







1、安装requests 和 BeautifulSoup
2、查看permit.mee.gov.cn网站信息
from bs4 import BeautifulSoup
import requests
datas = {"xkgk": "getxxgkContent", "dataid": "38467816d913465a82878598c9e356fd"}
r = requests.post("http://permit.mee.gov.cn/permitExt/xkgkAction!xkgk.action",data=datas)
html = r.content.decode(encoding="utf-8-sig")
soup=BeautifulSoup(html,'html.parser') #变格式,删除无用空格
print(soup.text) #显示爬取的信息
print(soup.status_code) #显示链接目标网站是否成功。显示200即表示成功
with open("d:\data.txt","w",encoding='utf-8') as f: #用 utf-8 编码打开 (实际文件的编码方式)
f.write(soup.text) #将爬取内容写入文本文件
续:
第一步,打开网址
第二步,进入谷歌浏览器,开发者工具
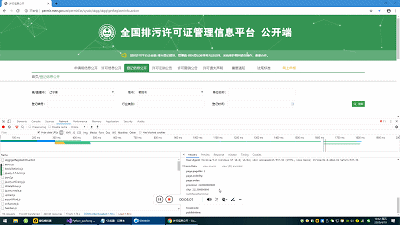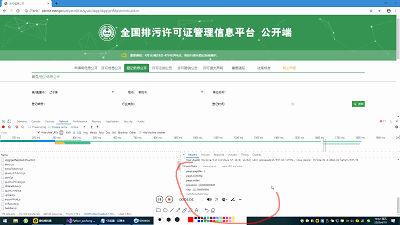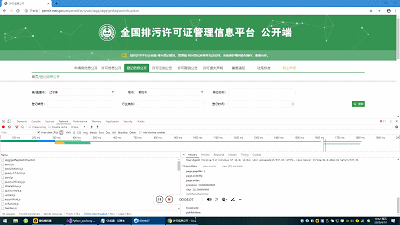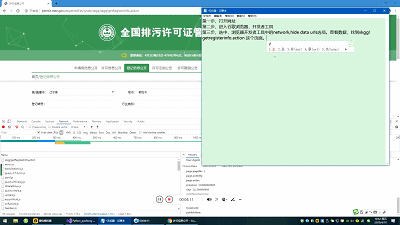
第三步,选中,浏览器开发者工具中的network,hide data urls选项。查看数据,找到xkgg!getregisterinfo.action 这个页面。就可以看到数据处理页面和数据需要转递的数据。数据为:form data 表单中的数据。
第四步,将网页地址和页面传递的数据用requests进行处理。
from bs4 import BeautifulSoup
import requests
datas = {"page.pageNo": "1",
"page.orderBy":"",
"page.order":"",
"province": "210000000000",
"city":"211300000000",
"registerentername":"",
"xkznum":"",
"treadname":"",
"treadcode":"",
"publishtime": ""}
r = requests.post("http://permit.mee.gov.cn/permitExt/syssb/xkgg/xkgg!licenseInformation.action",data=datas)
html = r.content.decode(encoding="utf-8-sig")
soup=BeautifulSoup(html,'html.parser') #变格式,删除无用空格
print(soup.text) #显示爬取的信息
print(soup.status_code) #显示链接目标网站是否成功。显示200即表示成功
print(soup.title.string)
with open("d:\data.txt","w",encoding='utf-8') as f: #用 utf-8 编码打开 (实际文件的编码方式)
f.write(soup.text)















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









