







在转换中,血统就是说你要知道一个数据是从哪里来的,在哪个步骤中,增加了或修改了这个数据,最后输出到哪个数据库表中。
本篇通过job,先把资源库导出成xml文件,然后通过分析xml文件,把想要的信息输入到数据库表中进行保存。当要查询表来源时,只需要查询存储资源库的表即可。
job:
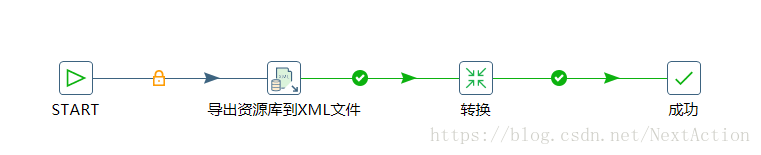
job中的转换:

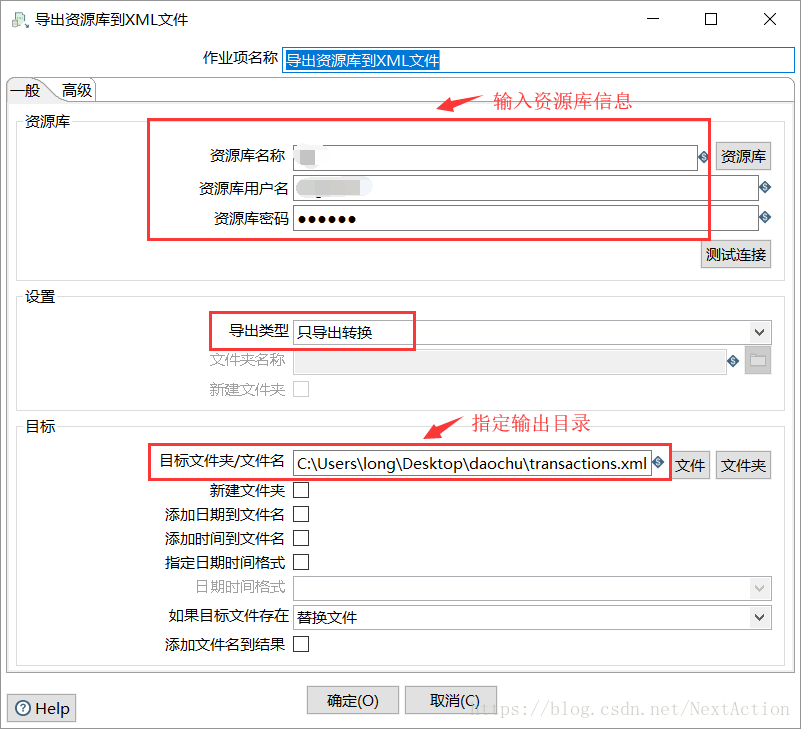
1. 导出资源库到XML文件
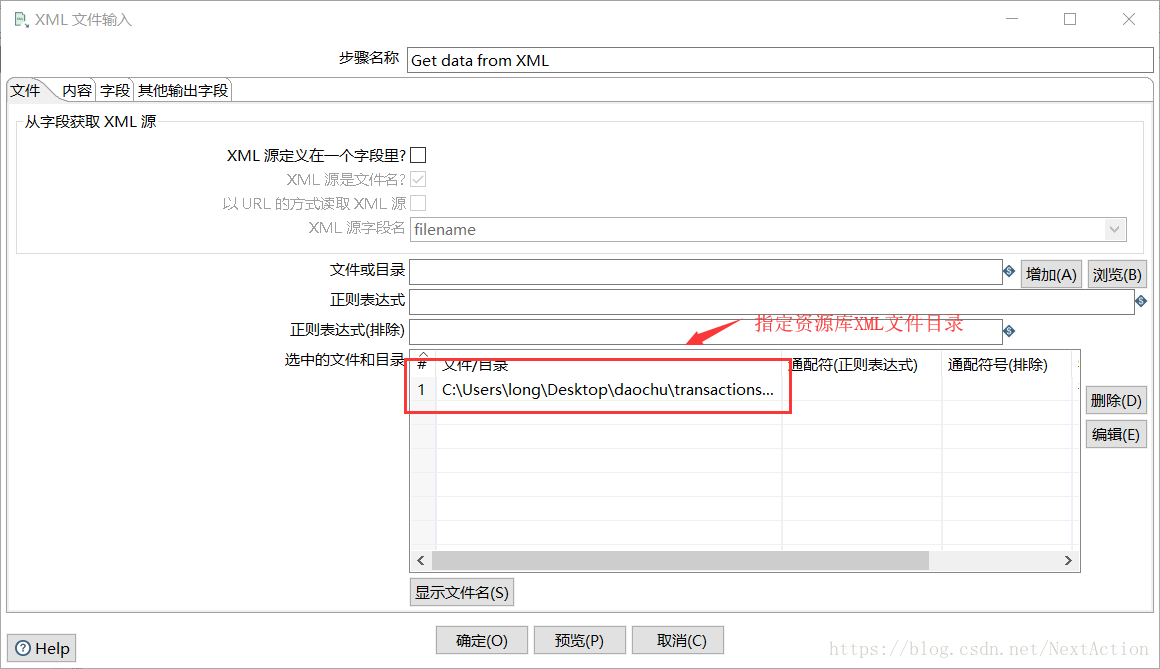
2. Get data from XML(解析导出的资源库XML文件)
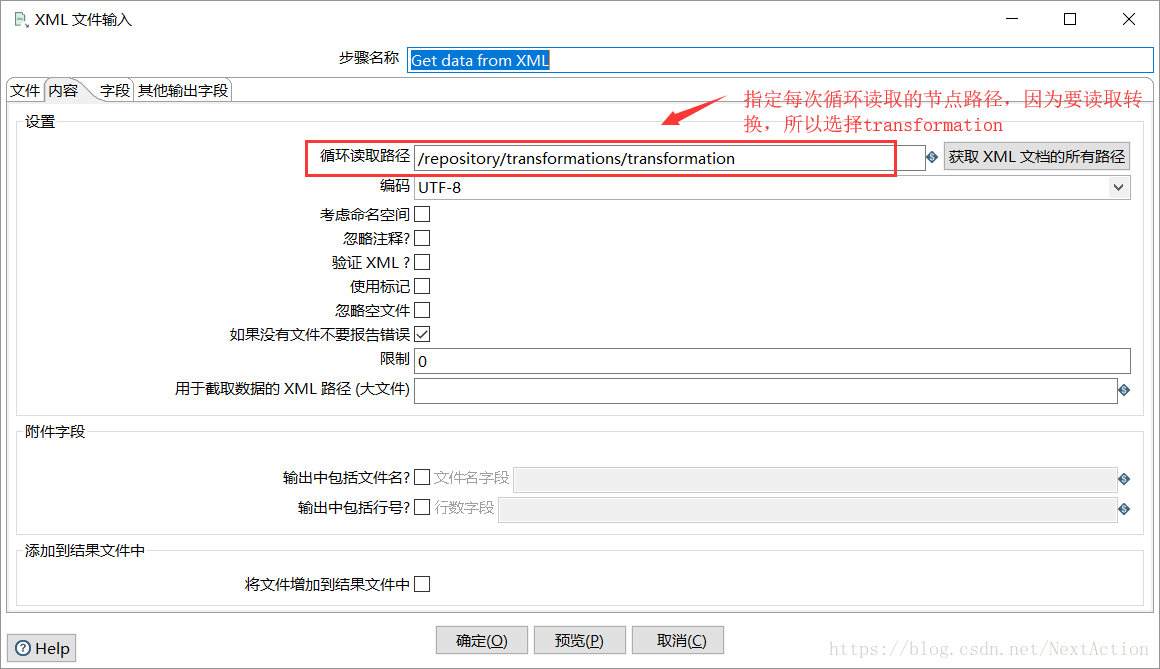
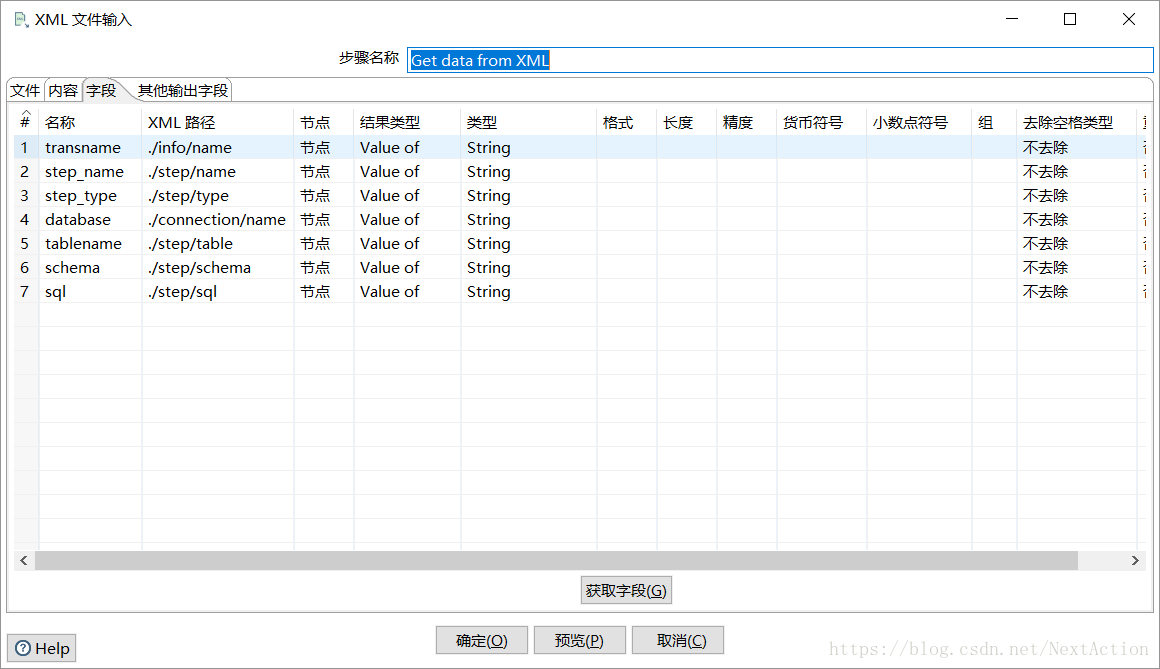
输出的字段名如下,其中“.”表示在“内容”标签中设置的循环路径:
transname(转换名称):./info/name
step_name(步骤名称):./step/name
step_type(步骤类型):./step/type
database(连接的数据库):./connection/name
tablename(输出的表名):./step/table
schema(表所在的schema名):./step/schema
sql(生成表的SQL):./step/sql
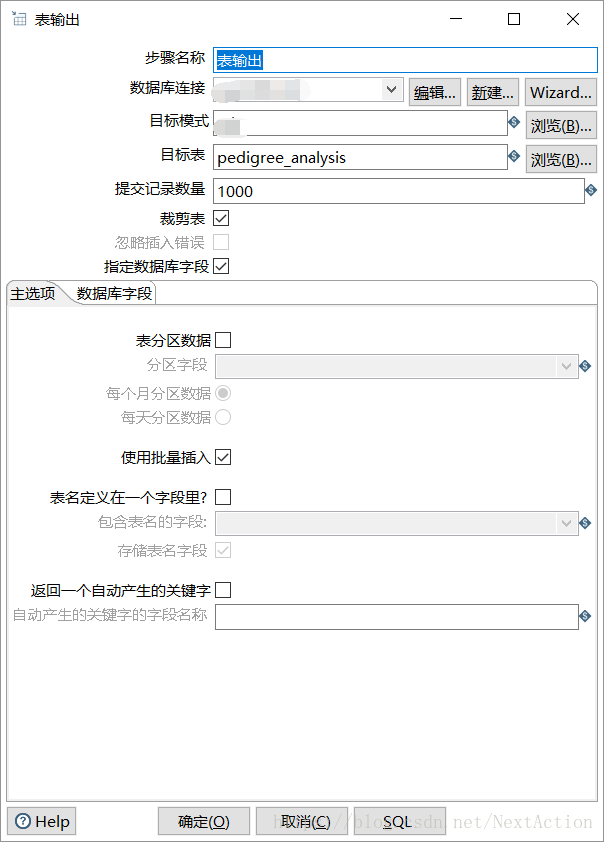
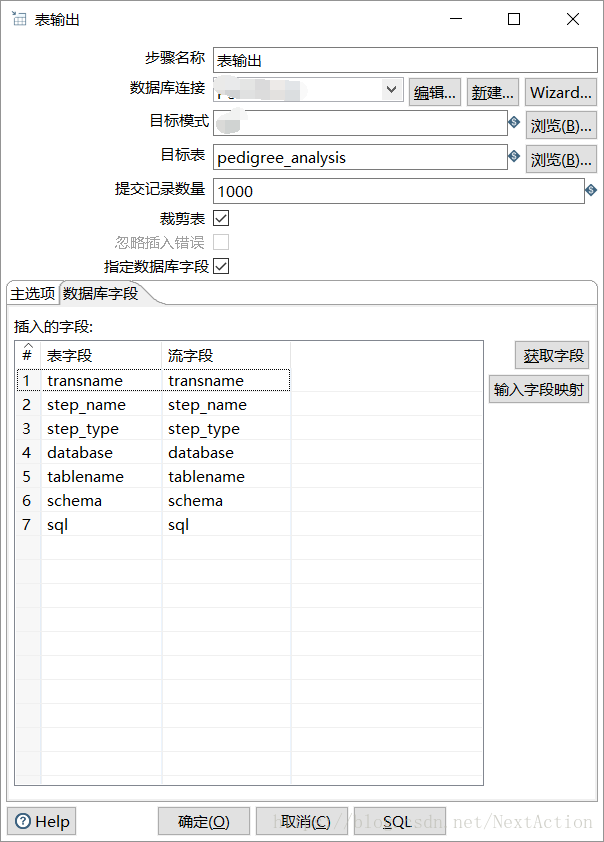
3. 表输出

















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









