







输入域与输出
输入/输出流
可以读入一个字节序列的对象的对象称为输入流, 可以向其中雪茹一个字节序列的对象称为输入流
通常是文件, 但也可以是网络连接, 甚至是内存块
抽象类InputStream和OutputStream构成了(I/O)类层次结构的基础。
读写字节
abstract int read()
这个方法将读入一个字节, 或在遇到结尾返回-1
以下方法读取流中所有字节
byte[] bytes = in.readAllBytes();
一次性写出一个字节数组
byte[] values = ...;
out.write(values);
transferTo方法将所有字节从一个输入流传递到另一个输出流
in.transferTo(out);
available方法检查当前可读入的字节数量
int byteAvailable = in.available();
if(byteAvailable > 0)
{
var data = new byte[bytesAvailable];
in.read(data);
}
完整的流家族
InputStream类和OutputStream类可以读写单个字节或字节数组, 这些类构成流结构基础
DataInputStream和DataOutputStream可以以二进制格式读写所有java基本类型
ZipInputStream和ZipOutoutStream可以以ZIP压缩格式读写文件
对于Unicode文本, 可以使用抽象类Reader和Writer的子类
四个附加接口:Closeable, Flushable, Readable和Appendable
前两个接口分别拥有以下方法
void close() throws IOException
void flush()
Readable接口只有一个方法
int read(CharBuffer cb)
Appendable接口有两个用于添加单个字符和字符序列的方法
Appendable append(char c)
Appendable append(CharSequence s)
CharSequence接口描述了一个char值的基本属性
在流类的家族中只有Writer实现了Appendable
组合输入/输出流过滤器
var fin = new FileInputStream("employee.dat");
只能从fin对象读入字节和字节数组
byte b = (byte) fin.read();
DataInputStream din = ...;
double x = din.readDouble();
DataInputStream没有从文件中获取流的方法, FileInputStream没有任何读入数值的方法
将两者组合
var fin = new FileInputStream("employee.dat");
var din = new DataInputStream(fin);
double x = din.readDouble();
FilterInputStream 和 FilterOutputStream 类用于向处理字节的输入输出流添加额外的功能。
若想用缓冲机制和用于文件的数据输入方法
var din = new DataInputStream(
new BufferedInputStream(
new FileInputStream("employee.dat")));
当多个输入流连接在一起时, 需要跟踪各个中介输入流(intermediate input stream).
例如, 当经常需要预览下一个字节时
var pbin = new PushbackInputStream(
new BufferedInputStream(
new FileInputStream("employee.dat")));
int b = pbin.read();
if(b != '<') pbin.unread(b);
如果希望能够预先浏览还能读入数字, 就需要一个即使可回推输入流, 又是数据输入流的引用
PushbackInputStream pbin;
var din = new DataInputStream(
pbin = new PushbackInputStream(
new BufferedInputStream(new FileInputStream("employee.dat"))));
文本输入与输出
OutputStreamWriter类将使用选定的字符编码方式, 把Unicode码元的输出流转换为字节流, 而InputStreamReader类将包含字节的输入流转换为可以产生Unicode码元的读入器
var in = new InputStreamReader(System.in);
//or
var in = new InputStreamReader(new FilInputStream("data.txt"), StandardCharsets.UTF_8);
Reader和Writer类都只有读入和读出单个字符的基础方法。
##如何写出文本输出
对于文本输出, 使用PrintWriter, 这个类拥有以文本格式打印字符串和数字的方法
var out = new PrintWriter("employee.txt", StandardCharsets.UTF_8);
默认情况下自动冲刷机制是禁用的
可以通过使用PrintWriter(Writer writer, boolean autoFlush)来启动的禁用自动刷新
var out = new PrintWriter(
new OutputStream(
new FileOutputStream("employee.txt"), StandartCharsets.UTF_8), true);
如何读入文本输入
最简单的处理任意文本的方式是使用Scanner类
也可以将文本文件直接一次性读入字符串中
var content = (Files.read String path, charset);
将文件一行行的读入
List<String> lines = Files.readAllLines(path, charset);
若文件太大, 可以将行惰性处理为一个Stream对象
try(Stream<String> lines = Files.lines(path, charset))
{
...
}
还可以使用Scanner 来读入token, 即由分隔符分割的字符串, 可以将分隔符修改为任意的正则表达式
Scanner in = ...;
in.useDelimiter("\\PL+");
while(in.hasNext())
{
String word = in.next();
...
}
也可以如下, 获取一个token流
Stream<String> words = in.tokens();
以文本格式存储对象
package textFile;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.charset.StandardCharsets;
import java.time.LocalDate;
import java.util.Scanner;
/**
* @author Cay Horstmann
*/
public class TextFileTest
{
public static void main(String[] args)throws IOException {
var staff = new Employee[3];
staff[0] = new Employee("Carl Cracker", 75000, 1987, 12, 15);
staff[1] = new Employee("Harry Hacker", 50000, 1989, 10, 1);
staff[2] = new Employee("Tony Tester", 40000, 1990, 3, 15);
//save all employee records to the file employee.dat
try(var out = new PrintWriter("employee.dat", StandardCharsets.UTF_8))
{
writeData(staff, out);
}
//retrieve all records into a new array
try(var in = new Scanner(new FileInputStream("employee.dat"), StandardCharsets.UTF_8))
{
Employee[] newStaff = readData(in);
//print the newly read employee records
for (Employee e : newStaff) {
System.out.println(e);
}
}
}
/**
* Write all employees in an array to a print writer
* @param employees an array of employees
* @param out a print writer
*/
private static void writeData(Employee[] employees, PrintWriter out) throws IOException
{
//write number of employees
out.println(employees.length);
for(Employee e: employees)
writeEmployee(out, e);
}
/**
* Read an array of employees from a scanner
* @param in the scanner
* @return the array of employees
*/
private static Employee[] readData(Scanner in)
{
//retrieve the array size
int n = in.nextInt();
in.nextLine(); //consume newline
var employees = new Employee[n];
for (int i = 0; i < n; i++) {
employees[i] = readEmployee(in);
}
return employees;
}
/**
* Writes employee data to a print writer
* @param out the print writer
*/
public static void writeEmployee(PrintWriter out, Employee e)
{
out.println(e.getName() + "|" + e.getSalary() + "|" + e.getHireDay());
}
/**
* Reads employee data from a buffered reader
* @param in the scanner
*/
public static Employee readEmployee(Scanner in)
{
String line = in.nextLine();
String[] tokens = line.split("\\|");
String name = tokens[0];
double salary = Double.parseDouble(tokens[1]);
LocalDate hireDate = LocalDate.parse(tokens[2]);
int year = hireDate.getYear();
int month = hireDate.getMonthValue();
int day = hireDate.getDayOfMonth();
return new Employee(name, salary, year, month, day);
}
}
字符编码方式
输入和输出流都是用于字节序列的, 但是许多情况下, 需要操作的是字符序列
**有些文件在开头添加了一个字节顺序标记, 即0xFEFF, 读入器可以使用这个值确定字节顺序, 然后丢弃它。
为了获取另一种编码方式的charset, 可以使用forName方法
Charset shiftJIS = Charset.forName("Shift-JIS");
读写二进制数据
DataInput和DataOutput接口
DataOutput接口定义了一系列用于以二进制格式写数组, 字符, boolean值和字符串的方法。
writeInt总是将一个正数写出为4字节的二进制数量值, writeDouble总是将一个double值写出为8字节的二进制数量值
writeUTF方法使用修订版的Unicode转换格式写出字符串, 其中, Unicode码元首先用UTF-16表示, 其结果之后使用UTF-8进行编码。
(没有其他方法会使用UTF-8这种修订)
当需要编写一个生成字节码的程序时, 对于大多数场合, 都应该使用writeChars方法
为了读回数据, 可以使用DataInput接口中定义的一系列方法
随机访问文件
RandomAccessFile类可以在文件中的任何位置查找或写入数据。
磁盘文件都是随机访问的, 而与网络套接字通信的输入/输出流却不是。
var in = new RandomAccessFile("employee.dat", "r");
var inOut = new RandomAccessFile("employee.dat", "rw");
当将已有文件打开时, 这个文件并不会删除
seek方法用来将这个文件指针设置到文件中的任意字节位置
getFilePointer方法返回文件指针的当前位置。
RandomAccessFile同时实现了DataInput和DataOutput接口。
假设希望读入一个雇员记录从第三条记录处
long n = 3;
in.seek((n - 1) * RECORD_SIZE);
var e = new Employee();
e.readData(in);
如果希望修改记录, 存回相同位置, 切记把文件指针置回该记录起始位置
in.seek((n - 1) * RECORD_SIZE);
e.writeData(out);
要确定文件中的字节总数
long nbytes = in.length();
int nrecords = (int) (nbytes / RECORD_SIZE);
如下程序将三条记录写入并读回
package randomAccess;
import java.io.*;
import java.time.LocalDate;
/**
* @author Cay Horstmann
*/
public class RandomAccessTest {
public static void main(String[] args)throws IOException {
var staff = new Employee[3];
staff[0] = new Employee("Carl Cracker", 75000, 1987, 12, 15);
staff[1] = new Employee("Harry Hacker", 50000, 1989, 10, 1);
staff[2] = new Employee("Tony Tester", 40000, 1990, 3, 15);
try(var out = new DataOutputStream(new FileOutputStream("employee.dat")))
{
//save all employee records to the file employee.dat
for (Employee e : staff) {
writeData(out, e);
}
}
try(var in = new RandomAccessFile("employee.dat", "r"))
{
//retrieve all records into a new array
//compute the array size
int n = (int)(in.length() / Employee.RECORD_SIZE);
var newStaff = new Employee[n];
//read employees in reverse order
for(int i = n - 1; i >= 0; i--)
{
newStaff[i] = new Employee();
in.seek(i * Employee.RECORD_SIZE);
newStaff[i] = readData(in);
}
//print the newly read employee records
for (Employee employee : newStaff) {
System.out.println(employee);
}
}
}
/**
* Writes employee data to a data output
* @param out the data output
* @param e the employee
*/
public static void writeData(DataOutput out, Employee e) throws IOException
{
DataIO.writeFixedString(e.getName(), Employee.NAME_SIZE, out);
out.writeDouble(e.getSalary());
LocalDate hireDay = e.getHireDay();
out.writeInt(hireDay.getYear());
out.writeInt(hireDay.getMonthValue());
out.writeInt(hireDay.getDayOfMonth());
}
/**
* Reads employee data from a data input
* @param in the data input
* @return the employee
*/
public static Employee readData(DataInput in) throws IOException
{
String name = DataIO.readFixedString(Employee.NAME_SIZE, in);
double salary = in.readDouble();
int y = in.readInt();
int m = in.readInt();
int d = in.readInt();
return new Employee(name, salary, y, m, d);
}
}
package randomAccess;
import javax.swing.*;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class DataIO {
public static void writeFixedString(String s, int size, DataOutput out) throws IOException
{
for (int i = 0; i < size; i++) {
char ch = 0;
if(i < s.length()) ch = s.charAt(i);
out.writeChar(ch);
}
}
public static String readFixedString(int size, DataInput in) throws IOException
{
var b = new StringBuilder(size);
int i = 0;
var done = false;
while(!done && i < size)
{
char ch = in.readChar();
i++;
if(ch == 0) done = true;
else b.append(ch);
}
in.skipBytes(2 * (size - i));
return b.toString();
}
}
package randomAccess;
import java.time.LocalDate;
public class Employee
{
public static final int NAME_SIZE = 40;
public static final int RECORD_SIZE = 2 * NAME_SIZE + 8 + 4 + 4 + 4;
private String name;
private double salary;
private LocalDate hireDay;
public Employee() {
}
public Employee(String n, double s, int year, int month, int day)
{
name = n;
salary = s;
hireDay = LocalDate.of(year, month, day);
}
public String getName()
{
return name;
}
public double getSalary()
{
return salary;
}
public LocalDate getHireDay()
{
return hireDay;
}
public void raiseSalary(double byPercent)
{
double raise = salary * byPercent / 100;
salary += raise;
}
public String toString()
{
return getClass().getName()
+ "[name=" + name + ",salary=" + salary + ",hireDay=" + hireDay + "]";
}
}
zip文档
每个ZIP文档都有一个头, 包含诸如每个文件名字和所使用的压缩方法等信息。在java中, 使用ZipInputStream读入ZIP文档, getNextEntry方法可以返回一个描述这些项的ZipEntry类型的对象, 该方法会从流中读入数据直至末尾。然后调用closeEntry来读入下一项。在读入最后一项之前, 不能关闭zin
var zin = new ZipInputStream(new FileInputStream(zipname));
ZipEntry entry;
while((entry = zin.getNextEntry()) != null)
{
read the content of zin
zin.closeEntry();
}
zin.close();
写出ZIP文件可以使用ZipOutputStream
var fout = new FileOutputStream("test.zip");
var zout = new ZipOutputStream(fout);
for all files
{
var ze = new ZipEntry(filname);
zout.putNextEntry(ze);
send data to zout
zout.closeEntry();
}
zout.close();
对象输入 / 输出流与序列化
保存和加载序列化对象
首先需要打开一个ObjectOutputStream对象
var out = new ObjectOutputStream(new FileOutputStream("employee.dat"));
var harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
var boss = new Manager("Carl Cracker", 80000, 1987, 12. 15);
out.writeObject(harry);
out.writeObject(boss);
读回对象
var in = new ObjectInputStream(new FileInputStream("employee.dat"));
var e1 = (Employee) in.readObject();
var e2 = (Employee) in.readObject();
但这种操作有一个大前提: 这些类必须实现Serializable接口
当一个对象被多个对象共享时存入, 由于每个对象都是用一个序列号(serial number)保存的, 所以读入完全不受影响。
算法如下:
- 对遇到的每一个对象引用都关联一个序列号
- 对每个对象当第一次遇到时, 保存其对象数据到输入流中
- 如果某个对象之前已经被保存过, 那么只写出与之前保存过的序列号x的对象相同的信息。
读回数据时,
- 对于对象输入流中的对象, 第一次遇到其序列号时, 构建它, 并使用流中数据来初始化他, 然后记录这个顺序号和新对象之间的关联。
- 当遇到“与之前保存过的序列号为x的对象相同”这一标记时, 获取与这个序列号相关联的对象引用
package objectStream;
import java.io.*;
/**
* @author Cay Horstmann
*/
public class ObjectStreamTest {
public static void main(String[] args) throws IOException, ClassNotFoundException
{
Employee harry;
harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
var carl = new objectStream.Manager("Carl Cracker", 80000, 1987, 12, 15);
carl.setSecretary(harry);
var tony = new objectStream.Manager("Tony Tester", 40000, 1990, 3, 15);
tony.setSecretary(harry);
var staff = new Employee[3];
staff[0] = carl;
staff[1] = harry;
staff[2] = tony;
//save all employee records to the file employee.dat
try(var out = new ObjectOutputStream(new FileOutputStream("employee.dat")))
{
out.writeObject(staff);
}
try(var in = new ObjectInputStream(new FileInputStream("employee.dat")))
{
//retrieve all records into a new array
var newStaff = (Employee[]) in.readObject();
//raise secretary's salary
newStaff[1].raiseSalary(10);
//print the newly read employee records
for(Employee e: newStaff)
System.out.println(e);
}
}
}
修改默认的序列化机制
有些数据域是不能序列化的, 例如只对本地方法有意义的存储文件句柄或窗口句柄的整数值。
如果这些域属于不可序列化类, 只需要将它们标记成transient
public class LabeledPoint implements Serializable
{
private String label;
private transient Pint2D.Double point;
}
private void writeObject(ObjectOutputStream out) throws IOException
{
out.defaultWriteObject();
out.writeDouble(point.getX());
out.writeDouble(point.getY());
}
private void readObject(ObjectInputStream in) throws IOException
{
in.defaultReadObject();
double x = in.readDouble();
double y = in.readDouble();
point = new Point2D.Double(x, y);
}
对于java.util.Date, 它提供了自己的readObject和writeObject方法, 为了优化查询, 它存储了Calender对象,和一个毫秒计数值。Calender是冗余的, 其实不需要保存
类还可以定义其自己的机制, 为实现这一点, 必须实现Externalizable接口。
public void readExternal(ObjectInputStream in) throws IOException, ClassNotFoundException;
public void writeExternal(ObjectOutputStream out) throws IOException;
这些方法对包括超类数据在内的整个对象的存储和恢复负全责
public void readExternal(ObjectInput s) throws IOException
{
name = s.readUTF();
salary = s.readDouble();
hireDay = LocalDate.ofEpochDay(s.readLong());
}
public void writeExternal(ObjectOutput s) throws IOException
{
s.writeUTF(name);
s.writeDouble(salary);
s.writeLong(hireDay.toEpochDay());
}
序列化单例和类型安全的枚举
如果目标对象是唯一的, 那么在实现单例和类型安全的枚举时必须多加小心
假设有如下代码
public class Orientation
{
public static final Orientation HORIZONTAL = new Orientation(1);
public static final Orientation VERTICAL = new Orientation(2);
private int value;
private Orientation(int v){value = v;}
}
当该类型实现Sericalizable接口时, 默认的序列化机制时无法正常使用的, 假设有如下代码:
Orientation original = Orientation.HORIZONTAL;
ObjectOutputStream out = ...;
out.write(original);
out.close();
ObjectInputStream in = ...;
var saved = (Orientation) in.read();
if(saved == Orentation.HORIZONTAL) ...
这个判断是false, 因为事实上saved的值是一个全新的对象, 即使构造器是私有的, 也可以创建全新的对象
为解决该问题, 需要额外定义另外一种称为readResolve的特殊序列化方法。
当定义了readResolve方法, 在对象被序列化之后就会调用该方法, 它必须返回一个对象, 而该对象会成为readObject的返回值
protected Object readResolve() throws ObjectStreamException
{
if(value == 1) return Orientation.HORIZONTAL;
if(value == 2) return Orientation.VERTICAL:
throw new ObjectStreamException(); //this should not happen
}
务必向所有类型安全的枚举以及向所有支持单例设计模式的类中添加readResolve方法。
版本管理
通过人为将类的SHA指纹定义成和这个类的早期指纹一样的就行
首先获取原先指纹:
serialver Employee
接下来定义指纹
class Employee implements Serializable
{
...
public static final serialVersionID = .....;
}
如果新版本添加了新的数据域, 那新的数据序列化后则为默认值
这个问题就看readObject是否能够保证所有方法在处理null数据是足够健壮。
为克隆使用序列化
直接将对象序列化再读回, 这样产生的新对象就是对现有对象的一个deep copy, 在此过程中, 可以使用ByteArrayOutputStream输出到字节数组中
package serialClone;
import java.io.*;
import java.time.LocalDate;
/**
* author Cay Horstmann
*/
public class SerialCloneTest
{
public static void main(String[] args) throws CloneNotSupportedException
{
var harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
//clone harry
var harry2 = harry.clone();
//mutate harry
harry.raiseSalary(10);
//now harry and the clone are different
System.out.println(harry);
System.out.println(harry2);
}
}
/**
* A class whose method uses serialization.
*/
class SerialCloneable implements Cloneable, Serializable {
@Override
protected Object clone() throws CloneNotSupportedException {
try{
//save the object to a byte array
var bout = new ByteArrayOutputStream();
try(var out = new ObjectOutputStream(bout))
{
out.writeObject(this);
}
//read a clone of the object from the byte array
try(var bin = new ByteArrayInputStream(bout.toByteArray()))
{
var in = new ObjectInputStream(bin);
return in.readObject();
}
}
catch(IOException | ClassNotFoundException e)
{
var e2 = new CloneNotSupportedException();
e2.initCause(e);
throw e2;
}
}
}
/**
* The familiar Employee class, redefined to extend the
* SerialCloneable class.
*/
class Employee extends SerialCloneable
{
private String name;
private double salary;
private LocalDate hireDay;
public Employee(String name, double salary, int year, int month, int day) {
this.name = name;
this.salary = salary;
hireDay = LocalDate.of(year, month, day);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public LocalDate getHireDay() {
return hireDay;
}
public void setHireDay(LocalDate hireDay) {
this.hireDay = hireDay;
}
/**
* Raises the salary of this employee.
* @param byPercent the percentage of the raise
*/
public void raiseSalary(double byPercent)
{
double raise = salary * byPercent / 100;
salary += raise;
}
public String toString()
{
return getClass().getName() + "[name=" + name + ",salary=" + salary + ", hireDay=" + hireDay + "]";
}
}
操作文件
Path
Path表示的是一个目录名序列, 路径中的第一个部件可以是根部件, 例如/ 或 C:/, 以根部件开始的路径是绝对路径, 否则就是相对路径
Path absolute = Paths.get(“home”, “harry”);
Path relative = Paths.get(“myprog”, “conf”, “user.properties”);
静态的Paths.get方法接收n个字符串, 并将它们用默认文件系统的路径分隔符链接。若不是合法路径, 则抛出InvalidPathException.
get方法可以获取包含多个部件的单个字符串,
String baseDir = props.getProperty("base.dir");
//May be a string such as /opt/myprog or c:\Program Files\myprog
Path basePath = Paths.get(baseDir); //OK that baseDir bas separators
组合或解析路径是司空见惯的操作。调用p.resolve(q) 将按照如下规则返回一个路径:
- 如果q是绝对路径, 那么结果就是q
- 否则将p后面跟着q, 作为结果
Path workRelative = Paths.get("Work");
Path workPath = basePath.resolve(workRelative);
resolve方法其中一种快捷方式接收一个字符串
Path workPath = basePath.resolve("work");
resolveSibling 方法通过解析指定路径的父路径产生其兄弟路径
如下调用会在workPath的同级路径创建一个temp
Path tempPath = workPath.resolveSibling("temp");
relativize是resolve的对立面, 调用 p.relativize® 将产生路径q, 而对q解析的结果正是r.
假如以 " /home/harry" 为目标对 " /home/fred/input.txt"进行相对化操作, 会产生"…/fred/input.txt"。
normalize方法将移除所有冗余的. 和 …
toAbsolutePath方法产生给定路径的绝对路径
Path p = Paths.get("/home", "fred", "myprog.properties");
Path parent = p.getParent(); // the path /home/fred
Path file = p.getFileName(); //the path myprog.properties
Path root = p.getRoot(); //the path /
读写文件
Files类使得普通文件操作变得简单
byte[] bytes = Files.readAllBytes(path);
var content = Files.readString(path, charset);
List<String> lines = Files.readAllLines(path, charset);
Files.writeString(path, content.charset);
Files.write(path, content.getBytes(charset), StandardOpenOption.APPEND);
Files.write(path, lines, charset);
如果要处理的文件长度比较大, 或者是二进制文件, 还是应该使用流或者读入/读出器
InputStream in = Files.newInputStream(path);
OutputStream out = Files.newOutputStream(path);
Reader in = Files.newBufferedReader(path, charset);
Writer out = Files.newBufferedWriter(path, charset);
创建文件和目录
创建目录使用
Files.createDirectory(path);
如果path的中间路径不存在的话
Files.createDirectories(path);
创建空文件
Files.createFile(path);
若文件已存在, 则抛出异常
创建临时文件/ 目录
Path newPath = Files.createTempFile(dir, prefix, suffix);
Path newPath = Files.createTempFile(prefix, suffix);
Path newPath = Files.createTempDirectory(dir, prefix);
Path newPath = Files.createTempDirectory(prefix);
dir是一个Path对象, prefix和suffix可以为null, 会生成一个随机名字的文件
复制, 移动和删除文件
Files.copy(fromPath, toPath);
Files.move(fromPath, toPath);
如果目标路径已经存在, 复制或移动会失败, 若想要覆盖已有的目标路径, 使用REPLACE_EXISTING选项, 如果想复制所有的文件属性, 使用COPY_ATTRIBUTES选项
Files.copy(fromPath, toPath, StandardCopyOption.REPLACE_EXISTING, StandardCopyOption.COPY_ATTRIBUTES);
可以将移动操作定义为原子性的, 可以保证要么移动成功, 要么源文件保存在原来位置
Files.move(fromPath, toPath, StandardCopyOption.ATOMIC_MOVE);
还可以将一个流复制到Path中
Files.copy(inputStream, toPath);
Files.copy(fromPath, outputStream);
删除文件
Files.delete(path);
boolean deleted = Files.deleteIfExists(path);
用于文件操作的标准选项
| 选项 | 描述 |
|---|---|
| StandardOpenOption | 与newBufferedWriter, newInputStream, newOutputStream, write 一起使用 |
| READ | 用于读取而打开 |
| WRITE | 用于写入而打开 |
| APPEND | 若用于写入而打开, 那么在文件末尾追加 |
| TRUNCATE_EXISTING | 若用于写入而打开, 那么移除现有内容 |
| CREATE_NEW | 创建新文件并且在文件已存在的情况下创建新文件会失败 |
| CREATE | 自动在文件不存在的情况下创建新文件 |
| DELETE_ON_CLOSE | 当文件关闭时, 尽“可能”删除该文件 |
| SPARSE | 标记该文件是稀疏的 |
| DSYNC或SYNC | 要求数据和文件是同步更新的 |
| StandardCopyOption | 与copy和move一起使用 |
| ATOMIC_MOVE | 原子性移动 |
| COPY_ATTRIBUTES | 复制文件的属性 |
| REPLACE_EXISTING | 如果目标已存在, 则替换它 |
| LinkOption | 与上面所有方法及exists, isDirectory, isRegularFile 一起使用 |
| NOFOLLOW_LINKS | 不跟踪符号链接 |
| FilesVisitOption | 与find, walk, walkFileTree 一起使用 |
| FOLLOW_LINKS | 跟踪符号链接 |
获取文件信息
如下的静态方法都会返回一个boolean值
- exists
- isHidden
- isReadable, isWritable, isExecutable
- isRegularFile, isDirectory, isSymbolicLink
size方法返回文件的字节数
long fileSize = Files.size(path);
getOwner方法将文件的所有者作为java.nio.file.attribute.UserPrincipal的一个实例返回
文件的基本属性集封装在BasicFileAttributes接口中, 基本文件属性包括
- 创建文件, 最后一次访问及最后一次修改日期
- 文件是常规文件, 目录, 还是符号链接
- 文件尺寸
- 文件主键
BasicFileAttributes attributes = Files.readAttributes(path, BasicFileAttributes.class);
访问目录中的项
Stream<Path> entries = Files.list(pathToDirectory)
为了处理子目录, 使用walk方法
Stream<Path> entries = Files.walk(pathToRoot)
可以限制深度, 调用File.walk(pathToRoot, depth)
使用目录流
DirectoryStream 是 Iterable的子接口, 可以在增强for中使用
try(DirectoryStream<Path> entries = Files.newDirectoryStream(dir))
{
for(Path entry: entries)
Process entries
}
访问目录中的项并没有具体的顺序
可以用glob模式来过滤文件:
try(DirectoryStream<Path> entries = Files.newDirectoryStream(dir, "*.java"))
glob模式
| 模式 | 描述 | 示例 |
|---|---|---|
| * | 匹配路径组成部分中0个或多个字符 | *.java 匹配当前目录中所有的java文件 |
| ** | 匹配跨目录边界的0个或多个字符 | **.java 匹配在所有子目录的java文件 |
| ? | 匹配一个字符 | ???.java 匹配所有四个字符的java文件 |
| […] | 匹配一个字符集合, 可以使用连线符[0 - 9] 和取反符[! 0 - 9] | Test[0- 8A-F].java匹配Testx.java, 其中x是一个十六进制数字 |
| {…} | 匹配有逗号隔开的多个可选项之一 | *.{java, class}匹配所有的java文件和类文件 |
| \ | 转义上述字符和\字符 | * \ * * 匹配所有文件名中有* 的文件 |
若想要访问所有的子孙成员, 可以调用walkFileTree方法, 并向其传递一个FileVisitor对象
这个对象会得到如下通知
- 遇到一个文件或目录时: FileVisitResult visitFile(T path, BasicFileAttributes attrs)
- 在一个目录被处理前: FileVisitResult preVisitDirectory(T dir, IOException ex)
- 在一个目录被处理后: FileVisitResult postVisitDirectory(T dir, IOException ex)
- 在试图打开文件或目录时失败: FileVisitResult visitFileFailed(path, IOException)
对于以上情况, 可以指定如下操作
- 继续访问下一文件: FileVisitResult.CONTINUE
- 继续访问, 但是不再访问这个目录下的任何项: FileVisitResult.SKIP_SUBTREE
- 继续访问, 但是不再访问这个文件的兄弟文件: FileVisitResult.SKIP_STBLINGS
- 终止访问: FileVisitResult.TERMINATE
SimpleFileVisitor 实现了FileVisitor接口, 除了visitFileFailed方法之外都是直接访问
如下代码打印所有子目录
Files.walkFileTree(Paths.get("/"), new SimpleFileVisitor<Path>()
{
public FileVisitResult preVisitDirectory(Path path, BasicFileAttributes attrs) throws IOException
{
System.out.println(path);
return FileVisitResult.CONTINUE;
}
public FileVisitResult postVisitDirectory(Path dir, IOException exc)
{
return FileVisitResult.CONTINUE;
}
public FileVisitResult visitFileFailed(Path path, IOException exc)
{
return FileVisitResult,SKIP_SUBTREE;
}
});
如下代码删除一个目录树
//Delete the directory tree starting at root
Files.walkFileTree(path, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Files.delete(file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
if(exc != null) throw exc;
Files.delete(dir);
return FileVisitResult.CONTINUE;
}
});
zip文件系统
FileSystem fs = FileSystems.newFileSystem(Paths.get(zipname), null);
Files.copy(fs.getPath(sourceName), targetPath);
以上代码将建立一个文件系统, 包含zip文件的所有文件吗如果知道文件名, 那么就可以提取文件
要列出zip文档的所有文件, 可以遍历文件树
FileSystem fs = FileSystems.newFileSystem(Paths.get(zipname), null);
Files.walkFileTree(fs.getPath("/"), new SimpleFileVisitor<Path>(){
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException
{
System.out.println(file);
return FileVisitResult.CONTINUE;
}
});
内存映射文件
内存映射文件的性能
通常内存映射比使用带缓冲的顺序输入还要快一点
首先从文件中获得一个通道(channel), 它通常是用于磁盘文件的一种抽象, 使之可以访问诸如内存映射, 文件加锁机制以及文件间快速数据传输等操作系统特性
FileChannel channel = FileChannel.open(path, options);
然后通过FileChannel类的map方法从这个通道获取一个ByteBuffer, 指定想要映射的文件区域与映射模式, 支持的模式有三种
- FileChannel.MapMode.READ_ONLY
- FileChannel.MapMode.READ_WRITE
- FileChannel.MapMode.PRIVATE
缓冲区支持顺序和随机数据访问
while(buffer.hasRamaining())
{
byte b = buffer.get();
...;
}
for (int i = 0; i < buffer.limit(); i++)
{
byte b = buffer.get(i);
}
还有读写字节数组的get(byte[] byte), get(byte[], int offset, int length)
还有getInt, getChar, getLong, getFloat, getShort, getDouble
若需要低位在前的二进制处理方式
buffer.order(ByteOrder.LITTLE_ENDIAN);
ByteOrder b = buffer.order();
写入方法如下: putInt, putChar, putLong, putFloat, putShort, putDouble
可以使用如下循环判断一个字节序列的校验和;
var crc = new CRC32();
while(more bytes)
crc.update(next byte);
long checksum = crc.getValue;
package memoryMap;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.zip.CRC32;
/**
* This program computes the CRC checksum of a file in four ways<br>
* Usage: java.memoryMap.memoryTest filename
* @author Cay Horstmann
*/
public class MemoryMapTest {
public static long checksumInputStream(Path filename) throws IOException {
try(InputStream in = Files.newInputStream(filename))
{
var crc = new CRC32();
int c;
while((c = in.read()) != -1)
crc.update(c);
return crc.getValue();
}
}
public static long checksumBufferedInputStream(Path filename) throws IOException
{
try(var in = new BufferedInputStream(Files.newInputStream(filename)))
{
var crc = new CRC32();
int c;
while((c = in.read()) != -1)
crc.update(c);
return crc.getValue();
}
}
public static long checksumRandomAccessFile(Path filename) throws IOException
{
try(var file = new RandomAccessFile(filename.toFile(), "r"))
{
long length = file.length();
var crc = new CRC32();
for(long p = 0; p < length; p++)
{
file.seek(p);
int c = file.readByte();
crc.update(c);
}
return crc.getValue();
}
}
public static long checksumMappedFile(Path filename) throws IOException
{
try(FileChannel channel = FileChannel.open(filename))
{
var crc = new CRC32();
int length = (int) channel.size();
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_ONLY, 0, length);
for(int p = 0; p < length; p++)
{
int c = buffer.get(p);
crc.update(c);
}
return crc.getValue();
}
}
public static void main(String[] args) throws IOException
{
System.out.println("Input Stream: ");
long start = System.currentTimeMillis();
Path filename = Paths.get(args[0]);
long crcValue = checksumInputStream(filename);
long end = System.currentTimeMillis();
System.out.println(Long.toHexString(crcValue));
System.out.println((end - start) + "milliseconds");
System.out.println("Buffered Input Stream: ");
start = System.currentTimeMillis();
crcValue = checksumBufferedInputStream(filename);
end = System.currentTimeMillis();
System.out.println(Long.toHexString(crcValue));
System.out.println((end - start) + "milliseconds");
System.out.println("Random Access File: ");
start = System.currentTimeMillis();
crcValue = checksumRandomAccessFile(filename);
end = System.currentTimeMillis();
System.out.println(Long.toHexString(crcValue));
System.out.println((end - start) + "milliseconds");
System.out.println("Mapped File: ");
start = System.currentTimeMillis();
crcValue = checksumMappedFile(filename);
end = System.currentTimeMillis();
System.out.println(Long.toHexString(crcValue));
System.out.println((end - start) + "milliseconds");
}
}
缓冲区数据结构
Buffer类是一个抽象类, 拥有例如ByteBuffer, CharBuffer, DoubleBuffer, IntBuffer, LongBuffer, ShortBuffer等
每个缓冲区具有
- 一个容量, 永远不能改变
- 一个读写位置, 下一个值将在此进行读写
- 一个界限, 读写不能超过它
- 一个可选标记, 用于重复一个读入操作或写出操作
0 <= 标记 <= 读写位置<= 界限 <= 容量
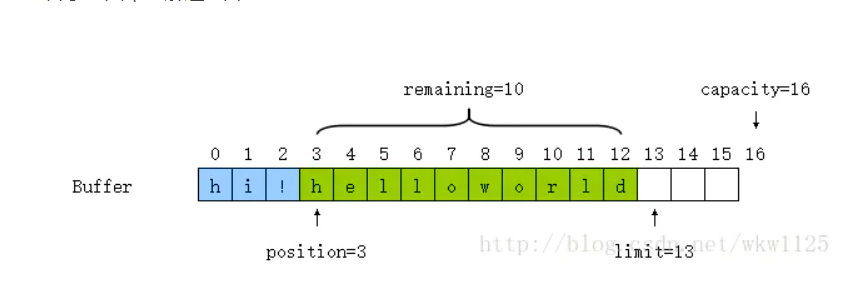
当写入到一定程度后, 就需要读出, 调用flip方法将limit设置到当前位置, 并把position复位到0, 在remaining方法返回正数(limit - position) 将缓冲区中所有值读入后, 调用clear清空缓冲区
重读缓冲区使用rewind或mark/reset方法
获取缓冲区调用ByteBuffer.allocate 或 ByteBuffer.wrap这样的静态方法
可以用来自某个通道的数据填充缓冲区, 或者将缓冲区的内容写出到通道中
ByteBuffer buffer = ByteBuffer.allocate(RECORD_SIZE);
channel.read(buffer);
channel.position(newpos);
buffer.flip();
channel.write(buffer);
文件加锁机制
FileChannel = FileChannel.open(path);
FileLock lock = channel.lock();
//or
FileLock lock = channel.tryLock();
锁定文件的一部分
FileLock lock(long start, long size, boolean shared);
FileLock tryLock(long start, long size, boolean shared);
若shared标志为false, 锁定文件的目的则为读写, 否则为读入
要想锁定所有字节, 使用Long.MAX_VALUE来表示尺寸
文件加锁机制是依赖操作系统的
- 某些系统下文件加锁仅仅是建议性的
- 某些系统中, 不能在锁定一个文件的同时将其映射到内存中
- 文件锁由整个java虚拟机持有, 若两个程序都由同一个虚拟机启动, 那不可能每一个都获得一个锁
- 一些系统下, 关闭一个通道会释放由java虚拟机持有的底层文件上的所有锁
- 在网络文件系统上锁定文件是高度依赖于系统的
正则表达式
[Jj] ava.+
- 第一个字母是J或j
- 接下来三个字符是ava
- 其余部分由一个或多个任意字符组成
- 大部分字符可以和其自身匹配
- . 符号可以匹配任何字符
- 使用\作为转义字符
- ^和$分别匹配一行的开头和结尾
- 可以将量词运用到表达式X
- 使用?作为后缀调用吝啬匹配
- 使用群组定义子表达式
匹配字符串
首先用正则表达式字符串构建一个Pattern对象, 然后获得一个Matcher
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(input);
if(matcher.matches()) ...
输入可以是任何实现了CharSequence接口的类的对象, 例如String, StringBuilder, charBuffer
可以设置一个或多个标志
Pattern pattern = Pattern.compile(expression, Pattern.CASE_INSENSITIVE + Pattern.UNICODE_CASE);
或者在模式中指定
String regex = "(?iU:expression)"
- Pattern.CASE_INSENSITIVE或i: 匹配字符时忽略大小写
- Pattern.UNICODE_CASE 或u: 与i组合, 用Unicode字母的大小写来匹配
- Pattern.UNICODE_CHARACTER_CLASS或U: 选择Unicode字符集代替POSIX
- Pattern.MULTILINE或m: ^和$匹配行的开头和结尾, 而不是整个输入的开头和结尾
- Pattern.UNIX_LINES 或d: 多行模式下, 只有\n被识别为行终止符
- Pattern.DOTALL或s: .符号匹配所有符号, 包括行终止符
- Pattern.COMMENTS或x: 空白字符和注释将被忽略
- Pattern.LITERAL: 逐字采纳,精确匹配
- Pattern.CANON_EQ: 考虑Unicode字符规范的等价性
在集合或流中匹配元素:
Stream<String> strings = ...;
Stream<String> result = strings.filter(pattern.asPrediate());
若正则表达式包含群组, 那么Matcher对象可以揭示群组的边界
int start(int groupIndex);
int end(int groupIndex);
抽取匹配字符串
String group(int groupIndex);
群组0是整个输入, 而用于第一个实际群组的索引是1
调用groupCount方法获得群组的数量, 对于具名的组
int start(String groupName);
int end(String groupName);
String group(String groupName);
嵌套群组依靠前括号排序
package regex;
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.regex.PatternSyntaxException;
/**
* This program tests regular expression matching.Enter a pattern and strings to match.
* or hit Cancel to exit. If the pattern contains groups, the group boundaries are displayed
* in the match.
* @author Cay Horstmann
*/
public class RegexTest {
public static void main(String[] args) throws PatternSyntaxException {
var in = new Scanner(System.in);
System.out.print("Enter pattern: ");
String patternString = in.nextLine();
Pattern pattern = Pattern.compile(patternString);
while(true)
{
System.out.print("Enter string to match: ");
String input = in.nextLine();
if(input == null || input.equals("")) return;
Matcher matcher = pattern.matcher(input);
if(matcher.matches())
{
System.out.println("Match");
int g = matcher.groupCount();
if(g >0)
{
for (int i = 0; i < input.length(); i++) {
//Print any empty groups
for(int j = 1; j <= g; j++)
if(i == matcher.start(j) && i == matcher.end(j))
System.out.print("()");
//Print ( for non-empty groups starting here
for(int j = 1; j <= g; j++)
if(i == matcher.start(j) && i != matcher.end(j))
System.out.print('(');
System.out.print(input.charAt(i));
//Print ) for non-empty groups ending here
for(int j = 1; j <= g; j++)
if(i + 1 != matcher.start(j) && i + 1 == matcher.end(j))
System.out.print(')');
}
System.out.println();
}
}
else
System.out.println("No match");
}
}
}
找出多个匹配
是由Mathcher.find来查找匹配内容
while(matcher.find())
{
int start = matcher.start();
int end = matcher.end();
String match = input.group();
...
}
可以调用results方法获取一个Stream。
List<String> matches = pattern.matcher(input)
.results()
.map(Matcher::group)
.collect(Collectors.toList());
若要处理文件中的数据, 使用Scanner.findAll方法来获取一个Stream< MatchResult >
var in new Scanner(path, StandardCharsets.UTF_8);
Stream<String> words = in.findAll("\\PL+").map(MatchResult::group);
package match;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.regex.MatchResult;
import java.util.regex.Pattern;
import java.util.regex.PatternSyntaxException;
/**
* This program displays all URLs in a web page by matching a regular expression that
* describes the <a href=...>HTML tag. Start the program as <br>
* java match.HrefMatch URL
* @author CayHorstmann
*/
public class HrefMatch {
public static void main(String[] args) {
try{
//get URL string command line or use default
String urlString;
if(args.length > 0) urlString = args[0];
else urlString = "http://openjdk.java.net/";
//read contents of URL
InputStream in = new URL(urlString).openStream();
var input = new String(in.readAllBytes(), StandardCharsets.UTF_8);
//search for all occurrences of pattern
var patternString = "<a\\s+href\\s*=\\s*(\"[^\"]*\"|[^\\s>]*)\\s*>";
Pattern pattern = Pattern.compile(patternString, Pattern.CASE_INSENSITIVE);
pattern.matcher(input).results().map(MatchResult::group).forEach(System.out::println);
}
catch (IOException | PatternSyntaxException e)
{
e.printStackTrace();
}
}
}
用分隔符来分割
String input = ....;
Pattern commas = Pattern.compile("\\s*,\\s*");
String[] tokens = commas.split(input); //"1, 2, 3"turns into["1", "2", "3"]
可以惰性获取它们
Stream<String> tokens = commas.splitAsStream(input);
还可以
String[] tokens = input.split("\\s*,\\s*");
如果输入数据在文件中, 需要使用扫描器
var in = new Scanner(path, StandardCharsets.UTF_8);
int.useDelimiter("\\s*,\\s*");
Stream<String> tokens = in.tokens();
替换匹配
Matcher类的replaceAll方法将正则表达式出现的所有地方都用替换字符串替代
Pattern pattern = Pattern.complie("[0-9]+");
Matcher matcher = pattern.matcher(input);
String ouput = matcher.replaceAll("#");
替换字符串可以包含对模式中群组的引用, $n表示替换成第n个群组, ${name} 被替换问具有给定名字的组
若字符串里有$和, 还不想被解释成群组的替换符
matcher.replaceAll(Matcher.quoteReplacement(str));
若想要实现比按照群组匹配拼接更复杂的操作, 可以提供一个替换函数, 该函数接收一个MatchResult对象, 产生一个字符串。
String result = Pattern.compile("\\PL{4,}")
.matcher("Mary had a little lamb")
.replaceAll(m -> m.group().toUpperCase());
//Yield "MARY had a LITTLE LAMB"
replaceFirst方法将只替换模式的第一次出现
of URL
InputStream in = new URL(urlString).openStream();
var input = new String(in.readAllBytes(), StandardCharsets.UTF_8);
//search for all occurrences of pattern
var patternString = "<a\\s+href\\s*=\\s*(\"[^\"]*\"|[^\\s>]*)\\s*>";
Pattern pattern = Pattern.compile(patternString, Pattern.CASE_INSENSITIVE);
pattern.matcher(input).results().map(MatchResult::group).forEach(System.out::println);
}
catch (IOException | PatternSyntaxException e)
{
e.printStackTrace();
}
}
}
## 用分隔符来分割
```java
String input = ....;
Pattern commas = Pattern.compile("\\s*,\\s*");
String[] tokens = commas.split(input); //"1, 2, 3"turns into["1", "2", "3"]
可以惰性获取它们
Stream<String> tokens = commas.splitAsStream(input);
还可以
String[] tokens = input.split("\\s*,\\s*");
如果输入数据在文件中, 需要使用扫描器
var in = new Scanner(path, StandardCharsets.UTF_8);
int.useDelimiter("\\s*,\\s*");
Stream<String> tokens = in.tokens();
替换匹配
Matcher类的replaceAll方法将正则表达式出现的所有地方都用替换字符串替代
Pattern pattern = Pattern.complie("[0-9]+");
Matcher matcher = pattern.matcher(input);
String ouput = matcher.replaceAll("#");
替换字符串可以包含对模式中群组的引用, $n表示替换成第n个群组, ${name} 被替换问具有给定名字的组
若字符串里有$和, 还不想被解释成群组的替换符
matcher.replaceAll(Matcher.quoteReplacement(str));
若想要实现比按照群组匹配拼接更复杂的操作, 可以提供一个替换函数, 该函数接收一个MatchResult对象, 产生一个字符串。
String result = Pattern.compile("\\PL{4,}")
.matcher("Mary had a little lamb")
.replaceAll(m -> m.group().toUpperCase());
//Yield "MARY had a LITTLE LAMB"
replaceFirst方法将只替换模式的第一次出现















 1056
1056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









