();
map2.put("ppdz", "12341");
map2.put("name", "啦啦2");
Map map3 = new HashMap();
map3.put("ppdz", "123");
map3.put("name", "啦啦3");
Map map4 = new HashMap();
map4.put("ppdz", "1234");
map4.put("name", "啦啦4");
Map map5 = new HashMap();
map5.put("ppdz", "1235");
map5.put("name", "啦啦5");
Map map6 = new HashMap();
map6.put("ppdz", "12346");
map6.put("name", "啦啦6");
Map map7 = new HashMap();
map7.put("ppdz", "123");
map7.put("name", "啦啦7");
Map map8 = new HashMap();
map8.put("ppdz", "12345");
map8.put("name", "啦啦8");
Map map9 = new HashMap();
map9.put("ppdz", "12345");
map9.put("name", "啦啦9");
list.add(map1);
list.add(map2);
list.add(map3);
list.add(map4);
list.add(map5);
list.add(map6);
list.add(map7);
list.add(map8);
list.add(map9);
// 新建set集合用于标记重复的id
Set arr = new HashSet();
// 新建集合用于接收去重过的Map
List<Map<String, Object>> newlist = new ArrayList<Map<String, Object>>();
// 外层循环从第一个开始遍历
for (int i = 0; i < list.size(); i++) {
// 判断i值是否存在于arr内,如果存在说明之前比较过排除这个循环
if (arr.contains(i)) {
continue;
}
// 获取map对象
Map m1 = list.get(i);
// 把map对象存放进新的list集合中
newlist.add(m1);
// 内层循环从下一个map开始获取比较
for (int j = i + 1; j < list.size(); j++) {
// 获取map对象
Map m2 = list.get(j);
// 比较m1和m2各自键为ppdz的值,如果相等说明这个为重复项
if (m1.get("ppdz").equals(m2.get("ppdz"))) {
// 纪录重复项的下标到arr中,防止重复判断
arr.add(j);
continue;
}
}
}
// 遍历得到结果
for (Map m : newlist) {
System.out.println(m.get("ppdz") + " " + m.get("name"));
}
}
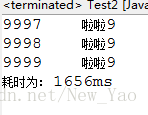
}运行结果如图:

这个是保留前面的,如果需要保留后面的把循环倒过来应该就可以了。
下面来测试一下这个的执行效率
插入1w条不同的map
for(int i=0;i<10000;i++){
Map map = new HashMap();
map.put("ppdz", i);
map.put("name", "啦啦9");
list.add(map);
}
下面插入10w条不同的map测试
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", i);
map.put("name", "啦啦9");
list.add(map);
}
下面测试一下共100w条记录,并且每一万条记录是相等的
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "1");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "2");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "3");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "4");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "5");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "6");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "7");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "8");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "9");
map.put("name", "啦啦9");
list.add(map);
}
for(int i=0;i<100000;i++){
Map map = new HashMap();
map.put("ppdz", "10");
map.put("name", "啦啦9");
list.add(map);
}
所以如果你需要去除的重复量比较大,完全可以这样用!














 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









